

kubernetes权威指南 第4版第三章节读书笔记
深入掌握Pod
1. kubelet只支持可以被API Server管理的Pod使用ConfigMap。 kubelet在本Node上通过 --manifest-url或--config自动创建的静态Pod将无 法引用ConfigMap
2. 在Pod对ConfigMap进行挂载(volumeMount)操作时,在容器 内部只能挂载为“目录”,无法挂载为“文件”。在挂载到容器内部后,在 目录下将包含ConfigMap定义的每个item,如果在该目录下原来还有其 他文件,则容器内的该目录将被挂载的ConfigMap覆盖
3. 将Pod信息注入为环境变量:

apiVersion: v1
kind: pod
metadata:
name: {{ template "module.name" . }}
namespace: {{ $.Release.Namespace }}
spec:
containers:
- name: {{ .Chart.Name }}
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldPath: matadata.podIP
4. 将容器资源信息注入为环 境变量
apiVersion: v1
kind: pod
metadata:
name: {{ template "module.name" . }}
namespace: {{ $.Release.Namespace }}
spec:
containers:
- name: {{ .Chart.Name }}
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}
resources:
requests:
memory: "32Mi"
cpu: "125m"
limits:
memory: "64Mi"
cpu: "250m"
env:
- name: MY_CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: test-container
resource: request.cpu
5. 通过Downward API将Pod的Label、Annotation列表通过 Volume挂载为容器中的一个文件
apiVersion: v1
kind: pod
metadata:
name: {{ template "module.name" . }}
namespace: {{ $.Release.Namespace }}
labels:
zone: us-est-coast
cluster: test-cluster1
rack: rack-22
annotations:
build: two
builder: john-doe
spec:
containers:
- name: {{ .Chart.Name }}
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}
resources:
requests:
memory: "32Mi"
cpu: "125m"
limits:
memory: "64Mi"
cpu: "250m"
volumeMounts:
- name: pidinfo
mountPath: /etc
readOnly: false
volumes:
- name: podinfo
downloadAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotations
这里要注意“volumes”字段中downwardAPI的特殊语法,通过items 的设置,系统会根据path的名称生成文件。根据上例的设置,系统将在 容器内生成/etc/labels和/etc/annotations两个文件。Downward API的价值.在某些集群中,集群中的每个节点都需要将自身的标识(ID)及进程绑定的IP地址等信息事先写入配置文件中,进程在启动时会读取这些 信息,然后将这些信息发布到某个类似服务注册中心的地方,以实现集 群节点的自动发现功能
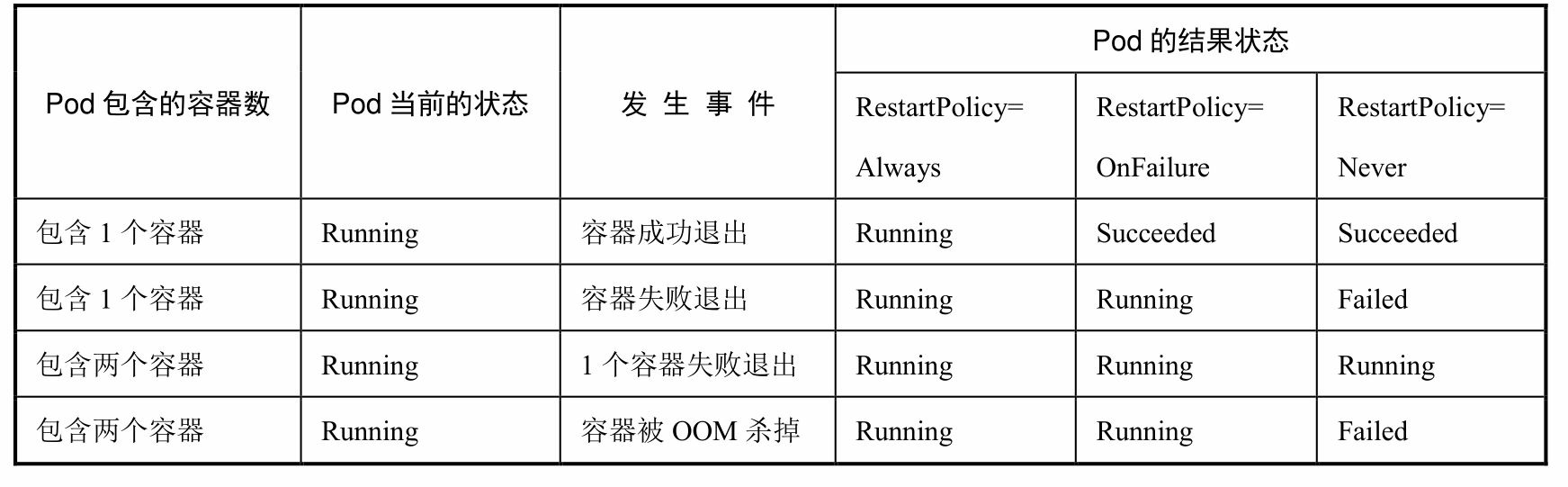
6. pod的生命周期:kubelet重启失效容器的时间间隔以sync-frequency乘以2n来计算,例 如1、2、4、8倍等,最长延时5min,并且在成功重启后的10min后重置该时间.
