爬取伯乐在线文章(一)
讨论QQ:1586558083
正文
Scrapy生成的项目目录

文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
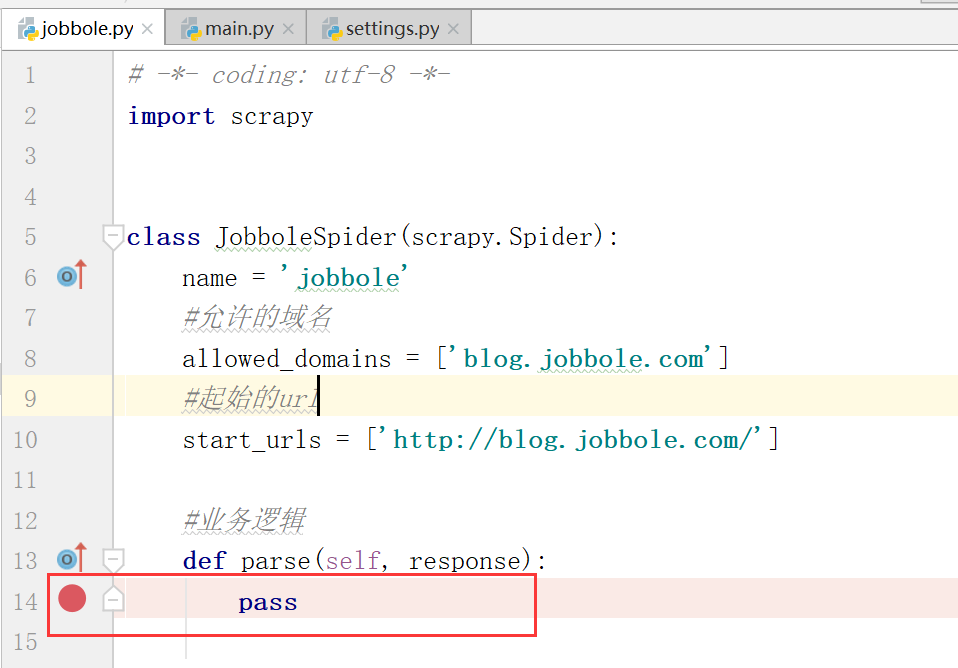
jobbole.py

# -*- coding: utf-8 -*- import scrapy class JobboleSpider(scrapy.Spider): name = 'jobbole' #允许的域名 allowed_domains = ['blog.jobbole.com'] #起始的url,是一个list,可以放入所有要爬取的URL start_urls = ['http://blog.jobbole.com/'] #业务逻辑 def parse(self, response): pass
设置断点模式
在scrapy.cfg文件同级目录下建立main.py文件,内容如下
# -*- coding: utf-8 -*- import sys import os from scrapy.cmdline import execute sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(['scrapy', 'crawl', 'jobbole'])
启动爬虫
启动爬虫命令:
scrapy crawl jobbole


(scrapyenv) E:\Python\Envs\EnterpriseSpider>scrapy crawl jobbole 2018-11-05 09:03:32 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: EnterpriseSpider) 2018-11-05 09:03:32 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0i 14 Aug 2018), cryptography 2.3.1, Platform Windows-10-10.0.17134-SP0 2018-11-05 09:03:32 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'EnterpriseSpider', 'NEWSPIDER_MODULE': 'EnterpriseSpider.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['EnterpriseSpider.spiders']} 2018-11-05 09:03:32 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.logstats.LogStats'] Unhandled error in Deferred: 2018-11-05 09:03:32 [twisted] CRITICAL: Unhandled error in Deferred: Traceback (most recent call last): File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\crawler.py", line 171, in crawl return self._crawl(crawler, *args, **kwargs) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\crawler.py", line 175, in _crawl d = crawler.crawl(*args, **kwargs) File "e:\python\envs\scrapyenv\lib\site-packages\twisted\internet\defer.py", line 1613, in unwindGenerator return _cancellableInlineCallbacks(gen) File "e:\python\envs\scrapyenv\lib\site-packages\twisted\internet\defer.py", line 1529, in _cancellableInlineCallbacks _inlineCallbacks(None, g, status) --- <exception caught here> --- File "e:\python\envs\scrapyenv\lib\site-packages\twisted\internet\defer.py", line 1418, in _inlineCallbacks result = g.send(result) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\crawler.py", line 80, in crawl self.engine = self._create_engine() File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\crawler.py", line 105, in _create_engine return ExecutionEngine(self, lambda _: self.stop()) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\core\engine.py", line 69, in __init__ self.downloader = downloader_cls(crawler) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\core\downloader\__init__.py", line 88, in __init__ self.middleware = DownloaderMiddlewareManager.from_crawler(crawler) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\middleware.py", line 58, in from_crawler return cls.from_settings(crawler.settings, crawler) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\middleware.py", line 34, in from_settings mwcls = load_object(clspath) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\utils\misc.py", line 44, in load_object mod = import_module(module) File "e:\python\envs\scrapyenv\lib\importlib\__init__.py", line 126, in import_module return _bootstrap._gcd_import(name[level:], package, level) File "<frozen importlib._bootstrap>", line 994, in _gcd_import File "<frozen importlib._bootstrap>", line 971, in _find_and_load File "<frozen importlib._bootstrap>", line 955, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 665, in _load_unlocked File "<frozen importlib._bootstrap_external>", line 678, in exec_module File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\downloadermiddlewares\retry.py", line 20, in <module> from twisted.web.client import ResponseFailed File "e:\python\envs\scrapyenv\lib\site-packages\twisted\web\client.py", line 41, in <module> from twisted.internet.endpoints import HostnameEndpoint, wrapClientTLS File "e:\python\envs\scrapyenv\lib\site-packages\twisted\internet\endpoints.py", line 41, in <module> from twisted.internet.stdio import StandardIO, PipeAddress File "e:\python\envs\scrapyenv\lib\site-packages\twisted\internet\stdio.py", line 30, in <module> from twisted.internet import _win32stdio File "e:\python\envs\scrapyenv\lib\site-packages\twisted\internet\_win32stdio.py", line 9, in <module> import win32api builtins.ModuleNotFoundError: No module named 'win32api' 2018-11-05 09:03:32 [twisted] CRITICAL: Traceback (most recent call last): File "e:\python\envs\scrapyenv\lib\site-packages\twisted\internet\defer.py", line 1418, in _inlineCallbacks result = g.send(result) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\crawler.py", line 80, in crawl self.engine = self._create_engine() File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\crawler.py", line 105, in _create_engine return ExecutionEngine(self, lambda _: self.stop()) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\core\engine.py", line 69, in __init__ self.downloader = downloader_cls(crawler) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\core\downloader\__init__.py", line 88, in __init__ self.middleware = DownloaderMiddlewareManager.from_crawler(crawler) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\middleware.py", line 58, in from_crawler return cls.from_settings(crawler.settings, crawler) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\middleware.py", line 34, in from_settings mwcls = load_object(clspath) File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\utils\misc.py", line 44, in load_object mod = import_module(module) File "e:\python\envs\scrapyenv\lib\importlib\__init__.py", line 126, in import_module return _bootstrap._gcd_import(name[level:], package, level) File "<frozen importlib._bootstrap>", line 994, in _gcd_import File "<frozen importlib._bootstrap>", line 971, in _find_and_load File "<frozen importlib._bootstrap>", line 955, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 665, in _load_unlocked File "<frozen importlib._bootstrap_external>", line 678, in exec_module File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed File "e:\python\envs\scrapyenv\lib\site-packages\scrapy\downloadermiddlewares\retry.py", line 20, in <module> from twisted.web.client