

Kubernetes核心原理笔记
kubernetes权威指南阅读笔记
笔记来自kubernetes权威指南,如需更详细的教程还请阅读原书,笔记只记录相关重要知识点,其中也包含一些自己的总结,有异议可以留言交流
Kubernetes API Server原理分析:
1.Kubernetes API Server通过一个进程名为kube-apiserver的进程提供服务,默认进程在本机端口(--insecure-port)提供REST 服务,同时通过HTTPS安全端口(--secure-port=6443)来启动安全机制
2.如果只想对外提供部分REST服务,则可以在master或者其他任何节点通过运行kubectl proxy进程启动一个内部代理实现,支持--reject-paths、--accept=hosts限制访问路径和访问来源
3.Kubernetes API Server最主要的REST接口是资源对象的增、删、改、查,除此之外,它还提供了一类特殊的REST接口——Kubernetes Proxy API 接口,这类接口的作用是代理请求,即Kubernetes API Server把收到的REST请求转发到某个Node上的kubelet守护进程的REST端口上,由kubelet进程负责响应,部分接口列表:/api/v1/proxy/nodes/{name}/pods/ #列出指定节点内所有Pod信息 /api/v1/proxy/nodes/{name}/stats/ #列出指定节点物理资源统计信息 /api/v1/proxy/nodes/{name}/spec/ #列出指定节点的概要信息 /api/v1/proxy/nodes/{name}/run #在指定节点运行某个容器 /api/v1/proxy/nodes/{name}/metrics # 列出指定节点相关的Metics信息等还可以直接访问某个Pod里容器运行的服务...
4.集群功能模块之间的通信,Kubernetes API Server作为集群的核心,负责各功能模块之间的通信,集群内各功能模块通过API Server将信息写入etcd,需要这些数据时,又通过API Server提供的REST接口(GET/LIST/WATCH)来实现,从而实现各模块之间的信息交互
5.kubelet与API Server交互。每个Node节点上的kubelet每隔一个时间周期,就会调用一次API Server的REST接口报告自身状态,API Server收到这些信息后会更新到etcd中。此外kubelet也会通过API Server的WATCH接口监听Pod信息,如果监听到新的Pod副本被调度绑定到本几点,则执行Pod对应的容器的创建和启动逻辑,只有会详细更新此部分内容。删除和修改同理
6.API Server和kube-scheduler的交互。Scheduler通过API Server的Watch接口监听到新pod副本信息后,它会检索所以符合Pod要求的Node列表,开始执行Pod调度逻辑,调度成后将Pod绑定到目标节点
7.为了缓解集群各模块对API Server的访问压力,各功能模块都采用了缓存机制来缓存数据,各功能模块定时从API Server获取指定的资源对象信息(通过LIST及WATCH方法),然后将这些信息保存到本地缓存,功能模块在某些情况下不直接访问API Server,而是通过访问缓存数据间接访问API Server,后面会详细介绍
Controller Manager原理分析(重点)
1.Controller Manager作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)等的管理,当某个Node意外宕机时,Conroller Manager会及时发现此故障并执行自动化修复流程,确保集群始终处于预期的工作状态
2.Controller Manager包含: Replication Controller、Node Controller、Ingress Controller、ResourceQuto Controller、Namespace Controller、Service Controller、ServiceAccount Controller、Token Controller、Endpoint Controller等,每个Controller都是一种具体的控制流程,而Controller正式这些Controller的核心管理者
3.一般我们俗称的自动系统和智能系统通常都会被一个"操纵系统"的机构不断修正系统的工作状态。所以我们可以把每个Controller都理解为这样一个个"操纵系统",它们通过API Server提供的接口实时监控整个集群里的每个资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试着将系统状态从"现有状态"修正到"预期状态"。
a) Replication Controller(副本控制器)本节不讨论资源对象Replication Controller
