HBase学习之路 (二)HBase集群安装
讨论QQ:1586558083
正文
前提
1、HBase 依赖于 HDFS 做底层的数据存储
2、HBase 依赖于 MapReduce 做数据计算
3、HBase 依赖于 ZooKeeper 做服务协调
4、HBase源码是java编写的,安装需要依赖JDK
版本选择
打开官方的版本说明http://hbase.apache.org/1.2/book.html
JDK的选择
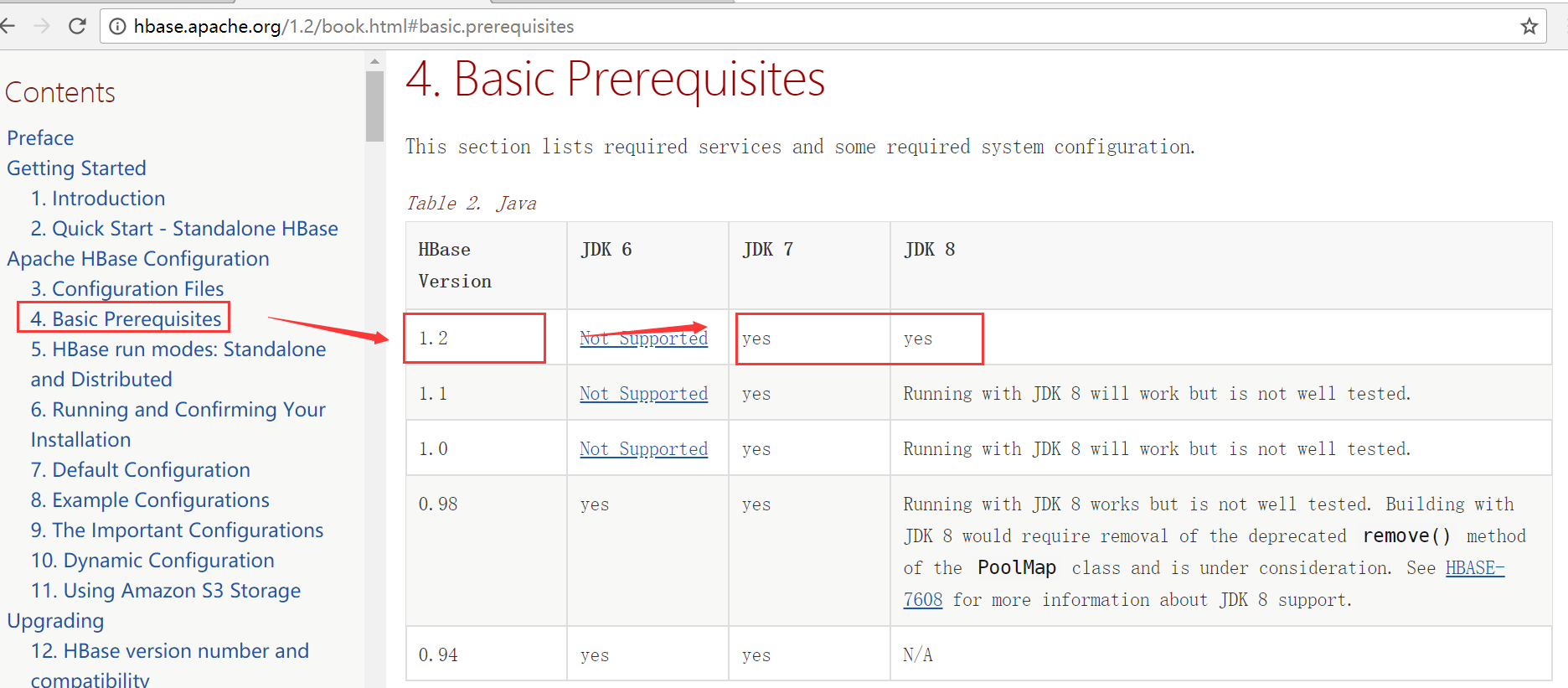
Hadoop的选择
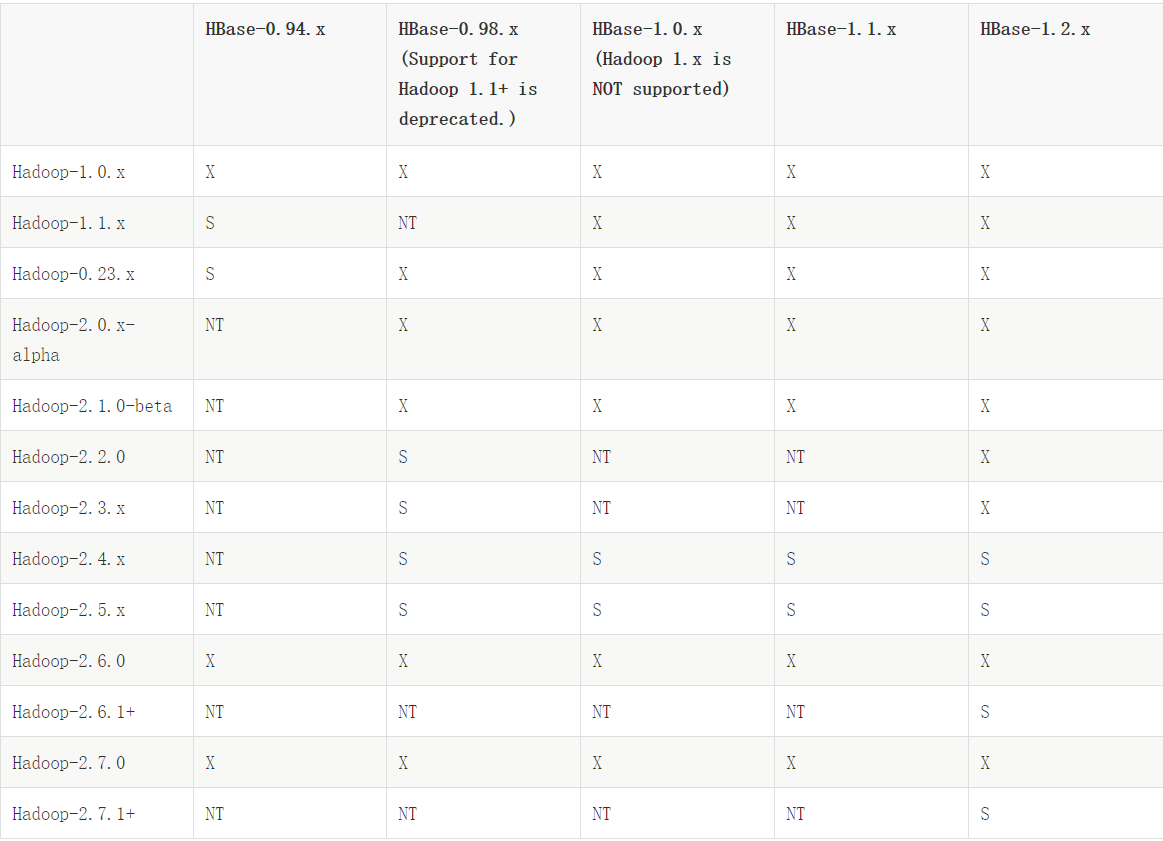
此处我们的hadoop版本用的的是2.7.5,HBase选择的版本是1.2.6
安装
1、zookeeper的安装
参考http://www.cnblogs.com/qingyunzong/p/8619184.html
2、Hadoopd的安装
参考http://www.cnblogs.com/qingyunzong/p/8634335.html
3、下载安装包
找到官网下载 hbase 安装包 hbase-1.2.6-bin.tar.gz,这里给大家提供一个下载地址: http://mirrors.hust.edu.cn/apache/hbase/

4、上传服务器并解压缩到指定目录
[hadoop@hadoop1 ~]$ ls apps data hbase-1.2.6-bin.tar.gz hello.txt log zookeeper.out [hadoop@hadoop1 ~]$ tar -zxvf hbase-1.2.6-bin.tar.gz -C apps/
5、修改配置文件
配置文件目录在安装包的conf文件夹中
(1)修改hbase-env.sh
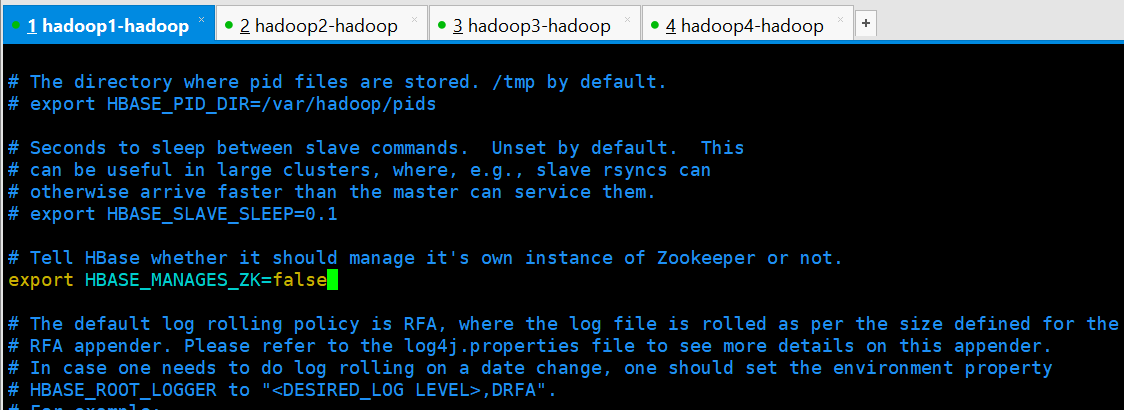
[hadoop@hadoop1 conf]$ vi hbase-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_73
export HBASE_MANAGES_ZK=false
