HBase学习之路 (十)HBase表的设计原则
建表高级属性
下面几个 shell 命令在 hbase 操作中可以起到很大的作用,且主要体现在建表的过程中,看 下面几个 create 属性
1、 BLOOMFILTER
默认是 NONE 是否使用布隆过虑及使用何种方式,布隆过滤可以每列族单独启用 使用 HColumnDescriptor.setBloomFilterType(NONE | ROW | ROWCOL) 对列族单独启用布隆
Default = ROW 对行进行布隆过滤
对 ROW,行键的哈希在每次插入行时将被添加到布隆
对 ROWCOL,行键 + 列族 + 列族修饰的哈希将在每次插入行时添加到布隆
使用方法: create 'table',{BLOOMFILTER =>'ROW'}
作用:用布隆过滤可以节省读磁盘过程,可以有助于降低读取延迟
2、 VERSIONS
默认是 1 这个参数的意思是数据保留 1 个 版本,如果我们认为我们的数据没有这么大 的必要保留这么多,随时都在更新,而老版本的数据对我们毫无价值,那将此参数设为 1 能 节约 2/3 的空间
使用方法: create 'table',{VERSIONS=>'2'}
附:MIN_VERSIONS => '0'是说在 compact 操作执行之后,至少要保留的版本
3、 COMPRESSION
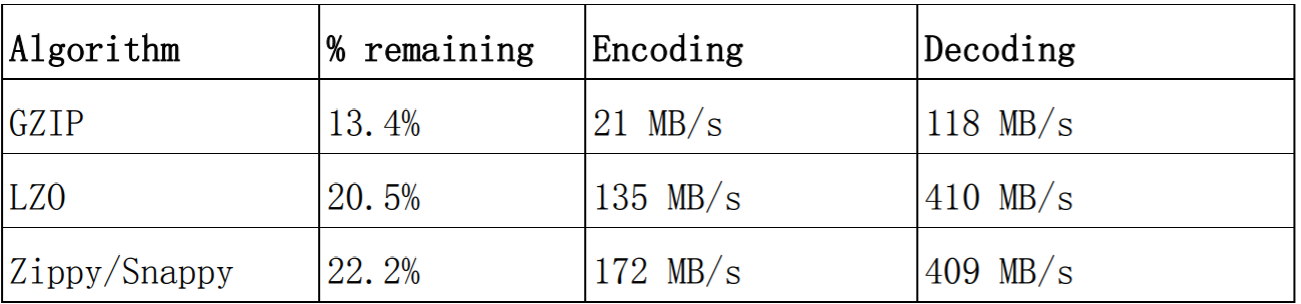
默认值是 NONE 即不使用压缩,这个参数意思是该列族是否采用压缩,采用什么压缩算 法,方法: create 'table',{NAME=>'info',COMPRESSION=>'SNAPPY'} ,建议采用 SNAPPY 压缩算 法 ,HBase 中,在 Snappy 发布之前(Google 2011 年对外发布 Snappy),采用的 LZO 算法,目标是达到尽可能快的压缩和解压速度,同时减少对 CPU 的消耗;
在 Snappy 发布之后,建议采用 Snappy 算法(参考《HBase: The Definitive Guide》),具体 可以根据实际情况对 LZO 和 Snappy 做过更详细的对比测试后再做选择。
如果建表之初没有压缩,后来想要加入压缩算法,可以通过 alter 修改 schema
4、 TTL
默认是 2147483647 即:Integer.MAX_VALUE 值大概是 68 年,这个参数是说明该列族数据的存活时间,单位是 s
这个参数可以根据具体的需求对数据设定存活时间,超过存过时间的数据将在表中不在 显示,待下次 major compact 的时候再彻底删除数据
注意的是 TTL 设定之后 MIN_VERSIONS=>'0' 这样设置之后,TTL 时间戳过期后,将全部 彻底删除该 family 下所有的数据,如果 MIN_VERSIONS 不等于 0 那将保留最新的 MIN_VERSIONS 个版本的数据,其它的全部删除,比如 MIN_VERSIONS=>'1' 届时将保留一个 最新版本的数据,其它版本的数据将不再保存。
5、 alter
使用方法:
如 修改压缩算法
disable 'table' alter 'table',{NAME=>'info',COMPRESSION=>'snappy'} enable 'table'
但是需要执行 major_compact 'table' 命令之后 才会做实际的操作。
6、 describe/desc
这个命令查看了 create table 的各项参数或者是默认值。
使用方式:describe 'user_info'
7、 disable_all/enable_all
disable_all 'toplist.*' disable_all 支持正则表达式,并列出当前匹配的表的如下:
toplist_a_total_1001 toplist_a_total_1002 toplist_a_total_1008 toplist_a_total_1009 toplist_a_total_1019 toplist_a_total_1035 ... Disable the above 25 tables (y/n)? 并给出确认提示
8、 drop_all
这个命令和 disable_all 的使用方式是一样的
9、 hbase 预分区
默认情况下,在创建 HBase 表的时候会自动创建一个 region 分区,当导入数据的时候, 所有的 HBase 客户端都向这一个 region 写数据,直到这个 region 足够大了才进行切分。一 种可以加快批量写入速度的方法是通过预先创建一些空的 regions,这样当数据写入 HBase 时,会按照 region 分区情况,在集群内做数据的负载均衡。
