Hive学习之路 (十五)Hive分析窗口函数(三) CUME_DIST和PERCENT_RANK
这两个序列分析函数不是很常用,这里也练习一下。
数据准备
数据格式
cookie3.txt
d1,user1,1000 d1,user2,2000 d1,user3,3000 d2,user4,4000 d2,user5,5000
创建表
use cookie; drop table if exists cookie3; create table cookie3(dept string, userid string, sal int) row format delimited fields terminated by ','; load data local inpath "/home/hadoop/cookie3.txt" into table cookie3; select * from cookie3;

玩一玩CUME_DIST
说明
–CUME_DIST :小于等于当前值的行数/分组内总行数
查询语句
比如,统计小于等于当前薪水的人数,所占总人数的比例
select dept, userid, sal, cume_dist() over (order by sal) as rn1, cume_dist() over (partition by dept order by sal) as rn2 from cookie.cookie3;
查询结果
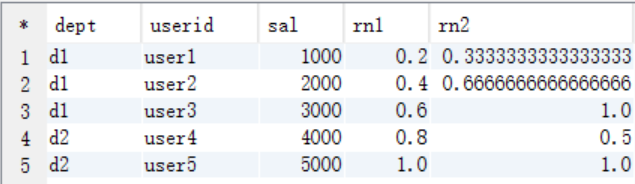
结果说明
rn1: 没有partition,所有数据均为1组,总行数为5, 第一行:小于等于1000的行数为1,因此,1/5=0.2 第三行:小于等于3000的行数为3,因此,3/5=0.6 rn2: 按照部门分组,dpet=d1的行数为3, 第二行:小于等于2000的行数为2,因此,2/3=0.6666666666666666
玩一玩PERCENT_RANK
说明
–PERCENT_RANK :分组内当前行的RANK值-1/分组内总行数-1
查询语句
select dept, userid, sal, percent_rank() over (order by sal) as rn1, --分组内 rank() over (order by sal) as rn11, --分组内的rank值 sum(1) over (partition by null) as rn12, --分组内总行数 percent_rank() over (partition by dept order by sal) as rn2, rank() over (partition by dept order by sal) as rn21, sum(1) over (partition by dept) as rn22 from cookie.cookie3;
查询结果
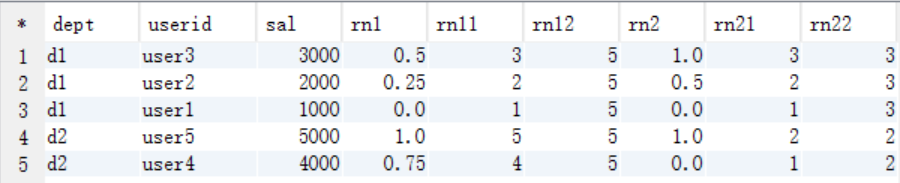
结果说明
–PERCENT_RANK :分组内当前行的RANK值-1/分组内总行数-1
rn1 == (rn11-1) / (rn12-1)
rn2 == (rn21-1) / (rn22-1)
rn1: rn1 = (rn11-1) / (rn12-1) 第一行,(1-1)/(5-1)=0/4=0 第二行,(2-1)/(5-1)=1/4=0.25 第四行,(4-1)/(5-1)=3/4=0.75 rn2: 按照dept分组, dept=d1的总行数为3 第一行,(1-1)/(3-1)=0 第三行,(3-1)/(3-1)=1

