[http] 报文
HTTP报文(messages)
HTTP报文是服务器和客户端之间交换数据的方式。
有两种类型的报文︰
请求--由客户端发送用来触发一个服务器上的动作;
响应--来自服务器的应答。
HTTP报文由采用ASCII编码的多行文本构成。在HTTP/1.1及早期版本中,这些报文通过连接公开地发送。在HTTP/2中,为了优化和性能方面的改进,曾经可人工阅读的报文被分到多个HTTP帧中。

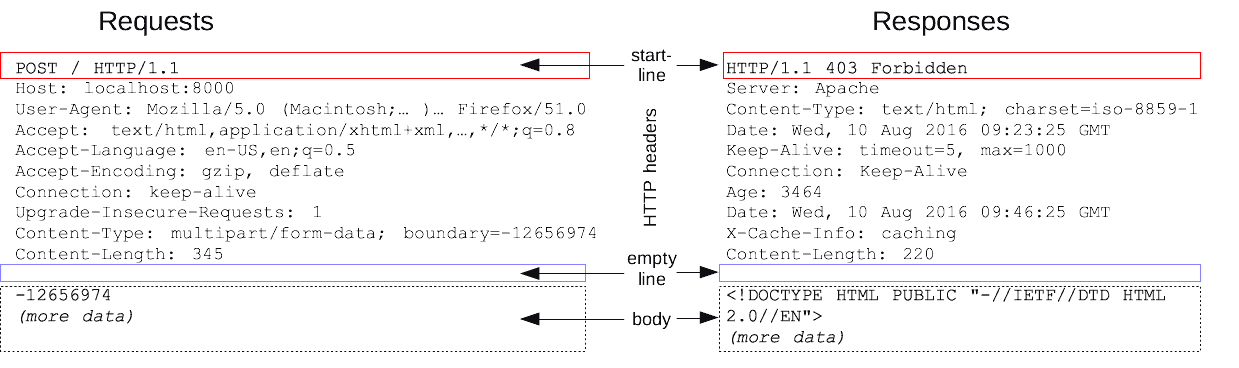
HTTP 请求和响应具有相似的结构,由以下部分组成︰
一行起始行用于描述要执行的请求,或者是对应的状态,成功或失败。这个起始行总是单行的。
一个可选的HTTP头集合指明请求或描述报文正文。
一个空行指示所有关于请求的元数据已经发送完毕。
一个可选的包含请求相关数据的正文 (比如HTML表单内容), 或者响应相关的文档。 正文的大小由起始行的HTTP头来指定。
起始行和 HTTP 报文中的HTTP 头统称为请求头,而其有效负载被称为报文正文。
HTTP Requests
起始行
HTTP请求是由客户端发出的报文,用来使服务器执行动作。起始行 (start-line) 包含三个元素:
1.一个 HTTP 方法,一个动词 (像 GET, PUT 或者 POST) 或者一个名词 (像 HEAD 或者 OPTIONS), 描述要执行的动作. 例如, GET 表示要获取资源,POST 表示向服务器推送数据 (创建或修改资源, 或者产生要返回的临时文件)。
2.请求目标 (request target),通常是一个 URL,或者是协议、端口和域名的绝对路径,通常以请求的环境为特征。请求的格式因不同的 HTTP 方法而异。它可以是:
一个绝对路径,末尾跟上一个 ' ? ' 和查询字符串。这是最常见的形式,称为 原始形式 (origin form),被 GET,POST,HEAD 和 OPTIONS 方法所使用。
POST / HTTP 1.1
GET /background.png HTTP/1.0
HEAD /test.html?query=qm HTTP/1.1
OPTIONS /anypage.html HTTP/1.0
一个完整的URL,被称为 绝对形式 (absolute form),主要在 GET 连接到代理时使用。
GET http://www.example.com
HTTP/1.1
由域名和可选端口(以':'为前缀)组成的 URL 的 authority component,称为 authority form。 仅在使用 CONNECT 建立 HTTP 隧道时才使用。
CONNECT www.example.com:80 HTTP/1.1
星号形式 (asterisk form),一个简单的星号('*'),配合 OPTIONS 方法使用,代表整个服务器。
OPTIONS * HTTP/1.1
3.HTTP 版本 (HTTP version),定义了剩余报文的结构,作为对期望的响应版本的指示符。
Headers
