从关系型数据库到非关系型数据库的发展
关系型数据库
自1970年,埃德加·科德提出关系模型之后,关系数据库便开始出现,经过了40多年的演化,如今的关系型数据库具备了强大的存储、维护、查询数据的能力。但在关系数据库日益强大的时候,人们发现,在这个信息爆炸的“大数据”时代,关系型数据库遇到了性能方面的瓶颈,面对一个表中上亿条的数据,SQL语句在大数据的查询方面效率欠佳。我们应该知道,往往添加了越多的约束的技术,在一定程度上定会拖延其效率。
非关系型数据库
在1998年,Carlo Strozzi提出NOSQL的概念,指的是他开发的一个没有SQL功能,轻量级的,开源的关系型数据库。注意,这个定义跟我们现在对NoSQL的定义有很大的区别,它确确实实字如其名,指的就是“没有SQL”的数据库。但是NoSQL的发展慢慢偏离了初衷,CarloStrozzi也发觉,其实我们要的不是"nosql",而应该是"norelational",也就是我们现在常说的非关系型数据库了。
NoSQL的简介
NoSQL的概念
非关系型数据库提出另一种理念,他以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,用户可以根据需要去添加自己需要的字段,这样,为了获取用户的不同信息,不需要像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。但非关系型数据库由于很少的约束,他也不能够提供想SQL所提供的where这种对于字段属性值情况的查询。并且难以体现设计的完整性。他只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,SQL数据库显得更为合适。
目前出现的NoSQL(Not only SQL,非关系型数据库)有不下于25种,除了Dynamo、Bigtable以外还有很多,比如Amazon的SimpleDB、微软公司的AzureTable、Facebook使用的Cassandra、类Bigtable的Hypertable、Hadoop的HBase、MongoDB、CouchDB、Redis以及Yahoo!的PNUTS等等。这些NoSQL各有特色,是基于不同应用场景而开发的,而其中以MongoDB和Redis最为被大家追捧。
NoSQL数据库的分类
1、键值(key-value)
2、列存储数据库
3、文档型数据库
4、图形(Graph)数据库
关系型数据库的瓶颈
1、高并发读写需求
网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈
2、海量数据的高效率读写
网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询,效率是非常低的
3、高扩展性和可用性
在基于web的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移。
4、对网站来说,关系型数据库的很多特性不再需要了:
事务一致性
关系型数据库在对事物一致性的维护中有很大的开销,而现在很多web2.0系统对事物的读写一致性都不高
读写实时性
对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比如发一条消息之后,过几秒乃至十几秒之后才看到这条动态是完全可以接受的
复杂SQL,特别是多表关联查询
任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询,特别是SNS类型的网站,从需求以及产品阶级角度,就避免了这种情况的产生。往往更多的只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能极大的弱化了
5、在关系型数据库中,导致性能欠佳的最主要原因是多表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询。为了保证数据库的ACID特性,我们必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一个格式化的数据结构。每个元组字段的组成都是一样,即使不是每个元组都需要所有的字段,但数据库会为每个元组分配所有的字段,这样的结构可以便于标语表之间进行链接等操作,但从另一个角度来说它也是关系型数据库性能瓶颈的一个因素。
关系型数据库瓶颈后对应的解决方案
1、Memcached + MySQL:
减轻数据的读取压力;
首次访问时:从RDBMS中取得数据保存到memcached中。
第二次访问时:直接从memcached中取得数据进行返回。
2、MySQL的主从读写分离
Memcached只能缓解读取压力,随着数据库的写入压力增加,读写集中在一个数据库上让数据库不堪重负;
可以使用主从复制技术来实现读写分离,以提高读写性能和读库的可扩展性。即Mysql的master-slave模式
3、分表分库
随着web2.0的继续高速发展,在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。
虽然MySQL推出了MySQL Cluster集群,但是由于在互联网几乎没有成功案例,性能也不能满足互联网的要求,只是在高可靠性上提供了非常大的保证。
MySQL的扩展型瓶颈
1、在互联网,大部分的MySQL都应该是IO密集型的,事实上,如果你的MySQL是个CPU密集型的话,那么很可能你的MySQL设计得有性能问题,需要优化了。大数据量高并发环境下的MySQL应用开发越来越复杂,也越来越具有技术挑战性。
