python爬虫爬取赶集网数据
前期的配置工作在之前的一篇博文中有提到过,现在直接进行爬取
一.创建项目
scrapy startproject putu
二.创建spider文件
1 scrapy genspider patubole patubole.com
三.利用chrome浏览器分析出房价和标题的两个字段的xpath表达式,开始编写patubole.py文件。网络的爬取是通过这个文件进行的
以下代码是最终的代码
所建的patubole.py文件必须实现name,parse函数,start_url这三个属性
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.http import Request 4 from urllib import parse 5 from patu.items import PatuItem 6 7 8 class PatuboleSpider(scrapy.Spider): 9 name = 'patubole' 10 # allowed_domains = ['python.jobbole.com'] 11 start_urls = ['http://xa.ganji.com/fang1/'] 12 13 def parse(self, response): 14 zufang_title=response.xpath('//*[@class="f-list-item ershoufang-list"]/dl/dd[1]/a/text()').extract() 15 zufang_money=response.xpath('//*[@class="f-list-item-wrap f-clear"]/dd[5]/div[1]/span[1]/text()').extract()17 for i,j in zip(zufang_title,zufang_money): 18 print(i,":",j)20
四.将爬取的数据保存到数据库sufang中。
(1)在pycharm中新建数据库
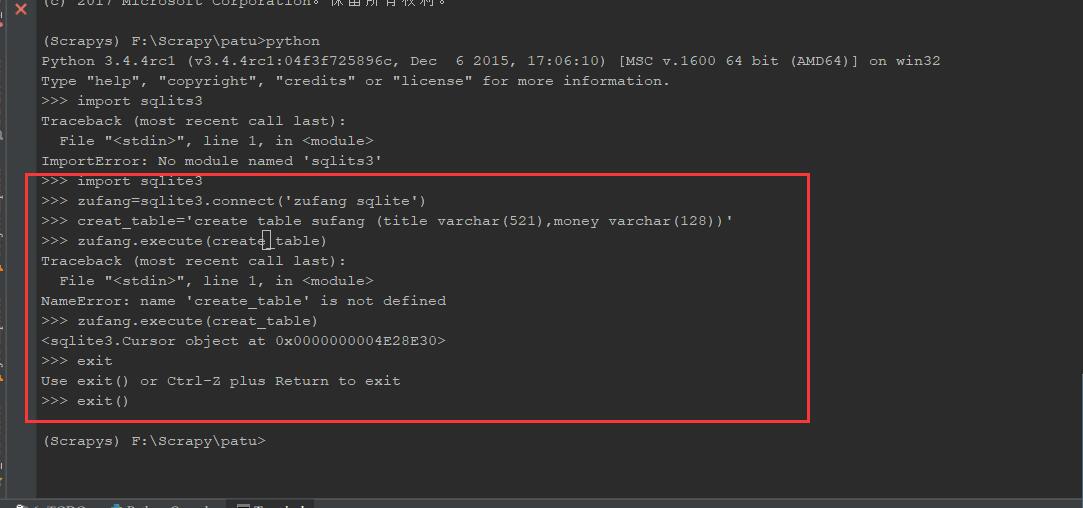
import sqlite3
zufang=sqlite3.connect('zufang sqlite')
create_table='create table zufang (title varchar(521),money varchar(128))'
zufang.execute(create_table)
exit()
完成后会出现
(2)将数据存放在新建的数据库zufang的数据表sufang中
数据的爬取是有patubole.py实现的,数据的存储是由pipelines.py实现的,pipelines.py又是有items.py提供数据的支持
所以编写items.py
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # https://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class PatuItem(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 zufang_title=scrapy.Field() 15 zufang_money=scrapy.Field() 16 pass
此时就要回过头来修改刚开是为了测试编写的patubole.py 文件
代码如下
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.http import Request 4 from urllib import parse 5 from patu.items import PatuItem 6 7 8 class PatuboleSpider(scrapy.Spider): 9 name = 'patubole' 10 # allowed_domains = ['python.jobbole.com'] 11 start_urls = ['http://xa.ganji.com/fang1/'] 12 13 def parse(self, response): 14 zufang_title=response.xpath('//*[@class="f-list-item ershoufang-list"]/dl/dd[1]/a/text()').extract() 15 zufang_money=response.xpath('//*[@class="f-list-item-wrap f-clear"]/dd[5]/div[1]/span[1]/text()').extract() 16 pipinstall=PatuItem() #创建PatuItem实例,实现数据的传递 17 for i,j in zip(zufang_title,zufang_money): 18 pipinstall['zufang_title']=i 19 pipinstall['zufang_money']=j 20 21 yield pipinstall #这一步很重要
22 23 24 # pass
(3)在settings.py中进行PatuPipeline文件配置
1 ITEM_PIPELINES = { 2 'patu.pipelines.PatuPipeline': 300, 3 }
(5)pipelines.py文件代码,实现存储数据到数据库中
其中包含SQL的相关知识
1 # Define your item pipelines here 2 # 3 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 4 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 5 6 import sqlite3 7 class PatuPipeline(object): 8 def open_spider(self,spider): 9 self.con=sqlite3.connect('zufang sqlite') 10 self.cn=self.con.cursor() 11 12 13 def process_item(self, item, spider): 14 # print(item.zufang_title,item.zufang_money) 15 insert_sql='insert into sufang (title,money) values("{}","{}")'.format(item['zufang_title'],item['zufang_money']) 16 print(insert_sql) 17 self.cn.execute(insert_sql) 18 self.con.commit() 19 return item 20 21 def spider_close(self,spider): 22 self.con.close()
最终结果

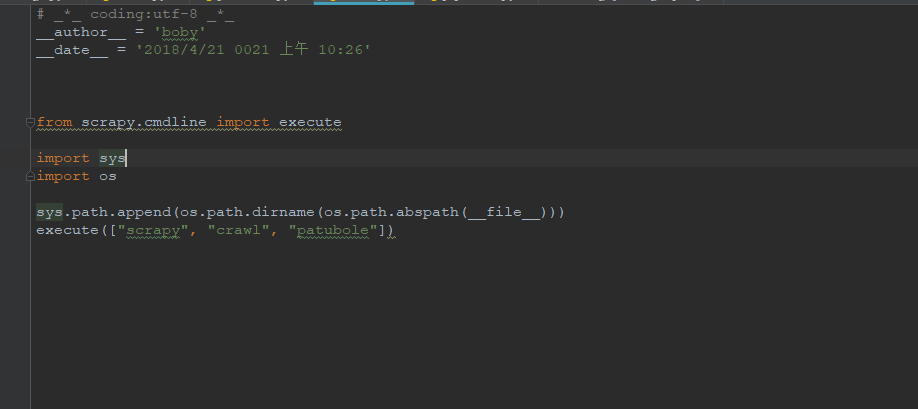
其中main.py文件是为了调式方便而添加的,可以不用,直接用相关命令启动爬虫