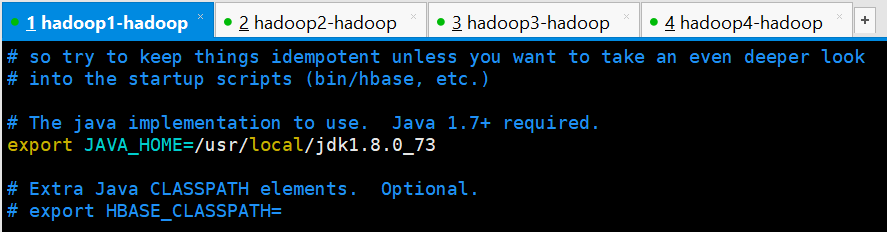
(2)修改hbase-site.xml
[hadoop@hadoop1 conf]$ vi hbase-site.xml

<configuration> <property> <!-- 指定 hbase 在 HDFS 上存储的路径 --> <name>hbase.rootdir</name> <value>hdfs://myha01/hbase126</value> </property> <property> <!-- 指定 hbase 是分布式的 --> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <!-- 指定 zk 的地址,多个用“,”分割 --> <name>hbase.zookeeper.quorum</name> <value>hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181</value> </property> </configuration>
(3)修改regionservers
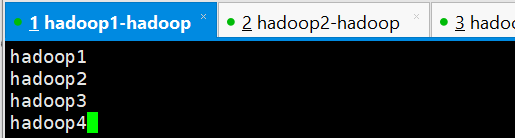
[hadoop@hadoop1 conf]$ vi regionservers
hadoop1
hadoop2
hadoop3
hadoop4
(4)修改backup-masters
该文件是不存在的,先自行创建
[hadoop@hadoop1 conf]$ vi backup-masters
hadoop4
(5)修改hdfs-site.xml 和 core-site.xml
最重要一步,要把 hadoop 的 hdfs-site.xml 和 core-site.xml 放到 hbase-1.2.6/conf 下
[hadoop@hadoop1 conf]$ cd ~/apps/hadoop-2.7.5/etc/hadoop/
[hadoop@hadoop1 hadoop]$ cp core-site.xml hdfs-site.xml ~/apps/hbase-1.2.6/conf/
6、将HBase安装包分发到其他节点
分发之前先删除HBase目录下的docs文件夹,
