Hadoop学习之路(二十一)MapReduce实现Reduce Join(多个文件联合查询)
MapReduce Join
对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接。
如果数据量比较大,在内存进行连接操会发生OOM。mapreduce join可以用来解决大数据的连接。
1 思路
1.1 reduce join
在map阶段, 把关键字作为key输出,并在value中标记出数据是来自data1还是data2。因为在shuffle阶段已经自然按key分组,reduce阶段,判断每一个value是来自data1还是data2,在内部分成2组,做集合的乘积。
这种方法有2个问题:
1, map阶段没有对数据瘦身,shuffle的网络传输和排序性能很低。
2, reduce端对2个集合做乘积计算,很耗内存,容易导致OOM。
1.2 map join
两份数据中,如果有一份数据比较小,小数据全部加载到内存,按关键字建立索引。大数据文件作为map的输入文件,对map()函数每一对输入,都能够方便地和已加载到内存的小数据进行连接。把连接结果按key输出,经过shuffle阶段,reduce端得到的就是已经按key分组的,并且连接好了的数据。
这种方法,要使用hadoop中的DistributedCache把小数据分布到各个计算节点,每个map节点都要把小数据库加载到内存,按关键字建立索引。
这种方法有明显的局限性:有一份数据比较小,在map端,能够把它加载到内存,并进行join操作。
1.3 使用内存服务器,扩大节点的内存空间
针对map join,可以把一份数据存放到专门的内存服务器,在map()方法中,对每一个<key,value>的输入对,根据key到内存服务器中取出数据,进行连接
1.4 使用BloomFilter过滤空连接的数据
对其中一份数据在内存中建立BloomFilter,另外一份数据在连接之前,用BloomFilter判断它的key是否存在,如果不存在,那这个记录是空连接,可以忽略。
1.5 使用mapreduce专为join设计的包
在mapreduce包里看到有专门为join设计的包,对这些包还没有学习,不知道怎么使用,只是在这里记录下来,作个提醒。
jar: mapreduce-client-core.jar
package: org.apache.hadoop.mapreduce.lib.join
2 实现reduce join
两个文件,此处只写出部分数据,测试数据movies.dat数据量为3883条,ratings.dat数据量为1000210条数据
movies.dat 数据格式为:1 :: Toy Story (1995) :: Animation|Children's|Comedy
对应字段中文解释: 电影ID 电影名字 电影类型
ratings.dat 数据格式为:1 :: 1193 :: 5 :: 978300760
对应字段中文解释: 用户ID 电影ID 评分 评分时间戳
2个文件进行关联实现代码


1 import java.io.IOException; 2 import java.net.URI; 3 import java.util.ArrayList; 4 import java.util.List; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.IntWritable; 10 import org.apache.hadoop.io.LongWritable; 11 import org.apache.hadoop.io.Text; 12 import org.apache.hadoop.mapreduce.Job; 13 import org.apache.hadoop.mapreduce.Mapper; 14 import org.apache.hadoop.mapreduce.Reducer; 15 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 16 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 17 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 18 19 public class MovieMR1 { 20 21 public static void main(String[] args) throws Exception { 22 23 Configuration conf1 = new Configuration(); 24 /*conf1.set("fs.defaultFS", "hdfs://hadoop1:9000/"); 25 System.setProperty("HADOOP_USER_NAME", "hadoop");*/ 26 FileSystem fs1 = FileSystem.get(conf1); 27 28 29 Job job = Job.getInstance(conf1); 30 31 job.setJarByClass(MovieMR1.class); 32 33 job.setMapperClass(MoviesMapper.class); 34 job.setReducerClass(MoviesReduceJoinReducer.class); 35 36 job.setMapOutputKeyClass(Text.class); 37 job.setMapOutputValueClass(Text.class); 38 39 job.setOutputKeyClass(Text.class); 40 job.setOutputValueClass(Text.class); 41 42 Path inputPath1 = new Path("D:\\MR\\hw\\movie\\input\\movies"); 43 Path inputPath2 = new Path("D:\\MR\\hw\\movie\\input\\ratings"); 44 Path outputPath1 = new Path("D:\\MR\\hw\\movie\\output"); 45 if(fs1.exists(outputPath1)) { 46 fs1.delete(outputPath1, true); 47 } 48 FileInputFormat.addInputPath(job, inputPath1); 49 FileInputFormat.addInputPath(job, inputPath2); 50 FileOutputFormat.setOutputPath(job, outputPath1); 51 52 boolean isDone = job.waitForCompletion(true); 53 System.exit(isDone ? 