1.Replication Controller的核心作用是确保任何时候集群中一个RC所关联的Pod副本数量保持预设值。如果发现Pod副本数量少于或者超过预期值,则会自动创建或减少Pod副本,知道符合条件的Pod副本数量达到预设值(注意:只有当Pod的重启策略是Always即RestartPolicy=Always),Replication Controller才会管理该Pod的操作。通常情况下Pod对象被设置成功创建后不会消失,唯一的例外是当Pod处于successed或failed状态的时间过长时该Pod会被系统自动回收,管理该Pod的副本控制器将在其他工作节点重新创建、运行该Pod副本
2.RC中的Pod模板就像模具,模具制作出来的东西一旦离开模具,它们之间就再没关系了。同样一旦Pod被创建完毕,无论模板如何变化,都不会影响已创建的Pod
3.Pod可以通过修改它的标签来实现脱离RC的管控,该方法可以用于将Pod从集群中千亿、数据修复等调试。对于被迁移的副本RC会自动创建一个副本替换
4.RC职责: 确保当前集群中有且仅有N个Pod实例,N是RC中定义的Pod副本数 当通过调整RC的spec.relicas属性值来实现系统扩容和收缩 通过实现RC中的Pod模板(主要是镜像版本)来实现系统的滚动升级
b) Node Controller
1.kubelet进程在启动时通过API Server注册自身的节点信息,并定时向API Server汇报状态信息。API Server接收到这些信息后,将这些信息更新到etcd中,etcd存储节点信息包含节点健康状况、节点资源、节点名称、节点地质信息、节点操作版本、Docker版本、kubelet版本。节点健康状况包含"就绪""未就绪""Unknow"三种
2.Node Controller通过API Server实时获取Node相关信息,实现管理和监控集群中的各个Node节点的相关控制功能
3.Node Controller核心工作流程如下:如果Controller Manager设置了"--cluster-cidr"参数---->则为每个Node配置"Spec.PodCIDR"--->逐个读取node信息,并和本地nodeStatusMap做比较--->没有收到节点信息或第一次收到节点信息,或在该处理过程中节点状态变成非"健康"状态(用Master节点的系统时间作为探测时间和节点状态变化时间) || 在指定时间内收到信的节点信息,且节点状态发生变化(用Master节点的系统时间作为探测时间和节点状态变化时间) || 在指定时间内收到新的节点信息,但节点状态没发生变化(用Master节点的系统时间作为探测时间,用上次节点信息中的节点状态变化时间作为该节点的状态变化时间) ---> 如果在某一段时间内没有收到节点状态信息,则设置节点状态未"未知" --- > 删除节点或同步节点信息
4.Controller Manger设置--cluster-cidr参数,是为每个没有设置Spec.PodCIDR的node节点生成一个CIDR地址,并用该CIDR地址设置节点的Spec.PodCIDR属性,这样做的目的是防止不同节点的CIDR地址发生冲突,这相当于每个节点的唯一标识符
5.逐个读取节点信息,多次尝试修改nodeStatusMap中的节点信息状态,将该节点和nodeStatusMap中保存的节点信息做比较。如果判断出kubelet发送的节点信息、第1次收到节点kubelet发送的节点信息或者在处理过程中节点状态变为非"健康"状态,则在nodeStatusMap中保存的节点信息,并用Node Controller所在节点的系统时间作为探测时间和节点状态变化时间。如果判断出在指定时间内收到新的节点信息,且节点状态发生变化,则在nodeStatusMap保存节点的状态信息。如果判断出在指定时间内收到新的节点信息,但节点状态没发生变化,则在nodeStatusMap中保存节点信息,并用Node Controller节点所在系统时间作为探测时间和节点状态变化时间,用上次节点信息中的节点状态变化时间作为该节点的状态变化时间。如果在某一段时间内(gracePeriod)没有收到节点状态信息,则设置节点状态为"未知",并通过API Server保存节点状态
6.逐个读取节点信息,如果节点状态为非"就绪"状态,则将节点加入待删除队列,否则将节点从该队列中删除。如果节点状态为非"就绪"状态,且系统指定了Cloud Provider,则Node Controller调用Cloud Provider查看节点,若发现节点故障,则删除etcd中的节点信息,并删除和该节点相关的Pod等资源信息
c) ResourceQuota Controller
1.ResourceQuota Controller(资源配额管理)确保了指定的资源对象在任何时候都不会超量占用系统物理资源,避免了某些业务进程的设计或实现导致整个系统运行崩溃,地整个集群的文档运行和稳定性有非常重要的作用
2.Kubernetes支持三个层次的资源配额管理: 容器级别,可以对CPU和Memory进行限制 Pod级别,可以对Pod内所以容器的可用资源进行限制 Namespace级别,为Namespace级别的资源限制包括:Pod数量、Replication Controller数量、Service数量、ResourceQuota数量、secret数量、可持有的PV数量