[hadoop@hadoop1 hbase-1.2.6]$ rm -rf docs/
在进行分发
[hadoop@hadoop1 apps]$ scp -r hbase-1.2.6/ hadoop2:$PWD
[hadoop@hadoop1 apps]$ scp -r hbase-1.2.6/ hadoop3:$PWD
[hadoop@hadoop1 apps]$ scp -r hbase-1.2.6/ hadoop4:$PWD
7、 同步时间
HBase 集群对于时间的同步要求的比 HDFS 严格,所以,集群启动之前千万记住要进行 时间同步,要求相差不要超过 30s
8、配置环境变量
所有服务器都有进行配置
[hadoop@hadoop1 apps]$ vi ~/.bashrc
#HBase
export HBASE_HOME=/home/hadoop/apps/hbase-1.2.6
export PATH=$PATH:$HBASE_HOME/bin
使环境变量立即生效
[hadoop@hadoop1 apps]$ source ~/.bashrc
启动HBase集群
严格按照启动顺序进行
1、启动zookeeper集群
每个zookeeper节点都要执行以下命令
[hadoop@hadoop1 apps]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop1 apps]$
2、启动HDFS集群及YARN集群
如果需要运行MapReduce程序则启动yarn集群,否则不需要启动
[hadoop@hadoop1 apps]$ start-dfs.sh
Starting namenodes on [hadoop1 hadoop2]
hadoop2: starting namenode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-namenode-hadoop2.out
hadoop1: starting namenode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-namenode-hadoop1.out
