【论文精读】You Only Look Once: Unified, Real-Time Object Detection(YOLOv1)
参考:https://www.bilibili.com/video/BV15w411Z7LG
1.预测阶段(前向推断)
输入:448×448×3
输出:7×7×30
每张图片被分为S×S(即7×7=49)的 grid cell ,每个grid cell预测B(即2)个 bounding box ,即每张图片最多预测49个物体,对小目标、密集目标效果很差。
(2个bounding box是以grid cell为中心的同心框)
由 “与ground truth的IoU较大的”bounding box负责 “拟合ground truth”
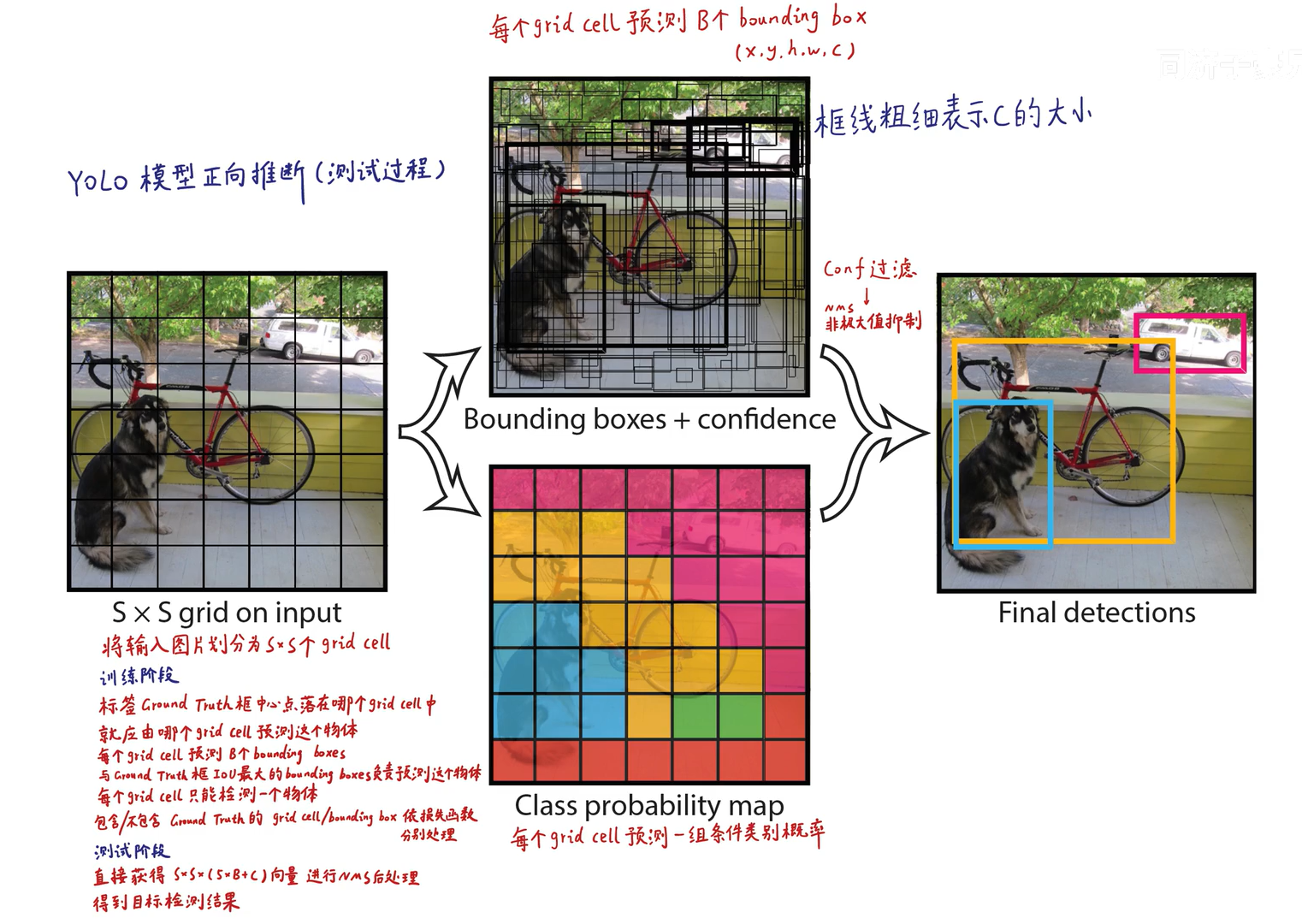
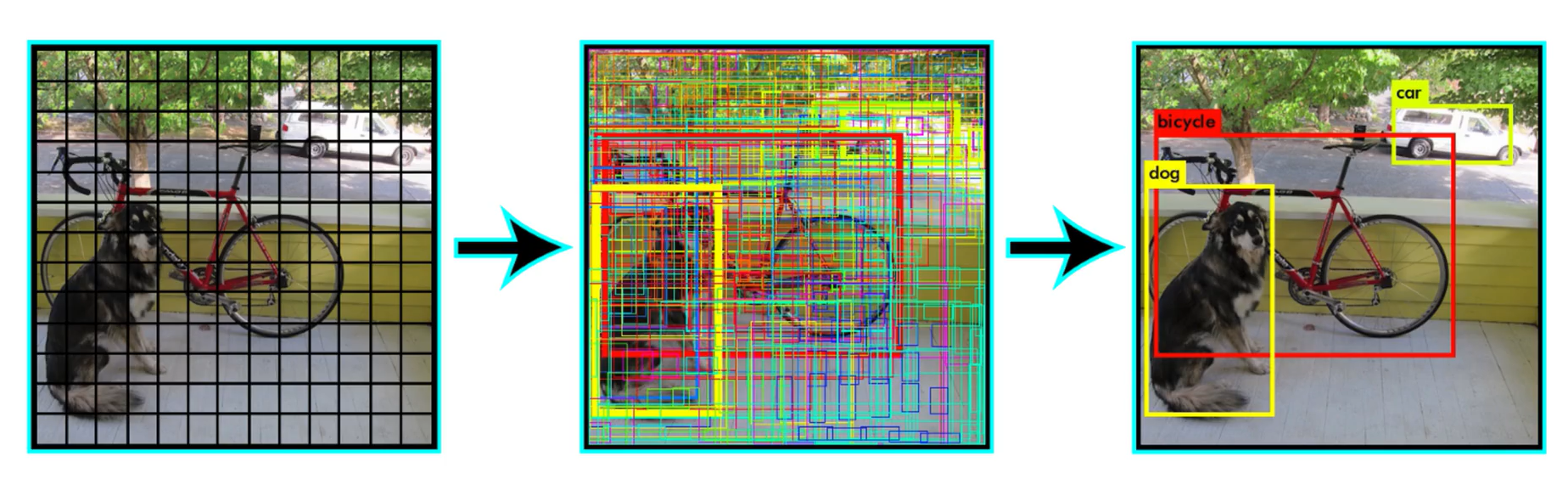
后处理(非极大值抑制,NMS)
过滤低置信度的框,去除重复识别的框
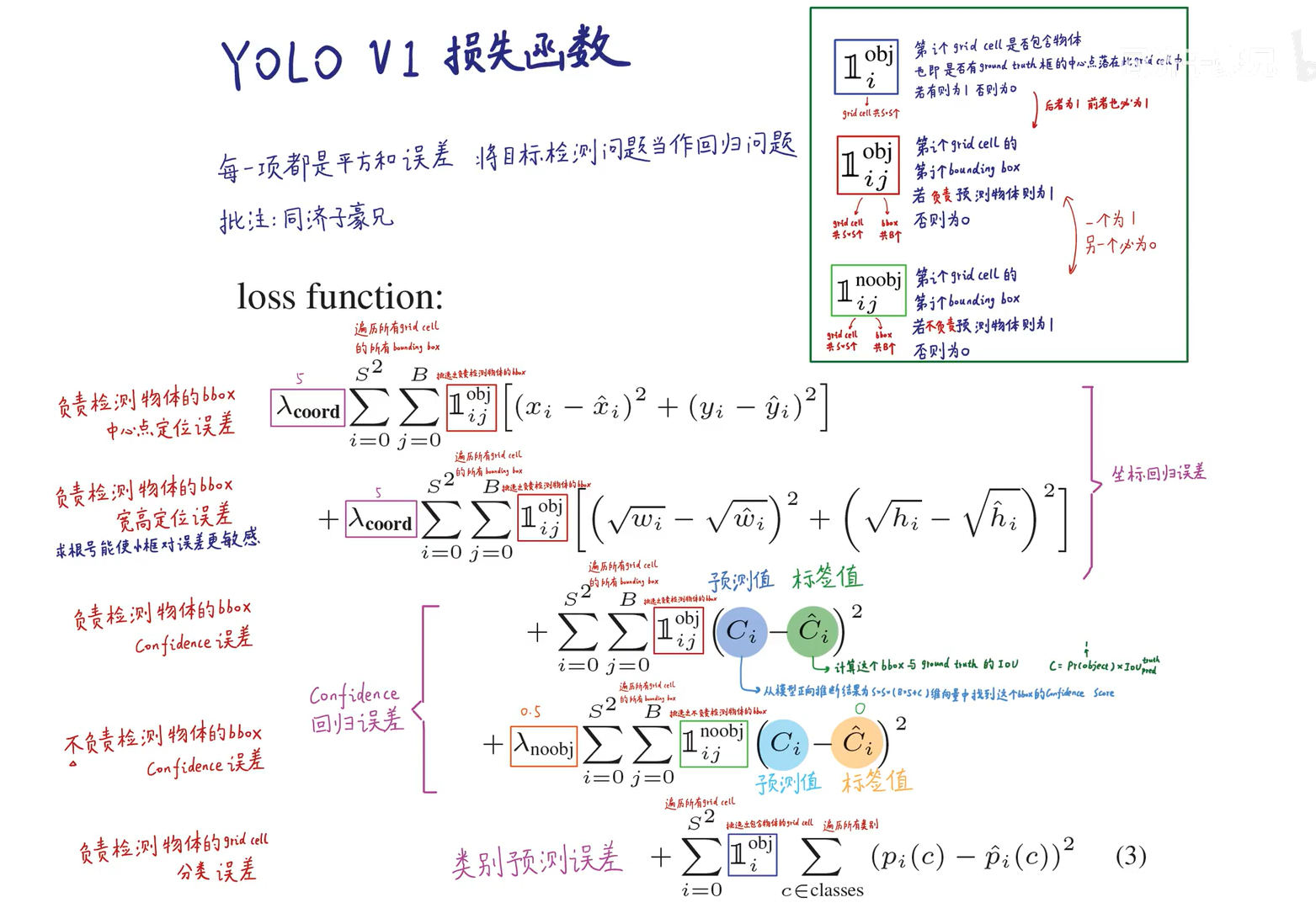