0 : 1); 54 } 55 56 57 public static class MoviesMapper extends Mapper<LongWritable, Text, Text, Text>{ 58 59 Text outKey = new Text(); 60 Text outValue = new Text(); 61 StringBuilder sb = new StringBuilder(); 62 63 protected void map(LongWritable key, Text value,Context context) throws java.io.IOException ,InterruptedException { 64 65 FileSplit inputSplit = (FileSplit)context.getInputSplit(); 66 String name = inputSplit.getPath().getName(); 67 String[] split = value.toString().split("::"); 68 sb.setLength(0); 69 70 if(name.equals("movies.dat")) { 71 // 1 :: Toy Story (1995) :: Animation|Children's|Comedy 72 //对应字段中文解释: 电影ID 电影名字 电影类型 73 outKey.set(split[0]); 74 StringBuilder append = sb.append(split[1]).append("\t").append(split[2]); 75 String str = "movies#"+append.toString(); 76 outValue.set(str); 77 //System.out.println(outKey+"---"+outValue); 78 context.write(outKey, outValue); 79 }else{ 80 // 1 :: 1193 :: 5 :: 978300760 81 //对应字段中文解释: 用户ID 电影ID 评分 评分时间戳 82 outKey.set(split[1]); 83 StringBuilder append = sb.append(split[0]).append("\t").append(split[2]).append("\t").append(split[3]); 84 String str = "ratings#" + append.toString(); 85 outValue.set(str); 86 //System.out.println(outKey+"---"+outValue); 87 context.write(outKey, outValue); 88 } 89 90 }; 91 92 } 93 94 95 public static class MoviesReduceJoinReducer extends Reducer<Text, Text, Text, Text>{ 96 //用来存放 电影ID 电影名称 电影类型 97 List<String> moviesList = new ArrayList<>(); 98 //用来存放 电影ID 用户ID 用户评分 时间戳 99 List<String> ratingsList = new ArrayList<>(); 100 Text outValue = new Text(); 101 102 @Override 103 protected void reduce(Text key, Iterable<Text> values, Context context) 104 throws IOException, InterruptedException { 105 106 int count = 0; 107 108 //迭代集合 109 for(Text text : values) { 110 111 //将集合中的元素添加到对应的list中 112 if(text.toString().startsWith("movies#")) { 113 String string = text.toString().split("#")[1]; 114 115 moviesList.add(string); 116 }else if(text.toString().startsWith("ratings#")){ 117 String string = text.toString().split("#")[1]; 118 ratingsList.add(string); 119 } 120 } 121 122 //获取2个集合的长度 123 long moviesSize = moviesList.size(); 124 long ratingsSize = ratingsList.size(); 125 126 for(int i=0;i<moviesSize;i++) { 127 for(int j=0;j<ratingsSize;j++) { 128 outValue.set(moviesList.get(i)+"\t"+ratingsList.get(j)); 129 //最后的输出是 电影ID 电影名称 电影类型 用户ID 用户评分 时间戳 130 context.write(key, outValue); 131 } 132 } 133 134 moviesList.clear(); 135 ratingsList.clear(); 136 137 } 138 139 } 140 141 }