2、分表分库的规则把握都是需要经验的。虽然有像淘宝这样技术实力强大的公司开发了透明的中间件层来屏蔽开发者的复杂性,但是避免不了整个架构的复杂性。分库分表的子库到一定阶段又面临扩展问题。还有就是需求的变更,可能又需要一种新的分库方式。
3、MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从MySQL省去,MySQL将变得非常的小。 关系数据库很强大,但是它并不能很好的应付所有的应用场景。
4、MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MySQL的开发人员面临的问题。
NoSQL的优势
1、易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
2、大数据量、高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了。
3、灵活的数据类型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。这点在大数据量的web2.0时代尤其明显。
4、高可用
NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如Cassandra,HBase模型,通过复制模型也能实现高可用。
NoSQL的应用场景
1、数据模型比较简单;
2、需要灵活性更强的IT系统;
3、对数据库性能要求较高;
4、不需要高度的数据一致性;
5、对于给定key,比较容易映射复杂值的环境。
Redis Ubuntu环境安装
卸载软件
sudo apt-get remove redis-server
清除配置
sudo apt-get remove --purge redis-server
删除残留文件
1、sudo find / -name redis:文档查找 名字
2、删除
sudo rm -rf var/lib/redis/
sudo rm -rf /var/log/redis
sudo rm -rf /etc/redis/
sudo rm -rf /usr/bin/redis-*
下载新的文档安装包
下载地址:http://redis.io/download
安装步骤
1、下载安装包
wget http://download.redis.io/releases/redis-3.2.8.tar.gz
2、解压
tar -zxvf redis-3.2.8.tar.gz
3、copy文件并ls查看
1、sudo mkdir -p /usr/local/redis/
2、sudo sudo mv ./redis-3.2.8 /usr/local/redis/
3、ls /usr/local/redis/
4、进入安装目录
cd /usr/local/redis/
5、翻译
1、首先打开README.md,翻阅基本build和install方式:sudo make
2、尝试环境是否可以正常使用(Hint: It's a good idea to run 'make test' ;):sudo make test
3、\o/ All tests passed without errors!:提示测试没有问题
6、生成
sudo make
7、测试,这段运⾏时间会较⻓
sudo make test
9、安装,将redis的命令安装到/usr/local/bin/⽬录
sudo make install
10、查看编译好的命令文件
ls /usr/local/bin/redis-*
11、修改配置文件
1、sudo mkdir /etc/redis
2、sudo cp redis.conf /etc/redis/
3、ls /etc/redis/redis.conf
安装后 sudo make test 报错
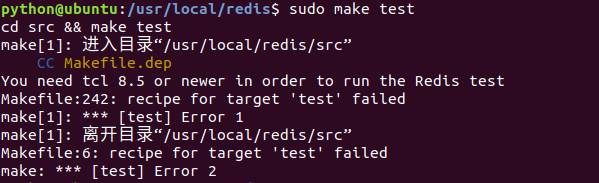
安装tcl 8.5
wget http://downloads.sourceforge.net/tcl/tcl8.6.1-src.tar.gz
sudo tar xzvf tcl8.6.1-src.tar.gz -C /usr/local/
cd /usr/local/tcl8.6.1/unix/
sudo ./configure
sudo make
sudo make install
Redis 配置文件位置和简单操作
Redis的配置信息在 /etc/redis/redis.conf 下
查看
sudo cat /etc/redis/redis.conf
修改
sudo vim /etc/redis/redis.conf
Redis 配置文件 redis.conf 核心配置说明:
# 绑定ip:如果需要远程访问,可将此⾏注释,或绑定⼀个真实ip
bind 127.0.0.1
# 端⼝,默认为6379
port 6379
# 是否以守护进程运⾏
# 如果以守护进程运⾏,则不会在命令⾏阻塞,类似于服务
# 如果以⾮守护进程运⾏,则当前终端被阻塞
# 设置为yes表示守护进程,设置为no表示⾮守护进程
# 推荐设置为yes
daemonize yes
# 数据⽂件
dbfilename dump.rdb
# 数据⽂件存储路径
dir /var/lib/redis
# ⽇志⽂件
logfile /var/log/redis/redis-server.log