import ResponseFailed File "e:\python\envs\scrapyenv\lib\site-packages\twisted\web\client.py", line 41, in <module> from twisted.internet.endpoints import HostnameEndpoint, wrapClientTLS File "e:\python\envs\scrapyenv\lib\site-packages\twisted\internet\endpoints.py", line 41, in <module> from twisted.internet.stdio import StandardIO, PipeAddress File "e:\python\envs\scrapyenv\lib\site-packages\twisted\internet\stdio.py", line 30, in <module> from twisted.internet import _win32stdio File "e:\python\envs\scrapyenv\lib\site-packages\twisted\internet\_win32stdio.py", line 9, in <module> import win32api ModuleNotFoundError: No module named 'win32api' (scrapyenv) E:\Python\Envs\EnterpriseSpider>
报错:ModuleNotFoundError: No module named 'win32api',缺少模块win32pi
安装缺少的模块,使用国内豆瓣源进行加速安装
pip install -i https://pypi.douban.com/simple pypiwin32
再次启动爬虫,运行成功。
(scrapyenv) E:\Python\Envs\EnterpriseSpider>scrapy crawl jobbole 2018-11-05 09:13:15 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: EnterpriseSpider) 2018-11-05 09:13:15 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0i 14 Aug 2018), cryptography 2.3.1, Platform Windows-10-10.0.17134-SP0 2018-11-05 09:13:15 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'EnterpriseSpider', 'NEWSPIDER_MODULE': 'EnterpriseSpider.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['EnterpriseSpider.spiders']} 2018-11-05 09:13:15 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.logstats.LogStats'] 2018-11-05 09:13:16 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 2018-11-05 09:13:16 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 2018-11-05 09:13:16 [scrapy.middleware] INFO: Enabled item pipelines: [] 2018-11-05 09:13:16 [scrapy.core.engine] INFO: Spider opened 2018-11-05 09:13:16 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2018-11-05 09:13:16 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023 2018-11-05 09:13:16 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.jobbole.com/robots.txt> (referer: None) 2018-11-05 09:13:18 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.jobbole.com/> (referer: None) 2018-11-05 09:13:18 [scrapy.core.engine] INFO: Closing spider (finished) 2018-11-05 09:13:18 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 440, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 21847, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2018, 11, 5, 1, 13, 18, 465449), 'log_count/DEBUG': 3, 'log_count/INFO': 7, 'response_received_count': 2, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2018, 11, 5, 1, 13, 16, 312886)} 2018-11-05 09:13:18 [scrapy.core.engine] INFO: Spider closed (finished) (scrapyenv) E:\Python\Envs\EnterpriseSpider>
在PyCharm中调试爬虫
1. 修改settings.py文件
将ROBOTSTXT_OBEY的值设置为False,否则爬虫会去读取每个网站的robots协议,这样爬虫会很快停止。
2. 在jobbole.py文件设置断点
3. 以Debug模式启动main文件
进入断点,此时查看response,发现传入进来的URL实际上就是starts_urls
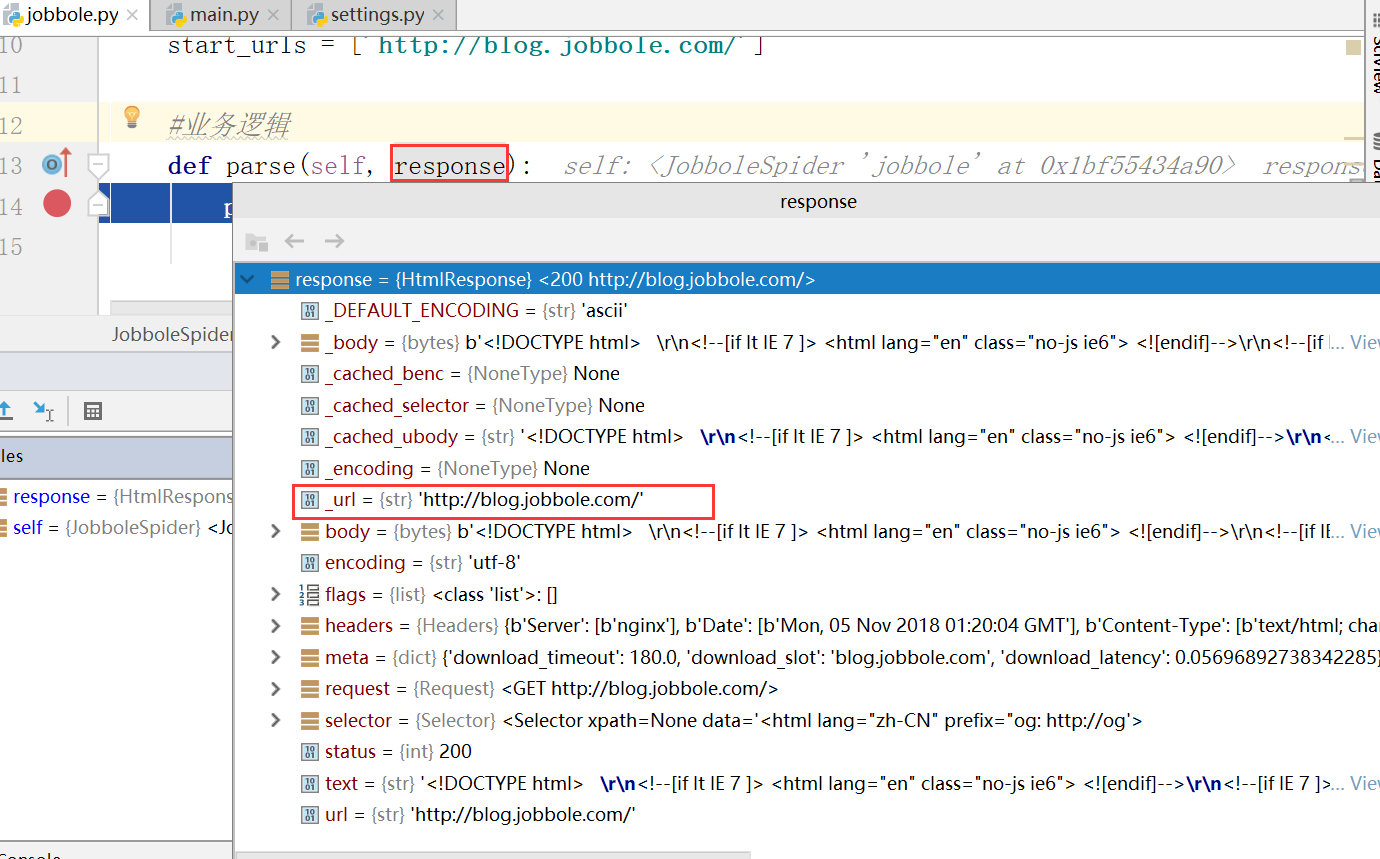
查看第一行response,发现类型是HtmlResponse,状态是200,返回成功
_DEFAULT_ENCODING是默认字符集ASCII,
encoding是scrapy设置的字符集UTF-8,
body设要爬取的网站html的源文件,我们实际操作的就是源文件。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决