3.Kubernetes的资源配额管理是通过Admission Control(准入控制)来控制的,Admission Control当前提供了两种方式的配额约束,分别是LimitRanger与ReourceQuota,其中LimitRanger作用于Pod和Container上,而ResourceQuota则作用于Namespace上,限制一个Namespace里的各类资源的使用总额
4.如果在Pod定义中声明了LimitRanger,则用户通过API Server请求创建或修改资源时,Admission Controller会计算当前配额使用情况,如果不符合配额约束则会创建对象失败。对于定义了ResourceQuota的Namespace,ResourceQuota Controller组件负责定期统计和生成该Namespace下的各类对象资源的使用总量,以及改Namespace下所有Container实例所使用的资源量(目前包括CPU和内存),然后将这些统计结果写入etcd的resourceQuotaStatusStorage目录(resourceQuotas/status)中。随后这些信息被Admission Control使用,以确保相关namespace下的资源peie总量不会超过ResourceQuota
中设定的值
d) Namespace Controller
1.用户通过API Server可以创建新的Namespace并保存在etcd中,Namespace Controller定时通过API Server读取这些Namespace信息。如果Namespace被API标识为优雅删除(通过设置删除期限,即DeletionTimestamp属性被设置),则将该Namespace的状态设置成Terminating并保存etcd中。同时删除Namespace下的ServiceAccount、RC、Pod、Secret、PersistenVolume、ListRange、ResourceQuota和Event等资源对象
2.当Namespace状态被设置成Terminating后,有Admission Controller的NamespaceLifecycle插件来阻止为该Namespace创建新的资源。同时在Namespace Controller删除完该Namespace中的所有资源对象后,Namespace Controller对该Namespace执行finalize操作,删除Namespace的spec.finalizers。如果Namespace Controller观察到Namespace设置了删除期限,同时Namespace的spec.finalizers域值是空的,那么Namespace Controller将通过API Server删除该Namespace资源
e) Service Controller 和 Endpoint Controller
1.Endpoints表示一个Service对应的所有Pod副本的访问地址,而Endpoint Controller就是负责生成和维护所有Endpoints对象的控制器
2.Endpoint Controller监听了Service和对应的Pod副本的变化,它如果监听到Service被删除,则删除该Service同名的Endpoint对象,同理更新或者创建
3.Endpoints对象是被每个Node上的kube-proxy进程所使用的,kube-proxy进程获取每个Service的Endpoints,实现了Service的负载均衡功能,之后会有相关详解
4.Service Controller它是属于Kubernetes集群与外部的云平台之间的一个接口控制器,之后会详解
Scheduler原理分析(重要)
1.Kubernetes Scheduler在整个系统中承担的是"承上启下"的重要功能,承上是指它负责接收Controller Manger创建新的Pod,为其安排一个落脚的"家"(node节点),启下是指安置工作完成之后,目标Node上的kubelet服务进程接管后续工作
2.Kubernetes Scheduler具体作用是将待调度的Pod(API Server新创建、Controller Manager为补足副本而创建的Pod等)按照特定的调度算法和调度策略绑定到集群中某个合适的Node上,并将绑定信息写入etcd中,整个调度过程涉及三个对象:待调度Pod列表、可用Node列表、以及调度算法和调度策略。简单来说,就是通过调度算法调度为待调度Pod列表的每个Pod从Node列表中选择一个最合适的Node,随后目标节点上的kubelet通过API Server监听到Kubernetes Scheduler产生的Pod绑定事件,然后获取对应的Pod清单,下载Image镜像,并启动容器
3.Kubernetes Scheduler当前提供的默认调度流程分为如下两步:a:预选调度过程,即遍历所有目标Node,筛选出符合要求的候选节点,为此,Kubernetes内置了多种预选策略(xxx Predicates)供用户选择
b:确定最优节点,在第一步的基础上,采用优选策略(xxx Priority)计算出每个候选节点的积分,积分高者胜出
