爬取伯乐在线文章(二)通过xpath提取源文件中需要的内容
讨论QQ:1586558083
正文
爬取说明
以单个页面为例,如:http://blog.jobbole.com/110287/
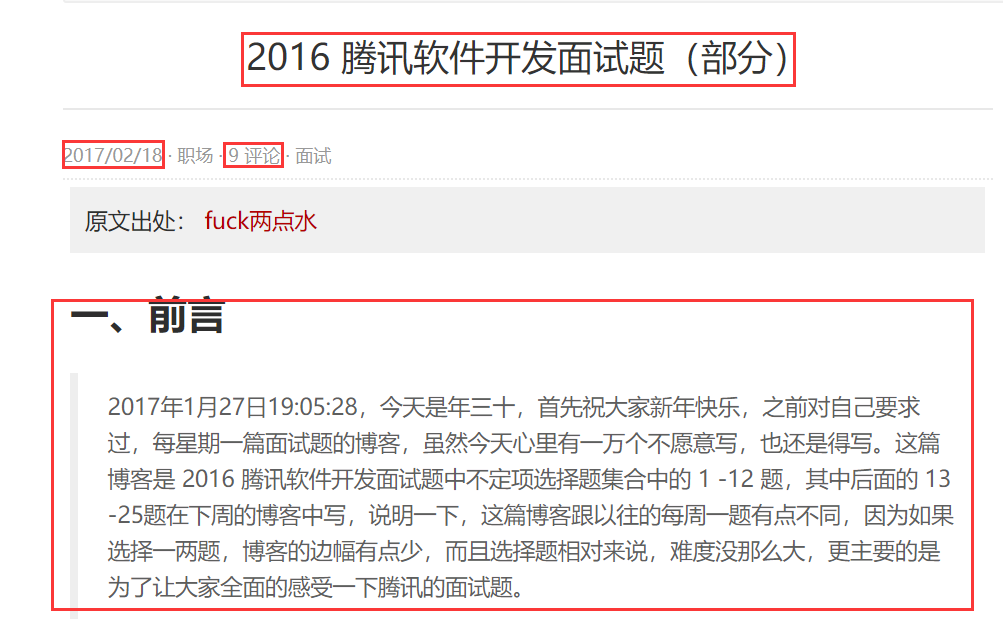
我们可以提取标题、日期、多少个评论、正文内容等
Xpath介绍
1. xpath简介
(1) xpath使用路径表达式在xml和html中进行导航
(2) xpath包含标准函数库
(3) xpath是一个w3c标准
2. Xpath的节点关系
(1) 父节点
(2) 子节点
(3) 同胞节点
(4) 先辈节点
(5) 后代节点
3. Xpath语法