# 数据库,默认有16个
database 16
# 主从复制,类似于双机备份。
slaveof
启动redis:redis-server 或 redis-server /etc/redis/redis.conf
连接redis服务器:redis-cli
Redis可视化客户端工具
项目地址: https://github.com/uglide/RedisDesktopManager
Redis 数据持久化
位置: /var/lib/redis/dump.rdb
Redis 的应用场景
1、取最新N个数据的操作
比如典型的取你网站的最新文章,我们可以将最新的5000条评论的ID放在Redis的List集合中,并将超出集合部分从数据库获取。
2、排行榜应用,取Top N操作
这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序, 这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score, 将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。
3、需要精确设定过期时间的应用
比如你可以把上面说到的sorted set的score值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序, 定时清除过期数据了,不仅是清除Redis中的过期数据,你完全可以把Redis里这个过期时间当成是对数据库中数据的索引, 用Redis来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录。
4、计数器应用
Redis的命令都是原子性的,你可以轻松地利用INCR,DECR命令来构建计数器系统。
5、uniq操作,获取某段时间所有数据排重值
这个使用Redis的set数据结构最合适了,只需要不断地将数据往set中扔就行了,set意为集合,所以会自动排重。
6、Pub/Sub构建实时消息系统
Redis的Pub/Sub系统可以构建实时的消息系统,比如很多用Pub/Sub构建的实时聊天系统的例子。
7、构建队列系统
使用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统。
8、缓存
最常用,性能优于Memcached(被libevent拖慢),数据结构更多样化。
Redis 数据类型
String 字符串
定义:String 是redis最基本的类型,value 不仅可以是 String,也可以是数字;使用 Strings 类型,可以完全实现目前 Memcached 的功能,并且效率更高。还可以享受 Redis 的定时持久化(可以选择 RDB 模式或者 AOF 模式);string类型是二进制安全的。意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象;string类型是Redis最基本的数据类型,一个键最大能存储512MB。
Hash 哈希
定义:Redis hash 是一个string类型的field和value的映射表,hash特别适合用于存储对象;Redis中每个hash可以存储2的32次方-1个键值对(40多亿)
List 列表
定义:列表类型可以存储一个有序的字符串列表,常用的操作时向列表两端添加元素,或者获得列表的某一个片段;列表类型内部是使用双向链表(double linked list)实现的,所以向列表两端添加元素的时间复杂度为O(I),获取越接近两端的元素,速度就越快。
Set 集合
定义:在集合中的每个元素都是不同的,且没有顺序。一个集合类型(set)键可以存储至多2的32次-1个字符串。集合类型的常用操作时向集合中加入或删除元素、判断某个元素是否存在等,由于集合类型在Redis内部是使用值为空的散列表(hash table)实现,所以这些操作的时间复杂度都是O(I)。最方便的是多个集合类型键之间还可以进行并集、交集、差集运算。
集合与列表的区别:
列表具有有序性,集合具有唯一性。
Zset(Sorted set:有序集合)
定义:在集合类型的基础上有序集合类型为集合中的每个元素都关联了一个分数,这使得我们不仅可以完成插入,删除和判断元素是否存在等集合类型支持的操作,还能够获得分数最高(或最低)的前N个元素,获得指定分数范围内的元素等与分数有关的操作。虽然集合中每个元素不同,但是他们的分数可以相同。
有序集合与列表比较:
1、相似处:
1、二者都是有序的。
2、二者都可以获得某一范围的元素。
2、区别:
1、列表类型是通过链表实现,获取靠近两端的数据速度快,当元素增加后,访问中间数据的速度会变慢。
2、有序集合类型是使用散列和跳跃表实现的,所以即使读取位于中间部分的数据速度也很快(时间复杂度O(log(N)))。
3、列表中不能简单的调整某个元素的位置,但是有序集合可以
4、有序集合要比列表类型更消耗内存。
Redis 相关操作指令
String 字符串命令:
1、set:设置key对应的值为string类型的value。
>set "name" "hello"
2、setnx(set if not exists):将key设置值为value,如果key不存在,这种情况下等同set命名;当key值存在,什么也不做。
>setnx "name" "hello"
3、setex:设置key对应字符串value,并且设置key在给定的seconds时间之后超时过期。
