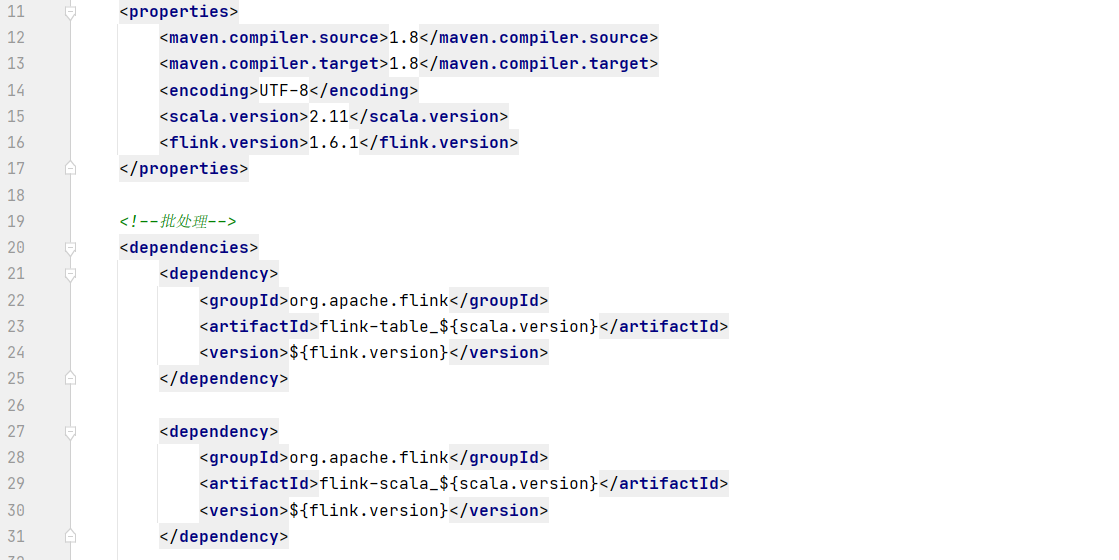
Maven 的pom文件
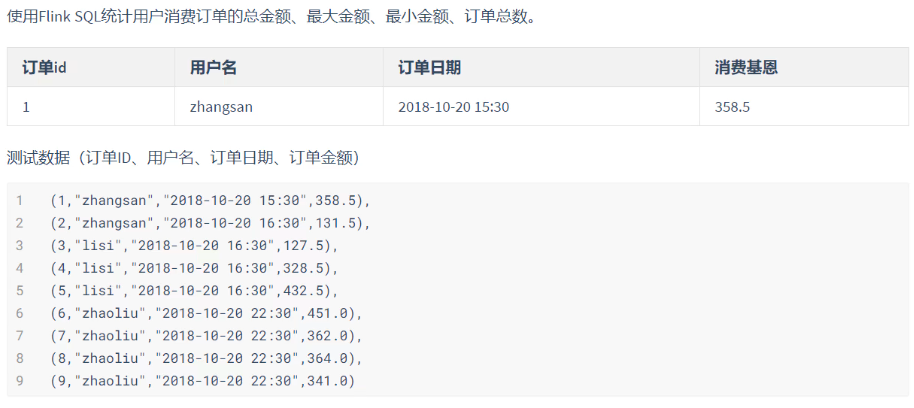
批数据处理案例01
代码实现:

package com.wanghao.sql
import org.apache.flink.api.scala._
import org.apache.flink.table.api.{Table, TableEnvironment}
import org.apache.flink.types.Row
object BatchFlinkSqlDemo {
def main(args: Array[String]): Unit = {
// 1、获取一个批处理运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2、获取一个Table运行环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
// 4、基于本地'Order' 集合创建一个DataSet source
val dataSet:DataSet[Order] = env.fromCollection(List(
Order(1,"zhangsan","2023-3-2 15:30", 310.01),
Order(2,"lisi","2023-3-2 15:30", 200.02),
Order(3,"zhangsan","2023-3-2 15:30", 400.01)
))
// 5、使用Table运行环境将DataSet注册为一个表
tableEnv.registerDataSet("t_order", dataSet)
// 6、使用SQL语句来操作数据(统计用户消费订单的总金额、最大金额、最小金额、订单总数)
val sql = "select username, " +
"sum(money) as totalMoney, " +
"max(money) as maxMoney, " +
"min(money) as minMoney, " +
"count(1) as totalCount " +
"from t_order group by username"
val table:Table = tableEnv.sqlQuery(sql)
// 7、使用TableEnv.ToDataSet 将Table转换为DataSet
val resultDataSet: DataSet[Row] = tableEnv.toDataSet[Row](table)
// 8、打印测试
resultDataSet.print()
}
// 3、创建一个样例类 ‘Order’ 用来映射数据(订单ID、用户名、订单日期、订单金额)
