Hadoop学习之路(二十七)MapReduce的API使用(四)
第一题
下面是三种商品的销售数据
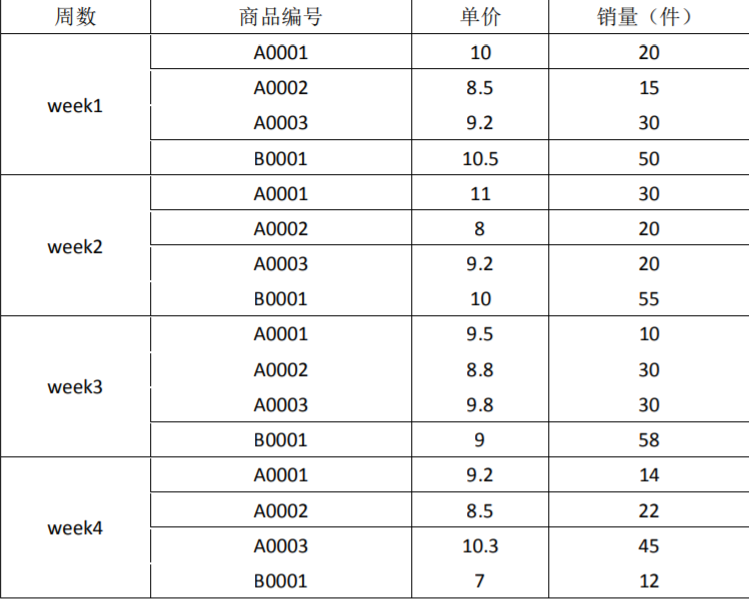
要求:根据以上数据,用 MapReduce 统计出如下数据:
1、每种商品的销售总金额,并降序排序
2、每种商品销售额最多的三周
第二题:MapReduce 题
现有如下数据文件需要处理:
格式:CSV
数据样例:
user_a,location_a,2018-01-01 08:00:00,60
user_a,location_a,2018-01-01 09:00:00,60
user_a,location_b,2018-01-01 10:00:00,60
user_a,location_a,2018-01-01 11:00:00,60
字段:用户 ID,位置 ID,开始时间,停留时长(分钟)
数据意义:某个用户在某个位置从某个时刻开始停留了多长时间
处理逻辑: 对同一个用户,在同一个位置,连续的多条记录进行合并
合并原则:开始时间取最早的,停留时长加和
要求:请编写 MapReduce 程序实现
其他:只有数据样例,没有数据。
UserLocationMR.java


1 /** 2 测试数据: 3 user_a location_a 2018-01-01 08:00:00 60 4 user_a location_a 2018-01-01 09:00:00 60 5 user_a location_a 2018-01-01 11:00:00 60 6 user_a location_a 2018-01-01 12:00:00 60 7 user_a location_b 2018-01-01 10:00:00 60 8 user_a location_c 2018-01-01 08:00:00 60 9 user_a location_c 2018-01-01 09:00:00 60 10 user_a location_c 2018-01-01 10:00:00 60 11 user_b location_a 2018-01-01 15:00:00 60 12 user_b location_a 2018-01-01 16:00:00 60 13 user_b location_a 2018-01-01 18:00:00 60 14 15 16 结果数据: 17 user_a location_a 2018-01-01 08:00:00 120 18 user_a location_a 2018-01-01 11:00:00 120 19 user_a location_b 2018-01-01 10:00:00 60 20 user_a location_c 2018-01-01 08:00:00 180 21 user_b location_a 2018-01-01 15:00:00 120 22 user_b location_a 2018-01-01 18:00:00 60 23 24 25 */ 26 public class UserLocationMR { 27 28 public static void main(String[] args) throws Exception { 29 // 指定hdfs相关的参数 30 Configuration conf = new Configuration(); 31 // conf.set("fs.defaultFS", "hdfs://hadoop02:9000"); 32 // System.setProperty("HADOOP_USER_NAME", "hadoop"); 33 34 Job job = Job.getInstance(conf); 35 // 设置jar包所在路径 36 job.setJarByClass(UserLocationMR.class); 37 38 // 指定mapper类和reducer类 39 job.setMapperClass(UserLocationMRMapper.class); 40 job.setReducerClass(UserLocationMRReducer.class); 41 42 // 指定maptask的输出类型 43 job.setMapOutputKeyClass(UserLocation.class); 44 job.setMapOutputValueClass(NullWritable.class); 45 // 指定reducetask的输出类型 46 job.setOutputKeyClass(UserLocation.class); 47 job.setOutputValueClass(NullWritable.class); 48 49 job.setGroupingComparatorClass(UserLocationGC.class); 50 51 // 指定该mapreduce程序数据的输入和输出路径 52 Path inputPath = new Path("D:\\武文\\second\\input"); 53 Path outputPath = new Path("D:\\武文\\second\\output2"); 54 FileSystem fs = FileSystem.get(conf); 55 if (fs.exists(outputPath)) { 56 fs.delete(outputPath, true); 57 } 58 FileInputFormat.setInputPaths(job, inputPath); 59 FileOutputFormat.setOutputPath(job, outputPath); 60 61 // 最后提交任务 62 boolean waitForCompletion = job.waitForCompletion(true); 63 System.exit(waitForCompletion ? 