4.Kubernetes Scheduler的调度流程是通过插件方式加载的"调度算法提供者"(AlgorithmProvider)具体实现的,一个AlogorithmProvider其实就是包括了一组预选策略与一组优选策略的结构体
5.Kubernetes Scheduler中可用的预选策略包含:NoDiskConflict、PodFitsResources、PodSelectorMathes、PodFitsHost、CheckNodeLabelPresence、CheckServiceAffinity、和PodFitsPorts策略等。默认的AlgorithmProvider加载的预选策略Predicates包括:PodFitsPorts(PodFitsPorts)、PodFitsResources(PodFitsResources)、NoDiskConflict(NoDiskConflict)、MatchNodeSelector(PodSelectorMatches)、HostName(PodFitsHost),即每个节点只有通过以上五个默认预选策略后,才能初步被选中。
6.NoDiskConflict: 判断备选Pod的gcePresistentDisk或AWSElasticBlockStore和备选节点中已存在的Pod是否存在冲突,检测过程如下:a): 首先读取备选Pod的所以Volume的信息(即pod.spec.Volume)的信息
7.PodFitsResource:判断备选节点的资源是否满足备选Pod的需求,检测过程:计算备选Pod和几点已存在Pod的所有容器需求资源(内存和CPU)的总和;获得备选节点的状态信息,其中包含节点资源信息;如果备选Pod和节点中已存在的所有容器资源总和超过了备选节点拥有的资源,则返回false,表明备选节点不适合备选Pod,否则返回true,表明备选节点适合备选Pod
8.PodSelectorMatches:判断备选节点是否包含备选Pod的标签悬着器指定的标签。如果Pod没有指定spec.nodeSelector标签选择器,则返回true;否则根据备选节点是否含有备选pod的spec.nodeSelector所指定的所有标签,有则返回true,反正则返回false
9.PodFitsHost:判断备选Pod的spec.nodeName域指定的节点名称和备选节点的名称是否一致
10.CHeckNodeLabelpRresence:如果用户在配置文件中指定了该策略,则Scheduler会通过RegisterCustomFitPredicate方法注册该策略。该策略用于判断策略列出的标签在备选节点存在时,是否选择该节点: a):读取备选节点中的标签列表 b):如果策略配置的标签列表在备选节点的标签列表中,且策略配置的Presence为false,则返回false ,否则返回true; 如果策略配置的标签列表在备选节点的标签列表中不存在,Presence 的值为true, 则返回false, 否则返回true
11.CheckServiceAffinity:如果用户指定了该策略,则Scheduler会通过RegisterCustomFitPredicate方法注册该策略,该策略用于判断备选节点是否包含策略指定的标签,或包含和备选Pod在相同Service和Namespace下的Pod所在节点的标签列表。如果存在,则返回true,反之返回false
12.PodFitsPorts:判断备选Pod所用的端口列表中的端口是否在备选节点中已被占用,如果被占用,则返回false
13.Scheduler 中的优选策略包含: LeastRequestedPriority、CalculateNodeLabelPriority和BalancedResourceAllocation等,每个接单通过优选选择策略时都会算出一个得分,计算各项得分,最终选出分值自大的节点作为优选的结果(也就是调度算法的结果)
a):LeastRequestedPriority:该优选策略用于从备选节点列表中选出资源消耗最小的节点 1:计算出所以备选节点上运行的Pod和备选Pod的CPU占用量totalMilliCPU 2:计算出所有备选节点上运行的Pod和备选Pod的内存占用量totalMemory 3:计算每个节点的得分: NodeCPUCapacity为CPU计算能力,NodeMemoryCapacity为内存大小: score=int(((NodeCPUCapacity-totalMilliCPU )*10) / NodeCPUCapacity+((NodeMemoryCapacity-totalMemory )*10) / NodeMemoryCapacity) / 2)
13.CalculateNodeLabelPriority:如果用户指定了该策略,则scheduler会通过RegisterCustomPriorityFunction方法注册该策略