来自请求的 HTTP headers 遵循和 HTTP header 相同的基本结构:不区分大小写的字符串,紧跟着的冒号 ('😂 和一个结构取决于 header 的值。 整个 header(包括值)由一行组成,这一行可以相当长。
有许多请求头可用,它们可以分为几组:
General headers,例如 Via,适用于整个报文。
Request headers,例如 User-Agent,Accept-Type,通过进一步的定义(例如 Accept-Language),或者给定上下文(例如 Referer),或者进行有条件的限制 (例如 If-None) 来修改请求。
Entity headers,例如 Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。

Body
请求的最后一部分是它的 body。不是所有的请求都有一个 body:例如获取资源的请求,GET,HEAD,DELETE 和 OPTIONS,通常它们不需要 body。 有些请求将数据发送到服务器以便更新数据:常见的的情况是 POST 请求(包含 HTML 表单数据)。
Body 大致可分为两类:
Single-resource bodies,由一个单文件组成。该类型 body 由两个 header 定义: Content-Type 和 Content-Length.
Multiple-resource bodies,由多部分 body 组成,每一部分包含不同的信息位。通常是和 HTML Forms 连系在一起。
HTTP Responses
状态行
HTTP 响应的起始行被称作 状态行 (status line),包含以下信息:
协议版本,通常为 HTTP/1.1。
状态码 (status code),表明请求是成功或失败。常见的状态码是 200,404,或 302。
状态文本 (status text)。一个简短的,纯粹的信息,通过状态码的文本描述,帮助人们理解该 HTTP 报文。
一个典型的状态行看起来像这样:HTTP/1.1 404 Not Found。
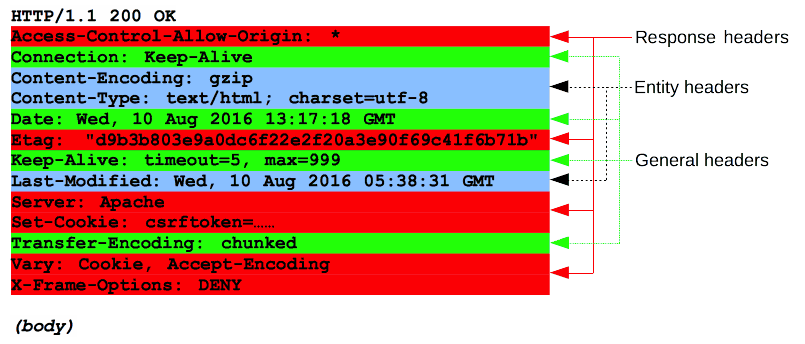
Headers
响应的 HTTP headers 遵循和任何其它 header 相同的结构:不区分大小写的字符串,紧跟着的冒号 ('😂 和一个结构取决于 header 类型的值。 整个 header(包括其值)表现为单行形式。
和request的headers相似。
有许多响应头可用,这些响应头可以分为几组:
General headers,例如 Via,适用于整个报文。
Response headers,例如 Vary 和 Accept-Ranges,提供其它不符合状态行的关于服务器的信息。
Entity headers,例如 Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。
Body
响应的最后一部分是 body。不是所有的响应都有 body:具有状态码 (如 201 或 204) 的响应,通常不会有 body。
Body 大致可分为三类:
