
C语言学习笔记 - 2
7. 控制语句
if 语句
不推荐用else,虽然符合业务逻辑,但是不够直观,需要将前面 N 个条件判断看懂,才能明白何种条件下才能进入else语句块中。
因此,下面代码中最好用 else if (data % 3 == 2)
int data = 0;
cout << "请输入一个int数值:";
cin >> data;
if (data % 3 == 0)
{
cout << data << "对3的余数为0" << endl;
}
else if (data % 3 == 1)
{
cout << data << "对3的余数为1" << endl;
}
else
{
cout << data << "对3的余数为2" << endl;
}
switch...case 语句
1. 语法格式
case语句中不能初始化变量
switch (表达式1) // 表达式结果不能是实型、字符串
{
case 值1: // 只能是常量表达式:整型(long、int、short、char)
语句1;
break;
case 值2:
语句2;
break;
case 值3:
语句3;
break;
default:
语句4;
break;
}
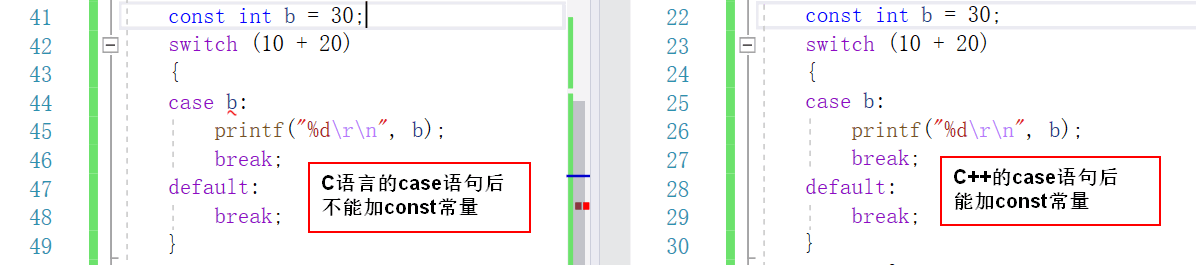
2. C和C++的switch不同点
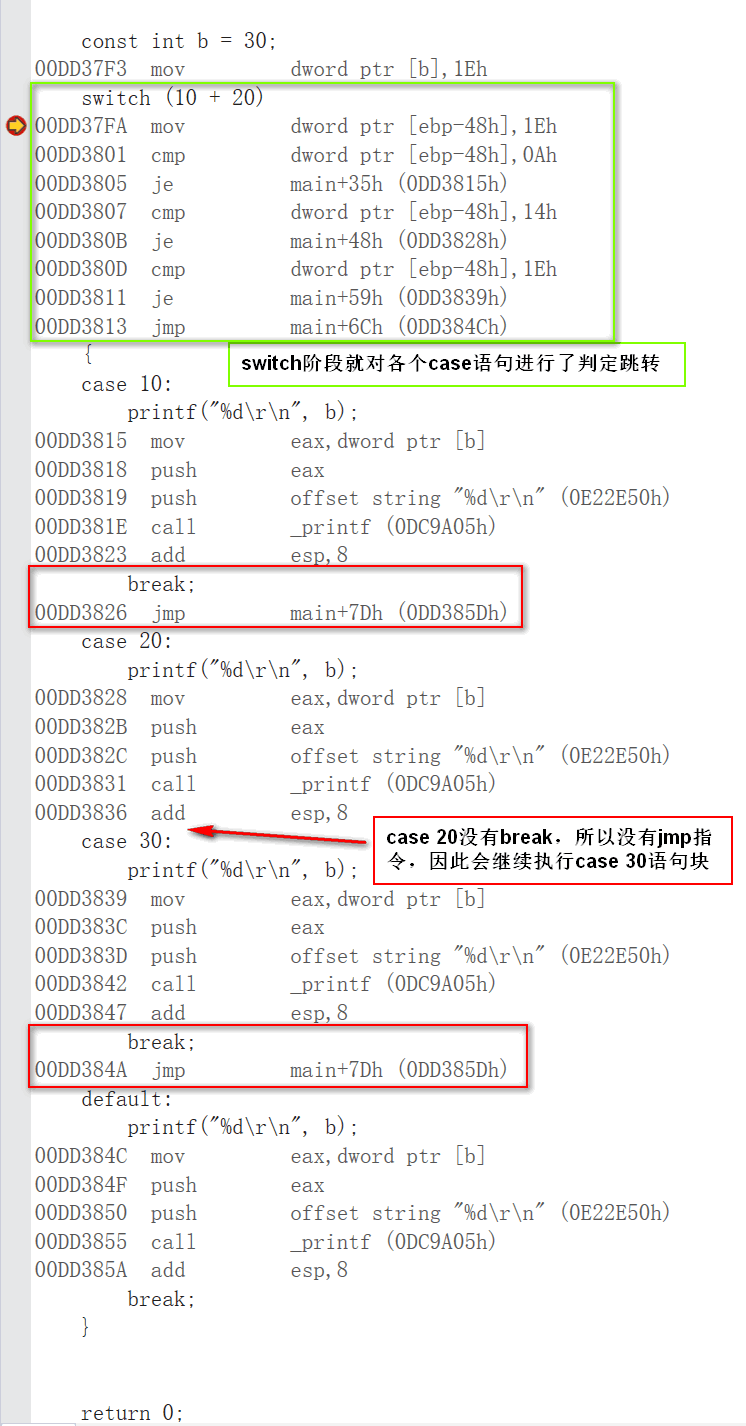
3. switch...case 反汇编
在 case 较少的情况下,switch...case 与if...else 是一样的
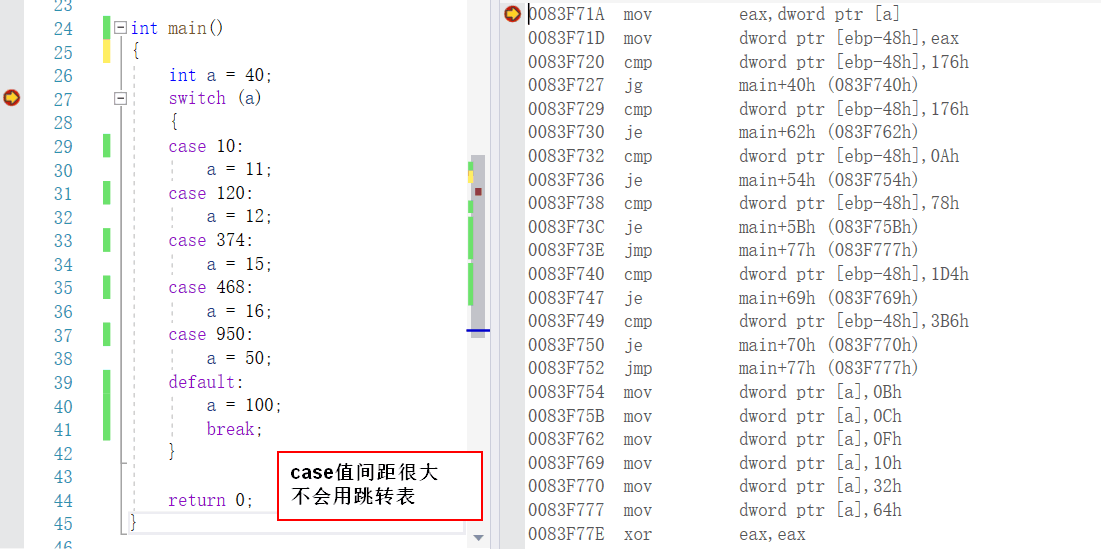
4. switch...case 跳转表
当 case 较多的情况下,编译器会考虑以空间换时间,对 switch case 进行优化(优化方案:添加跳转表)
由于 case 后的数据为相邻整型变量,所以系统在编译阶段,将这些数值映射为跳转表,将表头地址记录下来用于寻址。
- 编译阶段开辟一段连续空间,内部存储每个case语句块的入口地址,将寻址方式写入代码段:
