redis 问答
1、redis是什么,和应用场景
redis:remote dictionary server 远程数据服务或远程字典服务。 c语言写的key-value 存储系统
应用场景:缓存,数据库,消息队列,分布式锁,点赞列表,排行榜等
2、redis的八种数据类型
5种基本数据类型:
string:字符串。计数器,粉丝数,简单分布式锁
hashmap:key-value,value是一个map?
list:列表。可以当做 栈,队列,阻塞队列
set:集合,不能重复。点赞,收藏等
zset:有序集合,不能重复。有序集合的每个元素都需要指定一个分数,根据分数升序排列。排行榜等
3种特殊类型:
geospatial:3.2推出Geo类型,可以推算地理位置,两地之间的距离
hyperloglog:数学上集合的元素个数,不能重复,可以用来 统计网站的UV
bitmap:bit的值可以是0或1。表示某个元素对应的值或状态,可以统计用户信息例如 活跃分数,是否登录,是否打卡等
3、redis为何这么快
官方数据 redis 每秒可以支持 10w并发,原因大概如下
基于内存:
单线程模型处理客户请求,避免上下文切换
io多路复用:
c语言实现,有很多优化机制,例如动态字符串sds
4、redis6.0之后有多线程,会导致线程安全问题吗
不会。redis 依然是单线程模型处理客户端请求,只是多线程处理 读写和协议解析
执行命令还是单线程,所以不会有线程安全问题
引入多线程是因为:redis的性能瓶颈是网络io,而非cpu,多线程可以提高 io读写效率(io密集型?)
5、redis持久化机制,优缺点
redis有两种持久化机制:AOF 和 RDB
AOF:redis每执行一个命令,会将原语句记录到aod文件中,再通过fsync 策略将执行后的数据持久化到硬盘上(不含读语句)
优点:最多丢失1秒数据;
写入性能高(命令直接追加在文件末尾);
适合灾难性误删除恢复(AOF日志文件可读,如果flushall清空数据,但是还没有rewrite,就可以把flushall命令删除,进行恢复)
缺点:AOF文件比RDB数据快照大;
aof每次命令都写入,比rdb消耗性能多,aof重写可以优化文件
数据恢复慢,不适合冷备
RDB:redis默认持久化方式,周期性备份redis的整个文件(某个时间点,redis内存中的数据以二进制形式存储在rdb文件中),也为快照。采用fork子线程的方式来 写时同步
优点:大量数据恢复快(因为有全部数据快照);对读写影响小(因为是fork子线程)
缺点:可能会丢失较长时间的数据;同步可能会影响redis工作(fork子线程与redis数量量关系很大,可能有暂停几秒,如果数据大)
6、redis的过期键的删除策略
定时删除:每个设置了过期时间的key需要创建一个定时器,过期则删除。对内存友好,就是让cpu挺忙的
惰性删除:访问key才判断是否过期,及删除。节省了cpu资源,但是白白浪费了内存
定期删除:定期任务扫描 过期的key,并删除。是前两种方式的折中,平衡cpu和内存
7、redis的内存淘汰策略- 8种
- 1.noeviction:直接返回错误,不淘汰任何已经存在的redis键
- 2.allkeys-lru:所有的键使用lru算法进行淘汰
- 3.volatile-lru:有过期时间的使用lru算法进行淘汰
- 4.allkeys-random:随机删除redis键
- 5.volatile-random:随机删除有过期时间的redis键
- 6.volatile-ttl:删除快过期的redis键
- 7.volatile-lfu:根据lfu算法从有过期时间的键删除
- 8.allkeys-lfu:根据lfu算法从所有键删除
8、热key问题怎么解决
热key:大量请求方位某一个key,导致redis宕机
解决:结果缓存到本地内存;热key分散到不同服务器;永不过期;
9、缓存击穿,穿透,雪崩,怎么解决
缓存穿透:请求的数据在缓存和数据库都不存在,每次都要查数据库并返回空
解决:步隆过滤器;返回空对象
缓存击穿:大并发对热点key 集中访问,key失效的瞬间,持续的大并发穿透缓存,直接请求数据库。就好像 火力集中在屏幕击穿了一个洞
解决:互斥锁;永不过期
缓存雪崩:缓存中不同的数据大批量到了到期时间,而且查询数据量大,请求直接到数据库,导致宕机
解决:均匀过期;互斥锁;永不过期;双重缓存;
10、redis的部署方式
哨兵是不是可以附在 主从和集群模式上??
