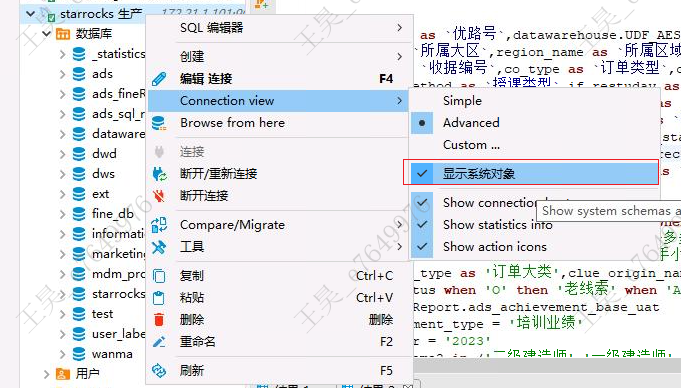
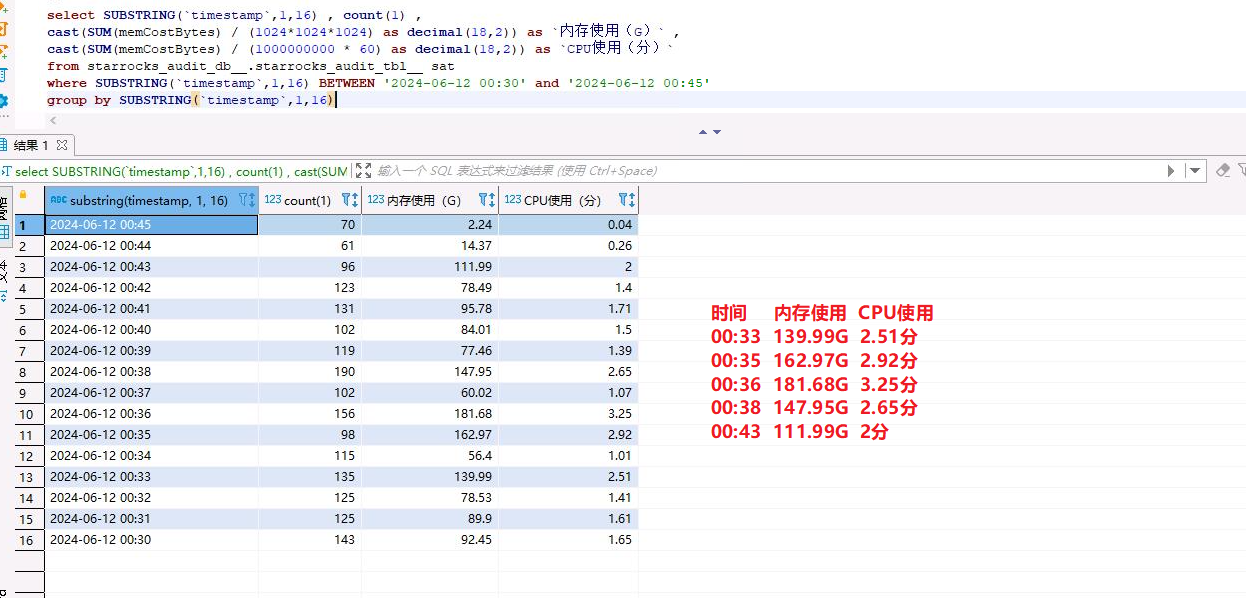
7-3、性能优化排查案例: 00:30 至 00:45 starrocks 数据库告警 内存 CPU 使用
selectSUBSTRING(`timestamp`,1,16) , count(1) ,
cast(SUM(memCostBytes) / (1024*1024*1024) asdecimal(18,2)) as `内存使用(G)` ,
cast(SUM(memCostBytes) / (1000000000*60) asdecimal(18,2)) as `CPU使用(分)`
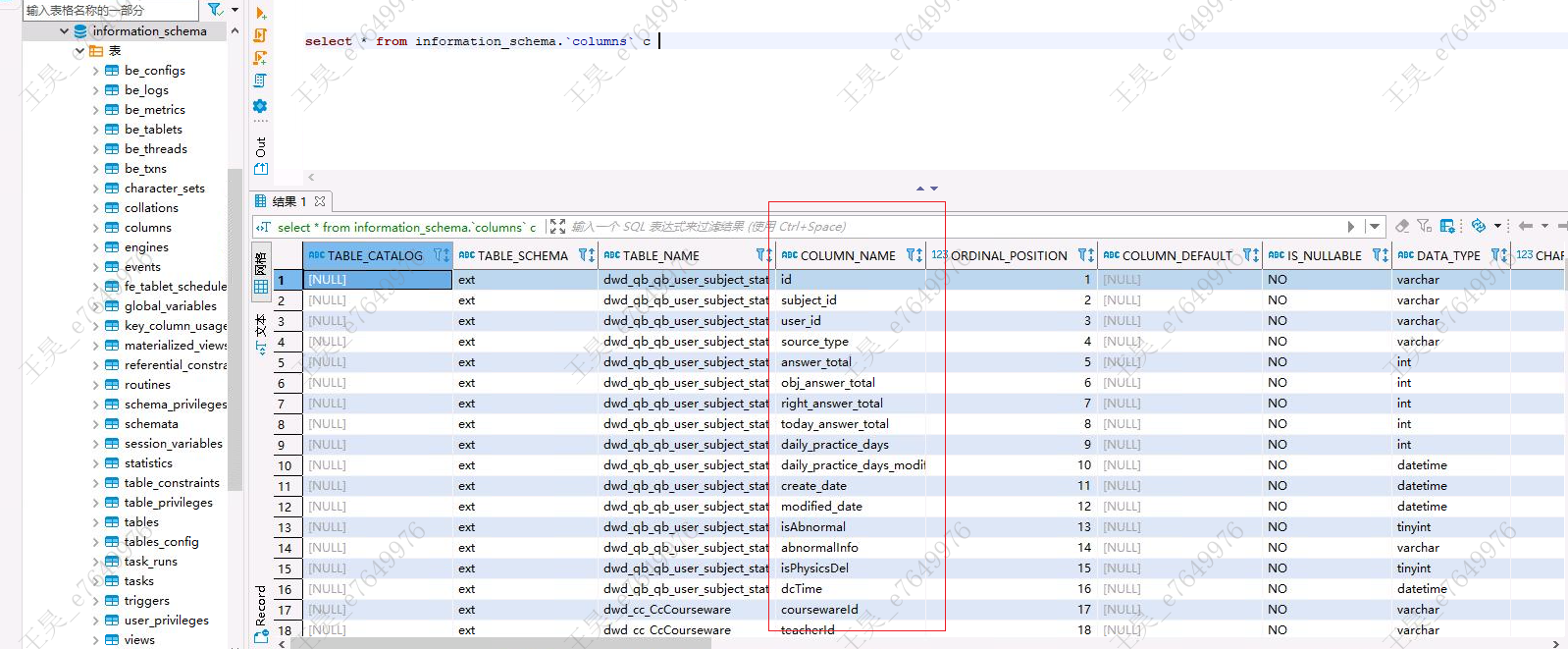
from starrocks_audit_db__.starrocks_audit_tbl__ sat
whereSUBSTRING(`timestamp`,1,16) BETWEEN'2024-06-12 00:30'and'2024-06-12 00:45'groupbySUBSTRING(`timestamp`,1,16)
orderbySUBSTRING(`timestamp`,1,16) desc
--select'00:35'as `时间`, temp_01.db as `数据库` , temp_01.num as `查询数量`, temp_01.内存使用(G), temp_01.CPU使用(分),
'00:36'as `时间`, temp_02.db as `数据库` , temp_02.num as `查询数量`, temp_02.内存使用(G), temp_02.CPU使用(分),
'00:37'as `时间`, temp_03.db as `数据库` , temp_03.num as `查询数量`, temp_03.内存使用(G), temp_03.CPU使用(分)
from (
select db , count(1) as num,
cast(SUM(memCostBytes) / (1024*1024*1024) asdecimal(18,2)) as `内存使用(G)` ,
cast(SUM(memCostBytes) / (1000000000*60) asdecimal(18,2)) as `CPU使用(分)`
from starrocks_audit_db__.starrocks_audit_tbl__ sat
whereSUBSTRING(`timestamp`,1,16) ='2024-06-12 00:35'groupby db
) temp_01
leftjoin (
select db , count(1) as num,
cast(SUM(memCostBytes) / (1024*1024*1024) asdecimal(18,2)) as `内存使用(G)` ,
