

栈空间分配和栈对齐访问
堆栈
参考文章:X86-64和ARM64用户栈的结构 (2) ---进程用户栈的初始化-大企鹅-51CTO博客
之前对于函数栈空间的理解就是栈空间由系统自动分配自动释放,并且局部变量等数据是存放在栈帧中,但是栈空间何时分配,栈空间大小等细节还是没有过多了解。下文将给大家详细介绍下堆栈。
栈在计算机中就是一块连续的存储区域(至少虚拟地址是连续的),只不过在这块连续的存储区域写入和删除数据按照先进后出的规则进行,在计算机中使用两个指针就可以完全描述一个栈,bp(base pointer)指向栈底,sp(stack pointer)指向栈顶。
栈的生命周期
栈的生命周期是和进程的生命周期保持一致的,进程在则栈在,进程亡则栈亡。因此,不妨从进程的生命周期探讨栈的生命周期。一个用户进程从无到开始运行,需要经过几个重要的步骤:
- Linux首先创建一个task_struct用于管理进程的方方面面。这里只是有了进程的“草图”,进程还没有被创建。
- 建立进程的虚拟地址空间,也即建立页表,建立虚拟地址到物理地址的映射,到这时一个用户进程所需的基本元素已经具备,一个进程被创建完成,在创建进程的过程中,进程的内核栈也被创建,内核栈不在本文的说明范围内。
- 接下来就需要可执行文件本身的参与,读取可执行文件头,解析文件头,文件头的前几个字节会指出当前文件是何种类型,如果是#!/bin/sh或 #!/bin/python 则该文件是脚本文件,有负责脚本文件的加载程序,本文只关注可执行文件。建立虚拟地址和可执行文件之间的映射。
- 初始化进程环境,其中比较重要的一项便是初始化用户栈
- 跳转到可执行文件的入口,执行可执行文件,运行到用户程序main函数,这其中主要右libc对栈进行管理。
- main()函数通过切换栈帧调用其它子函数,子函数也能通过切换栈帧调用其子函数。
- mian()函数返回,整个进程结束,释放栈占的内存,栈消失。
结合上面所述以及下图所示,栈的生命周期可以分为4个部分:
- Linux Kernel创建用户栈,为栈分配内存空间,处理传递给用户的参数,将参数压入栈中,压入指向参数的argv,计算出argc并将其压栈。
- libc的
_start函数将 Linux Kernel创建的栈和libc库函数接上头,由体系结构相关的汇编语言编写,核心作用是将栈顶地址赋值给SP,还将Linux设置的栈传递、参数传递以及一些库函数的函数指针传递给C语言编写的函数__libc_start_mian。_start函数只是起到一个过渡作用,根据CPU的体系结构将Linux Kernel初始化好的栈传递给后续的C语言编写的函数。 - libc的
__libc_start_mian函数是一个C语言写的函数,运行到该函数时用户栈的结构已经是编译器设计的了,同时由于_start函数已经设置好了SP的值,各种压栈、出找操作都在不断调整SP的值。该函数的功能主要有,main调用前的初始化工作;调用main;main函数返回后的清尾工作。 - 编译器设计main函数及其调用的子函数的栈。
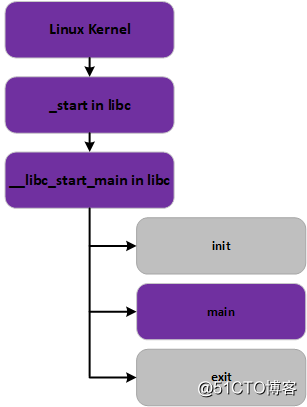
用户栈在系统中的位置
对于Linux内核而言,将整个内存空间划分为两个部分,Kernel Space 和User Space,前者用于支撑Linux Kenrel本身的运行所需空间,后者就是用于支持用户程序所需的运行空间。用户栈就是位于用户空间,一般位于用户空间的最高部分,向低地址处增长。
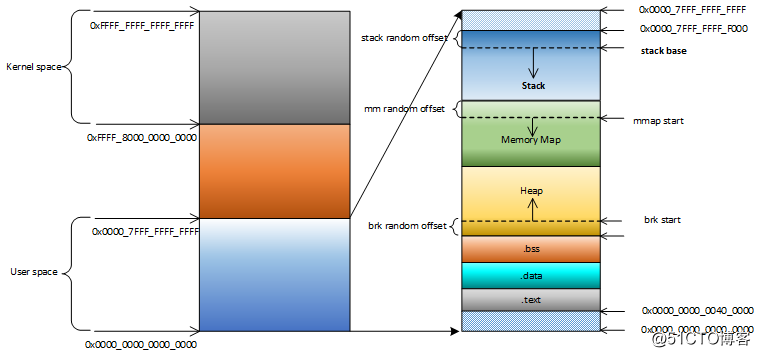
用户进程栈的初始化
在进程刚开始运行的时候,需要知道运行的环境和用户传递给进程的参数,因此Linux在用户进程运行前,将系统的环境变量和用户给的参数保存到用户虚拟地址空间的栈中,从栈基地址处开始存放。若排除栈基地址随机化的影响,在Linux64bit系统上用户栈的基地址是固定的:
在x86_64一般设置为0x0000_7FFF_FFFF_F000:
#define STACK_TOP_MAX TASK_SIZE_MAX
#define TASK_SIZE_MAX ((1UL << __VIRTUAL_MASK_SHIFT) - PAGE_SIZE)
#define __VIRTUAL_MASK_SHIFT 47在ARM64上是可以配置的,可以通过配置CONFIG_ARM64_VA_BITS的值决定栈的基地址:
#define STACK_TOP_MAX TASK_SIZE_64
#define TASK_SIZE_64 (UL(1) << VA_BITS)