jmp dword ptr [edx*4+0B3844h] - 运行时计算
switch值与case最小值的距离(求差) - 若
距离大于case最小值与case最大值之差,说明switch值大于最大值或小于最小值。直接跳转至default语句块 - 将
距离传入edx中,代入寻址公式跳转
int main()
{
......
int a = 102;
000B37EA mov dword ptr [a],66h
switch (a)
000B37F1 mov eax,dword ptr [a]
000B37F4 mov dword ptr [ebp-4Ch],eax
000B37F7 mov ecx,dword ptr [ebp-4Ch]
000B37FA sub ecx,64h
// 和case中的最小值作差,得到从最小case距离与a相等case之间的距离 ---> 2
000B37FD mov dword ptr [ebp-4Ch],ecx
000B3800 cmp dword ptr [ebp-4Ch],3
// 比较距离是否在范围内 ---> 2 < 3
000B3804 ja $LN7+9h (0B3834h)
// 若距离大于所有case的长度,跳转至default语句块
000B3806 mov edx,dword ptr [ebp-4Ch]
000B3809 jmp dword ptr [edx*4+0B3844h]
// 以0B3844作为基址,加上距离*4(一个地址4位),此处存储的是语句块的起始地址。
{
case 100:
t = 100;
000B3810 mov dword ptr [t],64h
break;
......
default:
t = 104;
000B3834 mov dword ptr [t],68h
break;
}
return 0;
000B383B xor eax,eax
}
case值间距过大不用跳转表
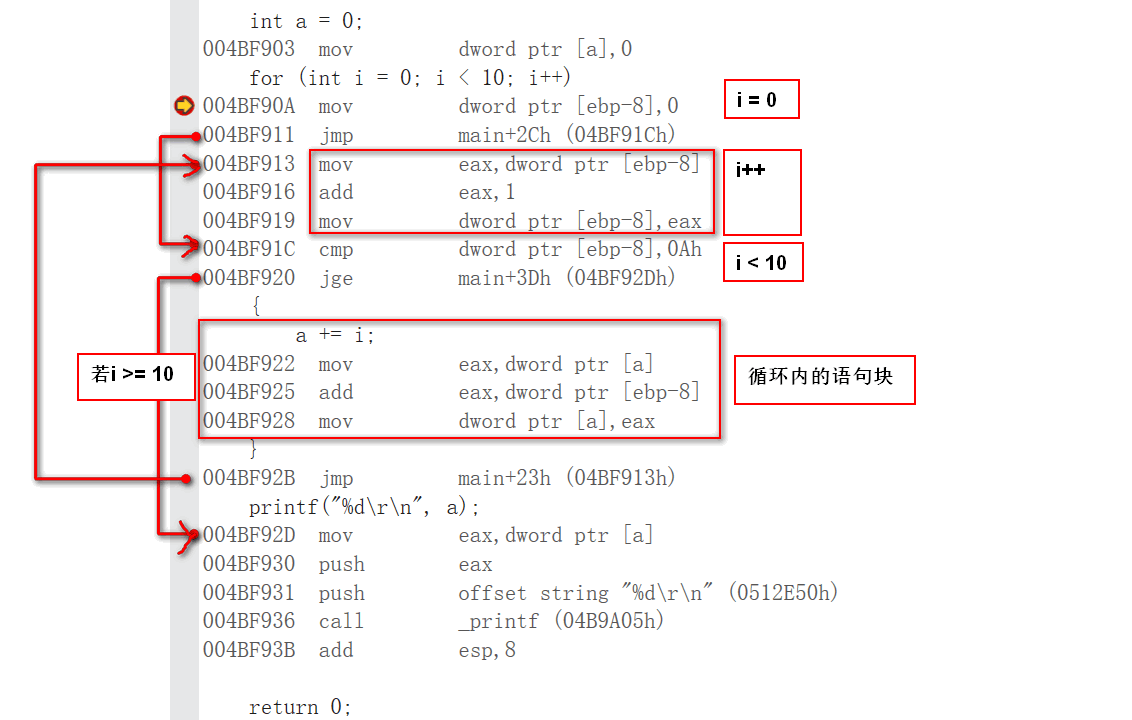
for 循环语句
循环嵌套时:先考虑内层循环,再考虑外层,避免混乱!
