
雪花算法造成的问题
问题1:
我们在处理数据库中的id时,没有使用自增,也没有在yml文件中配置:
mybatis-plus
mybatis-plus
其中主要是对id的类型进行修改。
mybatis-plus 的id_type的类型:
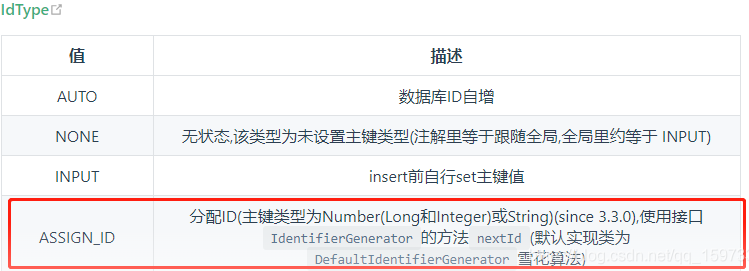
解决问题1:
现在有两种方法:
第一种解决方法:对id的数据类型进行修改,数据库实体和返回的对象都用:BigInteger。
因为数据库用的使用bigint对应的java中BigInteger, 并且BigInteger比Long范围更大。
第二种解决方法:使用 @JsonSerialize(using = ToStringSerializer.class) 注解。
// 进行转为String
如是使用的数据类型是BigInteger,依旧不能解决改问题,可以尝试去用第二种解决方法进行处理。
雪花算法:
雪花算法是Twitter开源的分布式ID生成算法,它主要是由64bit的long型生成的全局ID,引入了时间戳和ID保持自增的属性.
64bit分为四个部分: 第一个部分是1bit, 这不 使用,没有意义; 第二个部分是41bit, 组成时间戳; 第三个部分是10bit, 工作机器ID,里面分为两个部分,5个bit是的是机房号,代表最多有2^5即32个机房,5个bit是指机器的ID,代表最多有2^5个机器,即32个机器 . 第四部分是12bit, 代表是同一个毫秒类产生不同的ID,区分同一个毫秒内产生的ID.
总的来说就是一个机房,一台机器,在同一号毫秒时产生的ID,可能在同一秒钟产生不同的ID,最后12bit序列号可以区分在同一秒钟的不同ID.
雪花算法保证:
1.所生成的ID按时间递增 2.整个分布式系统不会有重复的ID

雪花算法优点是:
1、生成的id不会重复。
2、有序,不会造成空间浪费和胡乱插入影响性能。
3、生成很快特别是比UUid快得多。
4、相比UUid更小。
缺点是:时间回拨造成错乱