cast(SUM(memCostBytes) / (1000000000*60) asdecimal(18,2)) as `CPU使用(分)`
from starrocks_audit_db__.starrocks_audit_tbl__ sat
whereSUBSTRING(`timestamp`,1,16) ='2024-06-12 00:36'groupby db
) temp_02 on temp_01.db = temp_02.db
leftjoin (
select db , count(1) as num,
cast(SUM(memCostBytes) / (1024*1024*1024) asdecimal(18,2)) as `内存使用(G)` ,
cast(SUM(memCostBytes) / (1000000000*60) asdecimal(18,2)) as `CPU使用(分)`
from starrocks_audit_db__.starrocks_audit_tbl__ sat
whereSUBSTRING(`timestamp`,1,16) ='2024-06-12 00:37'groupby db
) temp_03 on temp_01.db = temp_03.db
select temp_01.stmt as `SQL语句` ,
'00:34'as `时间`, temp_03.num as `查询数量`, temp_03.内存使用(G), temp_03.CPU使用(分),
'00:35'as `时间`, temp_02.num as `查询数量`, temp_02.内存使用(G), temp_02.CPU使用(分),
'00:36'as `时间`, temp_01.num as `查询数量`, temp_01.内存使用(G), temp_01.CPU使用(分),
'00:37'as `时间`, temp_04.num as `查询数量`, temp_04.内存使用(G), temp_04.CPU使用(分)
from (
selectleft(stmt, 100) as stmt , count(1) as num,
cast(SUM(memCostBytes) / (1024*1024*1024) asdecimal(18,2)) as `内存使用(G)` ,
cast(SUM(memCostBytes) / (1000000000*60) asdecimal(18,2)) as `CPU使用(分)`
from starrocks_audit_db__.starrocks_audit_tbl__ sat
whereSUBSTRING(`timestamp`,1,16) ='2024-06-12 00:36'and db ='datawarehouse'groupbyleft(stmt, 100)