 7. NodeAffinity:Node亲和性调度 NodeAffinity意为Node亲和性的调度策略,是用于替换NodeSelector 的全新调度策略。目前有两种节点亲和性表达:◎ RequiredDuringSchedulingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上(功能与nodeSelector很像,但是使用 的是不同的语法),相当于硬限制 ◎ PreferredDuringSchedulingIgnoredDuringExecution:强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软 限制。多个优先级规则还可以设置权重(weight)值,以定义执行的先 后顺序。IgnoredDuringExecution的意思是:如果一个Pod所在的节点在Pod运 行期间标签发生了变更,不再符合该Pod的节点亲和性需求,则系统将 忽略Node上Label的变化,该Pod能继续在该节点运行
7. NodeAffinity:Node亲和性调度 NodeAffinity意为Node亲和性的调度策略,是用于替换NodeSelector 的全新调度策略。目前有两种节点亲和性表达:◎ RequiredDuringSchedulingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上(功能与nodeSelector很像,但是使用 的是不同的语法),相当于硬限制 ◎ PreferredDuringSchedulingIgnoredDuringExecution:强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软 限制。多个优先级规则还可以设置权重(weight)值,以定义执行的先 后顺序。IgnoredDuringExecution的意思是:如果一个Pod所在的节点在Pod运 行期间标签发生了变更,不再符合该Pod的节点亲和性需求,则系统将 忽略Node上Label的变化,该Pod能继续在该节点运行
8. PodAffinity:Pod亲和与互斥调度策略。Pod间的亲和与互斥从Kubernetes 1.4版本开始引入。这一功能让用 户从另一个角度来限制Pod所能运行的节点:根据在节点上正在运行的 Pod的标签而不是节点的标签进行判断和调度,要求对节点和Pod两个条 件进行匹配。这种规则可以描述为:如果在具有标签X的Node上运行了 一个或者多个符合条件Y的Pod,那么Pod应该(如果是互斥的情况,那么就变成拒绝)运行在这个Node上
9. Pod的互斥性调度
10. Taints和Tolerations(污点和容忍)Taint需要和Toleration配合使用,让Pod避开那些不合适的Node。在 Node上设置一个或多个Taint之后,除非Pod明确声明能够容忍这些污 点,否则无法在这些Node上运行。Toleration是Pod的属性,让Pod能够 (注意,只是能够,而非必须)运行在标注了Taint的Node上 可以用kubectl taint命令为Node设置Taint信息:kubectl taint nodes node1 key=value:NoSchedule 这个设置为node1加上了一个Taint。