
Zookeeper集群的搭建
Zookeeper介绍
下面这段内容摘自《从 Paxos 到 ZooKeeper 》第四章第一节的某段内容,推荐大家阅读一下:
Zookeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。
所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家 Raghu Ramakrishnan 开玩笑地说:“在这样下去,我们这儿就变成动物园了!”
此话一出,大家纷纷表示就叫动物园管理员吧,因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了。
而 Zookeeper 正好要用来进行分布式环境的协调,于是,Zookeeper 的名字也就由此诞生了。
Zookeeper是一个分布式的,开发源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护,域名服务,分布式同步.组服务,node管理等
Zookeeper实现了高性能,高可靠性,和有序的访问.高性能保证了zookeeper能应用在大型的分布式系统上.高可靠性保证它不会由于单一节点的故障而造成任何问题.你运行一个zookeeper也是可以的,但是在生产环境中,你部署3,5,7个节点(以为采用投票制)部署的越多,可靠性就越高,当然最好是部署奇数个,偶数个也不是不可以的.但是zookeeper集群是以宕机过半才会让这个集群宕机的(选举机制),所以奇数个集群更佳.
因为两个原因才是得zookeeper集群奇数个更佳:
1.就是采用的选举机制
2.我们知道在 ZooKeeper 中 Leader 选举算法采用了 Zab 协议。Zab 核心思想是当多数 Server 写成功,则任务数据写成功:
- 如果有 3 个 Server,则最多允许 1 个 Server 挂掉。
- 如果有 4 个 Server,则同样最多允许 1 个 Server 挂掉。
既然 3 个或者 4 个 Server,同样最多允许 1 个 Server 挂掉,那么它们的可靠性是一样的。
所以选择奇数个 ZooKeeper Server 即可,这里选择 3 个 Server。
搭建zookeeper集群
1.有一个单机的zookeeper
2.每一台zookeeper中有另外两台zookeeper的ip和端口号
zookeeper有三个端口号
访问端口2181
数据同步端口号:自定义
选举端口:自定义
在配置文件中配置另外两台port(数据同步端口):port(选举端口)
删除我以前使用过的zookeeper这个注册中心中的data文件,因为以前的一些数据可能保存在里面,搭建集群时,可能会有影响,然后再创建一个新的data文件

进入zoo.cfg文件中进行编辑
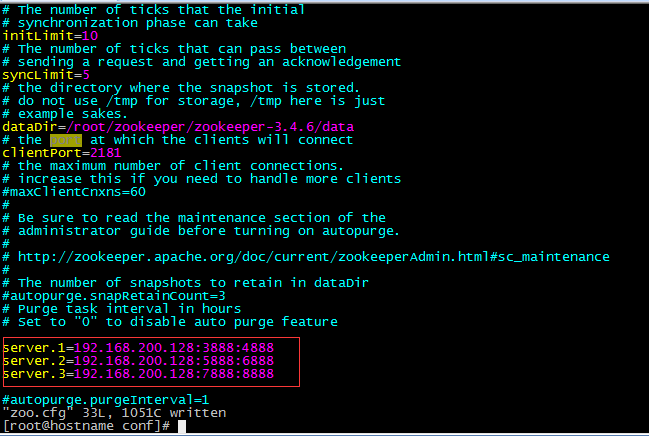
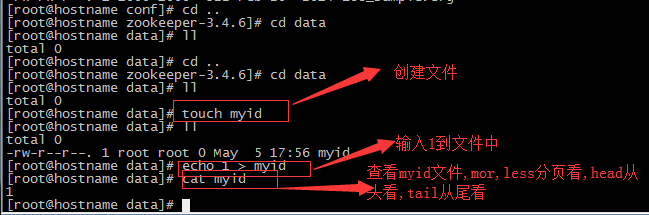
然后配置在data中创建一个文件夹,myid
因为我在同一个虚拟机上进行的搭建,所以将zookeeper改名字

然后直接进行复制三份也就得到了三份zookeeper,
然后更改一下配置文件conf下面的zoo.cfg文件中的datadir的位置和端口号

更改一下myid中的id



接着将剩下的两个启动起来就可以
本文来自博客园,作者:King-DA,转载请注明原文链接:https://www.cnblogs.com/qingmuchuanqi48/p/10815444.html

