数据科学家周暐:「数」中自有黄金屋——大数据的价值提升
编者按:
10 月 20 日晚,「七牛云 Niu Talk 」 数据科学系列论坛第二期如期举行。活动中,七牛云数据科学家周暐为我们带来了主题为《大数据价值提升的技术与实践》的主题演讲。从金矿开采引申到数据挖掘,围绕「大数据的特点」、「数据与模型」、「价值提升的案例」三个方面,深入浅出地为我们分享了他「沙里淘金」的经验。以下是演讲实录。
嘉宾简介
周暐,七牛云数据科学家,拥有 20 多年的工作经验,长期在全球知名的高科技企业工作。目前主要负责在国内推广和实施基于先进机器数据平台的大数据分析解决方案。

今天为大家带来的演讲主题是《大数据价值提升的技术与实践》,首先我想和大家分享我的一次旅行故事。我参观的是在宝岛台湾的一个小众景点,叫做「黄金博物馆」,它是在一座废弃的金矿上建成的。其中有珠光宝气、金碧辉煌的场景,但给我留下最深刻印象的,是其中展示了黄金生产链上的各个环节。其中有一个非常打动我的点,就是在一吨的金矿石里,仅仅能开采出三到四克的黄金,这样的比例其实是非常少的,甚至低于中彩票。
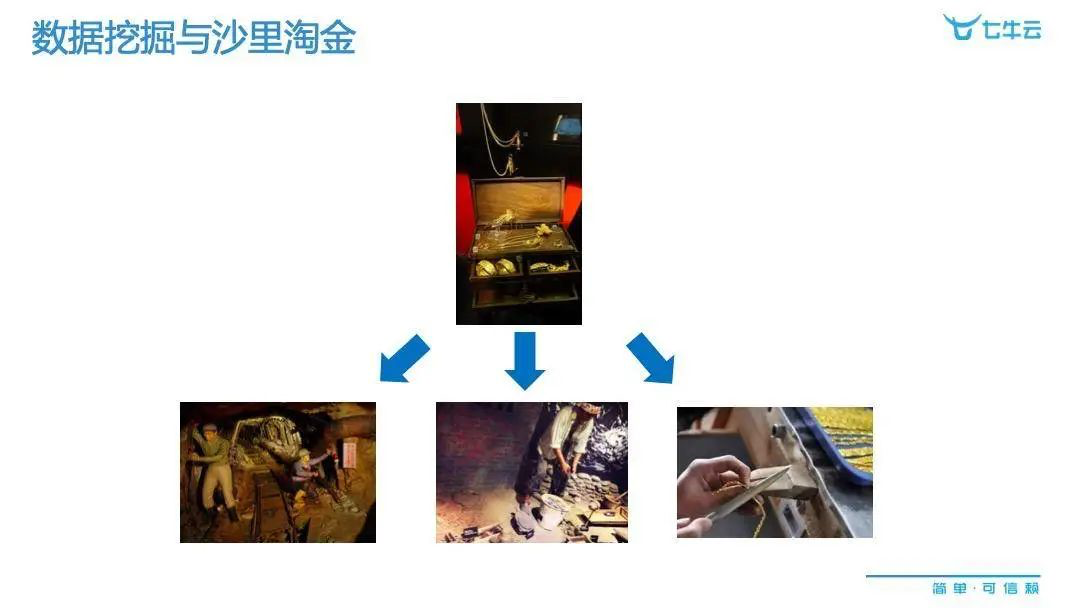
可能是出于职业敏感,我顿时就联想到了平时数据挖掘的过程,其实和沙里淘金非常相似。大家都知道现在已经进入到了大数据的时代,我们身边不少有数据,但是真正的能够从大数据里面去得到有益价值的人,好像不是那么多,真正到能够享受到其中乐趣的人,就更是少数了。那么今天我就围绕「大数据的特点」、「数据与模型」、「价值提升的案例」三个方面,和大家分享我「沙里淘金」的经验。
大数据的特点