该Taint的键为key,值为 value,Taint的效果是NoSchedule。这意味着除非Pod明确声明可以容忍 这个Taint,否则就不会被调度到node1上.然后,需要在Pod上声明Toleration。下面的两个Toleration都被设置 为可以容忍(Tolerate)具有该Taint的Node,使得Pod能够被调度到 node1上
tolerations: - key: "key" operator: "Equal" value: value effect: "NoSchedule"
或者
tolerations: - key: "key" operator: "Exists" effect: "NoSchedule"
Pod的Toleration声明中的key和effect需要与Taint的设置保持一致, 并且满足以下条件之一。◎ operator的值是Exists(无须指定value)。◎ operator的值是Equal并且value相等。如果不指定operator,则默认值为Equal。另外,有如下两个特例。◎ 空的key配合Exists操作符能够匹配所有的键和值。◎ 空的effect匹配所有的effect。在上面的例子中,effect的取值为NoSchedule,还可以取值为 PreferNoSchedule,这个值的意思是优先,也可以算作NoSchedule的软 限制版本—一个Pod如果没有声明容忍这个Taint,则系统会尽量避免把 这个Pod调度到这一节点上,但不是强制的系统允许在同一个Node上设置多个Taint,也可以在Pod上设置多个 Toleration。Kubernetes调度器处理多个Taint和Toleration的逻辑顺序为: 首先列出节点中所有的Taint,然后忽略Pod的Toleration能够匹配的部 分,剩下的没有忽略的Taint就是对Pod的效果了。下面是几种特殊情◎ 如果在剩余的Taint中没有NoSchedule效果,但是有 PreferNoSchedule效果,则调度器会尝试不把这个Pod指派给这个节点。◎ 如果在剩余的Taint中存在effect=NoSchedule,则调度器不会把 该Pod调度到这一节点上。◎ 如果在剩余的Taint中有NoExecute效果,并且这个Pod已经在该节点上运行,则会被驱逐;如果没有在该节点上运行,则也不会再被调 度到该节点上。
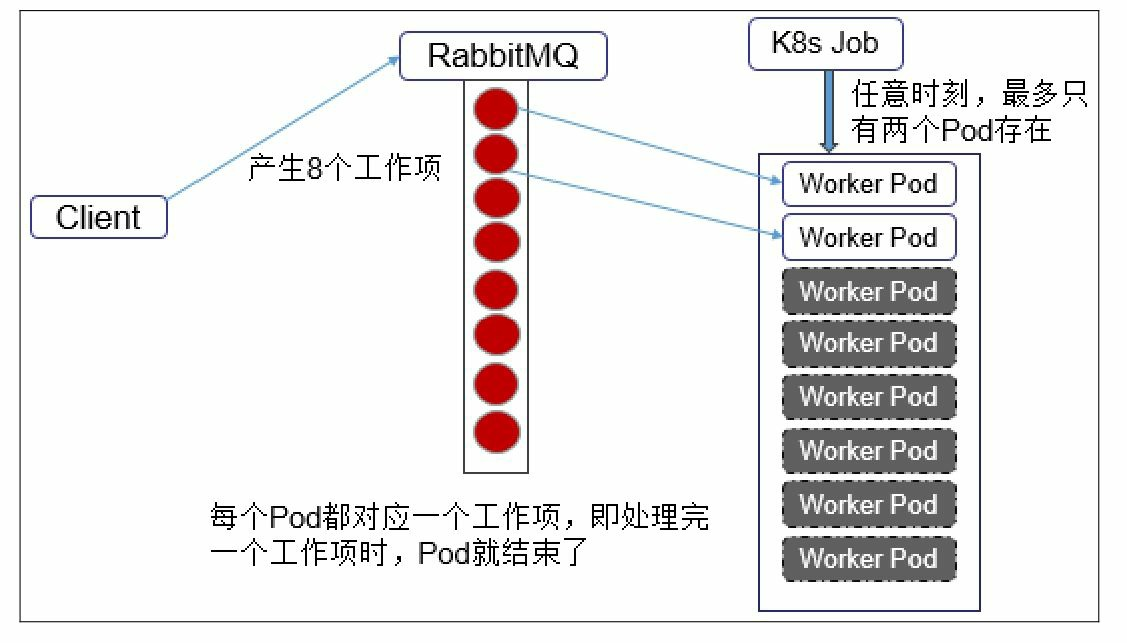
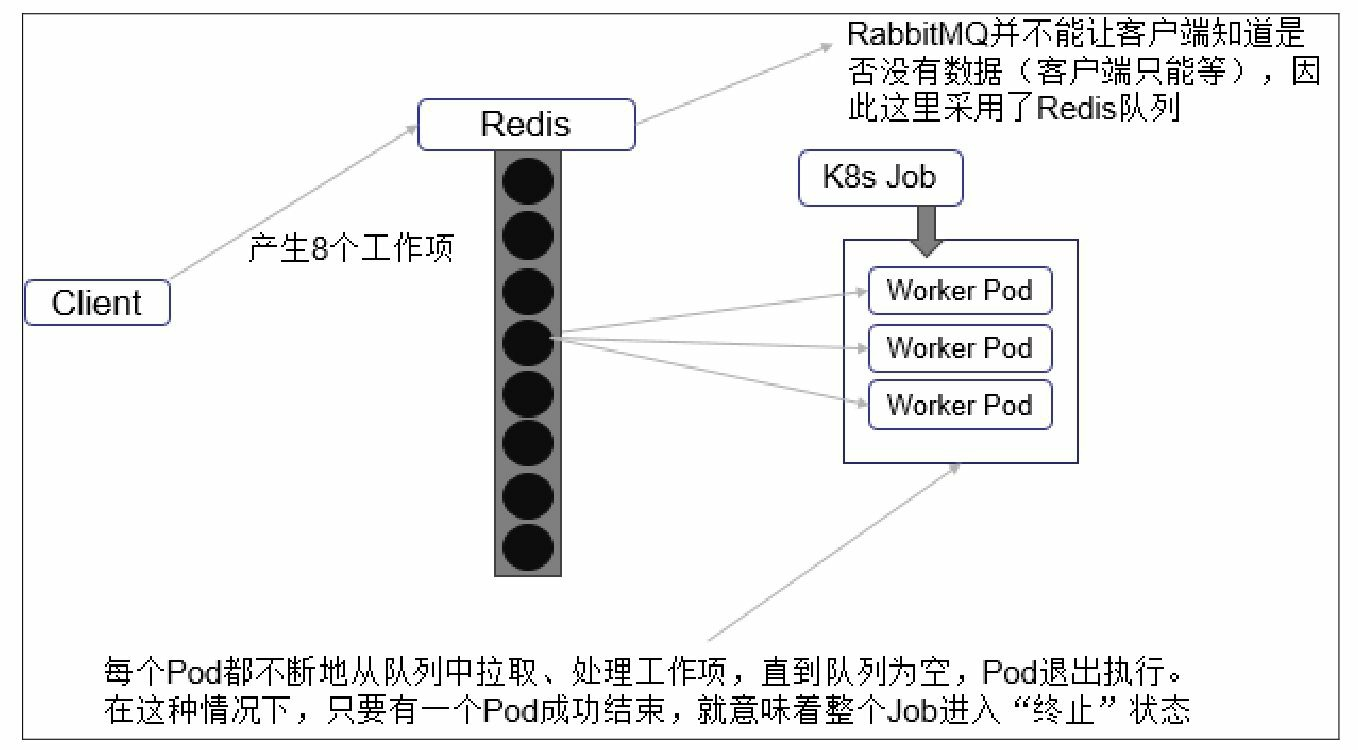
11. Pod Priority Preemption:Pod优先级调度。在Kubernetes 1.8版本之前,当集群的可用资源不足时,在用户提交 新的Pod创建请求后,该Pod会一直处于Pending状态,即使这个Pod是一 个很重要(很有身份)的Pod,也只能被动等待其他Pod被删除并释放资 源,才能有机会被调度成功。