#define VA_BITS (CONFIG_ARM64_VA_BITS)为了防止利用缓冲区溢出,Linux会对栈的基地址做随机化处理,在开启地址空间布局随机化(Address Space Layout Randomization,ASLR)后, 栈的基地址不是一个固定值。
在介绍Linux如何初始化用户程序栈之前有必要介绍一下虚拟内存区域(Virtual Memory Area, VMA)(还有一篇不错的中文博客), 因为栈也是通过vma管理的,在初始化栈之前会初始化一个用于管理栈的vma,在Linux上,vma用struct vm_area_struct描述,它描述的是一段连续的、具有相同访问属性的虚存空间,该虚存空间的大小为物理内存页面的整数倍, vm_area_struct 中比较重要的成员是vm_start和vm_end,它们分别保存了该虚存空间的首地址和末地址后第一个字节的地址,以字节为单位,所以虚存空间范围可以用[vm_start, vm_end)表示。
由于不同虚拟内存区域的属性不一样,所以一个进程的虚存空间需要多个vm_area_struct结构来描述。在vm_area_struct结构的数目较少的时候,各个vm_area_struct按照升序排序,以单链表的形式组织数据(通过vm_next指针指向下一个vm_area_struct结构)。但是当vm_area_struct结构的数据较多的时候,仍然采用链表组织的化,势必会影响到它的搜索速度。针对这个问题,Linux还使用了红黑树组织vm_area_struct,以提高其搜索速度。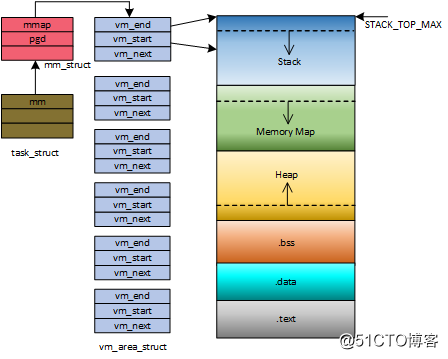
Linux 对栈的初始化在系统调用execve中完成,其主要目的有两个:
- 初始化用户栈
-
将传递给main()函数的参数压栈
用户栈的建立是伴随着可执行文件的加载建立的,Linux内核中使用linux_binprm管理加载的可执行文件,其定义如下:struct linux_binprm { char buf[BINPRM_BUF_SIZE];/*文件的头128字节,文件头*/ struct vm_area_struct *vma;/*用于存储环境变量和参数的空间*/ unsigned long vma_pages;/*vma中page的个数*/ struct mm_struct *mm; unsigned long p; /* current top of mem,vma管理的内存的顶端 */ unsigned int recursion_depth; /* only for search_binary_handler() */ struct file * file; struct cred *cred; /* new credentials */ int unsafe; /* how unsafe this exec is (mask of LSM_UNSAFE_*) */ unsigned int per_clear; /* bits to clear in current->personality */ int argc, envc; /*参数的数目和环境变量的数目*/ const char * filename; /* Name of binary as seen by procps */ const char * interp; /* Name of the binary really executed. Most of the time same as filename, but could be different for binfmt_{misc,script} */ unsigned interp_flags; unsigned interp_data; unsigned long loader, exec; struct rlimit rlim_stack; /* Saved RLIMIT_STACK used during exec. */ } __randomize_layout;
SYSCALL_DEFINE3(execve,
const char __user *, filename, //可执行文件
const char __user *const __user *, argv,//命令行的参数
const char __user *const __user *, envp)//环境变量
{
return do_execve(getname(filename), argv, envp);