最后的合并结果: 电影ID 电影名称 电影类型 用户ID 用户评论 时间戳
3 实现map join
两个文件,此处只写出部分数据,测试数据movies.dat数据量为3883条,ratings.dat数据量为1000210条数据
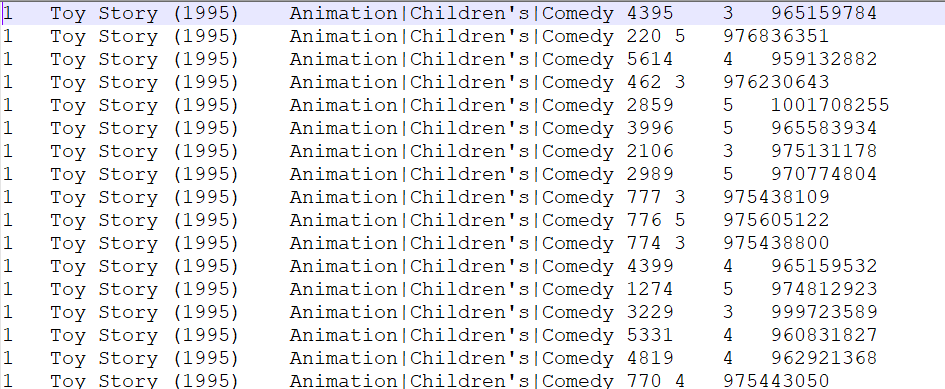
movies.dat 数据格式为:1 :: Toy Story (1995) :: Animation|Children's|Comedy
对应字段中文解释: 电影ID 电影名字 电影类型
ratings.dat 数据格式为:1 :: 1193 :: 5 :: 978300760
对应字段中文解释: 用户ID 电影ID 评分 评分时间戳
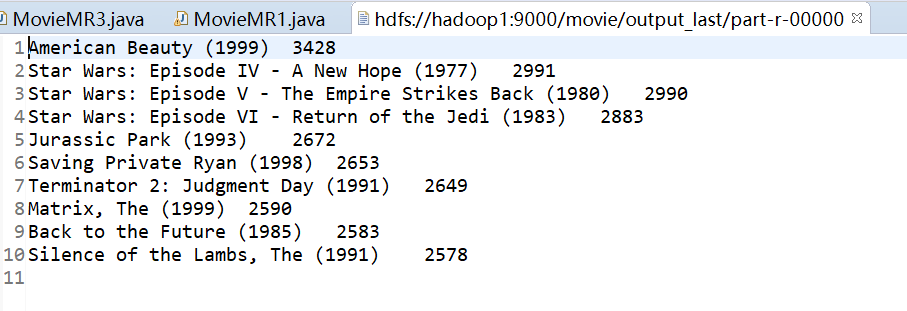
需求:求被评分次数最多的10部电影,并给出评分次数(电影名,评分次数)
实现代码
MovieMR1_1.java
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.WritableComparable; 6 7 public class MovieRating implements WritableComparable<MovieRating>{ 8 private String movieName; 9 private int count; 10 11 public String getMovieName() { 12 return movieName; 13 } 14 public void setMovieName(String movieName) { 15 this.movieName = movieName; 16 } 17 public int getCount() { 18 return count; 19 } 20 public void setCount(int count) { 21 this.count = count; 22 } 23 24 public MovieRating() {} 25 26 public MovieRating(String movieName, int count) { 27 super(); 28 this.movieName = movieName; 29 this.count = count; 30 } 31 32 33 @Override 34 public String toString() { 35 return movieName + "\t" + count; 36 } 37 @Override 38 public void readFields(DataInput in) throws IOException { 39 movieName = in.readUTF(); 40 count = in.readInt(); 41 } 42 @Override 43 public void write(DataOutput out) throws IOException { 44 out.writeUTF(movieName); 45 out.writeInt(count); 46 } 47 @Override 48 public int compareTo(MovieRating o) { 49 return o.count - this.count ; 50 } 51 52 }
MovieMR1_2.java
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.FileSystem; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.LongWritable; 7 import org.apache.hadoop.io.NullWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.Reducer; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 14 15 public class MovieMR1_2 { 16 17 public static void main(String[] args) throws Exception { 18 if(args.length < 2) { 19 args = new String[2]; 20 args[0] = "/movie/output/"; 21 args[1] = "/movie/output_last/"; 22 } 23 24 25 Configuration conf1 = new Configuration(); 26 conf1.set("fs.defaultFS", "hdfs://hadoop1:9000/"); 27 System.setProperty("HADOOP_USER_NAME", "hadoop"); 28 FileSystem fs1 = FileSystem.get(conf1); 29 30 31 Job job = Job.getInstance(conf1); 32 33 job.setJarByClass(MovieMR1_2.class); 34 35 job.setMapperClass(MoviesMapJoinRatingsMapper2.class); 36 job.setReducerClass(MovieMR1Reducer2.class); 37 38 39 job.setMapOutputKeyClass(MovieRating.class); 40 job.setMapOutputValueClass(NullWritable.class); 41 42 job.setOutputKeyClass(MovieRating.class); 43 job.setOutputValueClass(NullWritable.class); 44 45 46 Path inputPath1 = new Path(args[0]); 47 Path outputPath1 = new Path(args[1]); 48 if(fs1.exists(outputPath1)) { 49 fs1.delete(outputPath1, true); 50 } 51 //对第一步的输出结果进行降序排序 52 FileInputFormat.setInputPaths(job, inputPath1); 53 FileOutputFormat.setOutputPath(job, outputPath1); 54 55 boolean isDone = job.waitForCompletion(true); 56 System.exit(isDone ? 