case class Order(id:Int, username:String, createtime:String, money:Double)
}
批数据处理案例02

代码实现:
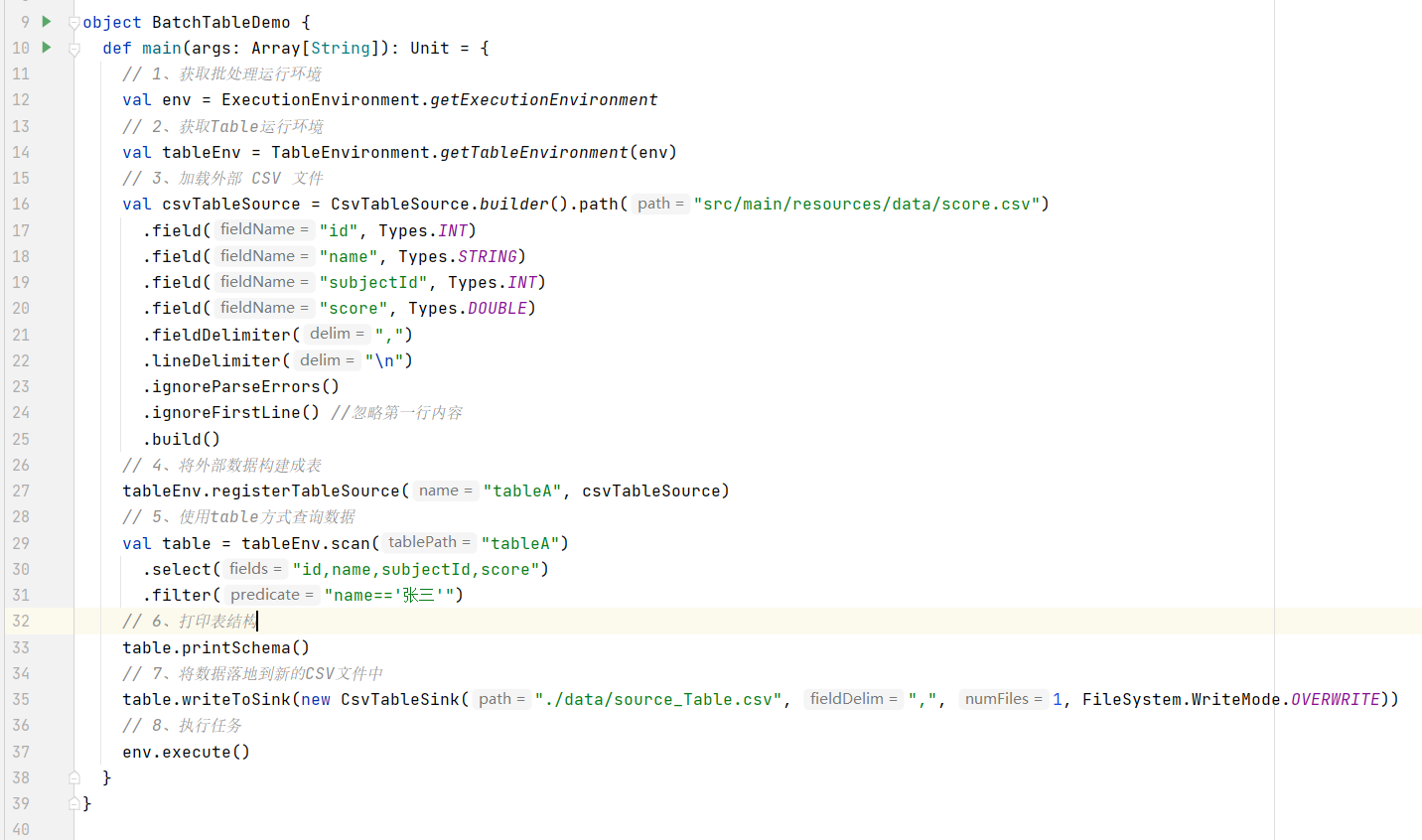
package com.wanghao.sql
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.core.fs.FileSystem
import org.apache.flink.table.api.{TableEnvironment, Types}
import org.apache.flink.table.sinks.CsvTableSink
import org.apache.flink.table.sources.CsvTableSource
object BatchTableDemo {
def main(args: Array[String]): Unit = {
// 1、获取批处理运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2、获取Table运行环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
// 3、加载外部 CSV 文件
val csvTableSource = CsvTableSource.builder().path("src/main/resources/data/score.csv")
.field("id", Types.INT)
.field("name", Types.STRING)
.field("subjectId", Types.INT)
.field("score", Types.DOUBLE)
.fieldDelimiter(",")
.lineDelimiter("\n")
.ignoreParseErrors()
.ignoreFirstLine() //忽略第一行内容
.build()
// 4、将外部数据构建成表
tableEnv.registerTableSource("tableA", csvTableSource)
// 5、使用table方式查询数据
val table = tableEnv.scan("tableA")
.select("id,name,subjectId,score")
.filter("name=='张三'")
// 6、打印表结构
table.printSchema()
// 7、将数据落地到新的CSV文件中
table.writeToSink(new CsvTableSink("./data/source_Table.csv", ",", 1, FileSystem.WriteMode.OVERWRITE))