Single-resource bodies,由已知长度的单个文件组成。该类型 body 由两个 header 定义:Content-Type 和 Content-Length。
Single-resource bodies,由未知长度的单个文件组成,通过将 Transfer-Encoding 设置为 chunked 来使用 chunks 编码。
Multiple-resource bodies,由多部分 body 组成,每部分包含不同的信息段。但这是比较少见的。
HTTP/2 帧(Frames)
HTTP/1.x 报文有一些性能上的缺点:
Header 不像 body,它不会被压缩。
两个报文之间的 header 通常非常相似,但它们仍然在连接中重复传输。
无法复用。当在同一个服务器打开几个连接时:TCP 热连接比冷连接更加有效。
HTTP/2 引入了一个额外的步骤:它将 HTTP/1.x 报文分成帧并嵌入到流 (stream) 中。数据帧和报头帧分离,这将允许报头压缩。将多个流组合,这是一个被称为 多路复用 (multiplexing) 的过程,它允许更有效的底层 TCP 连接。
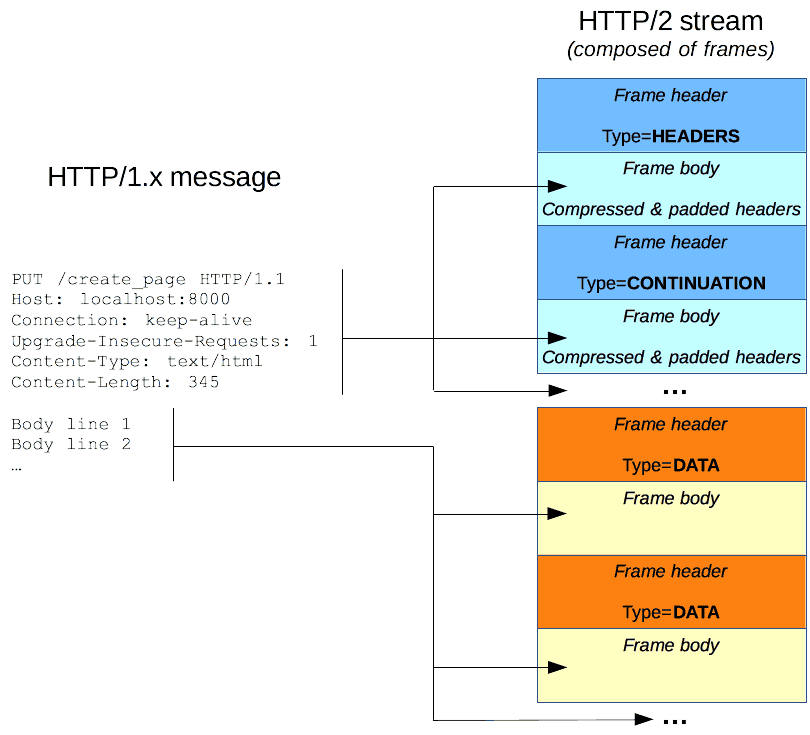
HTTP 帧现在对 Web 开发人员是透明的。在 HTTP/2 中,这是一个在 HTTP/1.1 和底层传输协议之间附加的步骤。Web 开发人员不需要在其使用的 API 中做任何更改来利用 HTTP 帧;当浏览器和服务器都可用时,HTTP/2 将被打开并使用。
HTTP 会话(session)
在像 HTTP 这样的客户端-服务器协议中, 会话 由以下三步组成:
1.客户端建立一条 TCP 连接 (如果传输层不是 TCP, 也可以是其他适合的连接).
2.客户端发送请求并等待应答.
3.服务器处理请求并送回应答, 包括一个状态码和对应的数据.
从 HTTP/1.1 开始, 在第三步后连接不再关闭, 客户端可以再次发起新的请求: 第二步和第三步可以进行数次.
建立连接
在客户端-服务器协议中,连接是由客户端发起建立的。HTTP 中打开连接的意思是建立一条下层传输层连接,通常就是 TCP。
使用 TCP 时, HTTP 服务器的默认端口号是 80, 另外还有 8000 和 8080 也很常用。页面的 URL 会包含域名和端口号, 当后者为 80 时可以省略掉。
发送客户端请求
一旦连接建立, 用户代理就可以发送请求 (用户代理通常是 web 浏览器, 但也可以是任何其他事物, 例如爬虫). 客户端请求由一系列文本指令组成, 并使用 CRLF(Carriage-Return Line-Feed,回车换行) 分隔, 它们被划分为三个块:
1.第一行包括请求方法及其参数:
文档路径, 即不包括协议和域名的绝对路径 URL
使用的 HTTP 协议版本
2.接下来的行每一行都表示一个 HTTP 首部, 为服务器提供关于所需数据的信息 (例如语言, 或 MIME 类型),或是一些改变请求行为的数据 (例如当数据已经被缓存时就不再应答). 这些 HTTP 首部组成一个块, 并以一个空行结束.