0 : 1); 57 58 59 } 60 61 //注意输出类型为自定义对象MovieRating,MovieRating按照降序排序 62 public static class MoviesMapJoinRatingsMapper2 extends Mapper<LongWritable, Text, MovieRating, NullWritable>{ 63 64 MovieRating outKey = new MovieRating(); 65 66 @Override 67 protected void map(LongWritable key, Text value, Context context) 68 throws IOException, InterruptedException { 69 //'Night Mother (1986) 70 70 String[] split = value.toString().split("\t"); 71 72 outKey.setCount(Integer.parseInt(split[1]));; 73 outKey.setMovieName(split[0]); 74 75 context.write(outKey, NullWritable.get()); 76 77 } 78 79 } 80 81 //排序之后自然输出,只取前10部电影 82 public static class MovieMR1Reducer2 extends Reducer<MovieRating, NullWritable, MovieRating, NullWritable>{ 83 84 Text outKey = new Text(); 85 int count = 0; 86 87 @Override 88 protected void reduce(MovieRating key, Iterable<NullWritable> values,Context context) throws IOException, InterruptedException { 89 90 for(NullWritable value : values) { 91 count++; 92 if(count > 10) { 93 return; 94 } 95 context.write(key, value); 96 97 } 98 99 } 100 101 } 102 }
MovieRating.java
1 import java.io.BufferedReader; 2 import java.io.FileReader; 3 import java.io.IOException; 4 import java.net.URI; 5 import java.util.HashMap; 6 import java.util.Map; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IntWritable; 12 import org.apache.hadoop.io.LongWritable; 13 import org.apache.hadoop.io.Text; 14 import org.apache.hadoop.mapreduce.Job; 15 import org.apache.hadoop.mapreduce.Mapper; 16 import org.apache.hadoop.mapreduce.Reducer; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 19 20 21 public class MovieMR1_1 { 22 23 public static void main(String[] args) throws Exception { 24 25 if(args.length < 4) { 26 args = new String[4]; 27 args[0] = "/movie/input/"; 28 args[1] = "/movie/output/"; 29 args[2] = "/movie/cache/movies.dat"; 30 args[3] = "/movie/output_last/"; 31 } 32 33 34 Configuration conf1 = new Configuration(); 35 conf1.set("fs.defaultFS", "hdfs://hadoop1:9000/"); 36 System.setProperty("HADOOP_USER_NAME", "hadoop"); 37 FileSystem fs1 = FileSystem.get(conf1); 38 39 40 Job job1 = Job.getInstance(conf1); 41 42 job1.setJarByClass(MovieMR1_1.class); 43 44 job1.setMapperClass(MoviesMapJoinRatingsMapper1.class); 45 job1.setReducerClass(MovieMR1Reducer1.class); 46 47 job1.setMapOutputKeyClass(Text.class); 48 job1.setMapOutputValueClass(IntWritable.class); 49 50 job1.setOutputKeyClass(Text.class); 51 job1.setOutputValueClass(IntWritable.class); 52 53 54 55 //缓存普通文件到task运行节点的工作目录 56 URI uri = new URI("hdfs://hadoop1:9000"+args[2]); 57 System.out.println(uri); 58 job1.addCacheFile(uri); 59 60 Path inputPath1 = new Path(args[0]); 61 Path outputPath1 = new Path(args[1]); 62 if(fs1.exists(outputPath1)) { 63 fs1.delete(outputPath1, true); 64 } 65 FileInputFormat.setInputPaths(job1, inputPath1); 66 FileOutputFormat.setOutputPath(job1, outputPath1); 67 68 boolean isDone = job1.waitForCompletion(true); 69 System.exit(isDone ? 