Kubernetes 1.8版本引入了基于Pod优先级 抢占(Pod Priority Preemption)的调度策略,此时Kubernetes会尝试释 放目标节点上低优先级的Pod,以腾出空间(资源)安置高优先级的 Pod,这种调度方式被称为“抢占式调度”。在Kubernetes 1.11版本中,该 特性升级为Beta版本,默认开启,在后继的Kubernetes 1.14版本中正式 Release。如何声明一个负载相对其他负载“更重要”?我们可以通过以下 几个维度来定义:◎ Priority,优先级;◎ QoS,服务质量等级;◎ 系统定义的其他度量指标。优先级抢占调度策略的核心行为分别是驱逐(Eviction)与抢占 (Preemption),这两种行为的使用场景不同,效果相同。Eviction是 kubelet进程的行为,即当一个Node发生资源不足(under resource pressure)的情况时,该节点上的kubelet进程会执行驱逐动作,此时 Kubelet会综合考虑Pod的优先级、资源申请量与实际使用量等信息来计 算哪些Pod需要被驱逐;当同样优先级的Pod需要被驱逐时,实际使用的 资源量超过申请量最大倍数的高耗能Pod会被首先驱逐。对于QoS等级 为“Best Effort”的Pod来说,由于没有定义资源申请(CPU/Memory Request),所以它们实际使用的资源可能非常大。Preemption则是 Scheduler执行的行为,当一个新的Pod因为资源无法满足而不能被调度 时,Scheduler可能(有权决定)选择驱逐部分低优先级的Pod实例来满 足此Pod的调度目标,这就是Preemption机制。需要注意的是,Scheduler可能会驱逐Node A上的一个Pod以满足 Node B上的一个新Pod的调度任务
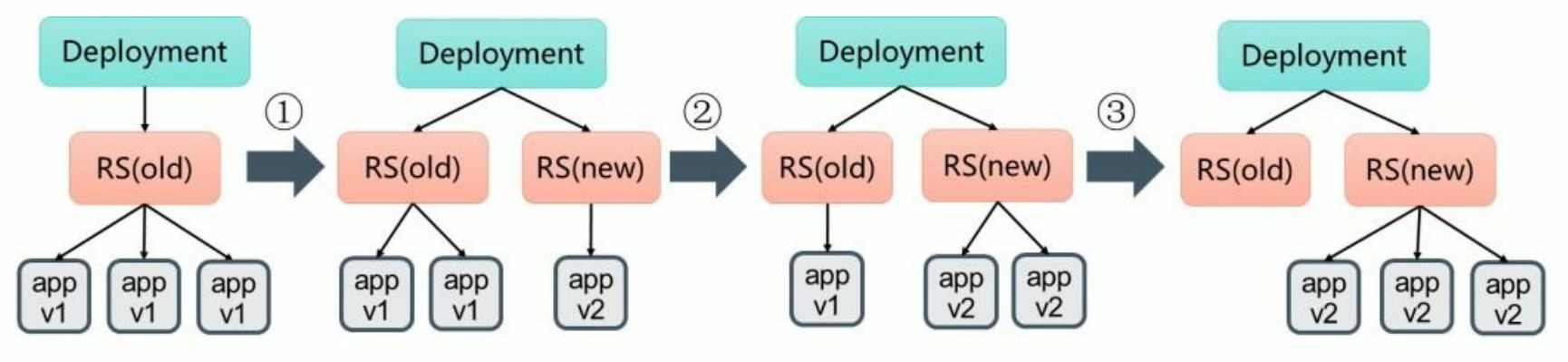
12. deployment更新。当更新Deployment时,系统创建了一个新的 ReplicaSet(nginx-deployment-3599678771),并将其副本数量扩展到 1,然后将旧的ReplicaSet缩减为2。之后,系统继续按照相同的更新策 略对新旧两个ReplicaSet进行逐个调整。最后,新的ReplicaSet运行了3个 新版本Pod副本,旧的ReplicaSet副本数量则缩减为0
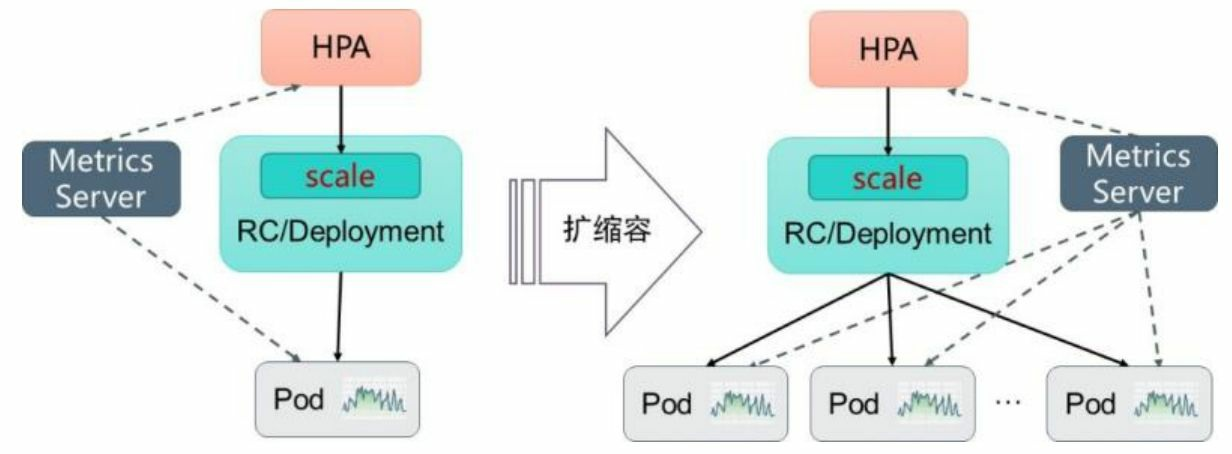
13. 自动扩缩容机制。Kubernetes中的某个Metrics Server(Heapster或自定义Metrics Server)持续采集所有Pod副本的指标数据。HPA控制器通过Metrics Server的API(Heapster的API或聚合API)获取这些数据,基于用户定义 的扩缩容规则进行计算,得到目标Pod副本数量。当目标Pod副本数量与 当前副本数量不同时,HPA控制器就向Pod的副本控制器 (Deployment、RC或ReplicaSet)发起scale操作,调整Pod的副本数量, 完成扩缩容操作