14.BalancedResouceAllocation:该优选策略用于从备选节点列表选出各项资源使用率最均衡的节点:1:计算所有备选节点上运行的Pod和备选Pod的CPU占用量totalMilliCPU 2: 计算出所有备选节点上运行的Pod和备选Pod的内存占用量totalMemory 3:计算每个节点的得分: score=int(10-math.Abs(totalMilliCPU/nodeCpuCapacity-totalMemory/nodeMemoryCapacity)*10)
Kubelet运行机制分析
1.定义:每个Node节点上都会启动一个kubelet服务进程,该进程用于处理节点下发到本节点的任务,管理Pod及Pod中的容器。每个kubelet进程会在API Server上注册节点自身信息,定期向Master节点汇报节点资源的使用情况
2.节点管理: kubelet可以通过启动参数 "--register-node"来决定是否想API Server注册自己。如果该参数为true,那么kubelet将试着通过API Server注册自己。当前每个kubelet被授予创建和修改任何节点的权限,kubelet通过启动参数"--node-status-update-frequency"设置每隔多长时间向API Server报告节点状态,默认为10s
3.Pod管理:kubelet通过以下自己方式获取自身Node上所运行的Pod清单 1:文件:kubelet启动参数--config指定的配置文件目录下的文件(默认为/etc/kubernetes/manifests/).通过--file-check-frequency设置检查文件目录的间隔时间,默认为20s 2:HTTP端点(URL):通过"--manifest-url"参数设置。通过--http-check-frequency设置检查该HTTP端点数据的时间间隔,默认为20s 3:API Server: kubelet通过API Server监听etcd目录,同步Pod列表
4.以非API Server方式创建的Pod都叫作Static Pod。kubelet将static pod的状态汇报给API Server,API Server为该Static Pod创建一个Mirror Pod和其相匹配。Mirror Pod的状态将真实反映Static Pod的状态。当Static Pod被删除时,与之对应的Mirror Pod也会被删除也会被删除;静态Pod是由kubelet进行管理的仅存于特定Node上的Pod。他们不能通过API Server管理,无法与ReplicationController、Deployment或者DaemonSet进行关联,并且kubelet也无法对他们进行健康检查。静态Pod总是由kubectl进行创建,并且总是在kubelet所在的Node上运行。注意静态Pod的数据是不会存在etcd的
5.kubelet通过API Server Client使用WATCH加LIST方式监听"/registry/nodes/$"获得当前节点的名称和"/registry/pods"目录,将获取的信息同步到本地缓存
kube-proxy运行机制分析
1.service在很多情况下是一个概念,而真正将Service的作用落实的是背后的kube-proxy服务进程
2.在Kubernetes集群的每一个node上都会运行一个kube-proxy服务进程,这个进程可以看作Service的透明代理兼负载均衡器,其核心功能是将到某个Service的访问请求转发到后端的多个Pod实例上。
3.对每一个TCP类型的Kubernetes Service,kube-proxy都会在本地的Node上建立一个SocketServer来负责接收请求,负责均匀发送到后端某个Pod的端口上,过程采用Round Robin算法,也可以通过修改Service的service.spec.sessionAffinity参数的值来实现会话保持特性的定向转发,如果设置为ClusterIP,则将来自同一个ClusterIP的请求都转发到同一个后端Pod
4.Service中的ClusterIP与NodePort等概念是kube-proxy服务通过Iptables(ipvs)的NAT转换实现的,kube-proxy在运行过程中动态创建Service相关的Iptables(ipvs)规则,这些规则实现了ClusterIP及NodePort的请求流量重定向到kube-proxy进程上对应服务的代理端口的功能。在Kubernetes集群内部,可以在任意节点发起对Service的访问
5.如果Service中定义了session保持,则kube-proxy接收请求时会从本地内存中查找是否存在来自该请求IP的affinityState对象,如果存在,且Session没有超时,则kube-proxy将请求转向改affinityState所指向的后端Pod。如果本地没有来自该请求IP的对象,记录请求的IP和指向的Endpoint。后面的请求就会“黏连”到这个创建好的affinityState对象上,这就实现了会话保持的功能
6.kube-proxy通过监听查询API Server中的Service与Endpoint的变化,为每个Service都创建一个"服务代理对象",并自动同步。
7.服务代理对象是kube-proxy程序内部的一种数据结构,它包含一个用于监听此服务请求的SocketServer,SocketServer的端口是随机选择的一个本地空闲端口