大数据的特征可以概括为「4 个 V」:体量大、形态多、速度快、不准确。里面其实是没有 value 这个词的,如果一定要加第 5 个「V」 的话,我觉得也应该是一个低密度的「V」(value)。也就是说如果处理不当,数据是有它的两面性,就是因为我们不能很方便、很快速地从中能够把它的价值提取出来。
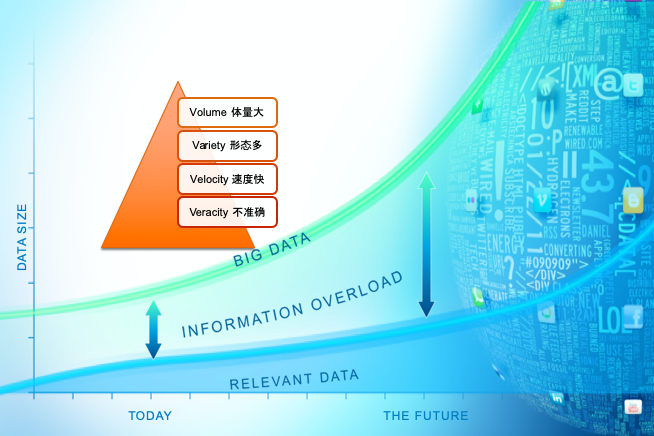
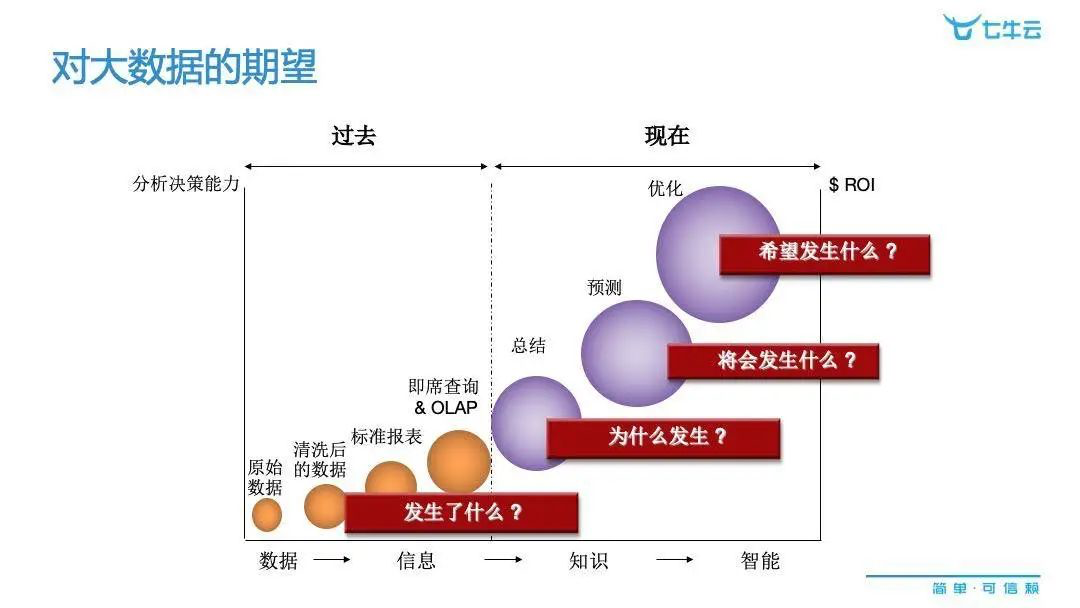
在现如今,无论是个人还是企业,对大数据的期望越来越高。经常有人跟我说,我们公司现在已经存储很多数据,那么你们能不能帮助我们做点什么,把它的价值发挥出来。实际很多公司在大数据方面并不是一张白纸,已经在做很多事了,比如数据的采集工作、清洗工作、存储工作,甚至开发出了一些成熟的可视化的报表,能够做一些快速的查询。
但以上种种,都属于过去阶段。现在我们对大数据的期望其实会变得更高,不仅仅期待它能够汇总过去发生的,还能告诉我们未来会发生什么。因为一旦有了对未来的预测,我们才真正成为数据的拥有者,真正掌握数据的价值。
数据与模型
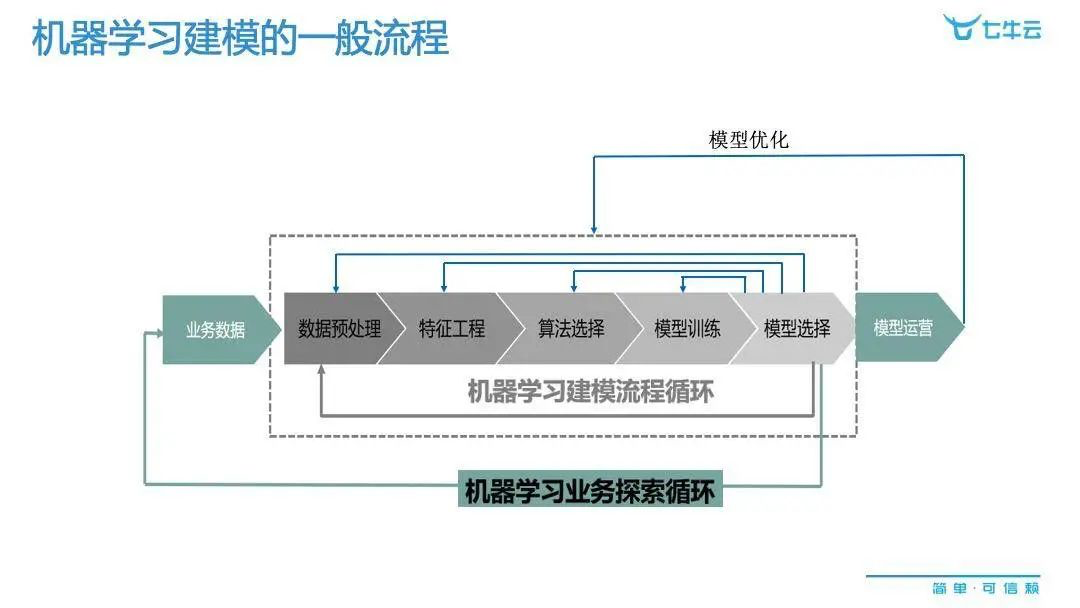
所以这一切的关键——无论是矿里采金、原油提炼,还是数据挖掘——就是要做一道工艺,这个工艺其实从大的方向讲就是为了两个字:模型。但是整个建模的过程,其实可以细分成很多的子过程。
说起模型,首先要和大家明确一下定义,因为这个词实在是太容易引发误解。举个简单的例子,比如我们说起 car model 的时候大家会想起什么?下图的两个画面,相信会分别浮现在不同人的脑海中。