14. 指标的类型Master的kube-controller-manager服务持续监测目标Pod的某种性能 指标,以计算是否需要调整副本数量。目前Kubernetes支持的指标类型 如下:◎ Pod资源使用率:Pod级别的性能指标,通常是一个比率值,例 如CPU使用率。 ◎ Pod自定义指标:Pod级别的性能指标,通常是一个数值,例如接收的请数量。◎ Object自定义指标或外部自定义指标:通常是一个数值,需要 容器应用以某种方式提供,例如通过HTTP URL“/metrics”提供,或者使 用外部服务提供的指标采集URL。Kubernetes从1.11版本开始,弃用基于Heapster组件完成Pod的CPU 使用率采集的机制,全面转向基于Metrics Server完成数据采集。Metrics Server将采集到的Pod性能指标数据通过聚合API(Aggregated API)如 metrics.k8s.io、custom.metrics.k8s.io和external.metrics.k8s.io提供给HPA 控制器进行查询
15. 扩缩容算法详解 Autoscaler控制器从聚合API获取到Pod性能指标数据之后,基于下 面的算法计算出目标Pod副本数量,与当前运行的Pod副本数量进行对 比,决定是否需要进行扩缩容操作:

即当前副本数×(当前指标值/期望的指标值),将结果向上取整。当计算结果与1非常接近时,可以设置一个容忍度让系统不做扩缩 容操作。容忍度通过kube-controller-manager服务的启动参数--horizontal- pod-autoscaler-tolerance进行设置,默认值为0.1(即10%),表示基于上 述算法得到的结果在[-10%-+10%]区间内,即[0.9-1.1],控制器都不会进行扩缩容操作。也可以将期望指标值(desiredMetricValue)设置为指标的平均值类 型,例如targetAverageValue或targetAverageUtilization,此时当前指标值 (currentMetricValue)的算法为所有Pod副本当前指标值的总和除以Pod 副本数量得到的平均值。此外,存在几种Pod异常的情况,如下所述:◎ Pod正在被删除(设置了删除时间戳):将不会计入目标Pod副本数量。◎ Pod的当前指标值无法获得:本次探测不会将这个Pod纳入目标 Pod副本数量,后续的探测会被重新纳入计算范围。◎ 如果指标类型是CPU使用率,则对于正在启动但是还未达到 Ready状态的Pod,也暂时不会纳入目标副本数量范围。可以通过kube- controller-manager服务的启动参数--horizontal-pod-autoscaler-initial- readiness-delay设置首次探测Pod是否Ready的延时时间,默认值为30s。 另一个启动参数--horizontal-pod-autoscaler-cpuinitialization-period设置首 次采集Pod的CPU使用率的延时时间。如果在HorizontalPodAutoscaler中设置了多个指标,系统就会对每个 指标都执行上面的算法,在全部结果中以期望副本数的最大值为最终结 果。如果这些指标中的任意一个都无法转换为期望的副本数(例如无法 获取指标的值),系统就会跳过扩缩容操作。最后,在HPA控制器执行扩缩容操作之前,系统会记录扩缩容建议 信息(Scale Recommendation)。控制器会在操作时间窗口(时间范围 可以配置)中考虑所有的建议信息,并从中选择得分最高的建议。这个 值可通过kube-controller-manager服务的启动参数--horizontal-pod- autoscaler-downscale-stabilization-window进行配置,默认值为5min。这 个配置可以让系统更为平滑地进行缩容操作,从而消除短时间内指标值 快速波动产生的影响
