

XML DTD约束 对xml文件的crud的查询Read Retrieve操作 xml递归遍历

本地的dtd文档
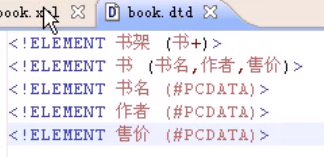
xml中引入dtd文档
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE 书架 SYSTEM "book.dtd">
<书架>
<书>
<书名>Java就业培训教程</书名>
<作者>张孝祥</作者>
<售价>39.00</售价>
</书>
<书>
<书名>JavaScript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00</售价>
</书>
<狗></狗>
</书架>
引入后,发现狗狗是不合法的,必须符合dtd约束
根据下面dtd文档生成xml文档
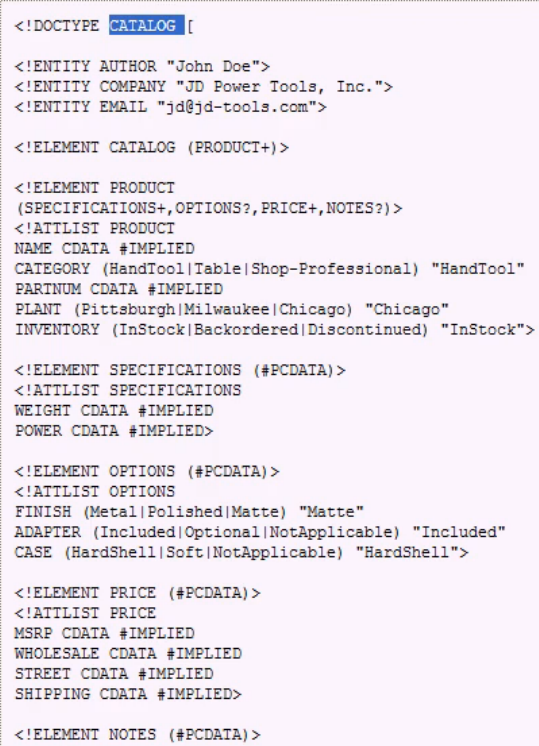
当中有正则,其中+表示一次或多次 ?表示0次或多次 *表示0次或多次
dtd的约束无法约束数字等特有表达,只能字符串,所以基本被淘汰
package com.swift.xml; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class DemoXML { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse("src/index.xml"); NodeList list = document.getElementsByTagName("书"); Node node = list.item(1); // 拿到书的所有文本 String text = node.getTextContent(); System.out.println(text); // 得到根节点 Node root = document.getElementsByTagName("书架").item(0); // 递归遍历不包括文本 traverse(root); } private static void traverse(Node root) { if (root instanceof Element) { System.out.println(root.getNodeName()); } NodeList list = root.getChildNodes(); for (int i = 0; i < list.getLength(); i++) { Node node = list.item(i); traverse(node); } } }
查询与递归操作
其中要注意:Element类的包导入有很多选择,这里要选择w3c的
Never waste time any more, Never old man be a yong man