甚至还有的人联想出、对应出更多的「car model」,所以我们会发现,不仅我们说「car model」会有多种理解,说起 data model 就更能引发争议了。
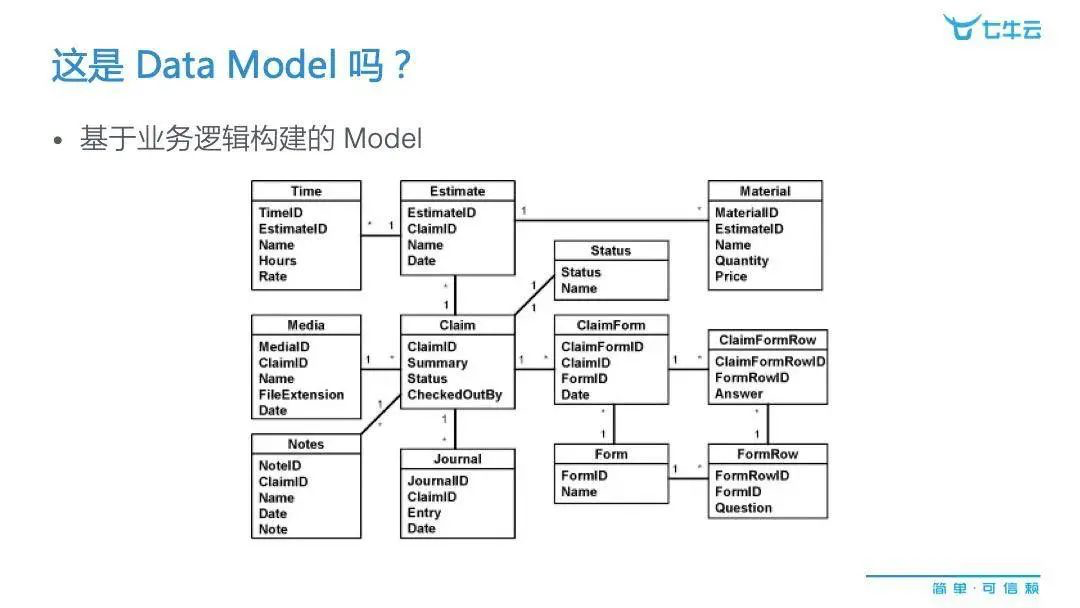
比如在工作中我们需要提炼出 data model,我的同事就跟我说我已经提炼出来了,但当我们细聊下去,我才发现其实他所谓的 model 是下图这样的一个表格。做数据库相关工作的人应该会很熟,基于这个表中的关联性,我们可以串起很多相关的表格,然后构建成一个大框架,从而做增、删、改、查等相关工作,这当然是很有价值的,但却不是我想要讲的「data model」。
我想讲的是基于机器学习构建的 model。它的应用场景,确实就像是那些拥有很多数据的企业追求的一样。在我们不知道数据发生机理的情况下,我们可以用一种黑箱的模式来表示。黑箱的左侧就是一串变量,我们可以把它作为输入变量,黑箱的右侧就是一个结果变量,我们可以把它叫做 response 或者是 output 。
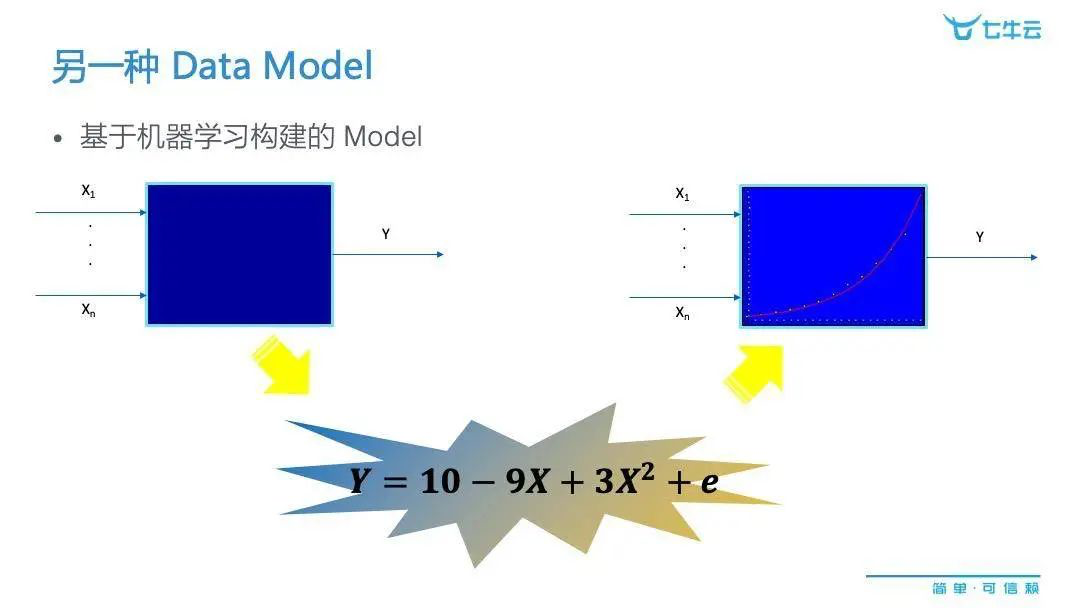
这样的黑箱可以发生在各种场景,它可能是生产的流程、管理的进程、市场的活动,甚至是一次用户对产品的体验。但是最终都会产生一个结果,我们就寻找输入因素对最终结果的影响关系是什么。我们可以把大量、真实具有代表性的数据,放到专门的机器学习工具模型里跑,可能就会得出这样的一个结果来。有了这个表达式,其实我们就可以更加方便、可视化地把 x 和 y 之间的关系给表达出来。那么这样一来,我们刚才的黑箱也就不再是黑箱,而变成了我们能够知道内部机理的白箱了。