16. HorizontalPodAutoscaler配置详解 。HorizontalPodAutoscaler资源对象处于Kubernetes的API 组“autoscaling”中,目前包括v1和v2两个版本。其中autoscaling/v1仅支 持基于CPU使用率的自动扩缩容,autoscaling/v2则用于支持基于任意指 标的自动扩缩容配置,包括基于资源使用率、Pod指标、其他指标等类 型的指标数据,当前版本为autoscaling/v2beta2
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscalee
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
◎ scaleTargetRef:目标作用对象,可以是Deployment、 ReplicationController或ReplicaSet。◎ targetCPUUtilizationPercentage:期望每个Pod的CPU使用率都 为50%,该使用率基于Pod设置的CPU Request值进行计算,例如该值为 200m,那么系统将维持Pod的实际CPU使用值为100m。◎ minReplicas和maxReplicas:Pod副本数量的最小值和最大值, 系统将在这个范围内进行自动扩缩容操作,并维持每个Pod的CPU使用 率为50%。
17. 基于autoscaling/v2beta2的HorizontalPodAutoscaler配置
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
◎ scaleTargetRef:目标作用对象,可以是Deployment、 ReplicationController或ReplicaSet。◎ minReplicas和maxReplicas:Pod副本数量的最小值和最大值, 系统将在这个范围内进行自动扩缩容操作,并维持每个Pod的CPU使用 率为50%。◎ metrics:目标指标值。在metrics中通过参数type定义指标的类 型;通过参数target定义相应的指标目标值,系统将在指标数据达到目标值时(考虑容忍度的区间,见前面算法部分的说明)触发扩缩容操作。可以将metrics中的type(指标类型)设置为以下三种,可以设置一 个或多个组合,如下所述:(1)Resource:基于资源的指标值,可以设置的资源为CPU和内存。(2)Pods:基于Pod的指标,系统将对全部Pod副本的指标值进行平均值计算。(3)Object:基于某种资源对象(如Ingress)的指标或应用系统的任意自定义指标。
metrics:
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
