


小型Http服务器
HTTP又叫做超文本传输协议,现如今用的最多的版本是1.1版本。HTTP有如下的特点:
支持客户/服务器模式(C/S或B/S)
简单快速:基于请求和响应,请求只需传送请求方法和请求路径
灵活:HTTP允许传送人任意类型的数据对象。
无连接:这个无连接说的是应用层,应用层无连接,下层使用TCP依然是面向连接的,无连接的含义是限制在每一次连接只处理一个请求,服务器处理完客户的请求以后,收到客户应答,就断开连接。
无状态:HTTP是无状态协议。无状态是指协议对于事务处理没有记忆能力。这次的请求和上次的请求之间是没有关系的。缺少状态意味着如果后续处理需要前面的一些信息,则必须重传,这样可能导致每次连接传送的数据量增大,但是当服务器不需要前面的信息时他的应答较快。
我们平常使用的HTTP协议工作过程如下:
一个HTTP操作叫做事物:
1)首先客户机与服务器需要建立连接。
2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:请求方法|统一资源标识符(URL)|协议版本号,后面是MIME信息包括请求修饰符、客户机信息和可能的内容。
3)服务器接到请求后,基于相应的响应信息、实体信息和可能的内容。
4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机和服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要点击鼠标,等待信息显示就可以了。
我们所实现的HTTP也要能够实现这些基本的功能。
本文的重点在于介绍HTTP服务器的框架结构,旨在了解HTTP服务器的流程,然后自己实现一个多线程的HTTP/1.0版本服务器,支持GET和POST方法。
首先我们来了解一下HTTP协议
1.URL(统一资源定位符)
它是一种特殊类型的URI,包含了用于查找某个资源的足够信息。
URL格式:
http://host[":"port][abs_path]
http表示通过http协议来定位网络资源,host表示合法的主机域名或IP地址。port指定一个端口号,为空则默认使用80端口。abs_path指定请求资源的路径,如果URL中没有给出abs_path,那么浏览器会自动加上"/",表示web根目录。
如:http://baidu.com经过浏览器之后变成http://baidu.com/
上面都是不带参的URL,带参数的URL如下:
https://www.baidu.com/?wd=100&rsv_spt=1
其中“?”表示参数的开始,每个参数都是“name=value”的形式,每个参数之间以“&”分隔。
2.HTTP请求和响应格式
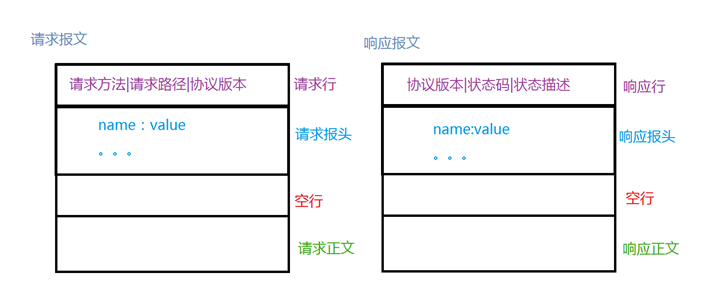
请求报文是由请求行、请求报头、空行和请求正文组成,响应报文是由响应行、响应报头、空行和响应正文组成。
请求方法:
GET:请求获取Request-URI所标识的资源
POST:在Request-URI所标识的资源后附加新的数据
HEAD:请求获取Request-URI所标识的资源的响应消息报头
DELETE:请求服务器删除Requet-URI作为其标识
. . . . . . .
