Java8系列 (三) Spliterator可分迭代器
本文转载自 jdk8 Stream 解析2 - Spliterator分割迭代器。
概述
我们最为常见的流的产生方式是 collection.stream(), 你点开Stream()方法, 他是通过 Collection 这个上层接口两个java8 新增特性 default method 进行实现。
@Override default Spliterator<E> spliterator() { return Spliterators.spliterator(this, 0); } default Stream<E> stream() { return StreamSupport.stream(spliterator(), false); }
这就牵扯到一个关键要点 Spliterator :分割迭代器。
本文主要描述 Spliterator 的作用,大部分来源于你不愿意读的 JavaDoc。
Spliterator 是 jdk8 非常重要的概念。里面的细节很值得学习玩味。
Spliterator 冗长的JavaDoc 说了什么?
基本介绍
Spliterator 是一个对源(数组,集合,io流等等)中元素进行遍历和分区的类。
可以通过 tryAdvance() 方法逐个遍历,也可以按照 forEachRemaining() 方法进行按 bulk 逐块的遍历。(内部调用的还是tryAdvance)
Spliterator 有类似 Collector 中的 characteristics , 但都是由十六进制来表示的。
- SIZED :表示大小固定, Collection常用
- DISTINCT : 去重, Set常用
- SORTED : 有顺序的 SortedSet 会用
- 等等
原生类型的特化版本
原始类型特化的分割迭代器也被提供,和Stream类似。减少装箱和拆箱的操作

比迭代器Iterator 更加高效的遍历元素的方式
提供更加高效的方法,进行数据的迭代。Iterator 的使用需要调用两个组合方法 hasNext() 以及 next() ,同时在多线程访问的情况下还会出现竞争,你需要去同步。
而分割迭代器 Spliterator 使用函数式编程的方式,只用一个方法就可以做到这个两个函数动作。就避免了竞争 ,就是 tryAdvance() 方法。后面会介绍
Spliterator的接口方法
tryAdvance()
同时做了 hasNext() 以及 next() 的工作。
/** * 类似于普通的 Iterator ,它会按顺序一个一个使用 Spliterator 中的元素执行action,并且如果还有其他元素要遍历就返回 true,否则返回 false。 */ boolean tryAdvance(Consumer<? super T> action);
forEachRemaining()
是一个默认方法,对余下的元素进行操作,直到元素全部被遍历完
一般情况下会直接调用上面的tryAdvance() 方法,但是也可以根据需要进行重写。
/** * 对余下的元素进行操作,直到元素全部被遍历完 * 如果源是有序的,遍历也是有序的 */ default void forEachRemaining(Consumer<? super T> action) { do { } while (tryAdvance(action)); }
这里有一点很值得注意,方法体中的 do {} 是空的,这个是因为 tryAdvance() 方法本身就完成了两个操作 hasNext() 以及 next(),所以方法体中不需要有任何操作了。这个是 函数式编程带来的好处。以及与命令式编程的区别。
trySplit()
尝试切分源来的 Spliterator, 返回的是(注意!!!)返回的是 分割出来的那一部分 数据,原有的数据集将不再包含这部分数据集合。两者 没有交集。剩下的可以继续分割,也许不可以继续分割了。
举个例子,我原来有 100个元素,我通过
trySplit切分出30个,作为一个新的 Spliterator分割迭代器返回,原有的,就还剩下70个。
- 如果是原有数据集合是
ORDERD的,分出来的也是有序的。 - 除非元素数量是无穷的,否则,最后一定会出现不能再分割的情况,这种情况下,返回的结果是
null。
Spliterator<T> trySplit();
