
浅谈java中Object类的方法
Java中Object类的方法
Object类中的方法总共有10个,其中有一个方法是私有的native修饰的,除了这个方法不讨论外,本文主要讨论的方法有9个(getClass、hashCode、equals、toString、wait、notify、notifyAll、finalize、clone)。
registerNatives() : void
private static native void registerNatives();
static {
registerNatives();
}
registerNatives()方法使用了native特征修饰符修饰,我们看不到该方法的具体实现,并且也没有注释,所以本文暂时不研究这个方法。
getClass() : Class
源码注释:
* Returns the runtime class of this {@code Object}. The returned
* {@code Class} object is the object that is locked by {@code
* static synchronized} methods of the represented class.
源码:
public final native Class<?> getClass();
getClass()方法返回当前运行时的类Class,即当前调用getClass()方法的对象对应的Class(字节码)。这个方法一般在发射场景中使用。
hashCode() : int
源码注释:
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
源码:
public native int hashCode();
hashCode()方法返回值是当前调用hashCode()方法的对象其内存地址所对应的的哈希值(hash value),并且这个方法在那些底层通过哈希表(hash table)实现的集合有很重要的意义,这个方法一般搭配equals()方法使用。
Ps:Hash表的底层实现就是数组+链表的数据结构,每一个元素在散列函数的作用下都对应一个散列值,根据这个值来决定元素在数组中的索引下标位置,而链表用于将那些散列值相同的元素串成一条链,即链表。
假设需要存储的元素:23、38、12、17、29、60。散列函数为:value % 11。
那么hash表的结构大致如下:
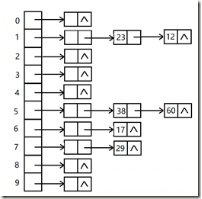
哈希函数能使一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快的定位,所以一般对访问速度有要求的场景下,使用hash表作为存储结构是优先选择。
toString() : String
源码注释:
* Returns a string representation of the object. In general, the
* {@code toString} method returns a string that
* "textually represents" this object. The result should
* be a concise but informative representation that is easy for a
* person to read.
* It is recommended that all subclasses override this method.
源码:
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
toString()方法用于返回对象的字符串表示形式,Object类中的toString()方法返回的字符串形式为类全名@内存地址,建议所有的子类都重写toString()方法,因为toString()方法的初衷就是返回一个字符串,并且我们能够很容易的通过这个字符串来区别同一个类下的对象,好比Person类下有三个属性,分别是name、age、gender,当Person没用重写toString()方法时,默认调用的是Object类中toString()方法,那么无论打印多少个Person类对象,它们的toString()方法返回值都是包名.Person@内存地址,完全达不到区分同类对象的需求,所以一般在类中重写toString()方法,如下:
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", gender=" + gender + "]";
}
equals() : boolean
源码注释:
* Indicates whether some other object is "equal to" this one.
源码:
public boolean equals(Object obj) {
return (this == obj);
}
equals()方法用于判断两个对象是否相等,Object类中的equals方法默认判断两个对象的地址引用是否相等。在实际开发中,一般需要根据业务逻辑重写equals方法,根据对象的属性值来判断两个对象在业务逻辑上是否相等,如Person类中有name属性,如果不重写equals方法,那么默认调用的是Object类中equals方法,那么所有Person对象都是不相等的,因为new出来的对象默认在堆内存中开辟一块新的内存空间,那么地址引用当然不相等。
Person类中的equals方法重写如下:
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
重写完equals方法之后,判断两个Person对象是否是同一个对象的判断准则不在是对象的地址引用,而是Person对象name属性值。这才是我们真正需要的结果。
== 和 equals的区别
==和equals都可用于对象是否相等。但是当equals方法被重写之后,它们之间就略有不同。
==可以用于比较基本类型和引用类型,基本类型比较的是值是否相等,引用类型比较的是地址引用是否相等。
Object类中的equals方法只可以用于比较引用类型,默认比较的是地址引用是否相等。重写后的equals方法不在是比较地址引用,而是比较对象的属性值是否相等,String类就重写了equals方法,所以通过String类的实例方法equals,比较的是两个字符串的每一个字符是否相等。
注意:equals方法一般需要结合hashCode方法重写。
notify() : void
源码注释:
Wakes up a single thread that is waiting on this object's
monitor. If any threads are waiting on this object, one of them
is chosen to be awakened. The choice is arbitrary and occurs at
the discretion of the implementation. A thread waits on an object's
monitor by calling one of the {@code wait} methods.
源码:
public final native void notify();
notify()方法使用了native特征修饰符修饰,表示该方法使用了其他语言来实现,所以我们看不到notify()方法的具体实现,但是通过notify()方法的注释,我们可以得知notify方法用于唤醒因线程同步进入阻塞状态的任意一个线程。
notifyAll() : void
源码注释:
Wakes up all threads that are waiting on this object's monitor. A
thread waits on an object's monitor by calling one of the
{@code wait} methods.