}int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}static int do_execveat_common(int fd, struct filename *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp,
int flags)
{
char *pathbuf = NULL;
struct linux_binprm *bprm;
struct file *file;
struct files_struct *displaced;
int retval;
bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
bprm->interp = bprm->filename;
retval = bprm_mm_init(bprm); //建立栈的vma
bprm->argc = count(argv, MAX_ARG_STRINGS);//传给main()函数的argc
if ((retval = bprm->argc) < 0)
goto out;
bprm->envc = count(envp, MAX_ARG_STRINGS); //envc
if ((retval = bprm->envc) < 0)
goto out;
retval = prepare_binprm(bprm);
if (retval < 0)
goto out;
retval = copy_strings_kernel(1, &bprm->filename, bprm);//复制文件名到vma
if (retval < 0)
goto out;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);//复制环境变量到vma
if (retval < 0)
goto out;
retval = copy_strings(bprm->argc, argv, bprm);//复制参数到vma
if (retval < 0)
goto out;
would_dump(bprm, bprm->file);
retval = exec_binprm(bprm); //执行可执行文件
}通过对Linux代码的研究,用户进程栈的不是一步完成的,大致可以分为三步,一是需要linux建立一个vma用于管理用户栈,vma的建立主要是在bprm_mm_init中完成的,vma->vm_end设置为STACK_TOP_MAX,这时并没有栈随机化的参与,大小为一个PAGE_SIZE。
接着通过以下三个函数的调用分别把文件名,环境变量、参数复制到栈vma中,
retval = copy_strings_kernel(1, &bprm->filename, bprm);
if (retval < 0)
goto out;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);
if (retval < 0)
goto out;
retval = copy_strings(bprm->argc, argv, bprm);
if (retval < 0)
goto out;
第三步主要是在exec_binprm->search_binary_handler->load_elf_binary->setup_arg_pages中完成的。这一步会对栈的基地址做随机化,并把已经建立起来vma栈复制到基地址随机化后的栈。
第四步 在函数create_elf_tables中完成,则是分别把argc,指向参数的指针,指向环境变量的指针,elf_info压栈。
比较重要的一步是start_thread(regs, elf_entry, bprm->p);启动用户进程,regs是当前CPU中寄存器的值,elf_entry是用户程序的进入点, bprm->p是用户程序的栈指针,根据这3个参数就可以运行一个新的用户进程了。
start_thread的实现是体系结构相关的,在x86-64上:
static void
start_thread_common(struct pt_regs *regs, unsigned long new_ip,
unsigned long new_sp,
unsigned int _cs, unsigned int _ss, unsigned int _ds)
{
WARN_ON_ONCE(regs != current_pt_regs());