for循环语句的汇编实现
while 循环语句
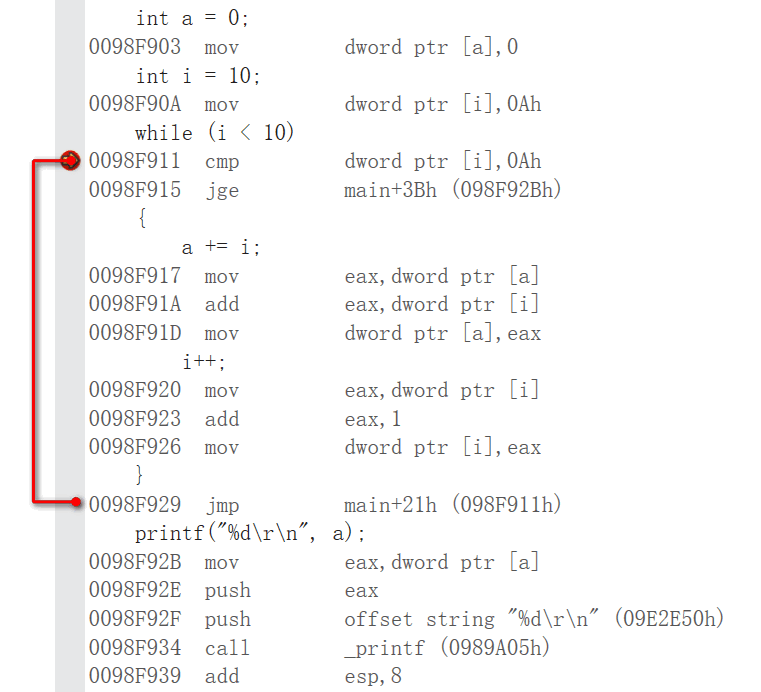
do...while 循环语句
do
{
循环体;
}while(表达式1);

goto 不要用
8. 数组
一维数值数组
局部变量存储在栈区
-
概念:用一段连续的空间,存放相同类型的数据的容器,叫做数组
-
定义一个数组,必须知道该数组
有几个元素,起什么名字,以及每个元素的类型 -
定义步骤:(注意优先级)
- 数组名和中括号结合,表明是数组
- 数组有几个元素,中括号里就写几
- 用数组的元素类型,定义普通变量
- 从上往下,整体替换
定义一个数组有5个元素,每个元素为函数的入口地址,该函数为void func(int, int) arr[5]; *p; void func(int, int); ----->*arr[5] ----->void (*arr[5])(int, int); -
分析步骤
和[]结合表示数组,和*结合表示指针,和()结合表示函数int *arr[5] 指针数组 int (*arr)[5] 数组指针 int (*arr)(int, int) 函数指针数组 -
定义数值数组
int arr[5]; int len = sizeof(arr) / sizeof(arr[0]); for(int i = 0; i < len; i++) { cout << arr[i] << " "; } cout << endl; -
初始化数值数组
// 全部初始化
// int arr[5] = {10, 20, 30, 40, 50};
// int arr[] = {10, 20, 30, 40, 50};
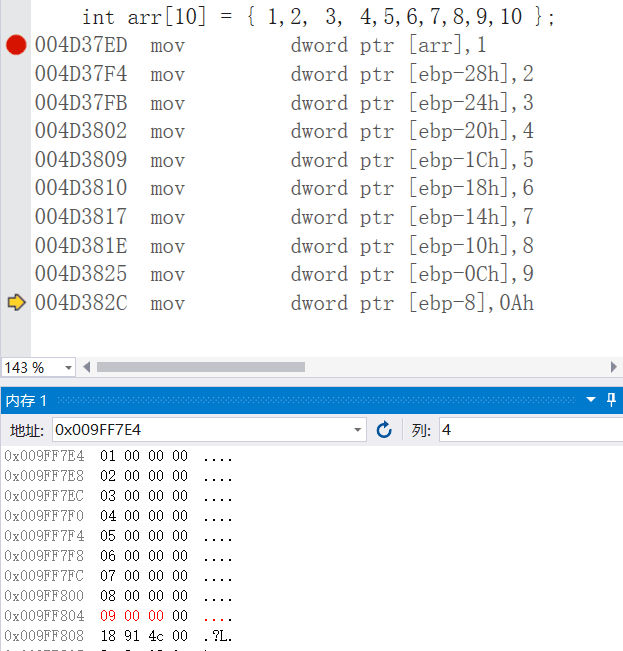
// 部分初始化
// int arr[5] = {10, 20, 30};
// int arr[5] = {0};
int len = sizeof(arr) / sizeof(arr[0]);
for(int i = 0; i < len; i++)
{
cout << arr[i] << " ";
}
cout << endl;

-
指定下标初始化
int arr[] = {1, [3]=5}; -
一维数值数组的元素的操作
二维数值数组
局部变量存储在栈区
定义与概念
int arr[3][4];
sizeof(arr); 二维数组总大小
sizeof(arr[0]); 一行数组的大小
sizeof(arr[0][0]); 数组元素的大小
二维数组的行数 row = sizeof(arr) / sizeof(arr[0])
二维数组的列数 col = sizeof(arr[0]) / sizeof(arr[0][0])