estimateSize()
估算还剩下多少个元素需要遍历,不一定精确。
但是如果这个 Spliterator 是 SIZED,没有被遍历或者 split, 或是 SUBSIZED的,没有被遍历,那么他这个值一定是准确的。
long estimateSize();
还有个与之相关的默认方法,就是利用这个特性。
default long getExactSizeIfKnown() { return (characteristics() & SIZED) == 0 ? -1L : estimateSize(); }
characteristics()
- 分割之前,返回的结果都是一致的
- 而分割之后,不保证一致
有一个默认方法用于判断 Spliterator 是否包含这个特性
default boolean hasCharacteristics(int characteristics) { return (characteristics() & characteristics) == characteristics; }
getComparator
如果源是SORTED 类型的,且有比较器 Comparator 的话,则返回这个 Comparator,如果是SORTED 类型的,但是没有比较器,则返回 null , 除此之外,都抛出异常。
接口的默认方法里,就是抛出了异常。
default Comparator<? super T> getComparator() { throw new IllegalStateException(); }
Spliterator的8个Characteristics 特性
ORDERED
源的元素有序,tryAdvance ,forEachRemaining和 trySplit 都会保证有序的进行元素的处理。
- 需要注意
hashSet这类Collection是不保证有序的 - 有
ORDERED特性的数据,在并发计算的时候客户端也要做顺序限制的保证
DISTINCT
太简单,唯一性。 类似 Set 这样的传入集合会拥有这样的特性
SORTED
有这种特性的 Spliterator ,有一个特定的顺序。或者是所有元素都是可比较的,或者是有特定的比较器。
有
SORTED一定会有ORDERED
SIZED
有这种属性的 Spliterator 在遍历和分割之前,estimateSize() 返回的大小是固定的,并且是准确的。
NONNULL
不为 NULL, 大部分并发的集合,队列,Map 都可能会有这样的特性。
IMMUTABLE
不可变的。元素遍历期间不可以被 添加,替换,删除(cannot be added, replaced, or removed),否则,应该抛出异常。
CONCURRENT
支持并发操作的。
- 顶层的
Spliterator不可以CONCURRENT与SIZED。 这两者是相互冲突的。 - 但是分割之后的
Spliterator, 可能是SIZED, 顶层不能决定底层
SUBSIZED
该 Spliterator 和所有从它拆分出来的分割迭代器都是 SIZED 以及 SUBSIZED 的。
如果分割后,没有按照要求返回SIZED 以及 SUBSIZED 属性,那么操作是不被保证的,也就是结果不可预测。
这个属性和
SIZED的区别就是,SIZED不保证SUBSIZED。而SUBSIZED会要求保证SIZED
内部特化而做的函数式接口 (OfPrimitive)
除了上面的函数,以及特性,Spliterator 迭代器中,还有几个定义在内部的接口。
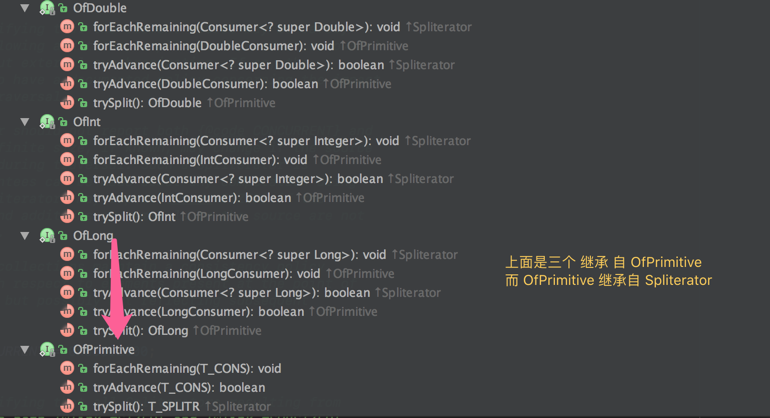
OfPrimitive 重载了(overloads)了 Spliterator 的方法。用于实现特化的分割迭代器。

overloads:参数列表不同,函数名相同,与返回值类型无关,与访问修饰符无关。
注意与
override的区别
免责声明:
本文转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除。
原文作者:待葡萄嗖透
原文出处:http://movingon.cn/2017/05/02/jdk8-Stream-%E8%A7%A3%E6%9E%902-Spliterator%E5%88%86%E5%89%B2%E8%BF%AD%E4%BB%A3%E5%99%A8/
