

上海 day16 -- python 常用模块1
2019-07-18 18:43 在上海的日子里 阅读(245) 评论(0) 编辑 收藏 举报目 录
-
collections模块
-
time 模块
-
datatime模块
-
random 模块
-
os 模块
-
sys 模块
-
序列化模块
一、collections 模块
具名元组 namedtuple : 给元组定义名字。
namedtuple() 有两个参数,一个是定义的名字,另一个是元组内的变量名字必须是字符串或可迭代对象。
# 具名元组 : 将自己建造的元组进行命名 # 示例1 建造坐标 from collections import namedtuple # namedtuple 括号内有两个参数,一个是自己起的元组名称,另一个可以是可迭代对象或字符串 point = namedtuple('基地坐标',['x','y']) # 第二个参数是可迭代对象 res = point(1,2) print(res) # 基地坐标(x=1, y=2) point1 = namedtuple('极地坐标','x y z') # 第二个参数也可以是字符串,但要注意字符串之间要以空格隔开,不然会认为是一个字符 res2 = point1(3,4,5) print(res2) # 极地坐标(x=3, y=4, z=5)
# 示例2 扑克牌 from collections import namedtuple point = namedtuple('黑桃K',"color number") res = point('黑色桃型','K') print(res) # 黑桃K(color='黑色桃型', number='K')
双端队列 deque:
# 从collections 引出双端队列之前,先看一下队列: # 队列:IFIO 先进先出原则 import queue q = queue.Queue() # 生成一个队列对象 q.put('xiao zhu') # .put() 方法给队列添加元素 q.put('xiao lu') q.put('xiao qin') res = q.get() # .get() 方法取值 res1 = q.get() res2 = q.get() res3 = q.get() print(res,res1,res2) # xiao zhu xiao lu xiao qin print(res3) # 如果队列中的值取完后,程序会一直运行并等待,直到取到值为止
""" 双端队列:deque 两端都可以进出 方法:append() appendleft() pop() popleft() """ from collections import deque q = deque(['w','e','r']) # 直接deque方法生成双端队列 q.append('猪') q.appendleft('猴') print(q) # deque(['猴', 'w', 'e', 'r', '猪']) q.pop() q.popleft() print(q) # deque(['w', 'e', 'r']) # 队列一般是不支持在队内插值的,只能在首尾插值 # 但是双端队列比较特殊,可以在任意位置查入元素 q.insert(1,'诸侯死对头') print(q)
有序字典:OrderedDict
""" 原生字典是无序的,打印出来的key值顺序是不固定的; 但是 OrderedDict 的key值是有序的,按照插入的顺序排列 """ normal_dict = dict([('zhu',1),('lu',2),('qin',3)]) print(normal_dict) # {'zhu': 1, 'lu': 2, 'qin': 3} from collections import OrderedDict dict = OrderedDict([('zhu',1),('lu',2),('qin',3)]) print(dict) # OrderedDict([('zhu', 1), ('lu', 2), ('qin', 3)]) 返回一个对象 dict1 = OrderedDict() # print(dict1) # dict1['x'] = 1 # dict1['y'] = 2 # dict1['z'] = 3 # print(dict1) # OrderedDict([('x', 1), ('y', 2), ('z', 3)]) # for i in dict1: # print(i,end=' ') # x y z dict1['x'] = 1 dict1['K'] = 666 dict1['y'] = 2 dict1['z'] = 3 print(dict1) # OrderedDict([('x', 1), ('K', 666), ('y', 2), ('z', 3)]) for i in dict1: print(i,end=' ') # x K y z 我们可以看出key的排列是有顺序的,是按照插入顺序排序
默认字典 defaultdict
# 默认字典 defaultdict from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] dict = defaultdict(list) # 后续字典中新建的key值对应的value就是列表 #print(dict['wer']) # [] 新添加的key值‘wer’对应的value就是空列表 for i in values: if i > 66: dict['k1'].append(i) else: dict['k2'].append(i) print(dict) # defaultdict(<class 'list'>, {'wer': [], 'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90]})
计数器 counter
# 计数器counter # 需求:将s = 'abcdeabcdabcaba' 统计字符数量并写成字典形式 d = {} for i in s: d[i] = 0 print(d) # {'a': 0, 'b': 0, 'c': 0, 'd': 0, 'e': 0} 可以完成去重 # 代码 from collections import Counter s = 'abcdeabcdabcaba' res = Counter(s) print(res) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
二、time 模块
time模块里有三种表现形式:
1、时间戳 time.time()
2、格式化时间 time.strftime()
3、结构化时间 time.localtime()