hadoop3: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop3.out
hadoop4: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop4.out
hadoop2: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop2.out
hadoop1: starting datanode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-datanode-hadoop1.out
Starting journal nodes [hadoop1 hadoop2 hadoop3]
hadoop3: starting journalnode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-journalnode-hadoop3.out
hadoop2: starting journalnode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-journalnode-hadoop2.out
hadoop1: starting journalnode, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-journalnode-hadoop1.out
Starting ZK Failover Controllers on NN hosts [hadoop1 hadoop2]
hadoop2: starting zkfc, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-zkfc-hadoop2.out
hadoop1: starting zkfc, logging to /home/hadoop/apps/hadoop-2.7.5/logs/hadoop-hadoop-zkfc-hadoop1.out
[hadoop@hadoop1 apps]$
启动完成之后检查以下namenode的状态
[hadoop@hadoop1 apps]$ hdfs haadmin -getServiceState nn1
standby
[hadoop@hadoop1 apps]$ hdfs haadmin -getServiceState nn2
active
[hadoop@hadoop1 apps]$
3、启动HBase
保证 ZooKeeper 集群和 HDFS 集群启动正常的情况下启动 HBase 集群 启动命令:start-hbase.sh,在哪台节点上执行此命令,哪个节点就是主节点
[hadoop@hadoop1 conf]$ start-hbase.sh
starting master, logging to /home/hadoop/apps/hbase-1.2.6/logs/hbase-hadoop-master-hadoop1.out
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
hadoop3: starting regionserver, logging to /home/hadoop/apps/hbase-1.2.6/logs/hbase-hadoop-regionserver-hadoop3.out
hadoop4: starting regionserver, logging to /home/hadoop/apps/hbase-1.2.6/logs/hbase-hadoop-regionserver-hadoop4.out
hadoop2: starting regionserver, logging to /home/hadoop/apps/hbase-1.2.6/logs/hbase-hadoop-regionserver-hadoop2.out
hadoop3: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
hadoop3: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
hadoop4: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