8.kube-proxy也创建了一个负载均衡器——LoadBalancer,LoadBalancer上保存了Service对应的后端Endpoint列表的动态转发路由表,儿具体的路由选择则取决于Round Robin负载均衡散发及Service的session保持这两个特性
9.kube-proxy针对变化的Service列表,kube-proxy会逐个处理,处理流程:如果该Service没有设置集群IP,则不作任何处理,否则获取该Service的所有端口定义列表;逐个读取服务端口 定义列表中的端口信息,根据端口名称、Service名称和Namespace判断本地是否已存在对应的服务代理对象,如果不存在则新建。如果存在并且Service端口被修改过,则先删除Iptables中和该Service相关的规则,关闭服务代理对象,然后走新建流程,即为该Service端口分配服务代理对象并为该Service创建相关的Iptables规则;更新负载均衡组件中对应Service的转发地址列表,对于新建的Service,确认转发时的会话保持策略;对于已经删除的Service则进行清理
集群安全机制
Authentication(认证)、Authorization(授权)、Admission Control、Secret和Service Account
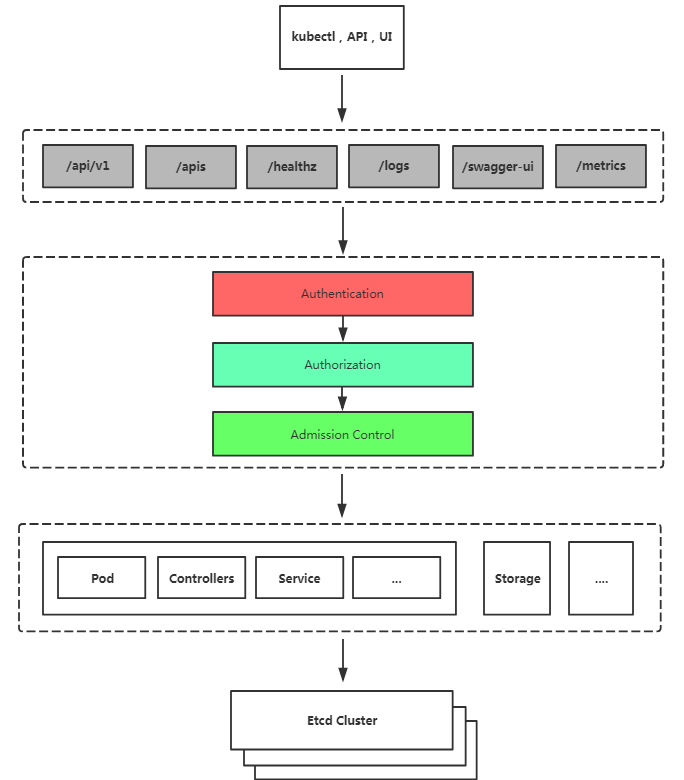
一、Authentication:
1.Kubernetes集群提供了3种级别的客户端身份认证:HTTPS证书认证:基于CA根证书签名的双向数字证书认证方式 HTTP Token认证:通过一个Token来识别合法用户 HTTP Base认证:通过用户名密码的方式认证
2.HTTPS认证原理:需要一个CA证书,CA是PKI系统中通信双方都信任的实体,被称为可信第三方(TTP)。CA作为可信第三方的重要条件之一就是CA的行为具有非否认性。CA通过证书证实他人的公钥信息,证书上有CA的签名。
3.HTTPS双向认证流程: a):HTTPS通信双方的服务器端向CA机构申请证书,CA机构为可信任的第三方。CA下发根证书、服务端证书及私钥给申请者 b):HTTPS通信双方的客户端向CA机构申请证书,CA下发根证书、客户端证书及私钥给申请者 c):客服端向服务器端发起请求,服务端下发服务端证书给客户端。客户端收到证书后,通过私钥解密证书,并利用服务器端证书中的公钥认证证书信息比较证书里的消息,例如域名和公钥与服务器刚刚发送的消息是否一致,如果一致则客户端认可这个服务器的合法身份 d):客户端发送客户端证书给服务端,服务端接收到证书后,通过私钥解密证书,获得客户端证书公钥,并用该公钥认证证书信息,确认客户端是否合法 e): 客户端通过随机密钥加密信息,并发送加密后的信息给服务端。服务端和客户端协商好加密方案后,客户端会产生一个随机的密钥,客户端通过协商好的加密方案,加密该随机密钥,并发送该随机密钥到服务器端 。服务器端接收到这个密钥后,双方通信的所有内容都通过该随机密钥加密
4.HTTP Token认证:HTTP Token是用一个很长的特殊编码方式的并且难以被模仿的字符串——Token来表妹客户身份的一种方式。Token是一个很复杂的字符串。当客户端发起API调用请求时,需要在HTTP Header里放入Token
5.HTTP Base认证:这种认证方式是把"用户名+冒号+密码"用BASE64算法进行编码后的字符串放在HTTP Request中的Header Authorization域里发送给服务端,服务端收到后镜像解码获取用户名密码,然后进行用户身份的鉴权过程
二、Authorization
1.当客户端发起API Server调用时,API Server内部要先进行用户认证,然后执行用户授权流程,通过“授权策略”来决定一个API调用是否合法。对合法用户进行收钱(Authorization)并且随后在用户访问时进行鉴权
2.API Server支持一下几种授权策略(通过API Server启动参数“--authorization-mode”设置):AlwaysDeny:表示拒绝所有请求 AlwaysAllow:允许所以请求(Kubernetes默认配置) ABAC:基于属性的访问控制,表示使用用户配置授权规则对用户请求进行匹配和控制 Webhook:通过调用外部REST服务对用户进行授权 RBAC:基于角色的访问控制
ABAC
1.ABAC授权模式讲解: 在API Server启用ABAC模式时,需要制定授权策略文件的路径和名字(--authorization-polic-file=SOME_FILE),授权策略文件里的每一行以一个Map类型的JSON对象进行设置
2.授权示例:
1.Alice 可以对所有资源做任何事情:
{"apiVersion": "abac.authorization.kubernetes.io/v1beta1", "kind": "Policy", "spec": {"user": "alice", "namespace": "*", "resource": "*", "apiGroup": "*"}}
