

Blank_Model
银行风控模型
一、神经网络
代码:
1 import pandas as pd 2 import numpy as np 3 from sklearn.model_selection import train_test_split 4 datafile = 'bankloan2.xls' 5 data = pd.read_excel(datafile) 6 x = data.iloc[:,:8] 7 y = data.iloc[:,8] 8 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=100) 9 from tensorflow.keras.models import Sequential 10 from tensorflow.keras.layers import Dense,Dropout 11 from tensorflow.keras.metrics import BinaryAccuracy 12 import time 13 start_time = time.time() 14 model = Sequential() 15 model.add(Dense(input_dim=8,units=800,activation='relu')) 16 model.add(Dropout(0.5)) 17 model.add(Dense(input_dim=800,units=400,activation='relu')) 18 model.add(Dropout(0.5)) 19 # model.add(Dense(input_dim=800,units=400,activation='relu')) 20 # model.add(Dropout(0.5)) 21 # model.add(Dense(input_dim=400,units=200,activation='softsign')) 22 # model.add(Dropout(0.5)) 23 model.add(Dense(input_dim=400,units=1,activation='sigmoid')) 24 25 model.compile(loss='binary_crossentropy', optimizer='adam',metrics=[BinaryAccuracy()]) 26 model.fit(x_train,y_train,epochs=500,batch_size=128) 27 loss,binary_accuracy = model.evaluate(x,y,batch_size=128) 28 end_time = time.time() 29 run_time = end_time-start_time 30 print('模型运行时间:{}'.format(run_time)) 31 print('模型损失值:{}'.format(loss)) 32 print('模型精度:{}'.format(binary_accuracy)) 33 34 yp = model.predict(x).reshape(len(y)) 35 yp = np.around(yp,0).astype(int) #转换为整型 36 from cm_plot import * # 导入自行编写的混淆矩阵可视化函数 37 38 cm_plot(y,yp).show() # 显示混淆矩阵可视化结果
混淆矩阵可视化函数cm_plot.py
1 def cm_plot(y, yp): 2 3 from sklearn.metrics import confusion_matrix #导入混淆矩阵函数 4 5 cm = confusion_matrix(y, yp) #混淆矩阵 6 7 import matplotlib.pyplot as plt #导入作图库 8 plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。 9 plt.colorbar() #颜色标签 10 11 for x in range(len(cm)): #数据标签 12 for y in range(len(cm)): 13 plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') 14 15 plt.ylabel('True label') #坐标轴标签 16 plt.xlabel('Predicted label') #坐标轴标签 17 return plt
训练结果
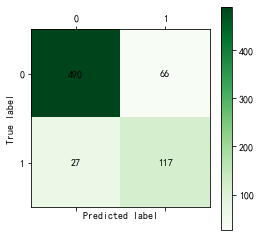
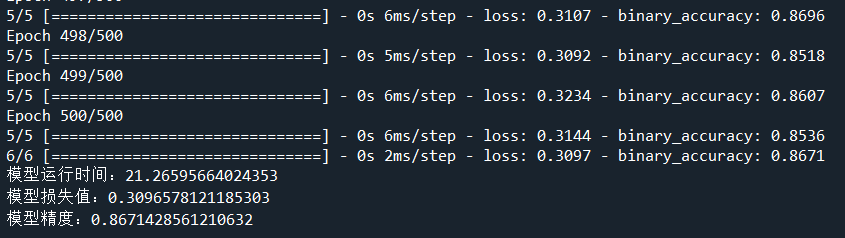
二、用支持向量机、决策树、随机森林方法训练
代码
import pandas as pd import time import numpy as np import seaborn as sns import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier as DTC from sklearn.ensemble import RandomForestClassifier as RFC from sklearn import svm from sklearn import tree from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.metrics import roc_curve, auc from sklearn.neighbors import KNeighborsClassifier as KNN #导入plot_roc_curve,roc_curve和roc_auc_score模块 from sklearn.metrics import plot_roc_curve,roc_curve,auc,roc_auc_score filePath = 'bankloan2.xls' data = pd.read_excel(filePath) x = data.iloc[:,:8] y = data.iloc[:,8] x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=100) #模型 svm_clf = svm.SVC() dtc_clf = DTC(criterion='entropy') rfc_clf = RFC(n_estimators=10) knn_clf = KNN() #训练 