''' time 模块 三种表现形式 时间戳 格式化时间 结构化时间 ''' import time # 时间戳 print(time.time()) # 格式化时间 res = time.strftime('%Y-%m-%d %H:%M:%S') print(res) # 2019-07-18 18:47:48 res1 = time.strftime('%Y-%m-%d %X') # %X 就相当于 %H:%M:%S print(res1) # 2019-07-18 18:49:40 res2 = time.strftime('%Y-%m-%d ') print(res2) # 2019-07-18 res3 = time.strftime('%Y/%m') print(res3) # 2019/07 res4 = time.strftime('%H:%M') print(res4) # 18:54 # 结构化时间 print(time.localtime()) # 结果:time.struct_time(tm_year=2019, tm_mon=7, tm_mday=18, tm_hour=18, # tm_min=56, tm_sec=31, tm_wday=3, tm_yday=199, tm_isdst=0)
时间戳、格式化时间和结构化时间之间是可以相互转化的:


# print(time.localtime()) # print(time.localtime(time.time())) # res = time.localtime(time.time()) # print(time.time()) # print(time.mktime(res)) # print(time.strftime('%Y-%m',time.localtime())) # print(time.strptime(time.strftime('%Y-%m',time.localtime()),'%Y-%m'))
三、datatime模块
datetime模块中的主要方法:datetime.date datetime.datetime datetime.timedelta
""" datetime 模块 --- 用来获取本地时间 """ import datetime # datetime.date 获取本地时间 年月日 res1 = datetime.date.today() # 年月日 ----time.strftime('%Y-%m-%d') print(res1) # 2019-07-18 # datetime.datetime 获取本地时间 年月日 时分秒 res2 = datetime.datetime.today() # 年月日 时分秒 -----time.strftime('%Y-%m-%d %X') print(res2) # 2019-07-18 19:05:42.752091 #print(res2.yaer) # 报错:datetime 没有year方法 # 针对性的获取 print(res1.year) # 2019 print(res1.month) # 7 print(res1.day) # 18 print(res1.weekday()) # 3 .weekday 0-6表示星期,0表示周一 print(res1.isoweekday()) # 4 isoweekday 1-7表示星期 1表示周一
操作时间运算:
import datetime # 操作时间 timedelta对另一个时间加7天或减7天 current_t = datetime.date.today() # 日期对象 print(current_t) # 2019-07-18 timedel_t = datetime.timedelta(days=7) # print(timedel_t) # 7 days, 0:00:00 """ ***** 日期对象 = 日期对象 +/- timedelta对象 timedelta = 日期对象 +/- 日期对象 """ c_time = current_t - timedel_t print(c_time) # 2019-07-11 t_time = c_time - current_t print(t_time) # -7 days, 0:00:00
小练习:datetime.datetime() 括号内可以自定义时间
''' 练习:计算生日时间 ''' import datetime cur_time = datetime.datetime.today() birth_time = datetime.datetime(2019,12,29) c_time = birth_time - cur_time print(c_time) # 163 days, 4:15:37.273318 cur_time = datetime.date.today() birth_time = datetime.date(2019,12,29) c_time = birth_time - cur_time print(c_time) # 164 days, 0:00:00
UCT时间:
# UTC时间 # dt_today = datetime.datetime.today() # dt_now = datetime.datetime.now() # dt_utcnow = datetime.datetime.utcnow() # print(dt_utcnow,dt_now,dt_today)
四、random 模块
random模块中的常用方法:
random.randint() random.random() random.choice() random.shuffle()
"""" random 模块 """ import random print(random.randint(1,5)) # 随机生成指定范围的数字,包含首尾 print(random.random()) # 随机生成0-1之间的小数 # 掷骰子原理 random.choice() print(random.choice(['a','b','c','d'])) # 摇号 随机从列表中抽取一个元素 print(random.choice([1,2,3,4])) # 摇号 随机从列表中抽取一个元素 # random.shuffle() 洗牌 随机打乱顺序 list1 = [22,33,44,55,66] #res = random.shuffle(list1) # None注意:列表是可变类型,直接修改不需要返回值接收 random.shuffle(list1) # 洗牌 打乱顺序 print(list1)
小程序:生成随机验证码
''' 小程序:生成随机验证码,要求封装成函数,想生成几位就生成几位 思路:大写字母,小写字母,0-9数字 这三种要随机选择;要生成5位,涉及到字符串的拼接 方法:随机生成random.randint() chr() ASCII码转换 摇号 random.choice() ''' import random def get_apl(n): l_str = "" for i in range(n): upper_apl = chr(random.randint(65,90)) lower_apl = chr(random.randint(97,122)) random_num = str(random.randint(0,9)) l_str += random.choice([upper_apl,lower_apl,random_num]) return l_str # 注意:return的缩进要与def保持一个tab键 res = get_apl(5) print(res) # ibFkp
五、os 模块
面试小问题:os模块 和 sys模块是用来做什么的?