2.Kubelet 可以读取任何pod:
{"apiVersion": "abac.authorization.kubernetes.io/v1beta1", "kind": "Policy", "spec": {"user": "kubelet", "namespace": "*", "resource": "pods", "readonly": true}}
3.Kubelet 可以读写事件:
{"apiVersion": "abac.authorization.kubernetes.io/v1beta1", "kind": "Policy", "spec": {"user": "kubelet", "namespace": "*", "resource": "events"}}
4.bob 可以在命名空间“projectCaribou”中读取 pod:
{"apiVersion": "abac.authorization.kubernetes.io/v1beta1", "kind": "Policy", "spec": {"user": "bob", "namespace": "projectCaribou", "resource": "pods", "readonly": true}}
5.任何人都可以对所有非资源路径进行只读请求
{"apiVersion": "abac.authorization.kubernetes.io/v1beta1", "kind": "Policy", "spec": {"group": "system:authenticated", "readonly": true, "nonResourcePath": "*"}}
{"apiVersion": "abac.authorization.kubernetes.io/v1beta1", "kind": "Policy", "spec": {"group": "system:unauthenticated", "readonly": true, "nonResourcePath": "*"}}
RBAC

1.基于角色的访问控制,在Kubernetes v1.5中引入,在v1.6版本成为kubeadm安装方式下的默认选项
2.RBAC引入了4个新的顶级资源对象:Role、ClusterRole、RoleBinding和ClusterRoleBinding。用户可以通过kubectl或者API调用创建这些对象
角色
•Role:授权特定命名空间的访问权限
•ClusterRole:授权所有命名空间的访问权限
角色绑定
•RoleBinding:将角色绑定到主体(即subject)
•ClusterRoleBinding:将集群角色绑定到主体
主体(subject)
•User:用户
•Group:用户组
•ServiceAccount:服务账号
使用RBAC授权对pod读取权限示例
创建角色
kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: namespace: developent name: pod-reader rules: - apiGroups: [""] resources: ["pods"] verbs: ["get", "watch", "list"] [root@k8s-master1 ~]# kubectl apply -f role-demo.yaml role.rbac.authorization.k8s.io/pod-reader created [root@k8s-master1 ~]# kubectl get role -n developent NAME AGE pod-reader 50s
角色绑定
kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: dev-read-pods namespace: developent subjects: - kind: User name: jane apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: pod-reader apiGroup: rbac.authorization.k8s.io
基于证书配置客户端身份认证
[root@k8s-master1 ~]# vim jane-csr.json { "CN": "jane", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing" } ] } [root@k8s-master1 ~]# cfssl gencert -ca=/opt/kubernetes/ssl/ca.pem -ca-key=/opt/kubernetes/ssl/ca-key.pem -config=/opt/kubernetes/ssl/ca-config.json -profile=kubernetes jane-csr.json | cfssljson -bare jane
创建kubeconfig文件