>setex "color" 10 "red"
>get "color" --- red
十秒过后
>get "color" --- (nil)
4、setrange:覆盖key对应的string的一部分,从指定的offset处开始,覆盖value的长度。
>set "email" "redis@126.com" --- "ok"
>setrange "email" 6 "gmail.com" --- (integer) 14
>get "email" --- redis@gmail.com
5、mset:一次设置多个值,成功返回ok表示所有的值都设置了,失败返回0表示没有任何值被设置。
>mset "key1" "python" "key2" "c++" --- "ok"
>get "key1" --- "hello"
>get "key2" --- "world"
6、mget:一次获取多个key的值,如果对应key不存在,则对应返回nil。
>mget "key1" "key2" "key3"
7、msetnx:对应给定的keys到他们相应的values上。只要有一个key已经存在,msetnx一个操作也不会执行。
>msetnx "key1" "hello" "key2" "world" --- (integer) 0
8、getset:设置key的值,并返回key的旧值。
>get "name" --- "hello"
>getset "name" "newName" --- "hello"
>get "name" --- "newName"
9、getrange key start end:获取指定key的value值的字符串。是由start和end的位移决定的。
>get "name" --- "newName"
>getrange "name" 1 3 --- "ewN"
10、incr 对key的值加1 操作
>set "age" 18 --- "ok"
>incr "age" --- (integer) 19
>get "age" ---"19"
11、incrby:用incr类似,加指定值,key不存在的时候会设置key,并认为原来的value值为0。
>incrby age 5 ---(integer) 24
>incrby age1111 5 --- (integer) 5
>get age1111 --- "5"
12、decr:对key的值做的事渐减操作,decr一个不存在key,则设置key为1.
>get age --- "24"
>decr age --- "23"
13、decrby:同decr,减指定值,key不存在的时候会设置key,并认为原来的value值为1.
>get age --- "23"
>decrby age 10 --- "13"
14、append:给指定key的字符串值追加value,返回新字符串值的长度。例如我们向name的值追加一个"redis"字符串:
>set "name" "value" --- OK
>append "name" "_newValue" --- (integer) 14
>get "name" ---"value_newValue"
Hash 哈希
1、hset:设置指定的hash field1。
>hset "myhash" "field1" "hello" --- (integer) 1
2、hsetnx:只在key指定的哈希集中不存在的字段时,设置字段的值。如果key指定的哈希集不存在,会创建一个新的哈希集并与 key 关联。如果字段已存在,该操作无效果。
>hsetnx "myhash" "field1" "hello"。 --- (integer) 1
3、hmset:同时设置hash多个field。
>hmset "myhash" "field1" "hello" "field2" "world" ---OK
4、hget:获取指定的hash值的field。
>hget "myhash" "field1" --- "hello"
5、hgetall:获取所有的hash值的数据。
>hgetall "myhash" ---
1) "field1"
2) "hello"
3) "field2"
4) "world"
6、hmget:获取hash值的多个field值。
>hmget "myhash" "field1" "field2" "field3" ---
1) "hello"
2) "world"
3) (nil)
7、hincrby:指定的hash field值,加上给定的值。
>hset "myhash" "field3" "0" --- (integer) 1
>hincrby "myhash" "field3" 1 --- (integer) 1
>hincrby "myhash" "field3" -8 --- (integer) -7
8、hexists:测试指定field是否存在。
>hexists "myhash" "field1" --- (integer) 1
>hexists "myhash" "field9" --- (integer) 0
9、hkeys:查看指定哈希中所有的key值。
>hkeys "myhash" ---
1) "field1"
2) "field2"
3) "field3"
10、hdel:从key指定的哈希集中移除指定的域。
>hdel "myhash" "field1" --- (integer) 1