最常用的就是GET方法和POST方法了。
请求路径:表示的是请求资源的路径,如果是GET方法的话,可以带有参数。他的值就是URL中的abs_path.如果是POST方法的话它的参数在消息正文中。
空行实际上是一种避免粘包的策略,我们知道,第一行是请求行,从第二行开始一直到空行就是消息报头了。
状态码:
状态码由三位数字组成,总共分为5类:
1xx:指示信息,表示请求已接受,继续处理
2xx:成功 表示请求被成功接收、理解、接受
3xx:重定向 要完成请求必须进行更一步的操作
4xx:客户端错误 请求语法有错误或请求无法实现
5xx:服务器端错误 服务器未能实现合法的请求
常见状态码:
200 OK //客户端请求成功
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,也就是输入了错误的URL
500 Internal Server Error //服务器发生了不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求
这里我们还要补充一个知识就是HTTP的长连接和短连接
HTTP协议的长连接和短连接实际上是TCP的长连接和短连接。
长连接:HTTP/1.1开始使用长连接,用来保持连接的特性。使用长连接的HTTP协议会在响应头加入一行代码:Connection:keep-Alive,在使用长连接的情况下,当网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次去访问这个服务器上面的网页,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接的,它会有一个保持时间,可以再不同的服务器软件上去设动这个时间。实现长连接需要服务器和客户端都支持长连接。
短连接:HTTP/1.0默认使用短连接,浏览器和服务器每进行一次HTTP操作,就建立一次连接,任务结束以后中断连接。当客户端浏览器再次访问西苑的时候,就需要重新建立会话。
以下是长短连接的操作:
长连接: 建立连接——数据传输。。。(保持连接)。。。数据传输——关闭连接
短连接:
建立连接——数据传输——关闭连接。。。建立连接——数据传输。。。
HTTP协议的底层使用TCP协议,所以HTTP协议的长短连接本质上是TCP的长短连接。长连接可以节省较多的TCP连接、释放的操作,节省时间,对于频繁请求资源的用户来说,长连接最适合不过了。但是由于有保活功能,当遇到大量的恶意连接时,服务器的压力会越来越大。这时服务器会采取一些策略,关闭一些长时间没有进行读写事件的连接。短连接对服务器来说管理比较简单,只要是存在的连接都是有效的连接,不需要额外的控制手段,而且不会长时间的占用资源。但如果客户端请求频繁的话,会在TCP建立和连接上浪费大量的时间。HTTP长短连接没有什么好坏优劣之分,只是使用的场景不同罢了。
下面我们就正式开始了解HTTP整体框架设计:
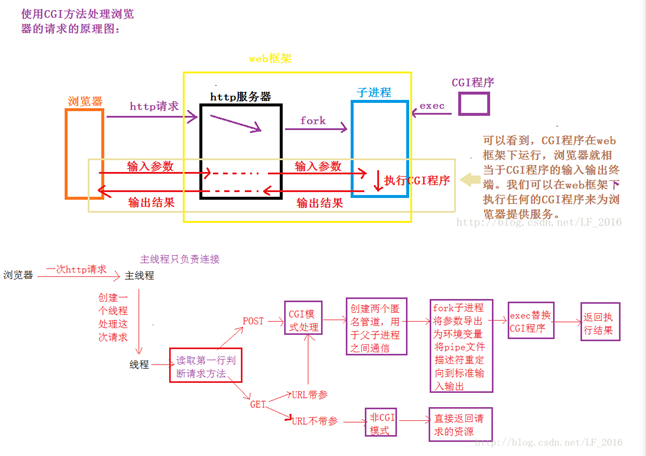
http/1.0版本的服务器采用的是短连接。我们要搭建的是多线程服务器并且使用短连接,所以每当建立一个连接之后,就创建一个线程去处理这个请求,并将这个线程设置成分离状态,然后主线程继续处于监听状态。当线程处理完这个请求之后,然后断开连接。这样一来一回就处理完一个请求。
CGI模式与非CGI模式:
当我们判断是GET请求时,并且URL中没有参数的时候,就使用非CGI模式,非CGI模式比较简单,首先我们需要解析出请求路径,判断请求的是不是合法资源,如果是的话,我们就返回这个资源。
当时CGI模式处理请求的话,我们需要fork一个子进程,对子进程exec替换CGI程序。在这过程中,我们使用pipe进行父子间的通信。所有需要的参数在exec之前,我们都将这些参数导出为环境变量,这样就算exec的话,子进程还是能够通过环境变量获取所需的参数。
如何实现支持GET和POST方法的小型http服务器呢?