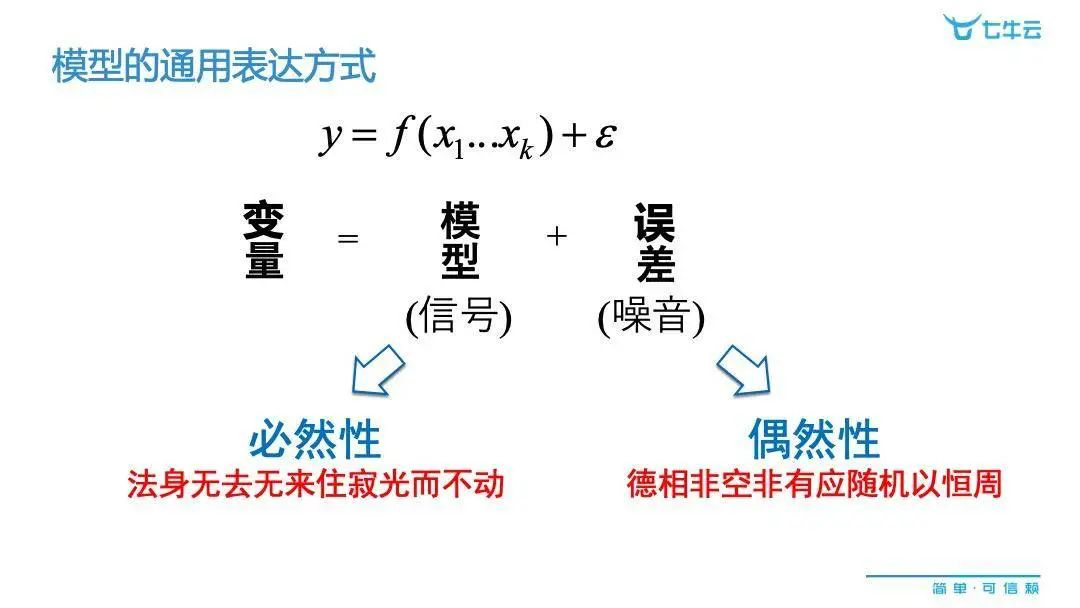
但是请各位务必注意,这样建设的模型是有误差的。所以我们想真正提炼出的 data model,其实可以用下图的表达式来表示,也就是说既有含信号的部分,但也不可避免地存在噪音部分。这样的偶然性和必然性,可谓是「法身无去无来住寂光而不动,德相非空非有应随机以恒周」。
我们所追求的这种模型,很多人会和另外一种模型混淆。比如以下这些很经典的公式,它们在很多领域都有很基础的应用。但是这些公式是通过机器学习的方法提炼出来的吗?显然不是。

这里就涉及「机理模型」的概念。一般来讲,机理模型是不需要基于历史数据来做挖掘的,它是通过一些专业模型产生的。其实这是我们最理想化的一类模型,因为它的特点是没有误差,而且从机理上能够解释透彻。现如今,我们有大量的历史数据,从中我们可以提炼出一些和机理模型相类似的表达式。虽然有误差,但如果这个误差控制在很小的范围,那么它还是有很大的实际应用意义的,这也是相对来说,可以做到的一件事。

那么怎样能够在有大量历史数据的情况下,提炼出机器学习的模型,来进一步帮助我们做实际应用呢?
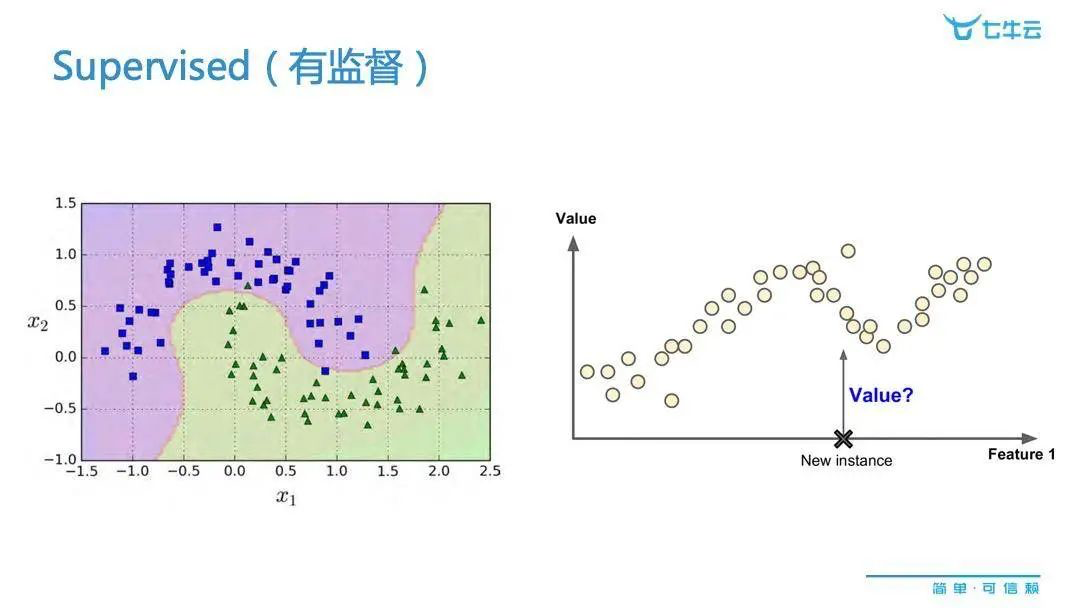
而在此之前,可能很多人会问:到底 data model 分哪些种类,又有哪些技术类别呢?按照主流的方向,可以大致分以下几类。比如对最常用的机器学习的语言来讲,就可以把它分为监督机器学习方法模型以及非监督机器学习方法模型。它们的区别在于,如果是有监督的话,也就是说明我们的数据里面往往是自带结果变量,反之则没有。