0 : 1); 70 71 } 72 73 public static class MoviesMapJoinRatingsMapper1 extends Mapper<LongWritable, Text, Text, IntWritable>{ 74 75 //用了存放加载到内存中的movies.dat数据 76 private static Map<String,String> movieMap = new HashMap<>(); 77 //key:电影ID 78 Text outKey = new Text(); 79 //value:电影名+电影类型 80 IntWritable outValue = new IntWritable(); 81 82 83 /** 84 * movies.dat: 1::Toy Story (1995)::Animation|Children's|Comedy 85 * 86 * 87 * 将小表(movies.dat)中的数据预先加载到内存中去 88 * */ 89 @Override 90 protected void setup(Context context) throws IOException, InterruptedException { 91 92 Path[] localCacheFiles = context.getLocalCacheFiles(); 93 94 String strPath = localCacheFiles[0].toUri().toString(); 95 96 BufferedReader br = new BufferedReader(new FileReader(strPath)); 97 String readLine; 98 while((readLine = br.readLine()) != null) { 99 100 String[] split = readLine.split("::"); 101 String movieId = split[0]; 102 String movieName = split[1]; 103 String movieType = split[2]; 104 105 movieMap.put(movieId, movieName+"\t"+movieType); 106 } 107 108 br.close(); 109 } 110 111 112 /** 113 * movies.dat: 1 :: Toy Story (1995) :: Animation|Children's|Comedy 114 * 电影ID 电影名字 电影类型 115 * 116 * ratings.dat: 1 :: 1193 :: 5 :: 978300760 117 * 用户ID 电影ID 评分 评分时间戳 118 * 119 * value: ratings.dat读取的数据 120 * */ 121 @Override 122 protected void map(LongWritable key, Text value, Context context) 123 throws IOException, InterruptedException { 124 125 String[] split = value.toString().split("::"); 126 127 String userId = split[0]; 128 String movieId = split[1]; 129 String movieRate = split[2]; 130 131 //根据movieId从内存中获取电影名和类型 132 String movieNameAndType = movieMap.get(movieId); 133 String movieName = movieNameAndType.split("\t")[0]; 134 String movieType = movieNameAndType.split("\t")[1]; 135 136 outKey.set(movieName); 137 outValue.set(Integer.parseInt(movieRate)); 138 139 context.write(outKey, outValue); 140 141 } 142 143 } 144 145 146 public static class MovieMR1Reducer1 extends Reducer<Text, IntWritable, Text, IntWritable>{ 147 //每部电影评论的次数 148 int count; 149 //评分次数 150 IntWritable outValue = new IntWritable(); 151 152 @Override 153 protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { 154 155 count = 0; 156 157 for(IntWritable value : values) { 158 count++; 159 } 160 161 outValue.set(count); 162 163 context.write(key, outValue); 164 } 165 166 } 167 168 169 }
最后的结果