开始爬取
1. 将starts_urls修改为http://blog.jobbole.com/110287/
2. def parse(self, response)方法中的response自带有xpath方法
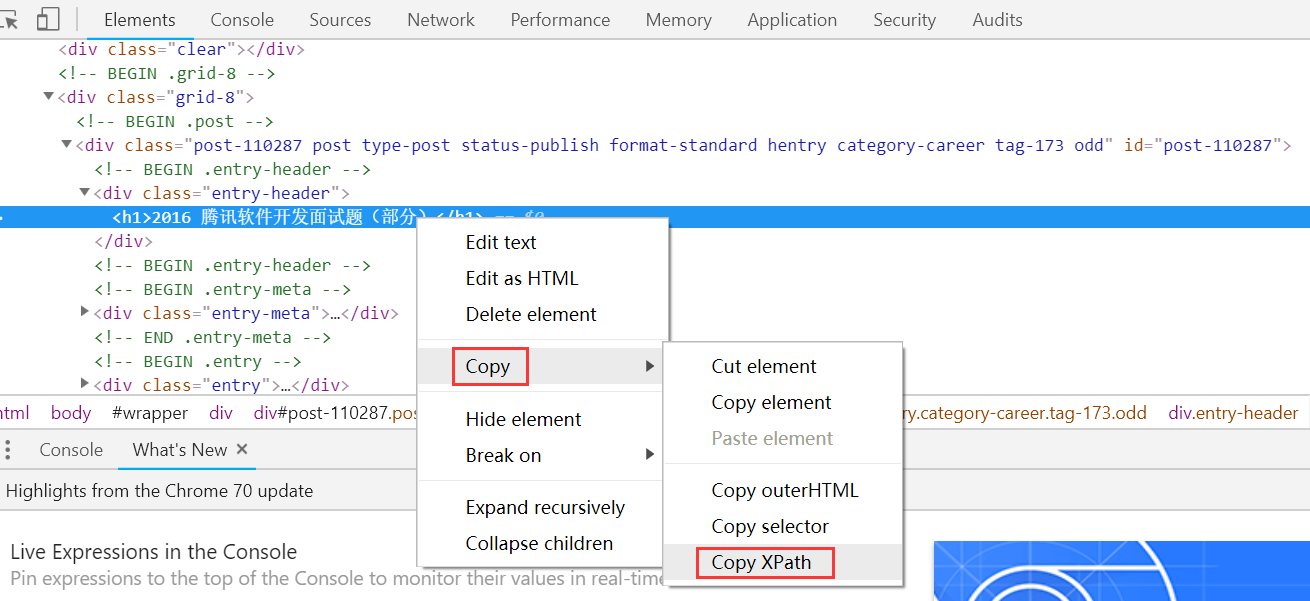
结果为://*[@id="post-110287"]/div[1]/h1
在parse方法里面进行解析:
#业务逻辑 def parse(self, response): title_selector = response.xpath('//*[@id="post-110287"]/div[1]/h1') pass
断点查看返回的title_selector的类型是SelectorList,里面存放的是一个selector,为什么不直接返回一个node类型,这是因为我们获取的h1下面可能还有很多层,我们可以进一步的做xpath筛选,直接返回node的话就无法做xpath筛选,所以scrapy做了进一步的封装,可以让我们进一步进行xpath筛选。

我们可以看到data里面的值是一个h1标签,我们可以直接调用一个text()函数获取里面的值,如下
title_selector = response.xpath('//*[@id="post-110287"]/div[1]/h1/text()')
此时在看data里面值就是我们需要的内容了

调试Xpath
在scarpy里面进行调试是比较慢的,scrapy提供了一种shell模式,可以在里面对某个URL进行调试,如下在cmd里面
(scrapyenv) E:\Python\Envs\EnterpriseSpider>scrapy shell http://blog.jobbole.com/110287/



(scrapyenv) E:\Python\Envs\EnterpriseSpider>scrapy shell http://blog.jobbole.com/110287/ 2018-11-05 10:14:15 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: EnterpriseSpider) 2018-11-05 10:14:15 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0i 14 Aug 2018), cryptography 2.3.1, Platform Windows-10-10.0.17134-SP0 2018-11-05 10:14:15 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'EnterpriseSpider', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'EnterpriseSpider.spiders', 'SPIDER_MODULES': ['EnterpriseSpider.spiders']} 2018-11-05 10:14:15 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole'] 2018-11-05 10:14:15 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 2018-11-05 10:14:15 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 2018-11-05 10:14:15 [scrapy.middleware] INFO: Enabled item pipelines: [] 2018-11-05 10:14:15 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 2018-11-05 10:14:15 [scrapy.core.engine] INFO: Spider opened 2018-11-05 10:14:15 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.jobbole.com/110287/> (referer: None) [s] Available Scrapy objects: [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc) [s] crawler <scrapy.crawler.Crawler object at 0x000002C00C180080> [s] item {} [s] request <GET http://blog.jobbole.com/110287/> [s] response <200 http://blog.jobbole.com/110287/> [s] settings <scrapy.settings.Settings object at 0x000002C00E7DD898> [s] spider <JobboleSpider 'jobbole' at 0x2c00ea8b160> [s] Useful shortcuts: [s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed) [s] fetch(req) Fetch a scrapy.Request and update local objects [s] shelp() Shell help (print this help) [s] view(response) View response in a browser >>>
使用如下

获取data里面值可以用Selector的extract方法,返回的是一个数组

在获取数组里面的第一个值就可以获取我们需要的内容



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决