if (static_cpu_has(X86_BUG_NULL_SEG)) {
/* Loading zero below won't clear the base. */
loadsegment(fs, __USER_DS);
load_gs_index(__USER_DS);
}
loadsegment(fs, 0);
loadsegment(es, _ds);
loadsegment(ds, _ds);
load_gs_index(0);
regs->ip = new_ip;
regs->sp = new_sp;
regs->cs = _cs;
regs->ss = _ss;
regs->flags = X86_EFLAGS_IF;
force_iret();
}
void
start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp)
{
start_thread_common(regs, new_ip, new_sp,
__USER_CS, __USER_DS, 0);
}在ARM64上:
static inline void start_thread_common(struct pt_regs *regs, unsigned long pc)
{
memset(regs, 0, sizeof(*regs));
forget_syscall(regs);
regs->pc = pc;
}
static inline void start_thread(struct pt_regs *regs, unsigned long pc,
unsigned long sp)
{
start_thread_common(regs, pc);
regs->pstate = PSR_MODE_EL0t;
regs->sp = sp;
}
不管是ARM64还是X86-64,都是将新的PC和SP复制给当前的current,然后一路路返回到do_execveat_common,从系统调用中断返回,因为current进程的pc和sp都已经被改变了,会从新的程序入口点elf_entry开始执行,栈也会从bprm->p开始,进程的全新的起点就开始了。新的起点一般不是我们常写的main函数,而是__start,__start就是elf_entry,其会执行一些初始化工作,最后才调用到main()函数。
每个函数都有属于自己的一个函数栈帧,假设函数调用关系为:main->func1->func2,那么在执行到func2的时候,该进程的堆栈空间如下所示:
| main栈帧 |
| func1栈帧 |
| func2栈帧 |
栈帧一般包含如下信息:
- 函数的实参和局部变量
- 函数调用链接信息-调用函数时要保存某些CPU寄存器的值,如PC,以便返回时能继续执行下一条指令
下面我们通过汇编函数来简单的分析一下栈帧的内容以及栈帧是如何分配和回收的。
首先我们写一段简单的函数调用C代码,并将其编译成汇编文件,亦可通过objdump -dS 命令将可执行文件反汇编得到汇编指令
#include <stdio.h> int foo(int a, int b) { char x =1; int c = 0; c = a + b + x; return c; } int main() { int ret = 0; ret = foo(2, 3); return 0; }
foo: .LFB0: .file 1 "call_no_stack.c" .loc 1 4 0 .cfi_startproc pushq %rbp //rbp入栈 (rsp-8) .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp //rsp 赋值给 rbp,这里rsp并没有移动,可能是因为这里是最后一个函数调用,所以不需要移动rsp .cfi_def_cfa_register 6 movl %edi, -20(%rbp) //这里通过rbp来访问栈,将main函数中的实参2放入rbp-20内存 movl %esi, -24(%rbp) //这里表示栈空间分配了24字节,猜测:函数中的参数值从栈顶开始存储 .loc 1 5 0 movb $1, -5(%rbp) //局部变量x入栈,x占用1个字节,相当于x后入栈:栈的地址是向下减少的 .loc 1 6 0 movl $0, -4(%rbp) //局部变量c入栈,放在rbp-4处 .loc 1 7 0 movl -20(%rbp), %edx movl -24(%rbp), %eax addl %eax, %edx //相加操作 movsbl -5(%rbp), %eax addl %edx, %eax movl %eax, -4(%rbp) .loc 1 8 0 movl -4(%rbp), %eax //将c变量的结果保存到eax寄存器,以便函数返回 .loc 1 9 0 popq %rbp //将堆栈pop,此时栈顶保存着调用函数的rbp值,将栈顶元素赋予rbp寄存器(恢复rbp寄存器) .cfi_def_cfa 7, 8 ret //跳转回上一层处继续执行 .cfi_endproc .LFE0: .size foo, .