
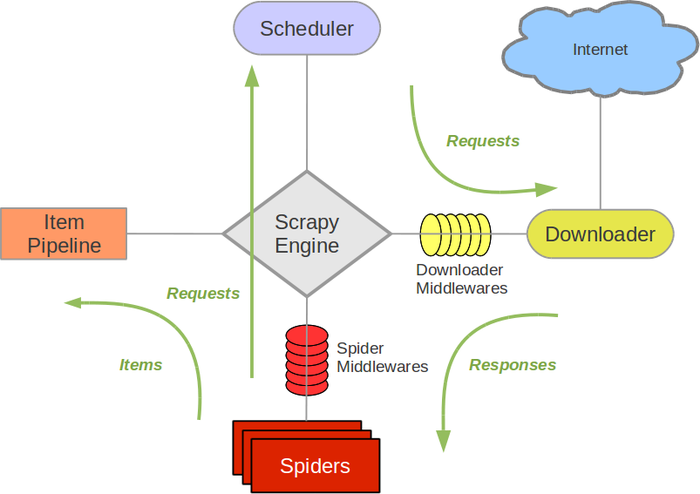
Scrapy框架图:
scrapy-engine:引擎,负责itemPipeline+Spiders+Scheduler+Downloader间的通讯和数据传递
scheduler:调度器,负责接收引擎发送过来的Requests请求,并将请求按一定方式排列入队,之后等待引擎来请求时交给引擎
downloader:下载器,负责下载引擎发送的所有Requests请求,并将其捕获到的Responses交还给引擎,引擎交给spiders来处理
spiders:负责处理所有的Responses,从中分析提取数据,获取item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入调度器
itempipeline:负责处理spiders中获取到的item字段,并进行处理(去重/持久化存储:就是保存数据)
downloader middlerwares:下载中间件,是一个自定义扩展下载功能的组件
spiders middlewares:spider中间件,操作引擎和spiders之间通信的中间件(进入spiders的Responses和从spiders出去的Requests)
流程(简化版):
程序开始运行
spiders将需要处理的网站URL交给引擎,引擎再将Requests请求交给调度器scheduler进行处理:后者将Requests请求按一定方式排列入队;
一定时间后(引擎要求取回Resquests)调度器将处理过的Requests交给引擎,引擎按照下载中间件downloader middlewares的设置要求将
Requests交给下载器downloader;下载器处理Requests(如果Requests下载失败,引擎会告诉调度器,让后者记录并在之后重新下载),下
载成功的Resquests可以捕获到相应的Responses;下载器将Responses(spider中间件处理过的)交给引擎,随后引擎将Responses交给spiders
处理;spiders处理Responses,将提取到的item字段数据交给itempipeline,同时将需要跟进的URL交给引擎,引擎再交给调度器,以此循环。
当调度器中不存在Requests请求时,程序运行结束
Scrapy项目实现步骤:
1.建立项目:
-在CMD下输入scrapy3 startproject item_name(项目名)
-cd item_name>>>scrapy3 genspider spider_name(spider名) domain_name(域名)
2.在items.py文件中定义字段,这些字段用来临时存储需要保存的数据(方便以后数据保存到数据库或本地)
3.在spider_name.py文件下编写爬虫脚本
4.在pipelines.py文件下保存数据
5.在settings.py文件下配置相关环境,这一步也不是必须做的
-将ROBOTSTXT_OBAY=True修改为ROBOTSTXT_OBAY=False(ROBOTSTXT协议规定哪些目录可以抓取)
-设置Requests头信息,取消注释行DEFAULT_REQUEST_HEADERS={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
-取消以下注释:Scrapy可以缓存已有的Requests,当再次请求时,如果存在缓存文档则返回缓存文档,而不用去网站请求,既可以加快本地缓存速度,也可以减轻网站压力