) temp_01
leftjoin (
selectleft(stmt, 100) as stmt , count(1) as num,
cast(SUM(memCostBytes) / (1024*1024*1024) asdecimal(18,2)) as `内存使用(G)` ,
cast(SUM(memCostBytes) / (1000000000*60) asdecimal(18,2)) as `CPU使用(分)`
from starrocks_audit_db__.starrocks_audit_tbl__ sat
whereSUBSTRING(`timestamp`,1,16) ='2024-06-12 00:35'and db ='datawarehouse'groupbyleft(stmt, 100)
) temp_02 on temp_01.stmt = temp_02.stmt
leftjoin (
selectleft(stmt, 100) as stmt , count(1) as num,
cast(SUM(memCostBytes) / (1024*1024*1024) asdecimal(18,2)) as `内存使用(G)` ,
cast(SUM(memCostBytes) / (1000000000*60) asdecimal(18,2)) as `CPU使用(分)`
from starrocks_audit_db__.starrocks_audit_tbl__ sat
whereSUBSTRING(`timestamp`,1,16) ='2024-06-12 00:34'and db ='datawarehouse'groupbyleft(stmt, 100)
) temp_03 on temp_01.stmt = temp_03.stmt
leftjoin (
selectleft(stmt, 100) as stmt , count(1) as num,
cast(SUM(memCostBytes) / (1024*1024*1024) asdecimal(18,2)) as `内存使用(G)` ,
cast(SUM(memCostBytes) / (1000000000*60) asdecimal(18,2)) as `CPU使用(分)`
from starrocks_audit_db__.starrocks_audit_tbl__ sat
whereSUBSTRING(`timestamp`,1,16) ='2024-06-12 00:37'and db ='datawarehouse'groupbyleft(stmt, 100)
) temp_04 on temp_01.stmt = temp_04.stmt






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具