Scrapy框架
讨论QQ:1586558083
正文
原理图一
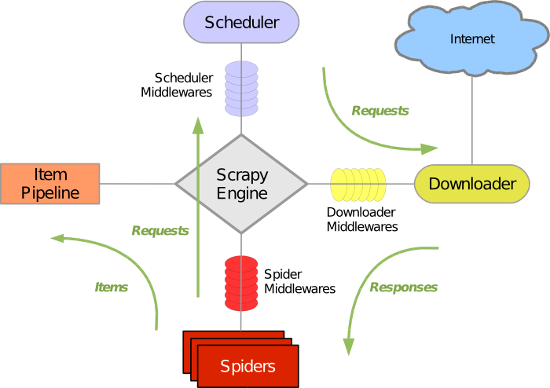
1,spider打开某网页,获取到一个或者多个request,经由scrapy engine传送给调度器scheduler
request特别多并且速度特别快会在scheduler形成请求队列queue,由scheduler安排执行
2,schelduler会按照一定的次序取出请求,经由引擎, 下载器中间键,发送给下载器dowmloader
这里的下载器中间键是设定在请求执行前,因此可以设定代理,请求头,cookie等
3,下载下来的网页数据再次经过下载器中间键,经过引擎,经过爬虫中间键传送给爬虫spiders
这里的下载器中间键是设定在请求执行后,因此可以修改请求的结果
这里的爬虫中间键是设定在数据或者请求到达爬虫之前,与下载器中间键有类似的功能
4,由爬虫spider对下载下来的数据进行解析,按照item设定的数据结构经由爬虫中间键,引擎发送给项目管道itempipeline
这里的项目管道itempipeline可以对数据进行进一步的清洗,存储等操作
这里爬虫极有可能从数据中解析到进一步的请求request,它会把请求经由引擎重新发送给调度器shelduler,调度器循环执行上述操作
5,项目管道itempipeline管理着最后的输出
原理图二

Scrapy数据流是由执行的核心引擎(engine)控制,流程是这样的:
1、爬虫引擎获得初始请求开始抓取。
2、爬虫引擎开始请求调度程序,并准备对下一次的请求进行抓取。
3、爬虫调度器返回下一个请求给爬虫引擎。
4、引擎请求发送到下载器,通过下载中间件下载网络数据。
5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎。
6、引擎将下载器的响应通过中间件返回给爬虫进行处理。
7、爬虫处理响应,并通过中间件返回处理后的items,以及新的请求给引擎。
8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器,调度器计划处理下一个请求抓取。
9、重复该过程(继续步骤1),直到爬取完所有的url请求。
Scrapy各组件的功能
爬虫引擎(ENGINE)
爬虫引擎负责控制各个组件之间的数据流,当某些操作触发事件后都是通过engine来处理。
调度器
调度接收来engine的请求并将请求放入队列中,并通过事件返回给engine。
下载器
通过engine请求下载网络数据并将结果响应给engine。
Spider
Spider发出请求,并处理engine返回给它下载器响应数据,以items和规则内的数据请求(urls)返回给engine。
管道项目(item pipeline)
负责处理engine返回spider解析后的数据,并且将数据持久化,例如将数据存入数据库或者文件。
下载中间件
下载中间件是engine和下载器交互组件,以钩子(插件)的形式存在,可以代替接收请求、处理数据的下载以及将结果响应给engine。
spider中间件
spider中间件是engine和spider之间的交互组件,以钩子(插件)的形式存在,可以代替处理response以及返回给engine items及新的请求集。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决