初始化
- 都可以省略行数下标,不能省略列标
- 未被初始化的部分自动补0
-
分段初始化(全部初始化)
int arr[3][4] = {{1,2,3,4},{5,6,7,8},{9,10,11,12}}; -
分段初始化(部分初始化)
int arr[3][4] = {{1,2},{5},{9,10,11}}; -
连续初始化(全部初始化)
int arr[3][4] = {1,2,3,4,5,6,7,8,9,10,11,12}; -
连续初始化(部分初始化)
int arr[3][4] = {1,2,5,9,10,11};
二维数组在内存中线性存储
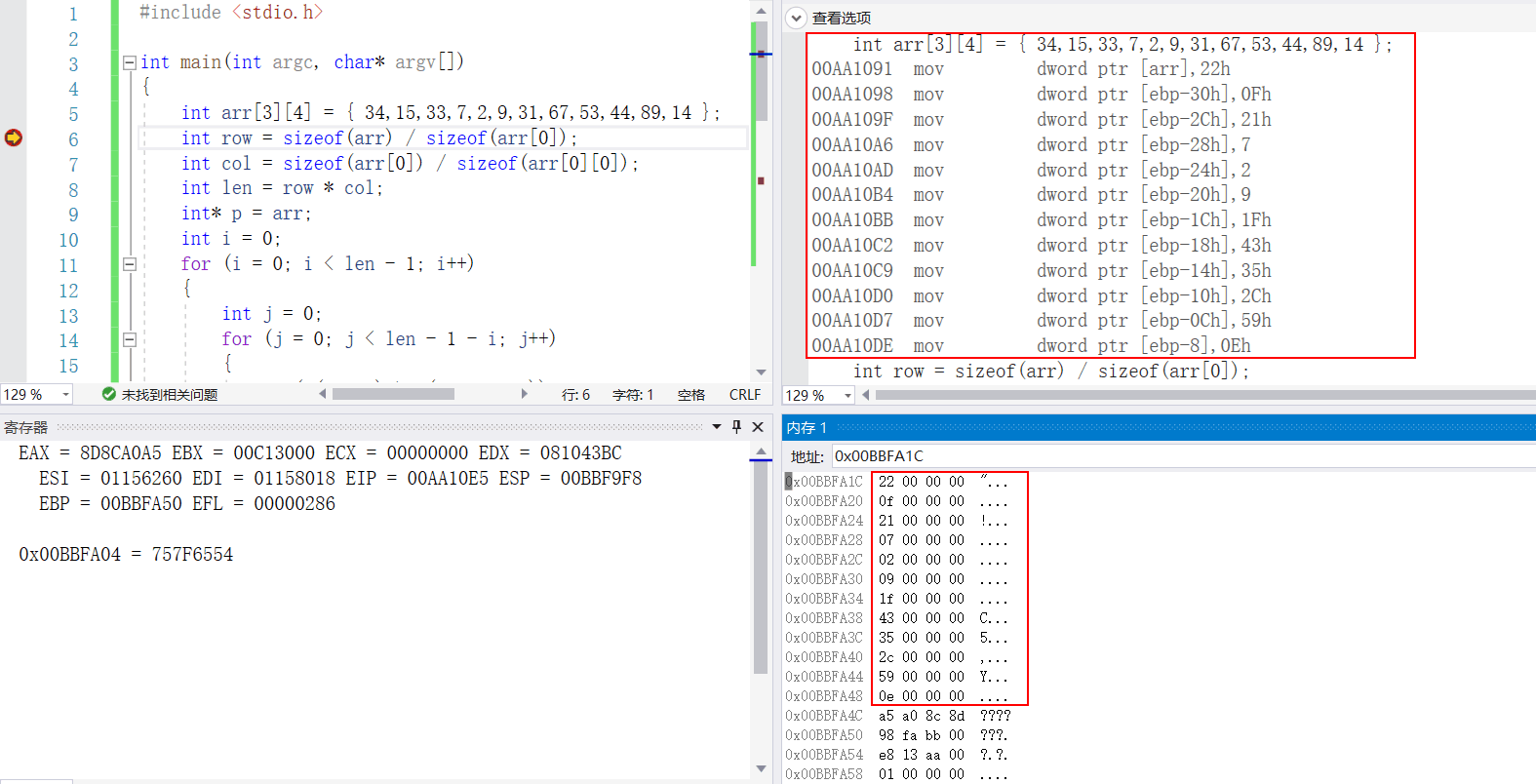
二维数组排序
#include <stdio.h>
int main(int argc, char* argv[])
{
int arr[3][4] = {34,15,33,7,2,9,31,67,53,44,89,14};
int row = sizeof(arr) / sizeof(arr[0]);
int col = sizeof(arr[0]) / sizeof(arr[0][0]);
int len = row * col;
int* p = arr;
int i = 0;
for(i = 0; i < len - 1; i++)
{
int j = 0;
for(j = 0; j < len - 1 - i; j++)
{
if(*(p+j) > *(p+j+1))
{
int tmp = *(p+j);
*(p+j) = *(p+j+1);
*(p+j+1) = tmp;
}
}
}
for(i = 0; i < row; i++)
{
int j = 0;
for(j = 0; j < col; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n");
return 0;
}
使用方法
变化的值放内层循环。
一维字符数组
局部变量:字符数组在栈区,字符串在只读数据区
初始化
- 逐个字符初始化字符数组,未被初始化的部分自动补 '\0'
char buf[32] = {'h', 'e', 'l', 'l', 'o'};
- char buf[5] = {'h', 'e', 'l', 'l', 'o'}; 若输出会造成内存泄露,因为字符串读取遇到 '\0' 才会结束,因此让末尾字符为 '\0',或多申请一个字符让其初始化时自动补 '\0'。
- 以字符串的形式初始化字符数组
char buf[16] = "hello";
- buf[5] = "hello"; 初始化时会内存污染,因为字符串常量会默认在字符串末尾加 '\0'