knn_clf.fit(x_train,y_train) rfc_clf.fit(x_train,y_train) dtc_clf.fit(x_train,y_train) svm_clf.fit(x_train, y_train) #ROC曲线比较 fig,ax = plt.subplots(figsize=(12,10)) rfc_roc = plot_roc_curve(estimator=rfc_clf, X=x, y=y, ax=ax, linewidth=1) svm_roc = plot_roc_curve(estimator=svm_clf, X=x, y=y, ax=ax, linewidth=1) dtc_roc = plot_roc_curve(estimator=dtc_clf, X=x, y=y, ax=ax, linewidth=1) knn_roc = plot_roc_curve(estimator=knn_clf, X=x, y=y, ax=ax, linewidth=1) ax.legend(fontsize=12) plt.show() #模型评价 rfc_yp = rfc_clf.predict(x) rfc_score = accuracy_score(y, rfc_yp) svm_yp = svm_clf.predict(x) svm_score = accuracy_score(y, svm_yp) dtc_yp = dtc_clf.predict(x) dtc_score = accuracy_score(y, dtc_yp) knn_yp = knn_clf.predict(x) knn_score = accuracy_score(y, knn_yp) score = {"随机森林得分":rfc_score,"支持向量机得分":svm_score,"决策树得分":dtc_score,"K邻近得分":knn_score} score = sorted(score.items(),key = lambda score:score[0],reverse=True) print(pd.DataFrame(score)) #中文标签、负号正常显示 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False #绘制混淆矩阵 figure = plt.subplots(figsize=(12,10)) plt.subplot(2,2,1) plt.title('随机森林') rfc_cm = confusion_matrix(y, rfc_yp) heatmap = sns.heatmap(rfc_cm, annot=True, fmt='d') heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right') heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right') plt.ylabel("true label") plt.xlabel("predict label") plt.subplot(2,2,2) plt.title('支持向量机') svm_cm = confusion_matrix(y, svm_yp) heatmap = sns.heatmap(svm_cm, annot=True, fmt='d') heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right') heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right') plt.ylabel("true label") plt.xlabel("predict label") plt.subplot(2,2,3) plt.title('决策树') dtc_cm = confusion_matrix(y, dtc_yp) heatmap = sns.heatmap(dtc_cm, annot=True, fmt='d') heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right') heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right') plt.ylabel("true label") plt.xlabel("predict label") plt.subplot(2,2,4) plt.title('K邻近') knn_cm = confusion_matrix(y, knn_yp) heatmap = sns.heatmap(knn_cm, annot=True, fmt='d') heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right') heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right') plt.ylabel("true label") plt.xlabel("predict label") plt.show() #画出决策树 import pandas as pd from sklearn.tree import export_graphviz x = pd.DataFrame(x) with open(r"banklodan_tree1.dot", 'w') as f: export_graphviz(dtc_clf, feature_names = x.columns, out_file = f) f.close() from IPython.display import Image from sklearn import tree import pydotplus dot_data = tree.export_graphviz(dtc_clf, out_file=None, #regr_1 是对应分类器 feature_names=x.columns, #对应特征的名字 class_names= ['不违约','违约'], #对应类别的名字 filled=True, rounded=True, special_characters=True)
结果
(1)混淆矩阵
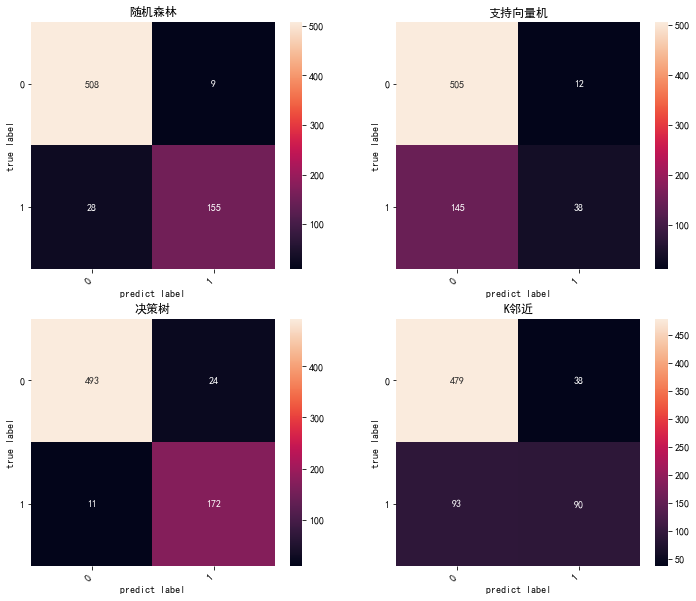
(2)ROC曲线
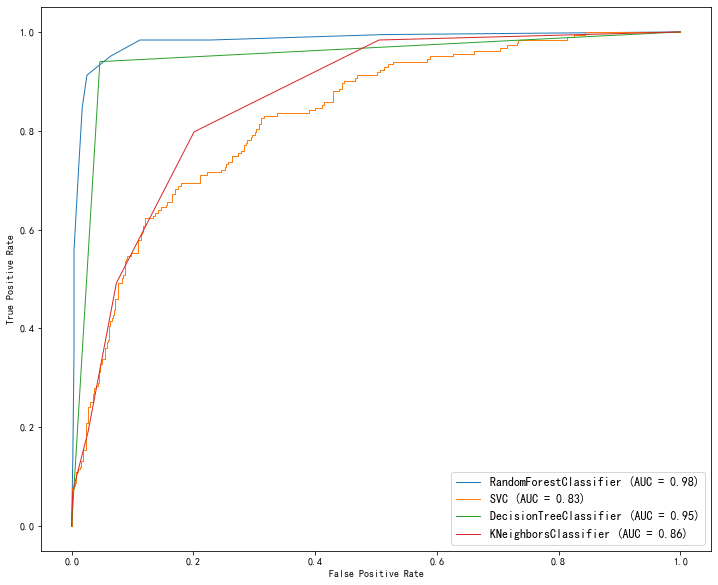
(3)