0 : 1); 64 } 65 66 private static class UserLocationMRMapper extends Mapper<LongWritable, Text, UserLocation, NullWritable> { 67 68 UserLocation outKey = new UserLocation(); 69 70 /** 71 * value = user_a,location_a,2018-01-01 12:00:00,60 72 */ 73 @Override 74 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 75 76 String[] split = value.toString().split(","); 77 78 outKey.set(split); 79 80 context.write(outKey, NullWritable.get()); 81 } 82 } 83 84 private static class UserLocationMRReducer extends Reducer<UserLocation, NullWritable, UserLocation, NullWritable> { 85 86 SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); 87 88 UserLocation outKey = new UserLocation(); 89 90 /** 91 * user_a location_a 2018-01-01 08:00:00 60 92 * user_a location_a 2018-01-01 09:00:00 60 93 * user_a location_a 2018-01-01 11:00:00 60 94 * user_a location_a 2018-01-01 12:00:00 60 95 */ 96 @Override 97 protected void reduce(UserLocation key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { 98 99 int count = 0; 100 for (NullWritable nvl : values) { 101 count++; 102 // 如果是这一组key-value中的第一个元素时,直接赋值给outKey对象。基础对象 103 if (count == 1) { 104 // 复制值 105 outKey.set(key); 106 } else { 107 108 // 有可能连续,有可能不连续, 连续则继续变量, 否则输出 109 long current_timestamp = 0; 110 long last_timestamp = 0; 111 try { 112 // 这是新遍历出来的记录的时间戳 113 current_timestamp = sdf.parse(key.getTime()).getTime(); 114 // 这是上一条记录的时间戳 和 停留时间之和 115 last_timestamp = sdf.parse(outKey.getTime()).getTime() + outKey.getDuration() * 60 * 1000; 116 } catch (ParseException e) { 117 e.printStackTrace(); 118 } 119 120 // 如果相等,证明是连续记录,所以合并 121 if (current_timestamp == last_timestamp) { 122 123 outKey.setDuration(outKey.getDuration() + key.getDuration()); 124 125 } else { 126 127 // 先输出上一条记录 128 context.write(outKey, nvl); 129 130 // 然后再次记录当前遍历到的这一条记录 131 outKey.set(key); 132 } 133 } 134 } 135 // 最后无论如何,还得输出最后一次 136 context.write(outKey, NullWritable.get()); 137 } 138 } 139 }
UserLocation.java
1 public class UserLocation implements WritableComparable<UserLocation> { 2 3 private String userid; 4 private String locationid; 5 private String time; 6 private long duration; 7 8 @Override 9 public String toString() { 10 return userid + "\t" + locationid + "\t" + time + "\t" + duration; 11 } 12 13 public UserLocation() { 14 super(); 15 } 16 17 public void set(String[] split){ 18 this.setUserid(split[0]); 19 this.setLocationid(split[1]); 20 this.setTime(split[2]); 21 this.setDuration(Long.parseLong(split[3])); 22 } 23 24 public void set(UserLocation ul){ 25 this.setUserid(ul.getUserid()); 26 this.setLocationid(ul.getLocationid()); 27 this.setTime(ul.getTime()); 28 this.setDuration(ul.getDuration()); 29 } 30 31 public UserLocation(String userid, String locationid, String time, long duration) { 32 super(); 33 this.userid = userid; 34 this.locationid = locationid; 35 this.time = time; 36 this.duration = duration; 37 } 38 39 public String getUserid() { 40 return userid; 41 } 42 43 public void setUserid(String userid) { 44 this.userid = userid; 45 } 46 47 public String getLocationid() { 48 return locationid; 49 } 50 51 public void setLocationid(String locationid) { 52 this.locationid = locationid; 53 } 54 55 public String getTime() { 