hadoop4: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
hadoop2: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
hadoop2: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
hadoop1: starting regionserver, logging to /home/hadoop/apps/hbase-1.2.6/logs/hbase-hadoop-regionserver-hadoop1.out
hadoop4: starting master, logging to /home/hadoop/apps/hbase-1.2.6/logs/hbase-hadoop-master-hadoop4.out
[hadoop@hadoop1 conf]$
观看启动日志可以看到:
(1)首先在命令执行节点启动 master
(2)然后分别在 hadoop02,hadoop03,hadoop04,hadoop05 启动 regionserver
(3)然后在 backup-masters 文件中配置的备节点上再启动一个 master 主进程
验证启动是否正常
1、检查各进程是否启动正常
主节点和备用节点都启动 hmaster 进程
各从节点都启动 hregionserver 进程
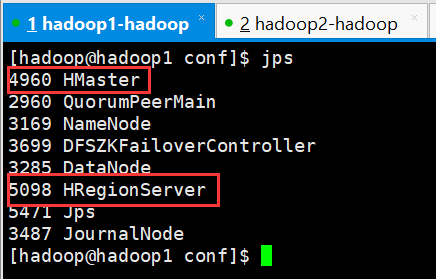
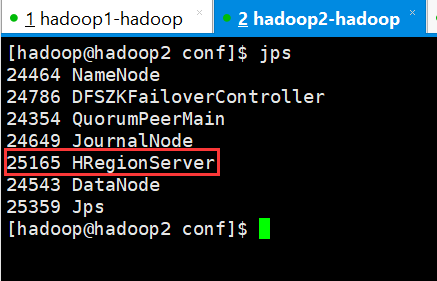
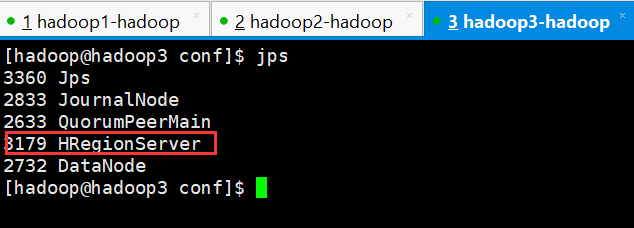
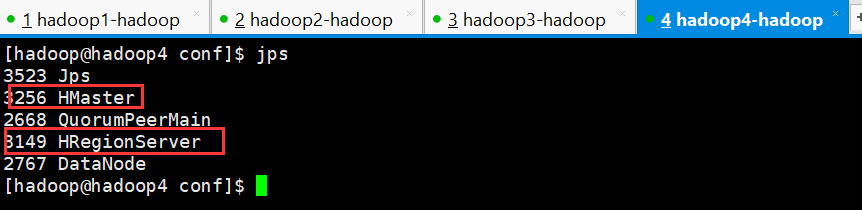
按照对应的配置信息各个节点应该要启动的进程如上图所示
2、通过访问浏览器页面
hadoop1
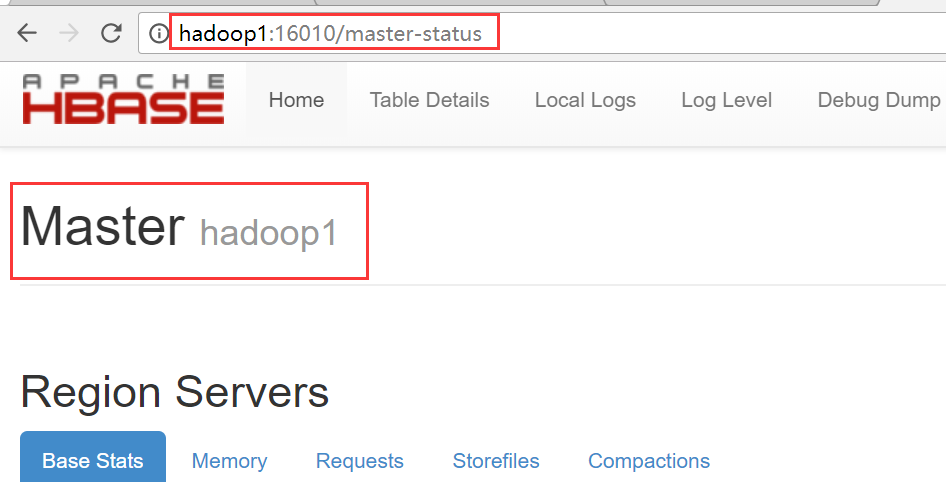
hadop4
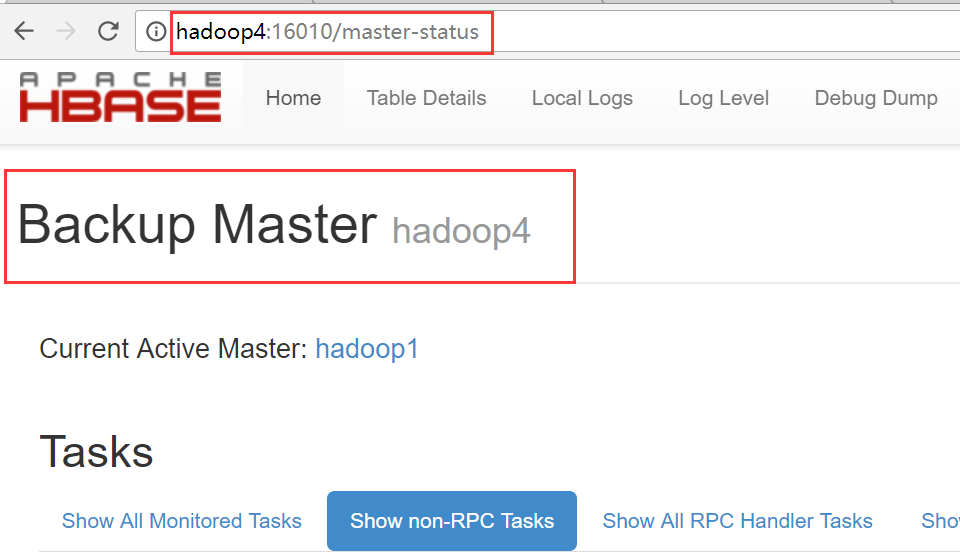