3.最后一块是可选的数据块, 包括了更多数据, 这主要被 POST 方法使用.
请求示例
POST /contact_form.php HTTP/1.1
Host: www.example.com
Content-Length: 64
Content-Type: application/x-www-form-urlencoded
name=Joe%20User&request=Send%20me%20one%20of%20your%20catalogue
注意最后的空行,它把首部与数据块分隔开。如果数据块是空的,服务器可以在收到代表首部结束的空行后就开始处理请求。
请求方法
HTTP 定义了一组 请求方法 用来指定对给定资源的行为. 尽管它们可以是名词, 但这些请求方法有时会 被叫做 HTTP 动词. 最常用的请求方法是 GET 和 POST:
GET 方法请求指定的资源. GET 请求应该只被用于获取数据.
POST 方法向服务器发送数据, 因此会改变服务器状态. 这个方法经常在 HTML 表单 中使用.
服务器响应结构
当用户代理发送请求之后, web 服务器会处理它, 并最终送回一个响应. 与客户端请求很类似地, 服务器响应由一系列文本指令组成, 并使用 CRLF 分隔, 但它们被划分为三个不同的块:
第一行是 状态行, 包括使用的 HTTP 协议版本, 状态码和一个状态描述 (可读的文本).
接下来的行每一行都表示一个 HTTP 首部, 为客户端提供关于所发送数据的一些信息 (如数据大小, 使用的压缩算法, 缓存指示). 与客户端请求的头部块类似, 这些 HTTP 首部组成一个块, 并以一个空行结束.
最后一块是数据块, 包括响应的数据 (如果有的话).
响应示例
成功的网页响应:
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (这里是 29769 字节的网页信息)
请求的资源已经永久移动的通知:
HTTP/1.1 301 Moved Permanently
Server: Apache/2.2.3 (Red Hat)
Content-Type: text/html; charset=iso-8859-1
Date: Sat, 09 Oct 2010 14:30:24 GMT
Location: https://www.example.com/ (该资源的新的链接, 服务器期望用户代理去访问它)
Keep-Alive: timeout=15, max=98
Accept-Ranges: bytes
Via: Moz-Cache-zlb05
Connection: Keep-Alive
X-Cache-Info: caching
X-Cache-Info: caching
Content-Length: 325 (如果用户代理不能跟随新的链接, 那么就显示一个默认页面)
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>301 Moved Permanently</title>
</head><body>
<h1>Moved Permanently</h1>
<p>The document has moved <a href="https://www.example.com/">here</a>.</p>
<hr>
<address>Apache/2.2.3 (Red Hat) Server at www.example.com Port 80</address>
</body></html>
请求的资源不存在的通知:
HTTP/1.1 404 Not Found
Date: Sat, 09 Oct 2010 14:33:02 GMT
Server: Apache
Last-Modified: Tue, 01 May 2007 14:24:39 GMT
ETag: "499fd34e-29ec-42f695ca96761;48fe7523cfcc1"
Accept-Ranges: bytes
Content-Length: 10732
Content-Type: text/html
<!DOCTYPE html... (包含一个站点自定义的页面, 帮助用户找到丢失的资源)
响应状态码
HTTP 响应状态码 用来表示一个 HTTP 请求是否成功完成. 响应被分为 5 种类型: 信息型响应, 成功响应, 重定向, 客户端错误和服务器错误.
200: OK. 请求已成功.
301: Moved Permanently. 这个响应码表示请求资源的 URI 已经被改变了.
404: Not Found. 服务器无法找到请求的资源.