命令方式:
# create table with specific split points hbase>create 'table1','f1',SPLITS => ['\x10\x00', '\x20\x00', '\x30\x00', '\x40\x00'] # create table with four regions based on random bytes keys hbase>create 'table2','f1', { NUMREGIONS => 8 , SPLITALGO => 'UniformSplit' } # create table with five regions based on hex keys hbase>create 'table3','f1', { NUMREGIONS => 10, SPLITALGO => 'HexStringSplit' }
也可以使用 api 的方式:
hbase org.apache.hadoop.hbase.util.RegionSplitter test_table HexStringSplit -c 10 -f info hbase org.apache.hadoop.hbase.util.RegionSplitter splitTable HexStringSplit -c 10 -f info
参数:
test_table 是表名
HexStringSplit 是split 方式
-c 是分 10 个 region
-f 是 family
可在 UI 上查看结果,如图:
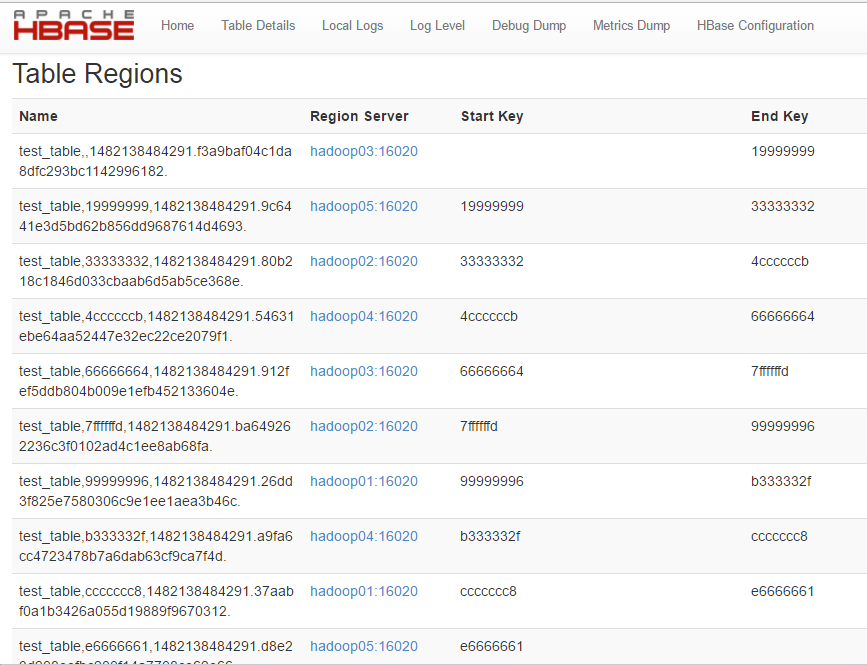
这样就可以将表预先分为 15 个区,减少数据达到 storefile 大小的时候自动分区的时间 消耗,并且还有以一个优势,就是合理设计 rowkey 能让各个 region 的并发请求平均分配(趋 于均匀) 使 IO 效率达到最高,但是预分区需要将 filesize 设置一个较大的值,设置哪个参数 呢 hbase.hregion.max.filesize 这个值默认是 10G 也就是说单个 region 默认大小是 10G
这个参数的默认值在 0.90 到 0.92 到 0.94.3 各版本的变化:256M--1G--10G
但是如果 MapReduce Input 类型为 TableInputFormat 使用 hbase 作为输入的时候,就要注意 了,每个 region 一个 map,如果数据小于 10G 那只会启用一个 map 造成很大的资源浪费, 这时候可以考虑适当调小该参数的值,或者采用预分配 region 的方式,并将检测如果达到 这个值,再手动分配 region。
表设计
1、列簇设计
追求的原则是:在合理范围内能尽量少的减少列簇就尽量减少列簇。
最优设计是:将所有相关性很强的 key-value 都放在同一个列簇下,这样既能做到查询效率 最高,也能保持尽可能少的访问不同的磁盘文件。
以用户信息为例,可以将必须的基本信息存放在一个列族,而一些附加的额外信息可以放在 另一列族。
2、RowKey 设计
HBase 中,表会被划分为 1...n 个 Region,被托管在 RegionServer 中。Region 二个重要的 属性:StartKey 与 EndKey 表示这个 Region 维护的 rowKey 范围,当我们要读/写数据时,如 果 rowKey 落在某个 start-end key 范围内,那么就会定位到目标 region 并且读/写到相关的数 据
那怎么快速精准的定位到我们想要操作的数据,就在于我们的 rowkey 的设计了
Rowkey 设计三原则
1、 rowkey 长度原则
Rowkey 是一个二进制码流,Rowkey 的长度被很多开发者建议说设计在 10~100 个字节,不 过建议是越短越好,不要超过 16 个字节。
原因如下:
1、数据的持久化文件 HFile 中是按照 KeyValue 存储的,如果 Rowkey 过长比如 100 个字 节,1000 万列数据光 Rowkey 就要占用 100*1000 万=10 亿个字节,将近 1G 数据,这会极大 影响 HFile 的存储效率;
2、MemStore 将缓存部分数据到内存,如果 Rowkey 字段过长内存的有效利用率会降低, 系统将无法缓存更多的数据,这会降低检索效率。因此 Rowkey 的字节长度越短越好。