-foo .globl main .type main, @function main: .LFB1: .loc 1 12 0 .cfi_startproc pushq %rbp //rbp:64位寄存器——指向栈底,将rbp寄存器内的值入栈-pushq操作会改变rsp的值 .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp //rsp:64位堆栈指针寄存器——指向栈顶,将rsp值存入rbp寄存器内 .cfi_def_cfa_register 6 subq $16, %rsp //rsp-16,这里讲栈顶指针向下移动16字节,相当于为main函数预留了16字节的栈空间-保存局部变量包括实参 .loc 1 13 0 movl $0, -4(%rbp) //对应局部变量ret = 0 .loc 1 14 0 movl $3, %esi //这里直接将实参存入esi寄存器而不是放入堆栈,可加快访问速度 movl $2, %edi call foo //调用foo函数:call指令有另个作用:1,将call指令的下一条指令入栈-并改变rsp 2,修改程序计数器eip,跳转到foo函数的开头执行 movl %eax, -4(%rbp) //eax寄存器保存着返回值,这里将eax赋值给rbp-4的位置,也就是ret .loc 1 15 0 movl $0, %eax .loc 1 16 0 leave //leave指令是函数开头的pushq %rbp和movq %rsp,%rbp的逆操作,
//有两个作用:1,把rbp赋值给rsp 2,然后把该函数栈栈顶保存的rbp值恢复到rbp寄存器中,同时rsp+4(第二部的操作相当于pop栈顶元素) .cfi_def_cfa 7, 8 ret //现在栈顶元素保存的是下一条执行的指令,ret的作用就是pop栈顶元素,并将栈顶元素赋值给程序计数器bip,然后程序跳转回bip所在地址继续执行 .cfi_endproc .LFE1: .size main, .-main
上述汇编代码可以用下图较为直观的展示:

可以看出:编译器生成汇编代码时,在当前函数开头,添加对应的对sp/esp/rsp(对应16/32/64位堆栈指针寄存器)的值减去所需堆栈内存大小,即对该函数分配(其实是预留)了堆栈内存。另外需要注意的是,在调用链的最后一层,即后续没有调用其他函数,那么堆栈指针是不会移动(估计和编译器实现有关)。上述main函数栈帧中,有这么一句:subq $16, %rsp,这个操作直接将栈指针往下移了16个字节,这就是在为堆栈分配空间以保存局部变量和实参。大家可以试一下在函数内分配一个数组,看看生成的汇编有什么变化。
栈空间对齐
这一部分引用相关文章:https://www.cnblogs.com/reload/p/3159053.html https://www.cnblogs.com/tcctw/p/11333743.html
栈的字节对齐,实际是指栈顶指针必须须是16字节的整数倍。栈对齐帮助在尽可能少的内存访问周期内读取数据,不对齐堆栈指针可能导致严重的性能下降。
上文我们说,即使数据没有对齐,我们的程序也是可以执行的,只是效率有点低而已,但是某些型号的Intel和AMD处理器对于有些实现多媒体操作的SSE指令,如果数据没有对齐的话,就无法正确执行。这些指令对16字节内存进行操作,在SSE单元和内存之间传送数据的指令要求内存地址必须是16的倍数。
因此,任何针对x86_64处理器的编译器和运行时系统都必须保证分配用来保存可能会被SSE寄存器读或写的数据结构的内存,都必须是16字节对齐的,这就形成了一种标准:
- 任何内存分配函数(alloca, malloc, calloc或realloc)生成的块起始地址都必须是16的倍数。
- 大多数函数的栈帧的边界都必须是16直接的倍数。
如上,在运行时栈中,不仅传递的参数和局部变量要满足字节对齐,我们的栈指针(%rsp)也必须是16的倍数