单机:一台机器读写,一般开发自测
主从:主负责写,从负责读
哨兵:哨兵是独立的进程,独立运行。原理是哨兵发送命令,等待redis服务器响应,从而监控多个redis实例。具备自动故障转移,集群监控,消息通知等
cluster集群:redis 3.0支持,自动将数据进行分片,每个master放一部分数据,提供内置高可用服务。
11、哨兵的作用
监控主从数据库,观察是否正常运行
如果主有异常,自动升级从为主。
12、哨兵选举过程
发现该master挂了的哨兵,发送命令给其他哨兵,让其选举自己
超过设定的 quoram参数,则为领头哨兵
确定好领头哨兵后,开始故障恢复,选择一个从数据库作为新的master
13、cluster集群怎么存放数据
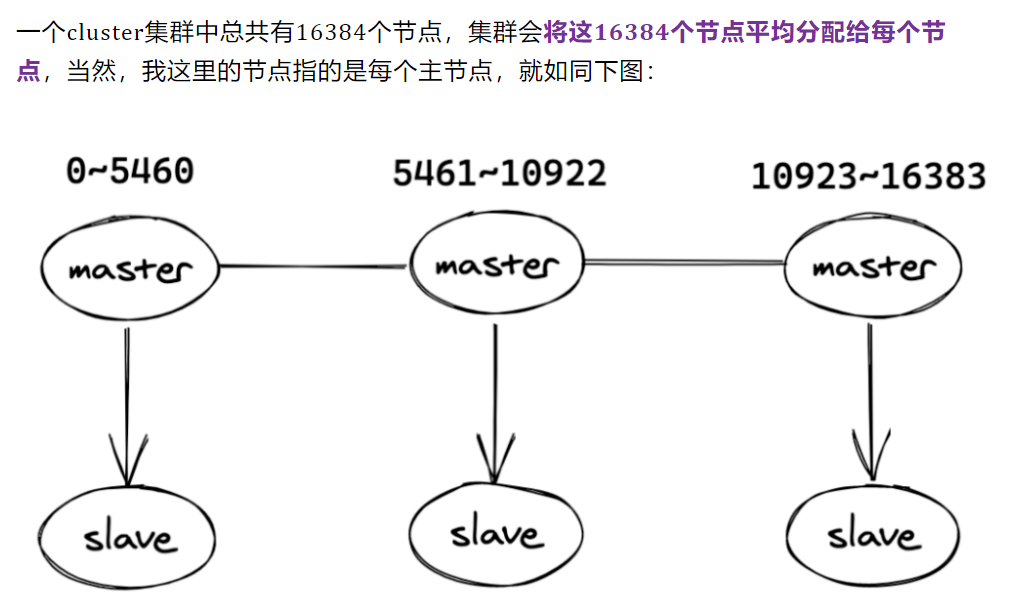
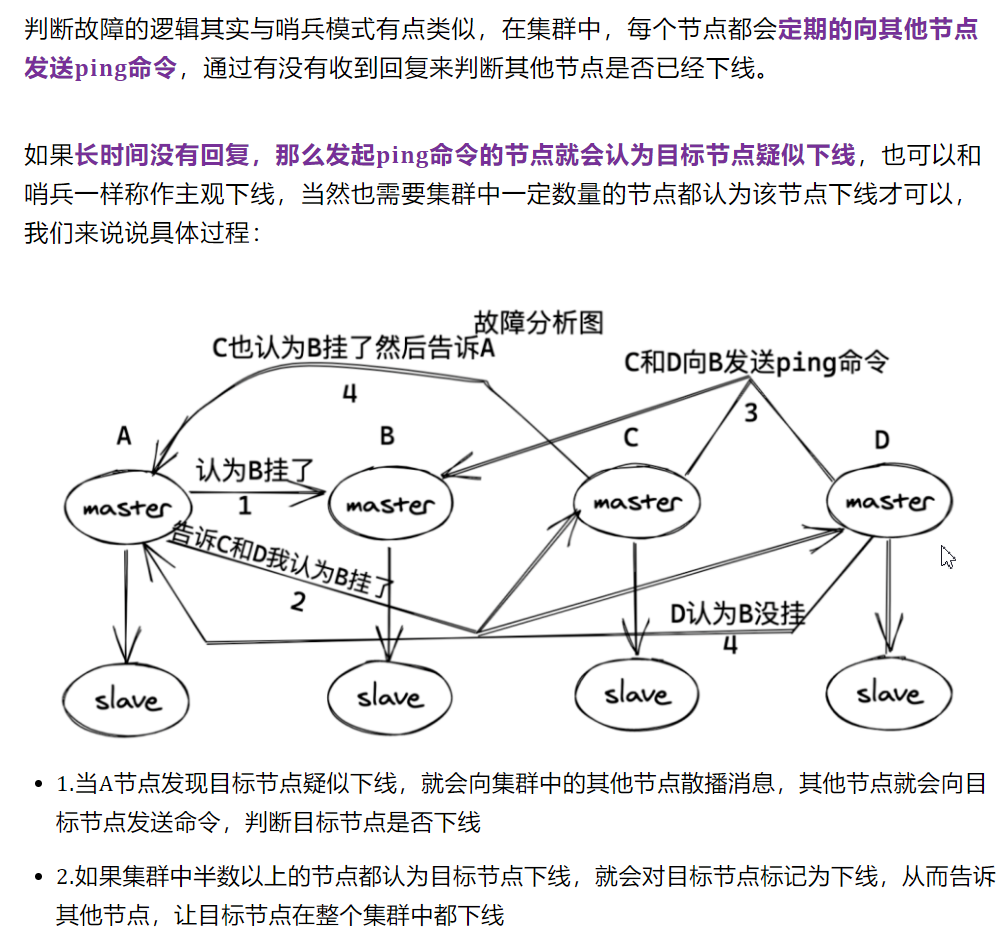
14、cluster故障恢复是怎样的
15、主从同步原理
1)从库启动,向主发送sync命令,master收到后,在后台保存快照(RDB持久化),保存期间如有其它命令会缓存起来
2)快照完成后,缓存的命令+快照 都打包给slave,保证主从一致
3)从库收到缓存命令+快照后,写入磁盘临时文件,写完后替换 RDB 快照。因为是fork子线程,这些操作不会阻塞,依然可接受其他命令
因为不会阻塞,如果主库还有修改数据的命令,会异步给slave,也就是 复制同步阶段。主从同步完成后,复制同步才结束
16、无磁盘复制是什么(直接通过网络io给slave)
主从通过rdb快照交互,存在如下问题:

1、
参考文章:
https://mp.weixin.qq.com/s/j7NzkVJlxYWrPAdqPi7BwA
备注:公众号清汤袭人能找到我,那是随笔的地方

 浙公网安备 33010602011771号
浙公网安备 33010602011771号