从数学的角度讲自带结构变量,我们可以在下图看到,比如已知数据 x1 和 x2,它就自带三角形或者方形的标签,这是数学上的意义,它实际上可能代表一个产品的 合格情况,申请贷款批准与否,这些都可以说是有监督型的机器学习方法里,可以用到的常用的场景。
那么下图右边和左边最大的区别是什么?其实右图也是有结果变量,但相比于左边的偏离散型数据,右边是偏连续性的结果。以刚才银行审批贷款为例,我们就不但可以预测一个用户他申请贷款是否被批准,同时我们还可以预测他能收获的贷款额度。
另一种场景就是无监督的机器学习方法模型,它应用的场景往往没有结果变量。比如一条数据、一个客户的基本信息,或者一个有成千上万个种类的产品,我们如何对他们「物以类聚,人以群分」?其实这个原则很简单,那就是组内的差异一定要尽可能小,但是组间的差异要尽可能大。这是个大的方向,具体怎么样才能达到效果,无监督的很多算法来帮助我们做这种事,它可以帮助我们把看似很大量的不同类别,归纳成少数几类,并提取特征。
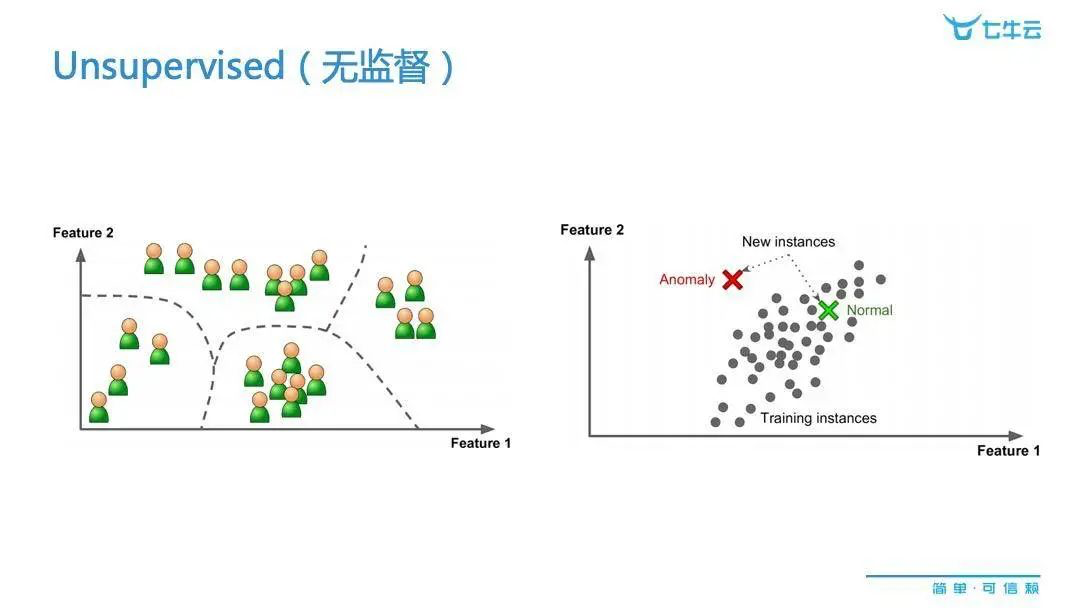
上图中的右侧,是另外一种无监督的应用——异常值检测。其实我们可以把异常值检测看作是一种特殊的聚类。一类就是正常,一类就是异常。它的特点就是往往异常的种类的数量比较少,而正常的比例的数量会绝对比较大。
聚类的方式可以分为几类,每一类的比例大小没有什么具体的限制。那么像右边这种异常检测,就有很多现实应用。还是以银行为例,我们可以通过这种异常检查去筛查参与信用欺诈、洗钱等行为的异常客户。