源码:
public final native void notifyAll();
notifyAll()方法和notify()方法基本差不多,不同的是notifyAll()方法不仅仅只唤醒一个因线程同步进入阻塞状态的线程,而是唤醒所有。
注意:notify()方法和notifyAll()方法需要在同步代码块或者同步方法中使用,因为这两个方法就是用来唤醒因线程同步锁进入阻塞状态的线程,如果不在线程同步环境下,那么notify()方法和notifyAll()方法需要唤醒的阻塞线程是哪一个呢?说白了就是不明确需要唤醒因哪一个线程同步锁进入阻塞状态的线程。而且如果不在同步代码块或者同步方法内使用这两个方法,编译会报错。
wait(long) : void
源码注释:
Causes the current thread to wait until either another thread invokes the
{@link java.lang.Object#notify()} method or the
{@link java.lang.Object#notifyAll()} method for this object, or a
specified amount of time has elapsed.
The current thread must own this object's monitor.
源码:
public final native void wait(long timeout) throws InterruptedException;
wait(long)方法是native修饰的,即具体实现过程由其他语言(如C、C++)来实现。虽然我们不能通过源码来了解wait(long)方法的作用,但是我们可以通过注释来了解wait(long)方法的功能或者作用,从注释上可以知道,wait()方法的执行可以让当前正在执行的线程进入阻塞状态,直到其他线程调用notify()或者notifyAll()方法来唤醒这个线程,或者当过了timeout毫秒之后,自动从阻塞状态进入就绪状态。
注意:wait()方法是同步监视器调用的,而不是线程本身调用的,同时也要弄清楚线程和同步监视器之间的关系。
wait() : void
源码注释:
Causes the current thread to wait until another thread invokes the
{@link java.lang.Object#notify()} method or the
{@link java.lang.Object#notifyAll()} method for this object.
In other words, this method behaves exactly as if it simply
performs the call {@code wait(0)}.
源码:
public final void wait() throws InterruptedException {
wait(0);
}
wait()方法从源码上可以得知,其实wait()方法本质上就是wait(0),所以我们可以参考wait(long)方法来理解wait()方法的作用,因为wait()方法没有参数,即没有一个timeout值,所以当同步监视器调用了wait()方法后,进入阻塞的线程不存在过了timeout毫秒后自动进入就绪列队(状态)中,所以因为同步监视器调用wait()进入阻塞状态的线程只有当其他线程调用notify()或者notifyAll()方法来唤醒其,使其进入就绪状态。
wait(long, int) : void
源码注释:
Causes the current thread to wait until another thread invokes the
{@link java.lang.Object#notify()} method or the
{@link java.lang.Object#notifyAll()} method for this object, or
some other thread interrupts the current thread, or a certain
amount of real time has elapsed.
@param timeout the maximum time to wait in milliseconds.
@param nanos additional time, in nanoseconds range 0-999999.
源码:
public final void wait(long timeout, int nanos) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos >= 500000 || (nanos != 0 && timeout == 0)) {
timeout++;
}
wait(timeout);
}
wait(long, int)方法通过其实现可以知道,该方法本质还是wait(long)方法,只不过和wait(long)方法不同之处是,wait(long, int)方法的对等待毫秒值的控制更加精确,其第一个参数是等待的毫秒值timeout,第二个参数是一个纳秒值nanos,纳秒值的最大值为999999,即约等于1毫秒,所有我们可以得到一个线程等待时间区间:[timeout, timeout+1],这时我们回到源码分析,当等待时间timeout小于0,那么抛出一个非法参数异常,当追加的纳秒值nanos小于0或者大于999999时,也抛出一个非法参数异常,当timeout和nanos的实参值都合法时,如果纳秒值大于500000,那么最后等待的总时间就是timeout+1,这里可以理解为四舍五入,如果等待毫秒值timeout为0,并且追加的纳秒值不等于0,那么最后的等待毫秒值为timeout+1,即为1毫秒。
wait(long, int)方法其实是对线程的等待时间timeout进行了更加精细的控制。
finalize() : void
源码注释:
Called by the garbage collector on an object when garbage collection
determines that there are no more references to the object.
A subclass overrides the {@code finalize} method to dispose of
system resources or to perform other cleanup.
源码:
protected void finalize() throws Throwable { }
当垃圾回收机制(Garbage Collection)确认了一个对象没有被引用时,那么垃圾回收机制就会回收这个对象,并在回收的前一刻这个对象调用finalize()方法,这类似C++中的析构函数,我们可以重写对象的finalize()方法来研究垃圾回收机制回收对象的过程。
clone() : void
源码注释:
Creates and returns a copy of this object.
The precise meaning of "copy" may depend on the class of the object.
源码:
protected native Object clone() throws CloneNotSupportedException;
clone()方法用于克隆当前对象,克隆分为浅克隆和深克隆。Object类中的clone()方法是浅克隆对象。
浅克隆就是复制值一份,然后赋值给克隆出来的对象,所以当浅克隆基本数据类型时,那么可以实现真正意义上的克隆,但是当浅克隆引用数据类型时,那么就会出现复制地址引用一份,然后赋值给克隆对象,这种克隆仅仅只是克隆复制了一份地址引用,本质上这两个对象操作的还是同一块内存,所以达不到真正意义上的克隆对象,所以一般需要实现Cloneable接口,并重写clone方法,当复制的属性是引用数据类型时,进行递归克隆(基本数据类型直接复制一份,引用数据类型递归调用clone方法),重写完clone方法才实现真正意义上的克隆。