- 字符数组长度可以不写
char buf[] = "hello";
sizeof(buf) = 6
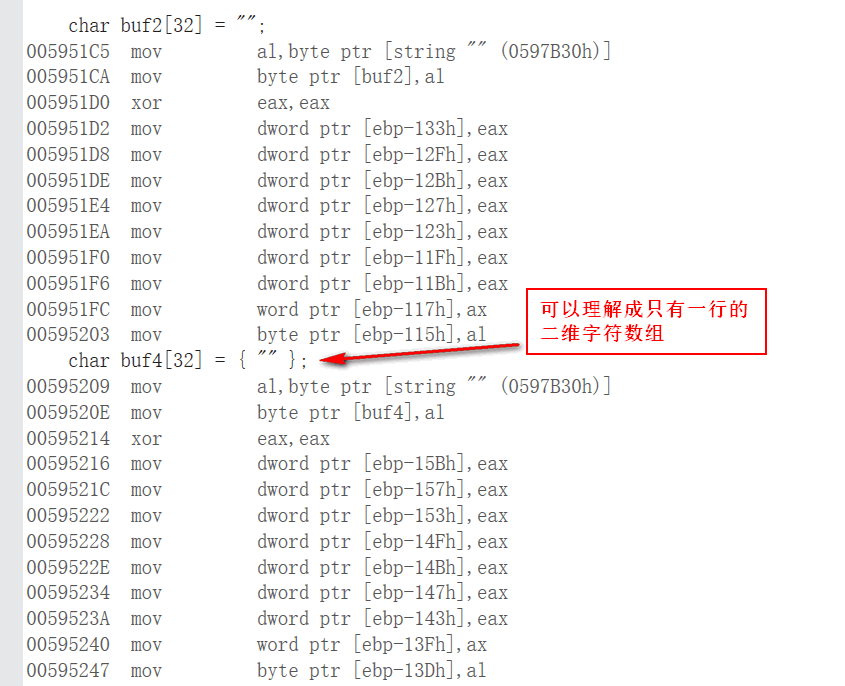
清零
char buf[16] = "";
- 双引号中看起来没有东西,实际上内部存储了一个 '\0',后面自动补 '\0'
遍历
- 用while遍历,以'\0'为判断依据
- 若字符串里有'\0',用for循环逐个字符遍历
- 增、删、改、查、拷贝、替换、加密、图片信息等面向字符的操作,用for循环逐个字符操作
- 直接cout字符串,仅用于查看
字符串
- 不能获取带空格的字符串
- C++获取带空格的字符串:cin.getline(buf, sizeof(buf)); sizeof(buf)中默认包含一个 '\0',所以传4的时候,输出的字符串有3个字符+1个 '\0'
- 字符串是一个变量,使用时给出一个地址,就算是局部变量
char str = "a"也不会存在栈区。
字符串输入
- scanf和%s结合不能获取带空格的字符串,如果首次遇到空格或回车会自动跳过
- gets能获取带空格的字符串,遇到换行符结束(不包含换行符),但是获取输入内容的时候,不会判断字符串大小,容易造成访问越界。
- fget解决了gets的不安全问题,(并且包含换行符)
char *fgets(char *s, int size, FILE *stream); fgets(buf, sizeof(buf), stdin); buf[strlen(buf) - 1] = '\0'; // 清掉回车
二维字符数组
- 二维字符数组局部变量存在栈区,字符串常量存在只读数据区。初始化时以4位为一个块进行拷贝,剩余部分以4位 '\0' 补位

- 字符串常量在只读数据区的话,是连续存储的么?通过反汇编观察到,不一定连续
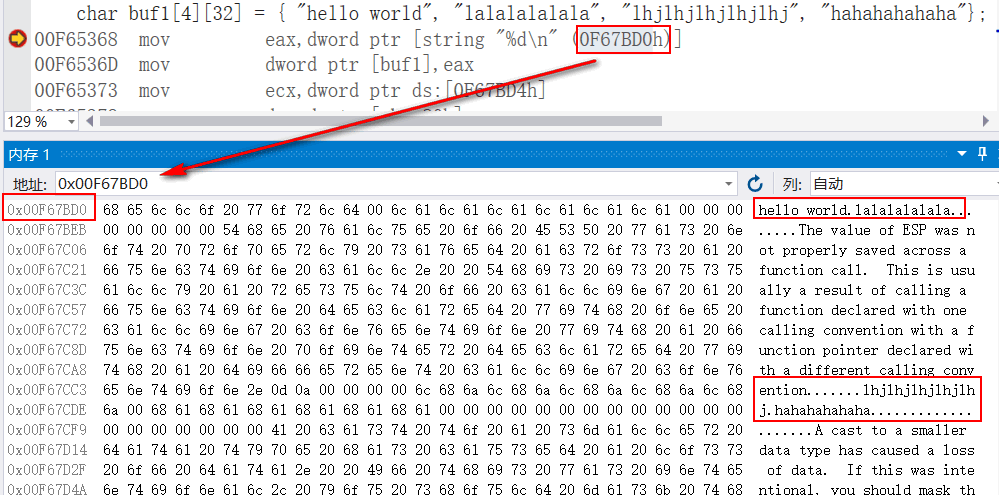
- 二维数组中的某一行越界,造成什么结果?
发现汇编指令用的是rep movs,rep是重复指令,依赖ecx(计数寄存器)重复了多少次。上面存在mov ecx, 8,那么8是从何而来呢?
首先这条指令rep movs dword ptr es:[edi],dword ptr [esi]用的是dword 4字节拷贝,而二维字符数组的列是32位,32 除 4 等于8,刚好将字符数组的一行装满。
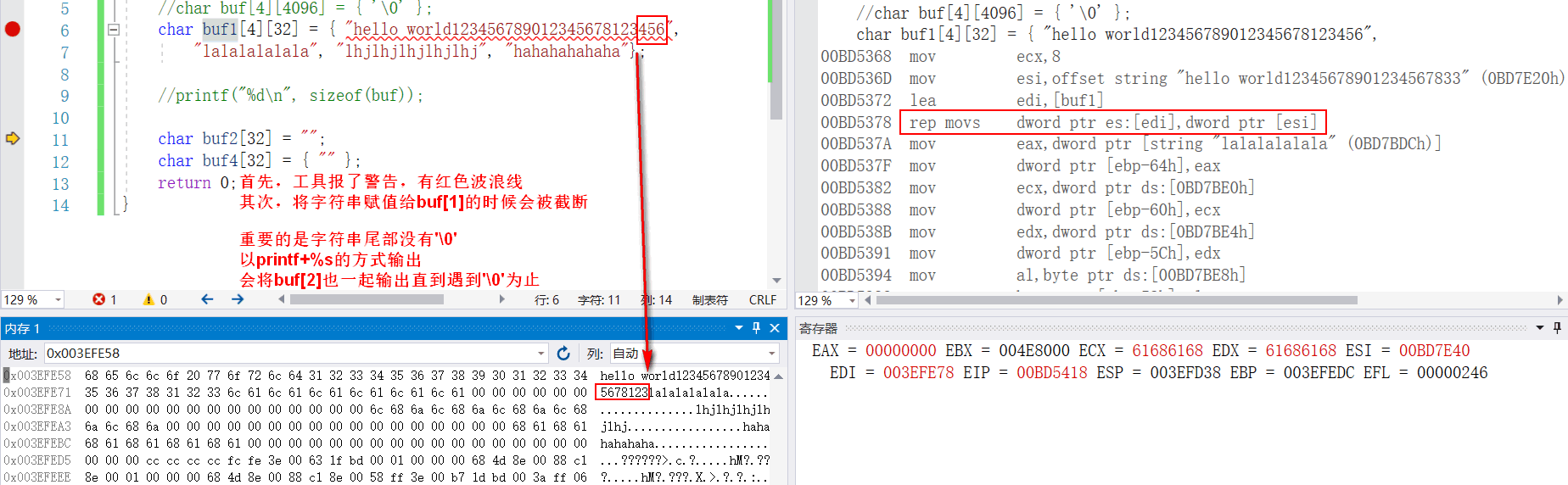
以下初始化的区别?
char buf[4][32] = {'\0'}; // 存在栈区吧?
char buf[4][32] = {""}; // 存在只读数据区?