2.训练阶段(反向传播)
监督学习是通过梯度下降和反向传播方法迭代地去微调神经元中的权重,来使得损失函数最小化的过程。
1.由居于ground truth中间的grid cell负责拟合人工标注的框
2.由与ground truth的IoU较大的那个bounding box负责拟合标注框。
损失函数:
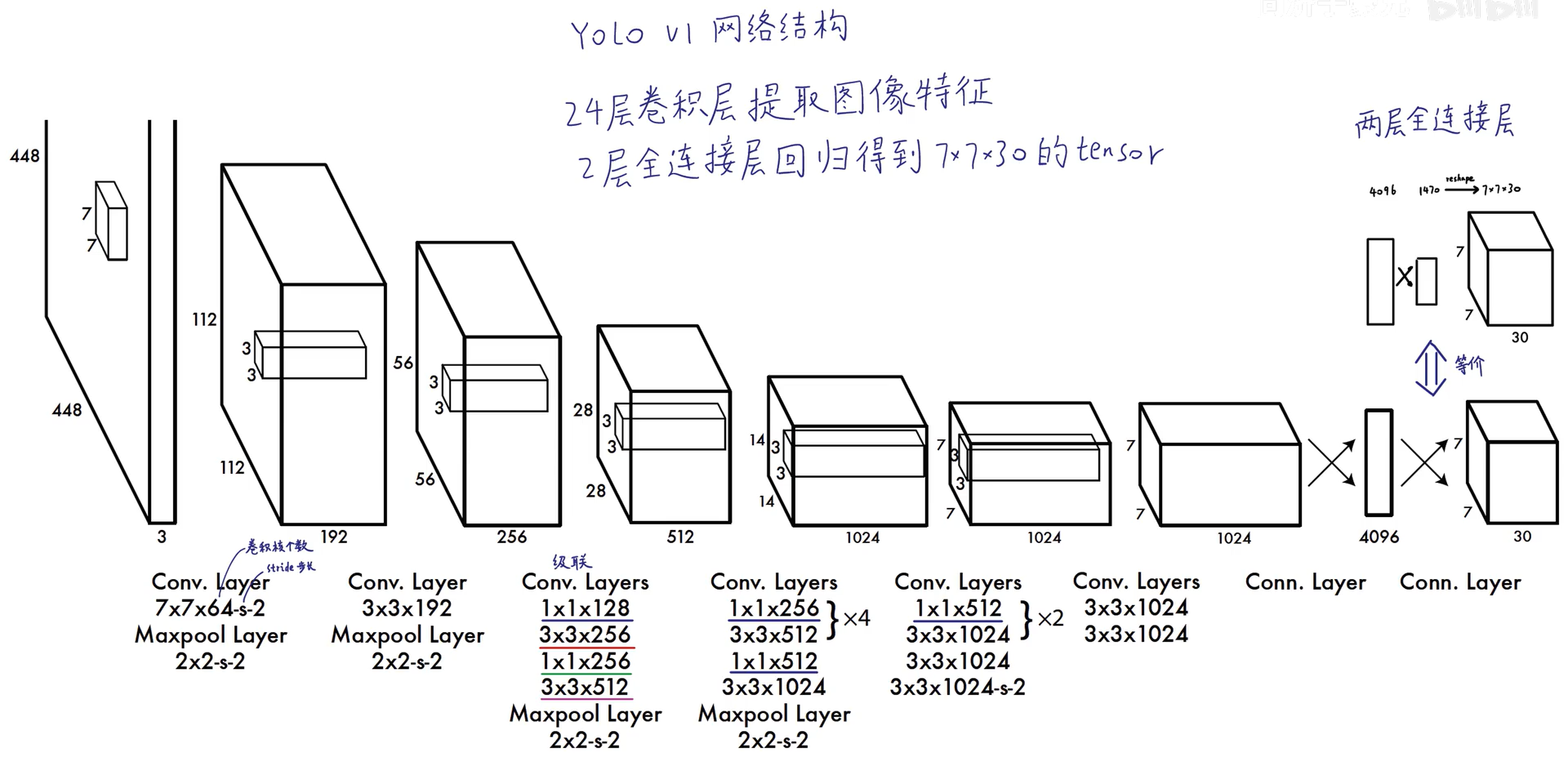
网络结构:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号