56 return time; 57 } 58 59 public void setTime(String time) { 60 this.time = time; 61 } 62 63 public long getDuration() { 64 return duration; 65 } 66 67 public void setDuration(long duration) { 68 this.duration = duration; 69 } 70 71 @Override 72 public void write(DataOutput out) throws IOException { 73 // TODO Auto-generated method stub 74 out.writeUTF(userid); 75 out.writeUTF(locationid); 76 out.writeUTF(time); 77 out.writeLong(duration); 78 } 79 80 @Override 81 public void readFields(DataInput in) throws IOException { 82 // TODO Auto-generated method stub 83 this.userid = in.readUTF(); 84 this.locationid = in.readUTF(); 85 this.time = in.readUTF(); 86 this.duration = in.readLong(); 87 } 88 89 /** 90 * 排序规则 91 * 92 * 按照 userid locationid 和 time 排序 都是 升序 93 */ 94 @Override 95 public int compareTo(UserLocation o) { 96 97 int diff_userid = o.getUserid().compareTo(this.getUserid()); 98 if(diff_userid == 0){ 99 100 int diff_location = o.getLocationid().compareTo(this.getLocationid()); 101 if(diff_location == 0){ 102 103 int diff_time = o.getTime().compareTo(this.getTime()); 104 if(diff_time == 0){ 105 return 0; 106 }else{ 107 return diff_time > 0 ? -1 : 1; 108 } 109 110 }else{ 111 return diff_location > 0 ? -1 : 1; 112 } 113 114 }else{ 115 return diff_userid > 0 ? -1 : 1; 116 } 117 } 118 }
UserLocationGC.java
1 public class UserLocationGC extends WritableComparator{ 2 3 public UserLocationGC(){ 4 super(UserLocation.class, true); 5 } 6 7 @Override 8 public int compare(WritableComparable a, WritableComparable b) { 9 10 UserLocation ul_a = (UserLocation)a; 11 UserLocation ul_b = (UserLocation)b; 12 13 int diff_userid = ul_a.getUserid().compareTo(ul_b.getUserid()); 14 if(diff_userid == 0){ 15 16 int diff_location = ul_a.getLocationid().compareTo(ul_b.getLocationid()); 17 if(diff_location == 0){ 18 19 return 0; 20 21 }else{ 22 return diff_location > 0 ? -1 : 1; 23 } 24 25 }else{ 26 return diff_userid > 0 ? -1 : 1; 27 } 28 } 29 }
第三题:MapReduce 题--倒排索引
概念: 倒排索引(Inverted Index),也常被称为反向索引、置入档案或反向档案,是一种索引方法, 被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档 检索系统中最常用的数据结构。了解详情可自行百度
有两份数据:
mapreduce-4-1.txt
huangbo love xuzheng
huangxiaoming love baby huangxiaoming love yangmi
liangchaowei love liujialing
huangxiaoming xuzheng huangbo wangbaoqiang
mapreduce-4-2.txt
hello huangbo
hello xuzheng
hello huangxiaoming
题目一:编写 MapReduce 求出以下格式的结果数据:统计每个关键词在每个文档中当中的 第几行出现了多少次 例如,huangxiaoming 关键词的格式:
huangixaoming mapreduce-4-1.txt:2,2; mapreduce-4-1.txt:4,1;mapreduce-4-2.txt:3,1
以上答案的意义:
关键词 huangxiaoming 在第一份文档 mapreduce-4-1.txt 中的第 2 行出现了 2 次
关键词 huangxiaoming 在第一份文档 mapreduce-4-1.txt 中的第 4 行出现了 1 次
关键词 huangxiaoming 在第二份文档 mapreduce-4-2.txt 中的第 3 行出现了 1 次
题目二:编写 MapReduce 程序求出每个关键词在每个文档出现了多少次,并且按照出现次 数降序排序
例如:
huangixaoming mapreduce-4-1.txt,3;mapreduce-4-2.txt,1
以上答案的含义: 表示关键词 huangxiaoming 在第一份文档 mapreduce-4-1.txt 中出现了 3 次,在第二份文档mapreduce-4-2.txt 中出现了 1 次