总之我们可以根据实际问题,把要分析的业务问题转化成数学问题,基于它我们就有很多的工具和方法可以使用了。然后最终不要忘了把它再转换成一个具有业务意义的答案,整个过程就能达到从大数据里提取价值的一个目的。
如果对算法感兴趣,下面有两个经典算法可以和大家分享。
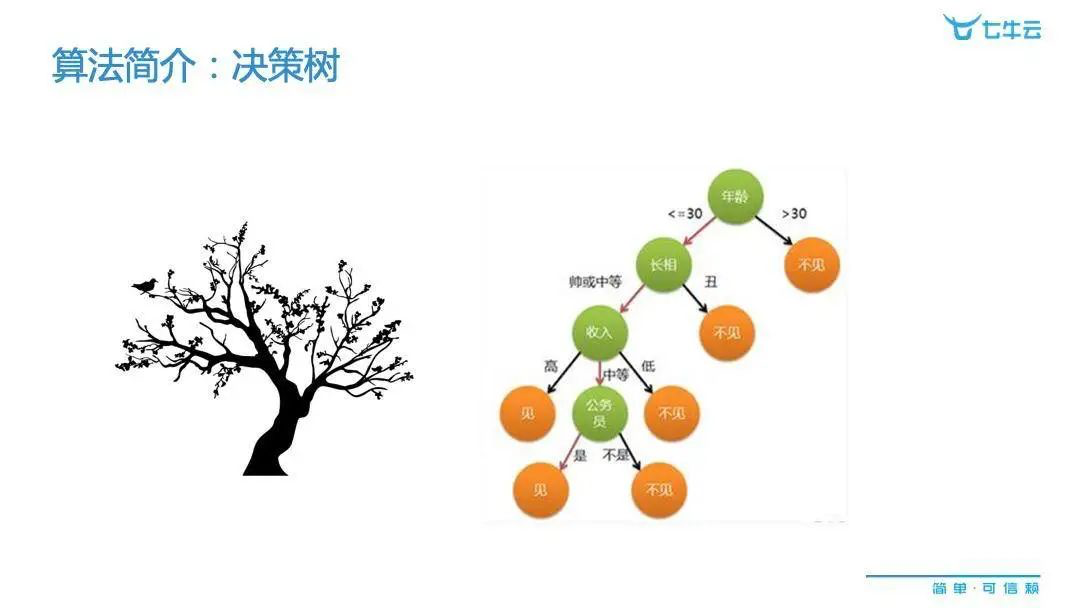
第一种是决策树,就是在监督型这个机器学里面常用的一种算法。它其实有很广泛的应用。比如在交友网站中,如果网站的主要任务是为会员介绍对象,提高速配成功率的话,那么可以怎样推荐?其实我们对会员做一些历史数据的挖掘,往往就能得到这样的结果。比如影响一个人是否和愿意和某个对象进行交往的因素有很多,但是通过决策树的算法,我们就可以提炼出像这一类会员是对哪些因素比较看重的。基于真实的历史的数据,其实我们就可以把一个人看似无序决策过程,用非常有逻辑性的方式表达出来。
另外一种算法是 ARIMA,这也是在经济、生产中,只要有持续性的数据就都可能会用得到的一种算法。它是用于实际数据分析的。比如下图是中国在过去几十年中,发生水灾受灾面积的一个时间序列图。
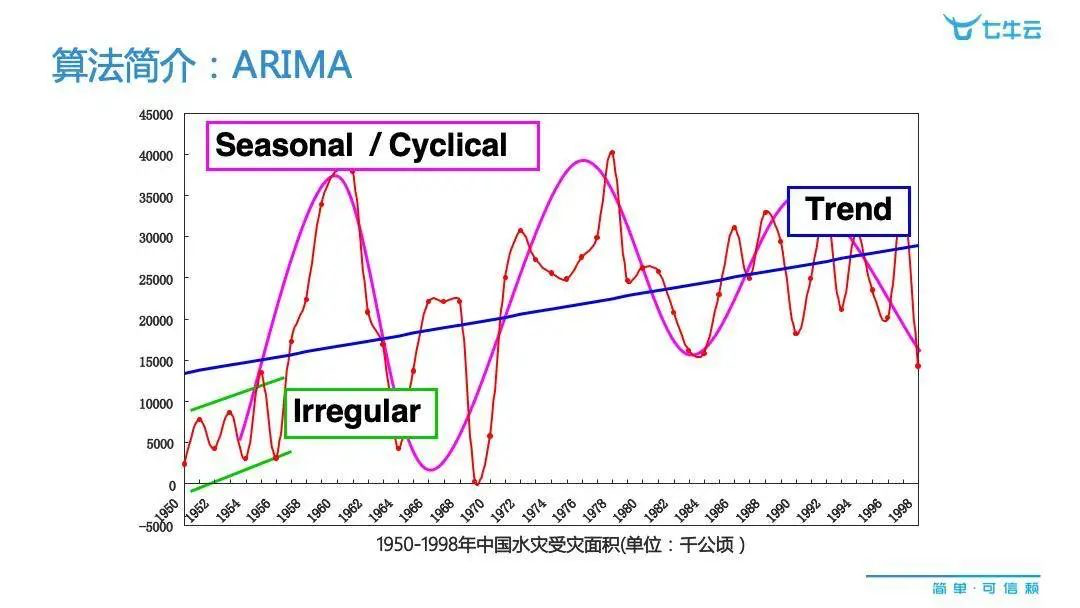
比如说我们要预测下一个年度中国整个国家发生水灾的受灾面积,可能很多人会有一些自己的想法,但 ARIMA 是一种自动化的算法。我们感觉上表面上看整个过程好像没有什么太多规律,但如果我们仔细关注一下的话,就会发现数据有一定的特点。把其中的趋势性、周期性以及不规则性,尽可能用一些函数的形式表达出来并进行整合,这样一来我们就能有一个更精确的预测,帮助我们做很多前瞻性的工作。
价值提升的案例