// 8、执行任务
env.execute()
}
}
流数据处理案例
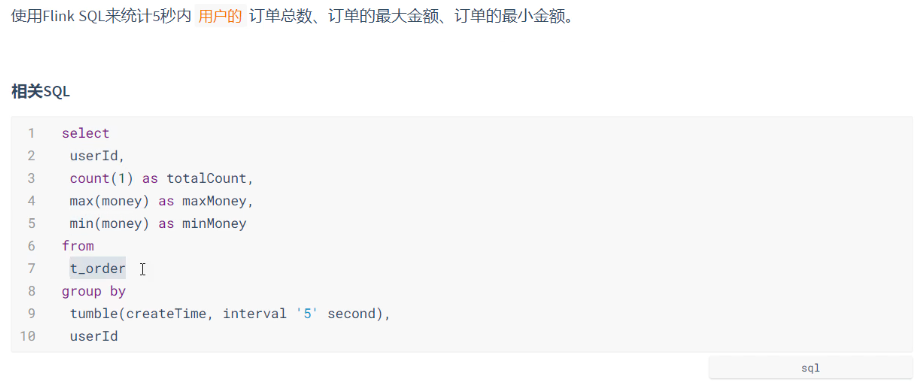
代码实现:


package com.wanghao.sql
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.api.{Table, TableEnvironment}
import org.apache.flink.types.Row
import java.util.UUID
import java.util.concurrent.TimeUnit
import scala.util.Random
object SteamFlinkSqlDemo {
case class Order(id:String, userId:Int,money:Int,createTime:Long)
def main(args: Array[String]): Unit = {
// 1、获取流处理运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2、获取Table运行环境
val tableEnv : StreamTableEnvironment = TableEnvironment.getTableEnvironment(env)
// 3、设置处理时间为'EventTime'
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 5、创建一个自定义数据源
val orderDataStream:DataStream[Order] = env.addSource(new RichSourceFunction[Order] {
override def run(ctx: SourceFunction.SourceContext[Order]): Unit = {
// -使用for循环生成1000个订单
for (i <- 0 until 1000) {
// -随机生成订单ID (UUID)
val id = UUID.randomUUID().toString
// -随机生成用户ID(0-2)
val userId = Random.nextInt(3)
// -随机生成订单金额(0-100)
val money = Random.nextInt(101)
// - 时间戳为当前系统时间
val createtime = System.currentTimeMillis()
// 收集数据
ctx.collect(Order(id,userId,money,createtime))
// - 每隔1秒生成一个订单
TimeUnit.SECONDS.sleep(1)
}
}