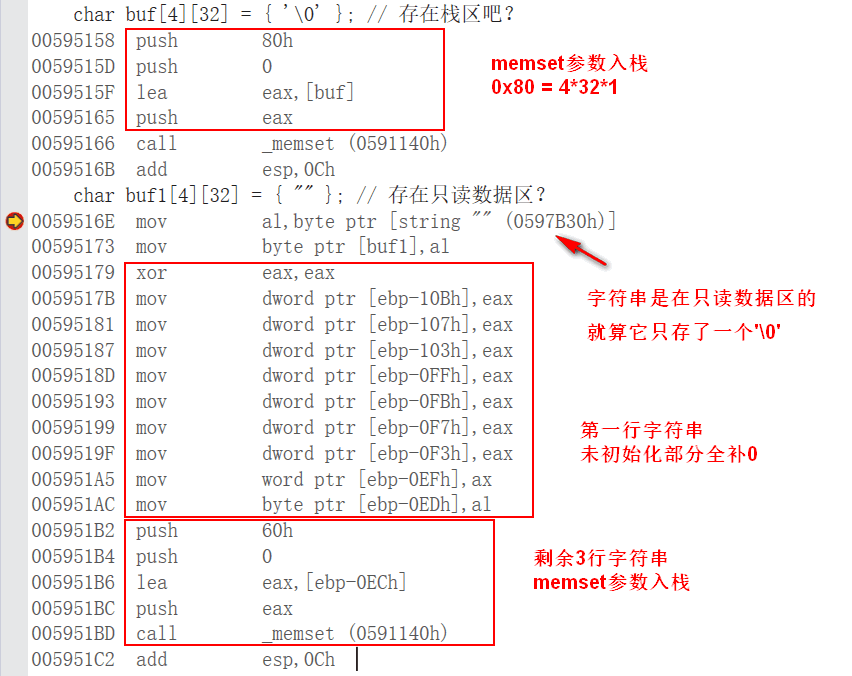
char buf[32] = "";
char buf[32] = {""};

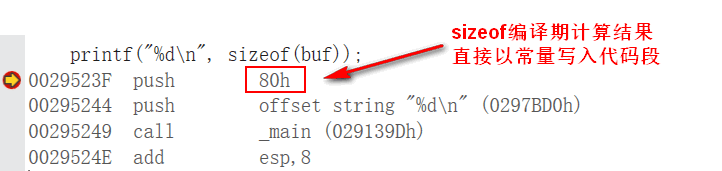
strlen和sizeof的区别
- strlen函数测量字符串变量的长度(遇到 '\0' 结束测量,长度不包含 '\0' )
- sizeof函数测量字符串类型的长度,包含 '\0'
- 【注】从数组作为函数的形参中能明确该问题,不能在函数里用sizeof计算大小,因为它是指针变量或数组指针变量,但是能用strlen计算字符串大小,因为它遇到'\0'结束
- sizeof是关键字,编译器就计算出结果,将结果直接作为常量写在代码段
9. 函数
函数定义原则
- 函数的功能要单一
- 除业务必须使用外,不要用全局变量,会破坏函数封装性
- 封装性。不管调用几次,函数只有一份,
节约空间 - 函数调用需要出入栈的开销,耗费时间。典型的
用时间换空间
函数的定义、声明、调用
- 定义:确定函数名、返回值类型、形参、
实现函数体 - 调用:函数名(实参);本质是执行函数体的功能代码
- 声明:对函数名、返回值类型、形参类型进行提前声明,不会实现函数体
形参、实参、返回值
-
形参:定义函数的时候
()里面的参数为函数形参- 在定义函数的时候,形参不占空间。只有
调用函数的时候,系统才给形参开辟空间【入栈】- 假设若定义时就开辟空间,但是没有调用,浪费空间
- 若不管浪费空间的问题,定义时开辟,若同时多次调用会冲突
- 有些编译器会将
参数存入寄存器,不同编译器可以接参的寄存器和个数不一样,需要测试一下。寄存器个数不够,会继续入栈 - 本质就是局部变量,函数结束,形参会被释放【调用约定、平栈】
- 在定义函数的时候,形参不占空间。只有
-
实参:调用函数时,传递给函数的参数值,就是实参
- 实参传递给形参的方式只有单向传递,只是单向传递又分为:传值、传地址、传引用。
-
函数返回值:
若函数无返回值,默认为int
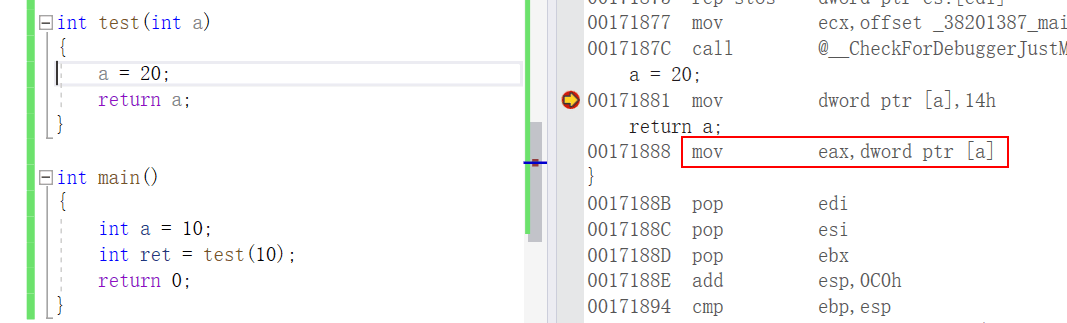
返回值小于4B,存入寄存器EAX中
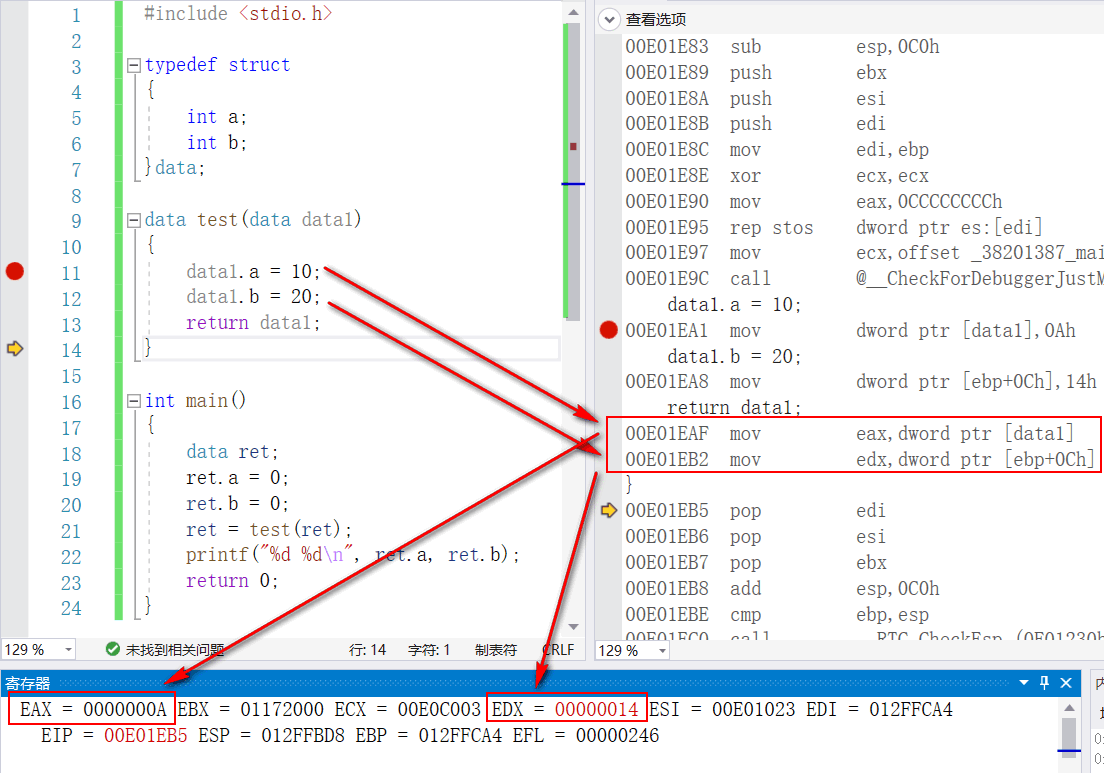
返回值大于4B小于8B,存入寄存器EAX和EDX中
返回值大于8B放入栈区的临时空间
将所有参数入栈后,最后将一个临时空间地址入栈,当被调函数返回前,会将返回值存入临时空间,将临时空间的地址存入寄存器EAX中返回给主调函数
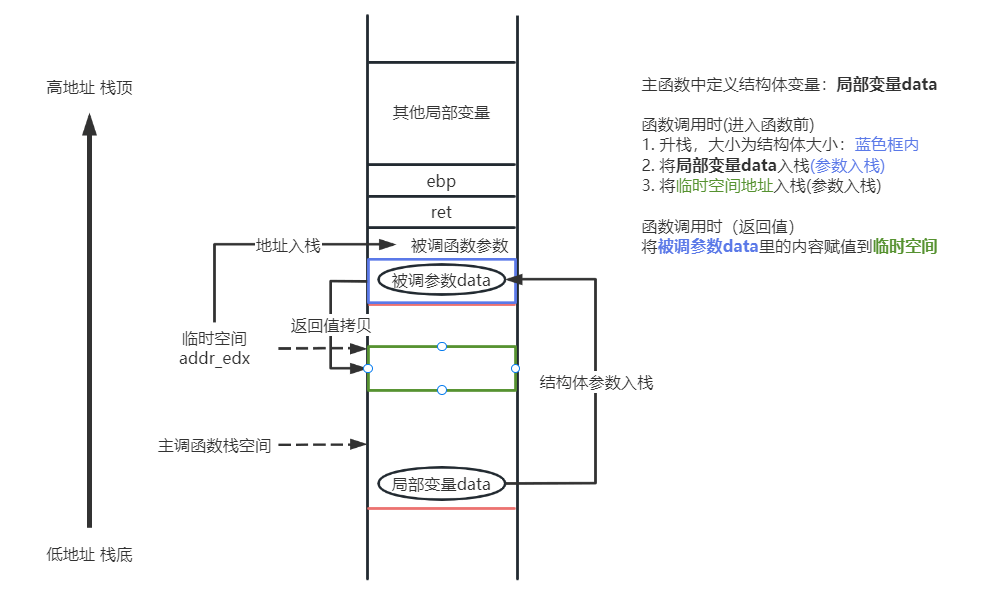
函数调用流程
Linux 是由shell解析器bash进程调起的main函数
形参类型
-
普通变量作为函数的形参,函数内部只能对外部变量进行读操作,不能修改外部变量值
-
数组作为函数的形参,那么函数内部可以操作外部数组的元素。eg:形参arr完全等价于外部的实参arr
-
二维数组做函数形参时,列下标不能省略。并且函数里面的二维数组求sizeof和函数外不一样。
10. 排序
冒泡排序
每次两两比较,将最大值交换到最后。
外层循环可以看成:需要找到 n-1 个最大值就可以排序成功,最后一个数不需要比较即为最小值。循环条件为:【i<n-1】
内层循环中,两两相比【j 与 j+1】,为了保证不越界,j 要小于n,并且j+1 也要小于n,取教小范围【j+1<n ---> j<n-1】。并且每次外层循环都能找到一个最大值,已找到的最大值不再需要比较,因此循环条件为:【j < n - 1 - i】