11、hlen:返回指定hash的field数量。
>hlen "myhash" --- (integer) 2
12、hvals:返回指定hash中所有的value值。
>hvals "myhash" ---
1) "world"
2) "-7"
List 列表
1、lpush:从左边向list列表中插入数据。
>lpush "mylist" "100001"
>lpush "mylist" "100002"
>lpush "mylist" "100003" "100004"
2、rpush:从右边向list列表中插入数据。
>rpush "mylist" "100005"
>rpush "mylist" "100006"
3、lpop:从列表左侧将数据弹出。
>lpop "mylist" --- "100004"
4、rpop:从列表右侧将数据弹出。
>rpop "mylist" --- "100006"
5、llen:获取列表中元素的个数。
>llen "mylist":--- (integer) 4
6、lrange key start stpo:返回索引从start到stop之间的所有元素(包含两端元素)。
>lrange "mylist" 0 -1 ---
1) "100003"
2) "100002"
3) "100001"
4) "100005"
8、lrem key count value:删除列表中前count个值为value的元素,返回删除的个数
8-1、count>0时 lrem 命令从列表左边开始删除前count个值为value的元素。
8-2、count<0时 lrem命令从列表右边开始删除前count个值为value的元素。
8-3、count=0时 lrem命令会删除所有值为value的元素。
>lpush "mylist" 2 2 2 --- (integer) 7
>rpush "mylist" 2 2 --- (integer) 10
>lrem "mylist" 1 2 --- (integer) 1
>lrem "mylist" -2 2 --- (integer) 2
>lrem "mylist" 0 2 --- (integer) 2
9、lindex key index:根据索引下标获取指定的列表元素。
>lindex "mylist" 1 --- "100002"
10、ltrim key start end:可以删除指定索引范围之外的所有元素,其指定列表范围的方法和lrange命令相同。
>ltrim "mylist" 0 -2 --- OK
11、linsert key before|after privot value:首先会在列表中从左到右查找值为pivot的元素,然后根据第二个参数是before还是after来决定将value插入到该元素的前面还是后面,返回插入后列表元素的个数
>lrange "mylist" 0 -1 ---
1) "100003"
2) "100002"
3) "100001"
4) "100005"
>linsert "mylist" before "100003" "3"
>linsert "mylist" after "100003" "4"
1) "3"
2) "100003"
3) "4"
4) "100002"
12、rpoplpush source destination:将元素从一个列表转到另一个列表。
>rpoplpush "mylist" "mylistnew" --- "100002"
>lrange "mylistnew" 0 -1
1) "100002"
Set 集合
1、sadd:用来向集合中添加一个或多个元素,如果键不存在则会自动创建。因为在一个集合中不能有相同的元素,所以如果要加入的元素已经存在于集合中聚会忽略这个元素。
>sadd letters a ---
>sadd letters a b c ---
2、smembers key:命令会返回集合中的所有元素
>smembers letters
3、sismember key member:判断一个元素是否在集合中是一个时间复杂度为O(I)的操作,无论集合中有多少个元素,sismember命令始终可以极快的返回结果。当值存在是sismembers 命令返回1 ,当值不存在或键不存在是返回0
>sismember letters a
>sismember letters d
4、集合间运算
sdiff key:对多个集合执行差集运算。
>sadd setA 1 2 3
>sadd setB 2 3 4
>sdiff setA setB
>sdiff SetB setA
5、sinter key:对多个集合执行交集运算。
>sinter setA setB
6、sunion key:对多个集合执行并集运算。
>sunion setA setB
7、scard key:获取集合中元素个数。
>smembers letters
>scard letters
8、spop letters:从集合中弹出一个元素。
>spop letters
>smembers letters
Zset(Sorted set:有序集合)
1、zadd:用来向有序集合中加入一个元素和该元素的分数,如果该元素已经存在则会用心的分数替换原来的分数。zadd命令的返回值是新加入到集合中的元素的个数。
>zadd scoreboard 89 Tom 67 Peter 100 David --- (integer) 3
注:分数不仅是整数,还支持双精度浮点数.