以上类似的方法还有很多,下面我想用更实际的应用来进行说明,通过结合实际业务,来做通用的流程,由此产生真正的商业价值。
下图可能会引起大家玩「捕鱼游戏」的回忆,那么我们就举一个关于游戏的例子。这是七牛云数据科学分析团队和客户一起合作,通过数据挖掘的方式,来真正发现游戏玩家的一些行为规律。

说起这种游戏运营,大家肯定会有一些经验,比如通过下图这样的留存率分析来发现其中变化,如果发生了降低的趋势,就要采取方法,做一些市场策略的改进。
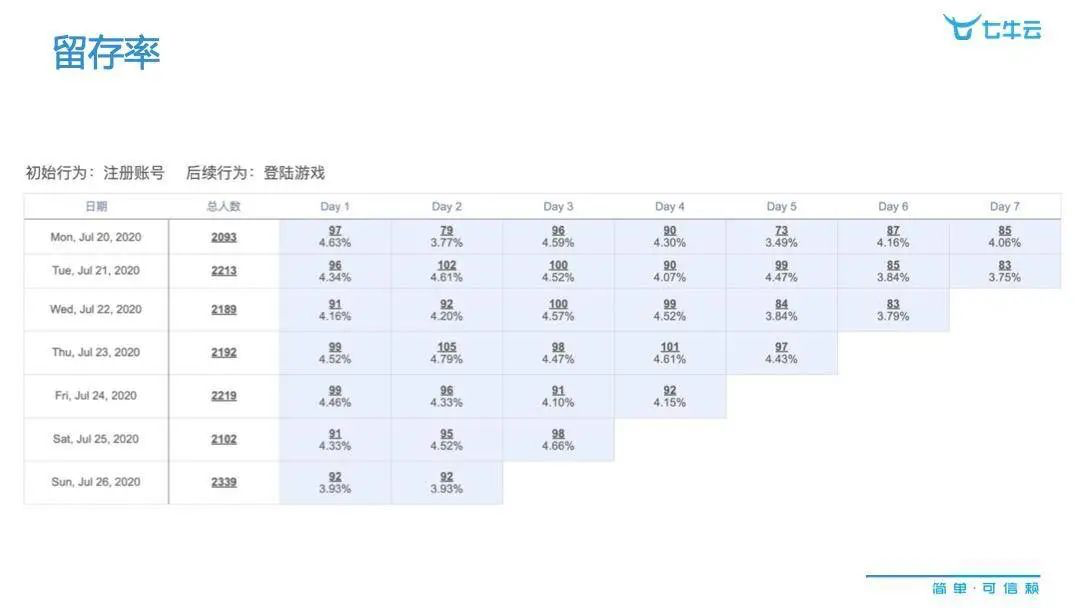
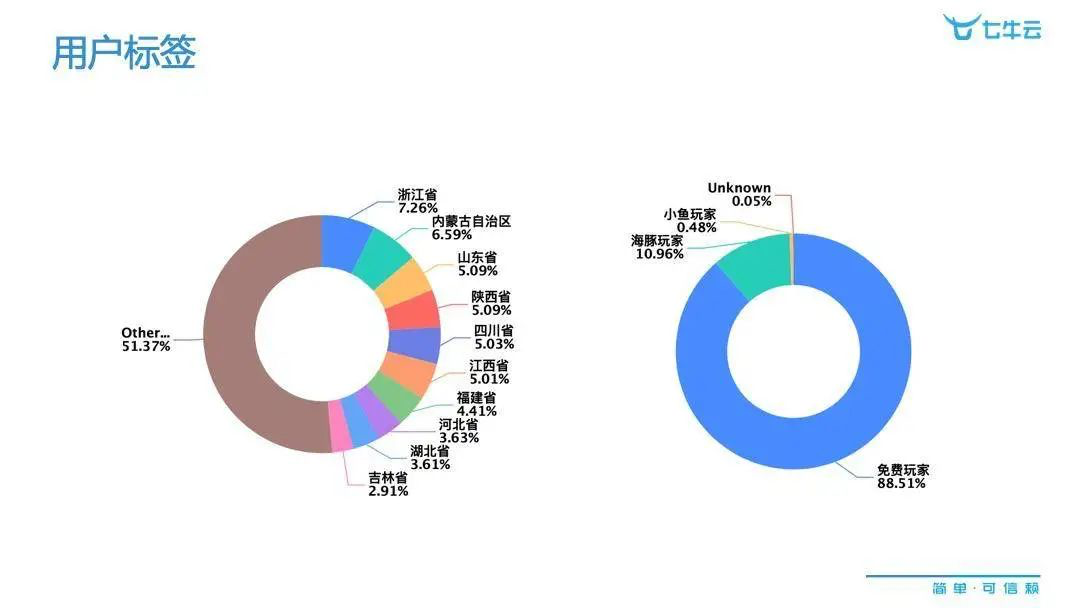
市场策略改进怎么改呢?往往大家会想到用户标签,比如下图这种标签是相对简单的,可以从一维的角度得到,比如说不同地区、不同额度的付费等,来找到不同的细分市场,基于不同的细分市场来做改进,这是一种策略。但其实这种方法,大部分的游戏运营公司早就用过,到了一定的程度之后,就会发现有一段无法跨越的瓶颈。
这时候就需要做一些更深层次的分析,也就是说我们不仅仅要用一些简单的属性数据,还要关注他的行为数据。我们先从业务的特性入手,根据游戏行业的特点,比如说抽奖的行为、参加比赛的行为、使用道具的行为、使用不同种类炮台的行为,以及最终击中目标的一些行为数据等等。

根据各种行为的重要性,甚至我们还考虑了心理学的因素来进行提炼,得出了至少有十几个维度的特征变量,我们把这些变量特征,放到我们的机器学习的工具平台里跑了一遍。
最终,我们真的发现它可以分成相关的少数几类,并且我们发现有几个变量对我们的聚类分析,产生了重要的影响。
