
mysql 问答
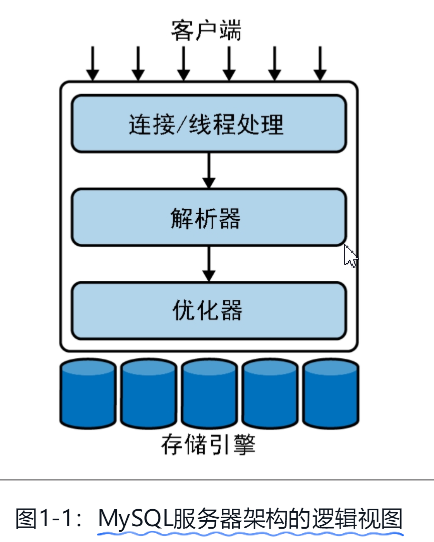
1、服务器架构的逻辑视图
2、mysql执行一条语句的内部过程
连接器:客户端连接过来
权限验证、查询缓存:连接器权限验证通过后,查看是否有缓存,有就直接返回
分析器:词法语法分析,分析是否有语法错误,有则返回
优化器:看下哪个索引合适
执行器:执行语句并返回结果
3、mysql常用引擎
innodb(5.5.5 后默认),myIsam,memory
4、innodb 和myisam 区别
innodb:支持事务,崩溃可以安全恢复, 表级和行级锁,支持外键,不支持fulltext的全文索引(不过可以用sphinx插件支持全文索引,效果更好)
myisam:不支持事务,崩溃不可以安全恢复,表级锁,不支持外键,性能更高,支持fulltext的全文索引
5、回表查询
普通索引查询到主键后,再回到主键索引树上 查询,称为回表查询
6、主键删除后,是不是就没有主键,无法回表查了
不是,主键删除后,会生成 6 字节的rowid作为主键,
7、自增表有3条数据,删2再重启数据库,再插入一条,id=多少
myisam=4,innodb=2, (8.0之前版本)
8、清空数据,truncate更快,不用写log。delete要写
9、唯一索引和普通索引,哪个更好(这里注意区别,修改时要到内存)
查询:没区别,都是从索引树查询
修改:唯一索引更慢,因为要读取数据到内存,并判断是否冲突
9、最左匹配,生效规则
最左匹配:索引以最左边为起点,任何连续的的索引都可以匹配,遇到(大于,小于,between,like)停止匹配
生效原则来看以下示例,比如表中有一个联合索
引字段 index(a,b,c):
• where a=1 只使用了索引 a;
• where a=1 and b=2 只使用了索引 a,b;
• where a=1 and b=2 and c=3 使用 a,b,c;
• where b=1 or where c=1 不使用索引;
• where a=1 and c=3 只使用了索引 a;
• where a=3 and b like ‘xx%’ and c=3 只使用了索引 a,b。
10、事务特性
acid
原子性:全部执行 或 全部不执行
一致性:一种正确状态转为另一种正确状态
隔离性:事务正确提交前,不能把数据改变给其他事务
持久性:事务提交后,永久落库
11、mysql的事务隔离级别
读未提交:会出现肮读
读已提交: 会出现不可重复读 (重点是update和delete)
可重复读:会出现幻读(查询某个范围数据,其他事务又在该范围插入了,重点是 insert) mysql的默认级别
串行:
transaction-isolation = REPEATABLE-READ
可用的配置值:READ-UNCOMMITTED、READ-COMMITTED、REPEATABLEREAD、SERIALIZABLE
12、innodb为何用B+树,而不是 b树,hash,二叉树,红黑树
b树:非叶子节点也保留数据,导致指针数少,
hash 查询慢
二叉树 不能自平衡,太高
红黑树:数据越多,高度越高,io成本大
13、怎么处理死锁
设置超时;回滚(好像找范围最小的释放) 2个策略
• 通过 innodb_lock_wait_timeout 来设置超时时间,一直等待直到超时;
• 发起死锁检测,发现死锁之后,主动回滚死锁中的某一个事务,让其他事
务继续执行。
14、全局锁,应用场景
对整个数据库实例加锁,全量逻辑备份场景适用。整个库处于 只读状态
15、innodb有几种锁算法
record lock:单行记录的锁 (通过索引条件检索记录时,才用行锁,for update)
select * from table where id=4 for update ; 如果查询条件是 索引/主键,则是行锁;否则是表锁
gap lock:间隙锁,某个范围的,不含记录本身
next-key lock:锁某个范围,包含记录本身
【gaplock 解决了幻读,引入了什么问题】性能下降,会死锁
15、mysql的重要日志
错误日志,查询日志,慢日志,redo,undo,bin log
redo:为了断电后,可以再用这个更新
undo:保留数据修改前的内容,用于回滚。例如 delete前,增加一条insert;update前,记录一条相反的
bin log(重要):表结构变更等,用于 恢复,复制,审计
16、redo和bin的区别
redo是物理日志,循环写入。innodb特有的
binlog:归档日志,逻辑日志,例如写的是 给id=2的c字段加1 ? 后面要参考这个 岂不是要分析语义?
追加写入,不会覆盖。 server层的,所有引擎都有
17、聚集索引和非聚集索引
本质上都是数据存储方式
聚集索引:当表有了聚集索引,表的数据行都放在索引树的叶子节点中,无法将数据放在不同的地方,所以表只允许有一个聚集索引。
innodb的聚集索引 实际是将 索引和数据保存在同一个B-Tree中。innodb通过主键聚集数据,如果没有主键,就选择唯一非空索引,如果无,则隐式定义一个主键作为聚集索引
非聚集索引:又叫二级索引,二级索引的叶子节点,没有保存指向行的物理指针,而是行的主键值。通过二级索引查找行时,先根据叶子节点找到主键,再去聚集索引根据主键找到数据行。
需要两次b-tree 查询
18、分布式事务:
0、标题:
参考地址
http://wed.xjx100.cn/news/133932.html?action=onClick
备注:公众号清汤袭人能找到我,那是随笔的地方


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现