其中,设置Pod的指标名为packets-per-second,在目标指标平均值为1000时触发扩缩容操作。
18. 例子:设置指标的名称为requests-per-second,其值来源于 Ingress“main-route”,将目标值(value)设置为2000,即在Ingress的每 秒请求数量达到2000个时触发扩缩容操作:
metrics:
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: extensions/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 2k
例2: 设置指标的名称为http_requests,并且该资源对象具有标签“verb=GET”,在指标平均值达到500时触发扩缩容操作
metrics:
- type: Object
object:
metric:
name: 'http_requests'
selector: 'verb=GET'
target:
type: AverageValue
value: 500
还可以在同一个HorizontalPodAutoscaler资源对象中定义多个类型的 指标,系统将针对每种类型的指标都计算Pod副本的目标数量,以最大值为准进行扩缩容操作
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu:
target:
type: AverageUtilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second
targetAverageValue: 1k
- type: Object
object:
metric:
name: request-per-second
describedObject:
apiVersion: extensions/v1beta1
kind: Ingress
name: main-route
target:
kind: Value
value: 10k
从1.10版本开始,Kubernetes引入了对外部系统指标的支持。例 如,用户使用了公有云服务商提供的消息服务或外部负载均衡器,希望基于这些外部服务的性能指标(如消息服务的队列长度、负载均衡器的 QPS)对自己部署在Kubernetes中的服务进行自动扩缩容操作。这时, 就可以在metrics参数部分设置type为External来设置自定义指标,然后就 可以通过API“external.metrics.k8s.io”查询指标数据了。当然,这同样要 求自定义Metrics Server服务已正常工作
- type: External
external:
metric:
name: queue_message_ready
selector: "queue=worker_tasks"
target:
type: AverageValue
averageValue: 30
在使用外部服务的指标时,要安装、部署能够对接到Kubernetes HPA模型的监控系统,并且完全了解监控系统采集这些指标的机制,后 续的自动扩缩容操作才能完成