HTTP/1.x 的连接管理
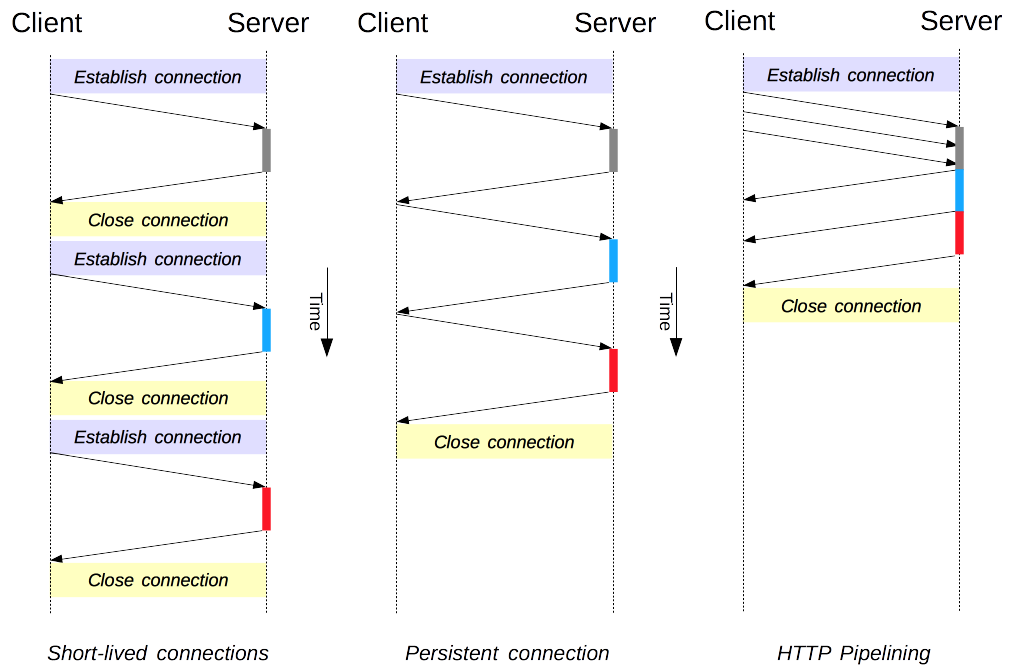
在 HTTP/1.x 里有几个模型:短连接(short-lived connections), 长连接(persistent connections), 和 HTTP 流水线(HTTP pipelining)。
HTTP/2 新增了其它连接管理模型。
HTTP 的传输协议主要依赖于 TCP 来提供从客户端到服务器端之间的连接。在早期,HTTP 使用一个简单的模型来处理这样的连接。这些连接的生命周期是短暂的:每发起一个请求时都会创建一个新的连接,并在收到应答时立即关闭。
这个简单的模型对性能有先天的限制:打开每一个 TCP 连接都是相当耗费资源的操作。客户端和服务器端之间需要交换好些个消息。当请求发起时,网络延迟和带宽都会对性能造成影响。现代浏览器往往要发起很多次请求(十几个或者更多)才能拿到所需的完整信息,证明了这个早期模型的效率低下。
有两个新的模型在 HTTP/1.1 诞生了。
首先是长连接模型,它会保持连接去完成多次连续的请求,减少了不断重新打开连接的时间。
然后是 HTTP 流水线模型,它还要更先进一些,多个连续的请求甚至都不用等待立即返回就可以被发送,这样就减少了耗费在网络延迟上的时间。
HTTP 的连接管理适用于两个连续节点之间的连接,如 hop-by-hop,而不是 end-to-end。当模型用于从客户端到第一个代理服务器的连接和从代理服务器到目标服务器之间的连接时(或者任意中间代理)效果可能是不一样的。HTTP 协议头受不同连接模型的影响,比如 Connection 和 Keep-Alive,就是 hop-by-hop 协议头,它们的值是可以被中间节点修改的。
短连接(Short-lived connections)
HTTP 最早期的模型,也是 HTTP/1.0 的默认模型,是短连接。每一个 HTTP 请求都由它自己独立的连接完成;这意味着发起每一个 HTTP 请求之前都会有一次 TCP 握手,而且是连续不断的。
TCP 协议握手本身就是耗费时间的,所以 TCP 可以保持更多的热连接来适应负载。短连接破坏了 TCP 具备的能力,新的冷连接降低了其性能。
这是 HTTP/1.0 的默认模型(如果没有指定 Connection 协议头,或者是值被设置为 close)。而在 HTTP/1.1 中,只有当 Connection 被设置为 close 时才会用到这个模型。
除非是要兼容一个非常古老的,不支持长连接的系统,没有一个令人信服的理由让人坚持使用这个模型。
长连接(Persistent connections)
短连接有两个比较大的问题:创建新连接耗费的时间尤为明显,另外 TCP 连接的性能只有在该连接被使用一段时间后(热连接)才能得到改善。为了缓解这些问题,长连接 的概念便被设计出来了,甚至在 HTTP/1.1 之前。或者这被称之为一个 keep-alive 连接。
一个长连接会保持一段时间,重复用于发送一系列请求,节省了新建 TCP 连接握手的时间,还可以利用 TCP 的性能增强能力。当然这个连接也不会一直保留着:连接在空闲一段时间后会被关闭(服务器可以使用 Keep-Alive 协议头来指定一个最小的连接保持时间)。