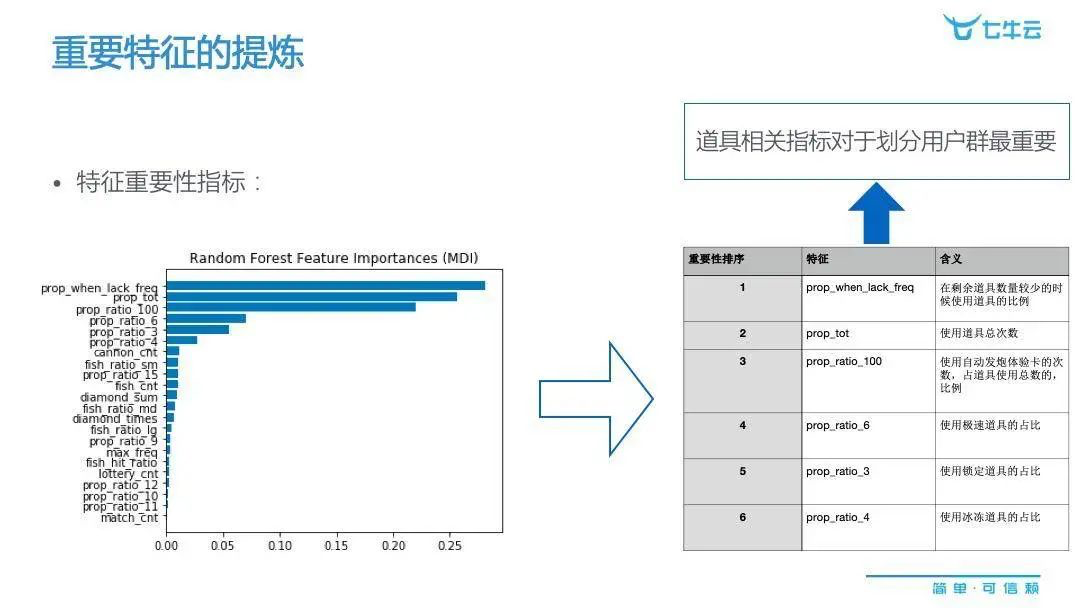
下面这张图就体现了变量的关键性,而且是不同用户分群的一个显著特征。
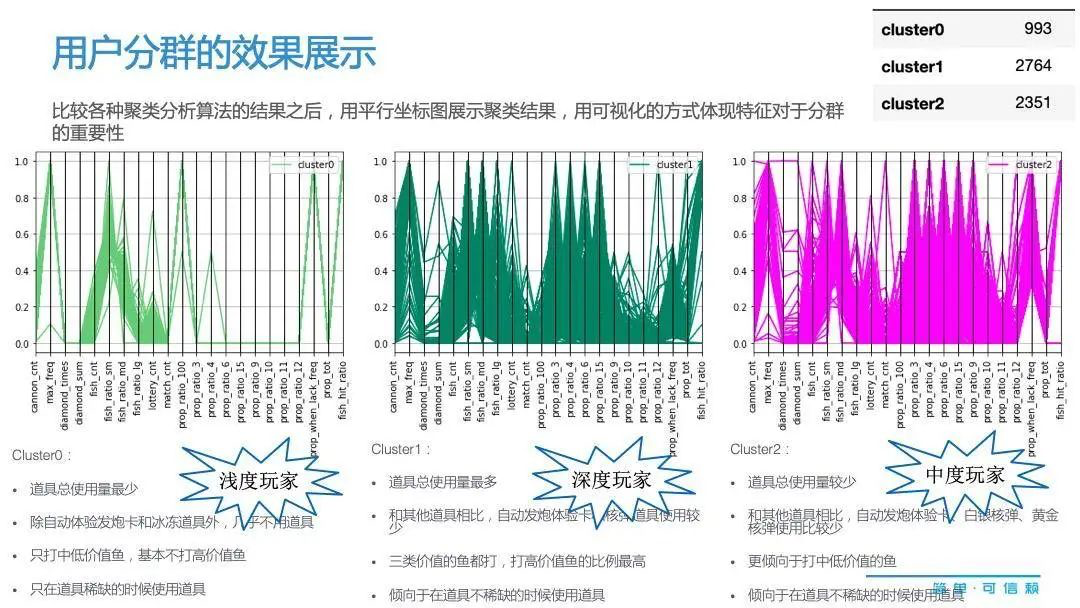
在这张平行坐标图中,它的每一个 x 轴基本上就显示了我们刚才提到的行为特征。比如图中的第一类客户,他的明显特征行为是很多变量为 0,意味着它的道具使用量最少。第二类用户就没有明显为 0 的那些变量,道具的使用频率也是相当高,还有很多地方分布很宽,证明各种各样的鱼都是他们的目标。第三种用户的特征,就处于前两者的中间状态。
通过这样的分析,我们可以发现第一类其实就是浅度玩家,而中间这种,是很多游戏公司最喜欢的深度玩家,而第三种就是两者之间的中度玩家。由此,我们可以给游戏市场做了一个非常有技术含量、有技术价值的深度标签。通过标签识别,我们可以更深层次地对客户进行细分,然后进行相关的市场营销策略。
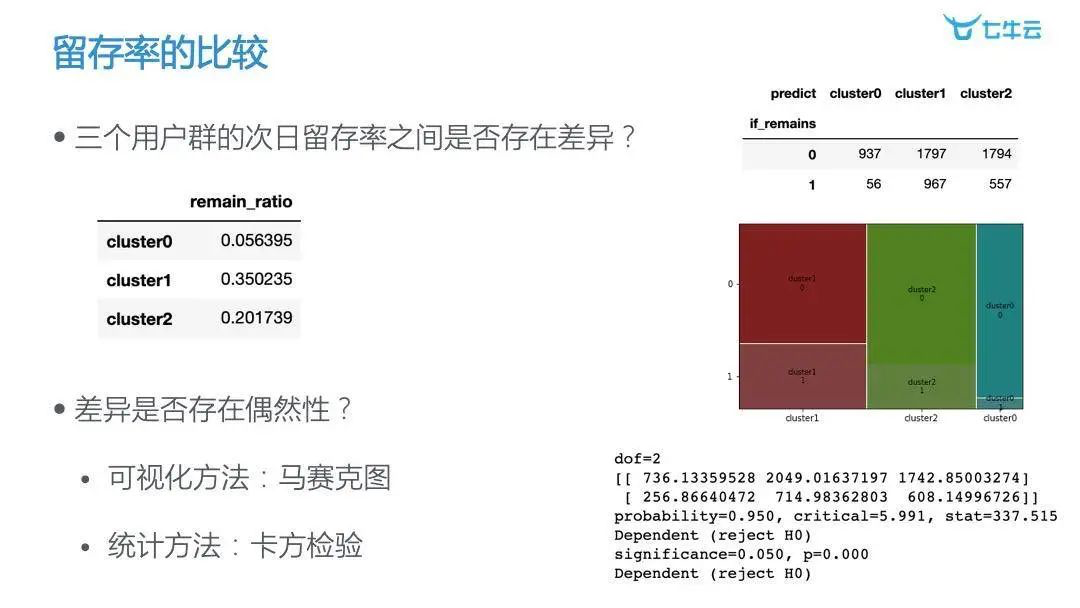
如此一来,得到的效果非常惊人。通过下图我们可以看出,浅度玩家的次月留存率只有 5%,远远低于深度玩家 35%。也就是说,我们能够真正找到那些深度玩家类别,然后想方设法去影响他们的一些特质。对于第一类和第三类的用户市场,我们也很有把握去进一步提升留存率。
以上就是我们在互联网行业的一个应用。最终我想化用一句咱们的古话,来为分享做一个总结:「数中自有黄金屋」。我们也非常愿意和更多合作伙伴一起,一起运用数据来「炼数成金」!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号