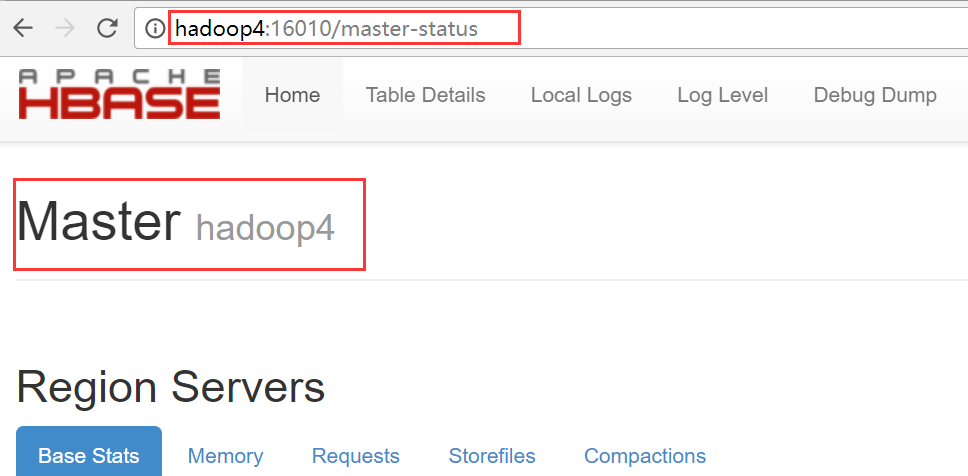
从图中可以看出hadoop4是备用节点
3、验证高可用
干掉hadoop1上的hbase进程,观察备用节点是否启用
[hadoop@hadoop1 conf]$ jps
4960 HMaster
2960 QuorumPeerMain
3169 NameNode
3699 DFSZKFailoverController
3285 DataNode
5098 HRegionServer
5471 Jps
3487 JournalNode
[hadoop@hadoop1 conf]$ kill -9 4960
hadoop1界面访问不了
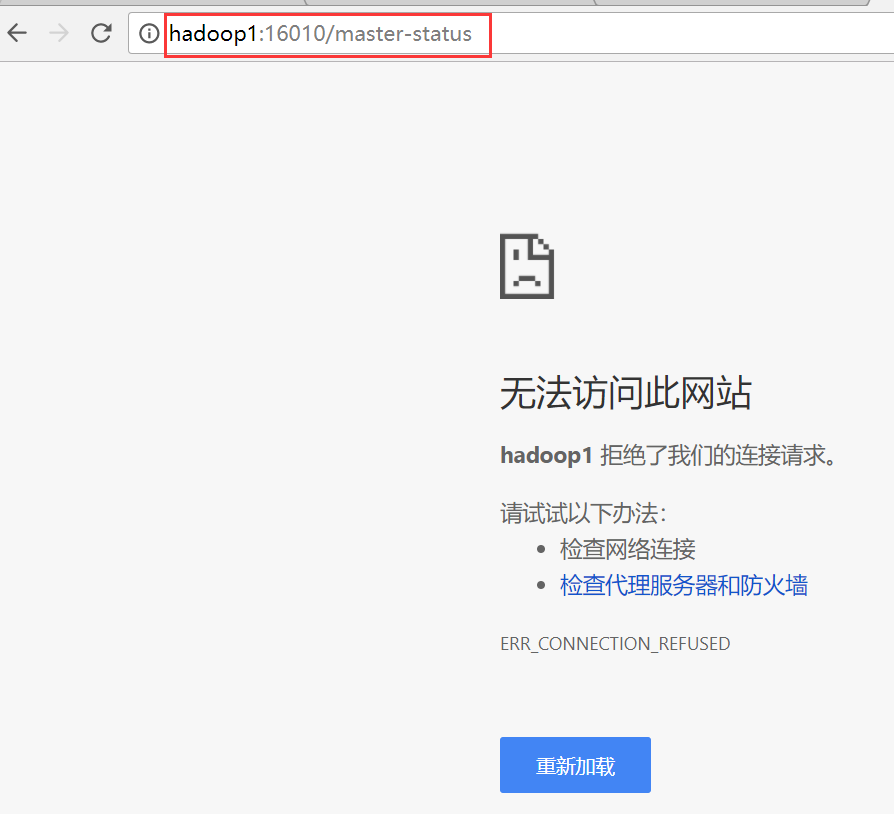
hadoop4变成主节点
4、如果有节点相应的进程没有启动,那么可以手动启动
启动HMaster进程
[hadoop@hadoop3 conf]$ jps
3360 Jps
2833 JournalNode
2633 QuorumPeerMain
3179 HRegionServer
2732 DataNode
[hadoop@hadoop3 conf]$ hbase-daemon.sh start master
starting master, logging to /home/hadoop/apps/hbase-1.2.6/logs/hbase-hadoop-master-hadoop3.out
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
[hadoop@hadoop3 conf]$ jps
2833 JournalNode
3510 Jps
3432 HMaster
2633 QuorumPeerMain
3179 HRegionServer
2732 DataNode
[hadoop@hadoop3 conf]$
启动HRegionServer进程
[hadoop@hadoop3 conf]$ hbase-daemon.sh start regionserver


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)