kubectl config set-cluster kubernetes \ --certificate-authority=/opt/kubernetes/ssl/ca.pem \ --embed-certs=true \ --server=https://192.168.0.130:6443 \ --kubeconfig=jane-kubeconfig kubectl config set-credentials jane \ --client-key=jane-key.pem \ --client-certificate=jane.pem \ --embed-certs=true \ --kubeconfig=jane-kubeconfig kubectl config set-context default \ --cluster=kubernetes \ --user=jane \ --kubeconfig=jane-kubeconfig kubectl config use-context default --kubeconfig=jane-kubeconfig
测试仅对developent命名空间查看pod权限
[root@k8s-master1 ~]# kubectl get pod -n developent NAME READY STATUS RESTARTS AGE nginx-7cdbd8cdc9-5dd7x 1/1 Running 0 16s nginx-7cdbd8cdc9-dthp7 1/1 Running 0 16s nginx-7cdbd8cdc9-lwzjf 1/1 Running 0 16s [root@k8s-master1 ~]# kubectl --kubeconfig=jane-kubeconfig get pod -n developent NAME READY STATUS RESTARTS AGE nginx-7cdbd8cdc9-5dd7x 1/1 Running 0 2m13s nginx-7cdbd8cdc9-dthp7 1/1 Running 0 2m13s nginx-7cdbd8cdc9-lwzjf 1/1 Running 0 2m13s [root@k8s-master1 ~]# kubectl --kubeconfig=jane-kubeconfig get pod Error from server (Forbidden): pods is forbidden: User "jane" cannot list resource "pods" in API group "" in the namespace "default"
使用RBAC授权UI权限示例
serviceAccount
当创建 pod 的时候,如果没有指定一个 service account,系统会自动在与该pod 相同的 namespace 下为其指派一个default service account。而pod和apiserver之间进行通信的账号,称为serviceAccountName。如下:
[root@k8s-master1 ~]# kubectl get pod NAME READY STATUS RESTARTS AGE nfs-client-provisioner-f69cd5cf-rfbdb 1/1 Running 0 4h31m web-0 1/1 Running 0 4h16m web-1 1/1 Running 0 4h16m [root@k8s-master1 ~]# kubectl get pod/web-0 -o yaml |grep "serviceAccountName" serviceAccountName: default [root@k8s-master1 ~]# kubectl describe pod web-0 Name: web-0 Namespace: default . . . . . Volumes: www: Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace) ClaimName: www-web-0 ReadOnly: false default-token-7vs6s: Type: Secret (a volume populated by a Secret) SecretName: default-token-7vs6s Optional: false
从上面可以看到每个Pod无论定义与否都会有个存储卷,这个存储卷为default-token-*** token令牌,这就是pod和serviceaccount认证信息。通过secret进行定义,由于认证信息属于敏感信息,所以需要保存在secret资源当中,并以存储卷的方式挂载到Pod当中。从而让Pod内运行的应用通过对应的secret中的信息来连接apiserver,并完成认证。每个 namespace 中都有一个默认的叫做 default 的 service account 资源。进行查看名称空间内的secret,也可以看到对应的default-token。让当前名称空间中所有的pod在连接apiserver时可以使用的预制认证信息,从而保证pod之间的通信。