2、zscore key member:获取元素的分数
>zscore scoreboard Tom --- "89"
3、zrange key start top:按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素
>zrange scoreboard 0 -1
1) "Peter"
2) "Tom"
3) "David"
4、zrevrange key start top:按照元素分数从大到小的顺序放回索引从start到stop之间的所有元素
>zrevrange scoreboard 0 -1
1) "David"
2) "Tom"
3) "Peter"
5、zrangebyscore key min max:按照元素分数从小到大的顺序返回分数在min和max之间的元素。
>zrangebyscore scoreboard 85 100
1) "Tom"
2) "David"
6、zincrby key increment member:增加一个元素的分数,返回值是更改后的分数。
>zincrby scoreboard 4 Tom --- "93"
Redis 全部数据类型相关操作指令地址
http://redis.cn/commands.html
http://doc.redisfans.com/
Redis 主从
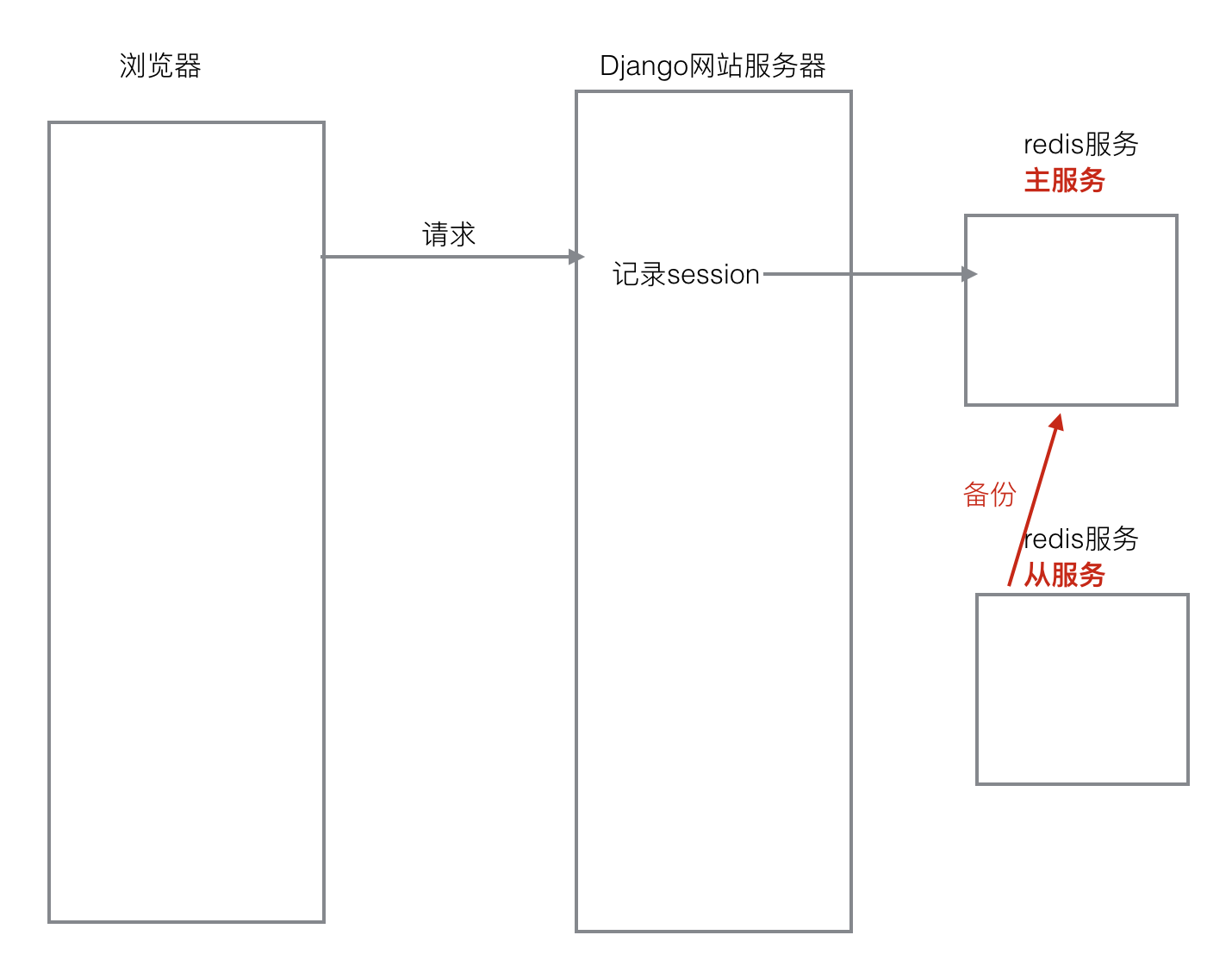
主从概念
1、一个master 可以拥有多个slave,一个slave又可以拥有多个slave,如此下去,形成了强大的多级服务器集群搭建
2、master用来写数据,slave用来读数据,经统计:网站的读写比率是 9:1
3、通过主从配置可以实现读写分离
4、master和slave都是一个redis实例(redis服务)
配置主服务器
1、查看当前主机的ip地址
ifconfig
2、修改 etc/redis/redis.conf文件
sudo vi redis.conf
bind 192.168.233.129 # 当前主机ip地址
port 6379
3、重启redis服务
sudo service redis stop
redis-server redis.conf
配置从服务器
1、复制etc/redis/redis.conf 文件
sudo cp redis.conf ./slave.conf
2、修改 redis/slave.conf 文件
sudo vi slave.conf
3、编辑内容
bind 192.168.233.129
slaveof 192.168.233.129 6379
port 6378
4、运行 redis 服务
sudo redis-server slave.conf
5、查看主从关系
redis-cli -h 129.168.233.129 info Replication
数据操作,验证是否成功
1、在master和slave分别执行info命令,查看输出信息 进入主客户端
redis-cli -h 192.168.233.129 -p 6379
2、进入从的客户端
redis-cli -h 192.168.233.129 -p 6378
3、在master上写数据
set aa aa
4、在slave上读数据
get aa
Redis 集群
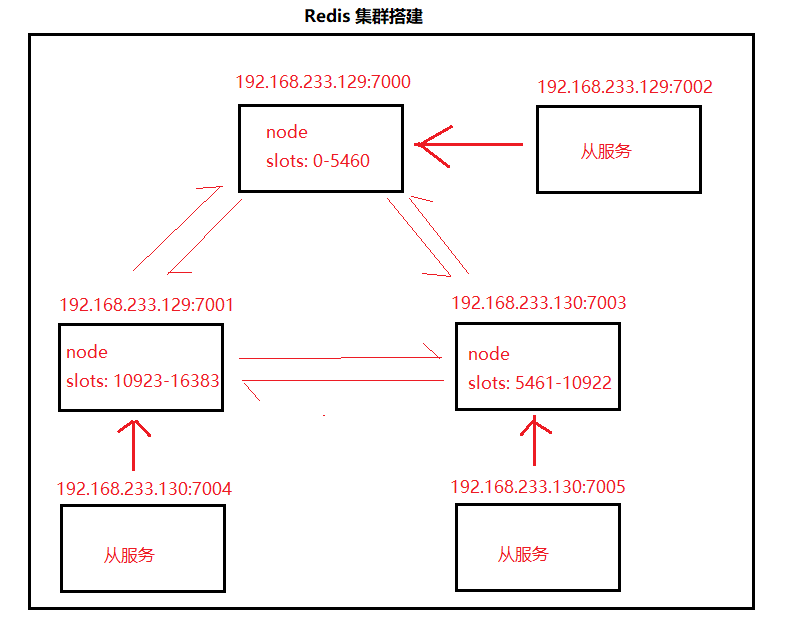
定义
集群是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。
当请求到来首先由负载均衡服务器处理,把请求转发到另外的一台服务器上。
Redis Cluster 工作条件与原理