GET方法:如果GET方法只是简单的请求一份资源,而不传递参数的话则由服务器直接返回资源即可,如果GET方法的URL中带有参数,则要是用CGI模式进行处理。
POST方法:POST方法要是用CGI模式进行处理。POST的参数在消息正文中出现。(如上图二中所示)
由于请求方法在http请求报文中的第一行,所以我们需要读取第一行然后判断是那种方法,并且判断是不是CGI模式。
我们的整个项目采用了B/S模式(浏览器/服务器模式),通过浏览器发送HTTP的GET和POST方法,然后服务器响应,最终通过html看到我们最终显示的效果。为了支持并发,我们采用了多线程结构。
1.创建监听套接字
创建过程是socket-->bind-->listen
2.进行accpet多线程的建立
我们使用accept接收客户端的connect请求。这个过程实际上是对backlog队列的一个操作。在accept前,内核接收到connect请求首先把socket放入未完成队列,然后accept的时候,需要把socket放入已完成队列当中去,然后accept成功以后从已完成的队列中取出。
accept成功以后,我们使用pthread_create创建线程,把socket托付给线程来进行操作。在线程处理的过程中需要线程等待,为了解决这个问题,我们可以使用线程分离,将线程作为孤儿进程托管给1号进程,当执行完毕之后,由1号进程来进行资源的回收。
3.线程处理
在整个线程处理函数内部,我们对HTTP的请求进行分析,通过对其中的路径参数等信息进行处理。
首先是对HTTP报文信息的处理,从这些中提取出有效的信息,我们采取的读取方式是按行读取。对于HTTP方法的第一行进行读取,这一行的三个字段是按照空格分开的,我们利用这个特性,把HTTP请求的方法,资源路径(URL)和HTTP版本信息提取出来。接下来我们需要考虑处理的就是参数,HTTP请求经常会带有一些参数,通过这些参数请求资源。GET方法的资源是在URL中,POST方法的资源是在消息正文当中。这样我们就能得到资源了。
在非cgi模式下,我们可以得到资源路径,这个资源路径其实是根目录下的路径,默认我们去寻找根目录下的主页。所以我们需要给资源加上index.html,然后我们把整个index.html的信息发送给socket。我们这里采用的方式是sendfile的操作。sendfile主要是实现零拷贝发送文件,实现一个高效的数据传输,并且对其进行验证。这样socket接收到主页信息,就可以显示出来网页了,当然这个过程是按照HTTPPOST响应发送过去的。
在cgi模式下我们处理带参的HTTP请求,我们把这些参数都取出来,然后使得函数获得cgi参数,然后用获取到的参数进行计算或者数据处理。
具体框架如图:
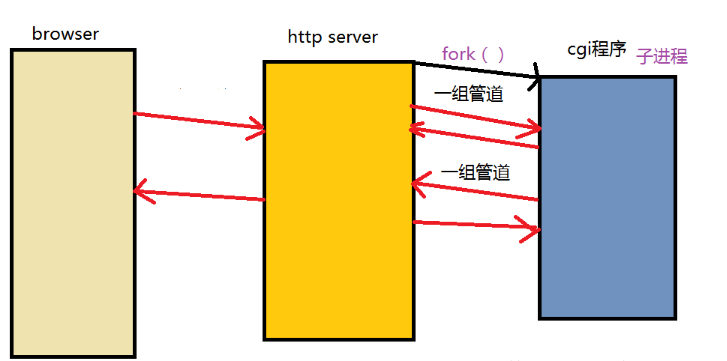
在这里我们的处理方式就是对这两组管道进行一下重定向,对于fork以后的子进程,我们把管道重定向,利用dup2系统调用,然后达到的效果就是子进程最终可以从stdin中得到父进程给的信息,而父进程也就是服务器又可以从socket得到HTTP请求的内容。然后子进程数据计算以后把数据写到stdout中,server从管道中取回数据,发送给socket,这样socket端也就是浏览器那边可以显示最后的结果。在这里面重要的还有一个点就是HTTP的参数如何传递到cgi程序中,我们使用的是环境变量的方式。cgi程序在子程序当中运行,可以获取到环境变量所以就可以得到所需的参数,下面是具体细节:
GET cgi模式:GET方法的时候,这时CGI所需要的参数是放在URL中的,所以这个时候我们就去在HTTP GET请求行的第二个内容资源路径中进行字符串的处理,我们找“?”,当找到以后,我们让指针指向这里,叫做query_string,我们把这个作为环境变量传给子进程就可以了。对于GET的cgi模式,最重要的就是method和query_string.
POST cgi模式:使用POST cgi模式时会有一个问题,就是我们的参数是在正文当中,另外需要知道正文的字节数。这个时候POST消息报头就起作用了,它在其中阻止了name:value形式的content_length:xxx这样的内容,然后获取到这个长度之后,我们就可以知道socket读取多少长度的内容了,然后读取完之后我们就可以获得参数,同样是按照“?”和“&”形式组织的,我们取出这个内容,然后进行数据操作。
我们需要说一下父进程后续操作,父进程处理的时候需要重定向管道,这样才好进行后续的操作,然后我们进行查看方法,如果是POST方法,我们需要把获取到的HTTP请求的正文全部放入和cgi打交道的管道当中。这样才能让cgi获取到正文信息。其他情况下我们都需要从cgi返回到管道的结果当中进行获取返回的信息,把这个信息发送给socket.最后,使用waitpid等待子进程。
4.cgi的编写方式
cgi的编写方式我们可以叫做cgi网关协议,我们所有的cgi程序需都可以套用这一套来进行操作,我们采用的传递参数方式是环境变量,其实还可以使用管道来传输。然后我们进行字符串处理,因为参数的组织方式是”?data1=100&data2=200”这种形式的,所以我们要找的关键符号就是“=”和“&”这样我们就可以渠道参数进行运算了。