3、目前操作系统是都是 64 位系统,内存 8 字节对齐。控制在 16 个字节,8 字节的整数 倍利用操作系统的最佳特性。
2、rowkey 散列原则
如果 Rowkey 是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将 Rowkey 的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个 Regionserver 实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有 新数据都在一个 RegionServer 上堆积的热点现象,这样在做数据检索的时候负载将会集中 在个别 RegionServer,降低查询效率。
3、 rowkey 唯一原则
必须在设计上保证其唯一性。rowkey 是按照字典顺序排序存储的,因此,设计 rowkey 的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问 的数据放到一块。
数据热点
HBase 中的行是按照 rowkey 的字典顺序排序的,这种设计优化了 scan 操作,可以将相 关的行以及会被一起读取的行存取在临近位置,便于 scan。然而糟糕的 rowkey 设计是热点 的源头。 热点发生在大量的 client 直接访问集群的一个或极少数个节点(访问可能是读, 写或者其他操作)。大量访问会使热点 region 所在的单个机器超出自身承受能力,引起性能 下降甚至 region 不可用,这也会影响同一个 RegionServer 上的其他 region,由于主机无法服 务其他 region 的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。 为了避免写热点,设计 rowkey 使得不同行在同一个 region,但是在更多数据情况下,数据 应该被写入集群的多个 region,而不是一个。
防止数据热点的有效措施
加盐
这里所说的加盐不是密码学中的加盐,而是在 rowkey 的前面增加随机数,具体就是给 rowkey 分配一个随机前缀以使得它和之前的 rowkey 的开头不同。分配的前缀种类数量应该 和你想使用数据分散到不同的 region 的数量一致。加盐之后的 rowkey 就会根据随机生成的 前缀分散到各个 region 上,以避免热点。
哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是 可以预测的。使用确定的哈希可以让客户端重构完整的 rowkey,可以使用 get 操作准确获取 某一个行数据
反转
第三种防止热点的方法是反转固定长度或者数字格式的 rowkey。这样可以使得 rowkey 中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机 rowkey,但是牺 牲了 rowkey 的有序性。
反转 rowkey 的例子以手机号为 rowkey,可以将手机号反转后的字符串作为 rowkey,这 样的就避免了以手机号那样比较固定开头导致热点问题
时间戳反转
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为 rowkey 的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到 key 的末尾,例 如 [key][reverse_timestamp] , [key] 的最新值可以通过 scan [key]获得[key]的第一条记录,因 为 HBase 中 rowkey 是有序的,第一条记录是最后录入的数据。比如需要保存一个用户的操 作记录,按照操作时间倒序排序,在设计 rowkey 的时候,可以这样设计 [userId 反转][Long.Max_Value - timestamp],在查询用户的所有操作记录数据的时候,直接指 定 反 转 后 的 userId , startRow 是 [userId 反 转 ][000000000000],stopRow 是 [userId 反 转][Long.Max_Value - timestamp]
如果需要查询某段时间的操作记录,startRow 是[user 反转][Long.Max_Value - 起始时间], stopRow 是[userId 反转][Long.Max_Value - 结束时间]