1、Redis Cluster至少需要三个主节点才能工作
2、Redis Cluster采用了数据分片机制,使用16384个(0-16383)Slot虚拟槽来平均存储数据。也可以根据每个节点的内存情况手动分配,手动分配时需要把16384个分配完,否则集群无法正常工作
3、Redis Cluster每一个节点都可以作为客户端的连接入口并写入数据。Redis cluster的分片机制让每个节点都存放了一部分数据,比如1W个key分布在5个节点,每个节点可能只存储了2000个key,但是每一个节点都有一个类似index索引记录了所有key的分布情况
4、每一个节点还应该有一个Slave节点作为备份节点(比如用3台机器部署成Redis cluster,还应该为这三台Redis做主从部署,所以一共要6台机器),当master节点故障时slave节点会选举提升为master节点
5、Redis Cluster集群默认监听在16379端口。集群中所有Master都参与选举,当半数以上的master节点与故障节点通信超时将触发故障转移。任意master挂掉且该master没有slave节点,集群将进入fail状态,这也是为什么还要为他们准备Slave节点的原因。如果master有slave节点,但是有半数以上master挂掉,集群也将进入fail状态。当集群fail时,所有对集群的操作都不可用,会出现clusterdown the cluster is down的错误
配置虚拟机1(ip:192.168.233.129)
在 192.168.233.129 上进入Desktop目录,创建conf 目录
在conf 目录下创建文件7000.conf ,编辑内容如下
port 7000 # 端口
bind 192.168.233.129 # 当前虚拟机ip地址
daemonize yes # 是否以守护进程运行
pidfile 7000.pid
cluster-enabled yes # 开启集群
cluster-config-file 7000_node.conf
cluster-node-timeout 15000 # 节点互连超时时间,毫秒为单位
appendonly yes
在conf目录下创建文件7001.conf,编辑内容如下
port 7001
bind 192.168.233.129
daemonize yes
pidfile 7001.pid
cluster-enabled yes
cluster-config-file 7001_node.conf
cluster-node-timeout 15000
appendonly yes
在conf目录下创建文件7002.conf,编辑内容如下
port 7002
bind 192.168.233.129
daemonize yes
pidfile 7002.pid
cluster-enabled yes
cluster-config-file 7002_node.conf
cluster-node-timeout 15000
appendonly yes
注:以上三个文件的配置区别在port、pidfile、cluster-config-file三项
使用配置文件启动redis服务
redis-server 7000.conf
redis-server 7001.conf
redis-server 7002.conf
配置虚拟机2(ip:192.168.233.130)
在演示中,192.168.233.130 为当前ubuntu 机器的ip
在 192.168.233.130 上进入Destop目录,创建conf目录
在conf目录下创建文件7003.conf,编辑内容如下
port 7003
bind 192.168.233.130