优化:内层循环若一次都没有交换,那么前面数据就是有序的,可以跳出排序了。
for(i = 0; i < n - 1; i++)
{
for(j = 0; j < n - i - 1; j++)
{
if(arr[j] > arr[j+1])
{
arr[j] = arr[j] ^ arr[j+1];
arr[j+1] = arr[j] ^ arr[j+1];
arr[j] = arr[j] ^ arr[j+1];
flag = 1;
}
}
if(0 == flag)
{
break;
}
}
选择排序
以 第i位 为假设最小值,遍历时比较并记录最小值的下标,若下标与 第i位 不同,则交换。
内层循环每次的记录值都是 i,并且每次都从 i的下一位 开始比较。
for(i = 0; i < n - 1; i++)
{
int tmp = 0, j = 0;
for(tmp = i, j = i + 1; j < n; j++)
{
if(arr[tmp] > arr[j])
tmp = j;
}
if(i != tmp)
{
arr[i] = arr[i] ^ arr[tmp];
arr[tmp] = arr[i] ^ arr[tmp];
arr[i] = arr[i] ^ arr[tmp];
}
}
11. 指针
大小端
- 低低高高为小端
低地址存低位,高地址存高位
物理地址通过MMU转化为虚拟地址
-
32位平台,地址编号的大小是4字节
-
64位平台,地址编号的大小是8字节
-
类型可以认为是为了区分内存大小
-
指针本质指的是地址编号的类型
-
指针类型变量都是4字节/8字节(32位/64位)
地址和指针的区别
地址:系统为内存的每一个字节分配的编号
指针:指的是地址编号的类型
指针变量:本质是变量,存储的是地址编号
指针根据类型的大小,可以从存储的地址编号开始访问
定义指针变量的步骤
- *修饰指针变量名
- 保存谁的地址就定义谁
- 从上往下整体替换
案例1:定义一个指针变量p,保存int data 的地址
int data = 100;
- *p
- int data
- int (*p)
- int *p
- p = &data
案例2:定义一个指针变量p,保存int arr[5] 的首地址
- *p
- int arr[5];
- int (*p)[5]; // 数组指针
案例3:定义一个指针变量p,保存int my_add(int, int)入口地址
- *p
- int my_add(int, int)
- int (*p)(int, int) //函数指针
指针变量的定义分析
在定义的时候,*的作用 是描述p为指针变量,变量名为p
int *p;
int data;
// 定义的时候,*描述p为指针变量,&data赋值给p,而不是*p
int *p = &data;
指针变量的初始化
-
初始化为合法的空间(较少使用)
int data;
int *p = &data; -
初始化为空
int *p = NULL;// 给p赋值,不是*p哦- #define NULL (void*)0 是0地址编号
- 只有当p指向合法地址空间时,才能使用
通过指针变量访问空间内容
*p == data == 100;
*p 取地址
mov eax, dword ptr[p]
mov ecx, dword ptr[eax]
在使用中:*p表示取p所保存地址编号对应空间的内容
指针变量相关类型
int data = 0;
int *p = &data;