长连接也还是有缺点的;就算是在空闲状态,它还是会消耗服务器资源,而且在重负载时,还有可能遭受 DoS attacks 攻击。这种场景下,可以使用非长连接,即尽快关闭那些空闲的连接,也能对性能有所提升。
HTTP/1.0 里默认并不适用长连接。把 Connection 设置成 close 以外的其它参数都可以让其保持长连接,通常会设置为 retry-after。
在 HTTP/1.1 里,默认就是长连接的,协议头都不用再去声明它(但还是会把它加上,防止因为某种原因要退回到 HTTP/1.0 )。
HTTP 流水线(HTTP pipelining)
默认情况下,HTTP 请求是按顺序发出的。下一个请求只有在当前请求收到应答过后才会被发出。由于会受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
流水线是在同一条长连接上发出连续的请求,而不用等待应答返回。这样可以避免连接延迟。理论上讲,性能还会因为两个 HTTP 请求有可能被打包到一个 TCP 消息包中而得到提升。就算 HTTP 请求不断的继续,尺寸会增加,但设置 TCP 的 MSS(Maximum Segment Size) 选项,任然足够包含一系列简单的请求。
并不是所有类型的 HTTP 请求都能用到流水线:只有 idempotent 方式,比如 GET、HEAD、PUT 和 DELETE 能够被安全的重试:如果有故障发生时,流水线的内容要能被轻易的重试(repeated)。
今天,所有遵循 HTTP/1.1 的代理和服务器都应该支持流水线,虽然实际情况中还是有很多限制:一个很重要的原因是,仍然没有现代浏览器去默认支持这个功能。由于这些原因,流水线已经在HTTP/2被更好的算法替代,如 multiplexing。
域名分片(Domain sharding)
作为 HTTP/1.x 的连接,请求时序列化的,哪怕本来是无序的,在没有足够庞大可用的带宽时,也无从优化。一个解决方案是,浏览器为每个域名建立多个连接,以实现并发请求。曾经默认的连接数量为 2 到 3 个,现在比较常用的并发连接数已经增加到 6 条。如果尝试大于这个数字,就有触发服务器 DoS 保护的风险。
如果服务器端想要更快速的响应网站或应用程序的应答,它可以迫使客户端建立更多的连接。
例如,不要在同一个域名下获取所有资源,假设有个域名是 www.example.com,可以把它拆分成好几个域名:www1.example.com、www2.example.com、www3.example.com。所有这些域名都指向同一台服务器,浏览器会同时为每个域名建立 6 条连接(在这个例子中,连接数会达到 18 条)。这一技术被称作域名分片。

除非有紧急而迫切的需求,一般不使用这一过时的技术,升级到 HTTP/2 就好了。在 HTTP/2 里,做域名分片就没必要了:HTTP/2 的连接可以很好的处理并发的无优先级的请求。域名分片甚至会影响性能。大多数 HTTP/2 的实现还会使用一种称作连接凝聚(connection coalescing)的技术去尝试合并被分片的域名。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号