override def cancel(): Unit = {
}
})
// 6、添加水印,允许延时2秒
val waterDataStream = orderDataStream.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[Order] {
var currentTimeStamp = 0L
// 获取水印
override def getCurrentWatermark: Watermark = {
new Watermark(currentTimeStamp - 2000)
}
// 获取当前时间
override def extractTimestamp(element: Order, previousElementTimestamp: Long): Long = {
currentTimeStamp = Math.max(element.createTime, previousElementTimestamp)
currentTimeStamp
}
})
// 7、导入 import org.apache.flink.table.api.scala._ 隐式参数
import org.apache.flink.table.api.scala._
// 8、使用'registerDataStream' 注册表,并分别指定字段,还要指定rowtime字段
tableEnv.registerDataStream("t_order", waterDataStream, 'id, 'userId, 'money, 'createtime.rowtime)
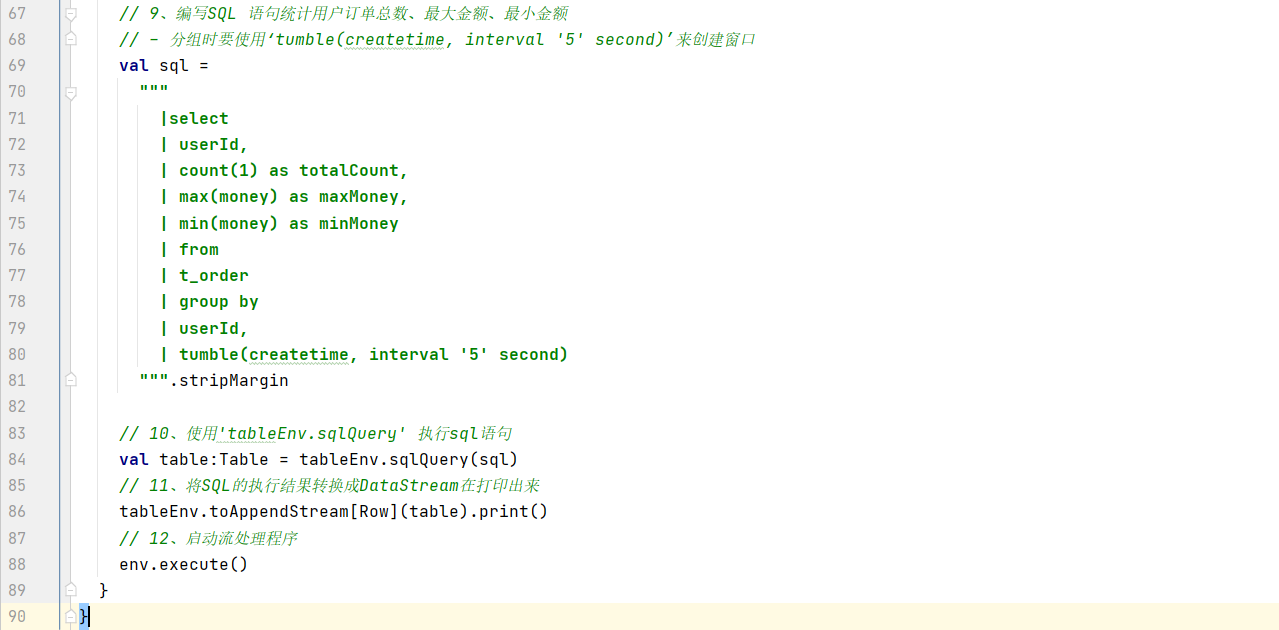
// 9、编写SQL 语句统计用户订单总数、最大金额、最小金额
// - 分组时要使用‘tumble(createtime, interval '5' second)’来创建窗口
val sql =
"""
|select
| userId,
| count(1) as totalCount,
| max(money) as maxMoney,
| min(money) as minMoney
| from
| t_order
| group by
| userId,
| tumble(createtime, interval '5' second)
""".stripMargin
// 10、使用'tableEnv.sqlQuery' 执行sql语句
val table:Table = tableEnv.sqlQuery(sql)
// 11、将SQL的执行结果转换成DataStream在打印出来
tableEnv.toAppendStream[Row](table).print()
// 12、启动流处理程序
env.execute()
}
}