- 指针变量自身的类型
- 将变量名去掉,剩下啥类型,自身就是啥类型。p自身类型是int*
- 仅为赋值时使用,判断类型是否匹配
- 指针变量指向的类型
- 将变量名以及离变量名最近的一个* 一起去掉,剩下什么就是指向什么类型。p指向的类型为int
- p保存了 data的地址 == p指向了 data == p指向类型就决定了p能保存指向类型定义的变量的地址
eg:p指向类型为int 就决定了 p能保存int定义的变量的地址。
指针变量的指向类型的作用
- 指向类型的大小 决定了 指针变量的取值宽度
- 指向类型的大小 决定了 指针变量+1的跨度
&和*的关系
int data = 0; // data的类型为int
&data;// 整个表达式的类型为int*
int *p; // p 的类型为int*
&p; // 整个表达式的类型为int**
对变量取地址的类型为变量的类型+*
int data = 0;
int *p = &data
p的类型为int*
*p整体的类型为int
对地址取内容的类型为地址类型基础上-*
在使用中,&和*一起出现,从右往左依次抵消。
void
- sizeof(void) == 1是编译器特点,C语言中规定是没有大小的
- void不能定义普通变量
系统无法根据data的void类型为其开辟空间,所以定义失败 - void*可以定义变量,是
万能指针 - void*是指针类型,本质是指针类型,32位平台任何指针都是4字节,64位平台是8字节
可以保存任何一级指针类型的地址 - +1会报错,不能跳,*p会报错,因为指向类型是void,void类型没有宽度和跨度
- 强制类型转换,才能+1或取*,但不改变p自身类型(void*)
- 多数作为函数参数使用,达到函数功能通用的目的
数组指针
int arr[5] = {1,2,3,4,5};
- arr数组名 代表的是数组首元素的地址,不是数组首地址
- arr + 1代表第1个元素地址,
- 数组名是符号常量,不能被赋值
arr++会报错 - 数组元素的指针变量,
int arr[5] = {100,200,300,400,500};
int *p = arr;
cout << *p++ << endl; // 100
// * 与 ++ 的运算符优先级相同,从右向左结合
//
cout << *(p++) << endl; // 200
cout << (*p)++ << endl; // 300
[] * ()区别
arr[1] ==> *(arr + 1) == *(1 + arr) == 1[arr]
[]是*()的缩写:[]左边的数写在+左边,[]里面的数写在+右边
&arr[0] == &*(arr + 0) == arr + 0 == arr
数组的中括号里可以为负数
int arr[5] = {100, 200, 300, 400, 500};
int* p = arr
cout << p[3] << endl;
// *(p+3) = 400
指针运算
指针减法含义:两个地址之间的元素个数
指向同一个数组的两个指针相减,不是单纯的地址相减,相减后除以一个单位的大小
指向同一个数组的两个不同类型指针不能相减,会报错,强转后可以
指向同一个数组的两个指针相加无意义
二维数组
二维数组的数组名代表首行的首地址,+1 跳过一行
数组指针代表数组的首地址,+1 跳过一个数组



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律