os 模块是用来和操作系统打交道的,sys模块是用来和python解释器打交道的。
以一个文件小程序来引出以下3个os模块的小方法:
os.path.dirname() 以括号内参数为参照,查找它的上一级文件绝对路径
os.path.join() 文件路径的拼接,必须要有文件名才能进行拼接
os.listdir() 参数是文件路径,该方法是打印出该文件路径下的所有内容。
程序需求:打印出‘老男孩影视作品’下的所有内容
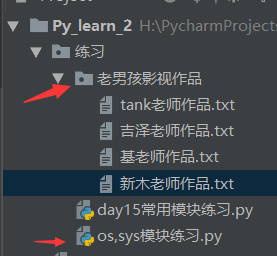
import os # 需求:将'老男孩影视作品'下的内ring打印出来让用户选择。。。 # 首先要找到文件的路径 BASE_DIR = os.path.dirname(__file__) # 找到的是上一级目录"练习" # 文件路径的拼接必须要得到文件的名字 MOVIE_DIR = os.path.join(BASE_DIR,'老男孩影视作品') # 进行路径的拼接,从'练习'目录向下找‘老男孩作品’ #print(MOVIE_DIR) # H:/PycharmProjects/Py_learn_2/练习\老男孩影视作品 movie_list = os.listdir(MOVIE_DIR) # 该路径下的所有文件 # print(movie_list) # '老男孩'文件下的所有文件 得到的是一个列表 # 打印文件列表给用户看 for index,file in enumerate(movie_list,1): # 枚举索引从1 开始 print(index,file) choice = input("请输入想看的文件编号:").strip() if choice.isdigit(): choice = int(choice) if choice >=1 and choice<(len(movie_list)+1): # 获取用户想看的文件名, target_file = movie_list[choice-1] # 获取文件名之后进行文件路径拼接 target_path = os.path.join(MOVIE_DIR,target_file) with open(target_path,'r',encoding='utf-8') as f: print(f.read())
os 模块的其他方法:
# os.mkdir("tank老师精选!") # 在当前执行文件下目录下新建文件 # 查找文件是否存在,在执行文件目录的下一层可以查找 print(os.path.exists(r'H:\PycharmProjects\Py_learn_2\练习\老男孩影视作品\tank老师作品.txt')) # True # 查找文件是否存在,在执行文件的目录层可以查找 print(os.path.exists(r'H:\PycharmProjects\Py_learn_2\练习\tank老师精选!')) # True # os.path.isfile() 只能判断文件,不能判断文件夹 print(os.path.isfile(r'H:\PycharmProjects\Py_learn_2\练习\老男孩影视作品\tank老师作品.txt')) # True print(os.path.isfile(r'H:\PycharmProjects\Py_learn_2\练习\老男孩影视作品')) # False # os.rmdir 只能删除空文件夹 #os.rmdir(r'H:\PycharmProjects\Py_learn_2\练习\老男孩影视作品') # 报错! os.rmdir(r'tank老师精选!') # 删除成功!
常用方法:
print(os.path.dirname(__file__)) # 返回path的目录。其实就是os.path.split(path)的第一个元素 print(os.getcwd()) # 获取当前工作目录,即当前python脚本工作的目录路径 H:\PycharmProjects\Py_learn_2\练习 print(os.chdir(f'H:\PycharmProjects\Py_learn_2\练习\老男孩影视作品')) # None 切换到参数文件路径所在的目录,若文件没有下一层会报错 print(os.getcwd()) # H:\PycharmProjects\Py_learn_2\练习\老男孩影视作品 # 获取文件的大小 os.path.getsize() print(os.path.getsize(r'H:\PycharmProjects\Py_learn_2\练习\老男孩影视作品\tank老师作品.txt')) # 33 获取的是字节数 with open(r'H:\PycharmProjects\Py_learn_2\练习\老男孩影视作品\tank老师作品.txt','r',encoding='utf-8') as f: print(len(f.read())) # 11 获取的是字符数
六、sys 模块
sys模块常用方法:
import sys # 返回操作系统平台名称 print(sys.platform) # win32 # 获取Python解释程序的版本信息 print(sys.version) # 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 17:54:52) [MSC v.1900 32 bit (Intel)] # 添加环境变量 sys.path.append() # 命令行参数List,第一个元素是程序本身路径 print(sys.argv) # 命令行启动文件 可以做身份的验证
sys.argv 的用法,一个还看不懂的程序!!!
print(sys.argv) # 命令行启动文件 可以做身份的验证 if len(sys.argv) <= 1: print('请输入用户名和密码') else: username = sys.argv[1] password = sys.argv[2] if username == 'jason' and password == '123': print('欢迎使用') # 当前这个py文件逻辑代码 else: print('用户不存在 无法执行当前文件')
七、序列化模块