daemonize yes
pidfile 7003.pid
cluster-enabled yes
cluster-config-file 7003_node.conf
cluster-node-timeout 15000
appendonly yes
在conf目录下创建文件7004.conf,编辑内容如下
port 7004
bind 192.168.233.130
daemonize yes
pidfile 7004.pid
cluster-enabled yes
cluster-config-file 7004_node.conf
cluster-node-timeout 15000
appendonly yes
在conf目录下创建文件7005.conf,编进内容如下
port 7005
bind 172.16.179.131
daemonize yes
pidfile 7005.pid
cluster-enabled yes
cluster-config-file 7005_node.conf
cluster-node-timeout 15000
appendonly yes
注:以上三个配置文件的区别在 port、pidfile、cluster-config-file 三项
使用配置文件启动redis
redis-server 7003.conf
redis-server 7004.conf
redis-server 7005.conf
redis-trib.rb 和 redis-cli --cluster
redis-trib.rb 命令(Ruby 脚本),会对ruby环境有一些依赖,需要安装ruby环境。
PS:Redis 5开始可以使用redis-cli --cluster 命令来创建集群,命令语法和redis-trib.rb 一样,省去了配置ruby环境的步骤。
创建集群方法(redis-trib.rb create / redis-cli --cluster create)
redis-trib.rb create --replicas 1 192.168.233.129:7000 192.168.233.129:7000 192.168.233.129:7001 192.168.233.129:7002 192.168.233.129:7003 192.168.233.129:7004 192.168.233.129:7005
# create 创建集群
# replicas 代表每个主节点有几个从节点
# 后面跟上的IP和端口是所有master和slave的节点信息
添加集群节点方法(redis-trib.rb add-node)
redis-trib.rb add-node 192.168.233.129:7010 192.168.233.129:7000
# 第一个ip是新节点,第二个ip是已存在的节点
redis-trib.rb reshard 192.168.233.129:7000 # 重新分片
删除集群节点方法(redis-trib.rb del-node)
redis-trib.rb reshard 192.168.233.129:7001 # 将需要删除节点的slot 移走,需要填写接受slot 的节点ID,需要把分区均匀分给其他分区
redis-trib.rb del-node 192.168.233.129:7001 xxxxxxxxxxxxxxxxxxx # 删除节点和它的id
查看redis cluster 节点状态
redis-cli -p 7000 cluster nodes # 可以看到自己和其他节点的状态
redis-cli -p 7000 cluster info # 可以看到集群的详细状态,包括集群状态、分配槽信息





