
Hadoop 2.0中的日志收集以及配置方法
Hadoop中的日志包含三个部分,Application Master产生的运行日志和Container的日志。
一、ApplicationMaster产生的作业运行日志
Application Master产生的日志信息详细记录了Map Reduce job的启动时间,运行时间,用了多少个Mapper,多少个Reducer,Counter等等信息。MapReduce作业中的Application Master是运行在container中的。
默认情况下,Application Master产生的日志信息保存在HDFS上的特定的路径下,由以下几个参数来决定。
yarn.app.mapreduce.am.staging-dir : 默认为/tmp/hadoop-yarn/staging
mapreduce.jobhistory.done-dir : 存放已经结束的MR job的日志,默认为${yarn.app.mapreduce.am.staging-dir}/history/done
mapreduce.jobhistory.intermediate-done-dir : 存放正在运行中的MR job的日志,默认为${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate
到达HDFS目录下查看后发现,每个MR job都包含两个文件,一个是.jobhist结尾的文件,一个conf.xml

打开一个jhist查看,前半部分是avsc文件,描述了数据文件的结构,例如包含了什么字段,每个字段的数据类型以及possible value.
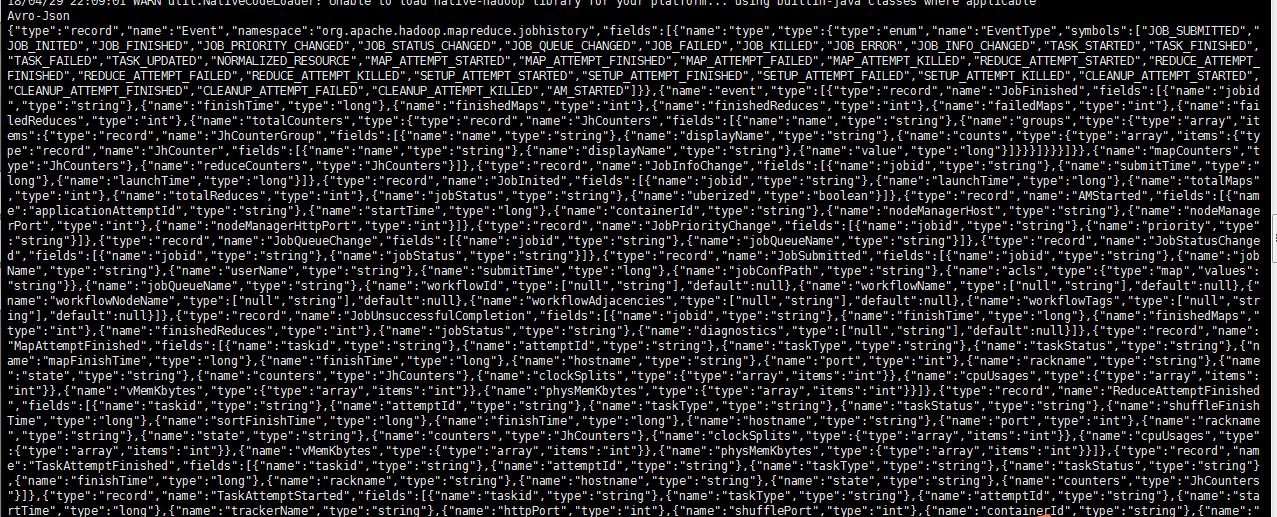
后面的部分则是json格式的数据,描述了MapReduce Job的运行状态和日志信息。

打开conf.xml可以发现,这个xml文件中包含了这个MapReduce job的参数。

二、Container日志
Container日志存放在每个NodeManager的本地磁盘上,存放位置由参数 yarn.nodemanager.log-dirs 决定,默认是$HADOOP_HOME/logs/userlogs下。这里包含了每一个application的log.

每一个以application命名的文件夹下,包含三个container的文件夹,以0000001结尾的文件夹下的文件就是ApplicationMaster的运行日志。

每个container文件夹下都包含三个文件,syserr,sysout, syslog

三、日志聚集功能
因为container的运行日志保存在每个NodeManager的本地磁盘下,不方便管理,可以启用日志聚集功能,打开该功能后,container的日志会被上传到HDFS某个目录下,并将syserr,sysout和syslog合并成一个文件,可以通过jobhistory server来查看,在没有启用日志聚集的功能时,在jobhistory server的Web UI里是没办法查看某个Map或者Reduce的日志的。
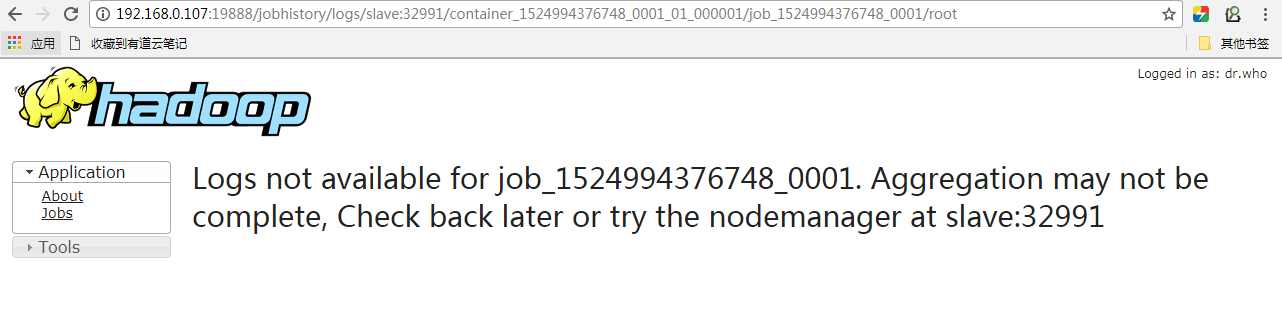
并且用"yarn logs -applicationId xxxx" 命令尝试输出yarn的log,log是没办法显示的。
在每个NodeManager的yarn-site.xml中配置以下参数。
1.yarn.log-aggregation-enable
是否启用日志聚集功能,默认值为false
2.yarn.log-aggregation.retain-seconds
在HDFS上聚集的日志最多保存多长时间,默认值为-1,-1的意思是不删除?
3.yarn.log-aggregation.retain-check-interval-seconds
隔多长时间查看聚集的日志并删除已经超过时间的日志,默认值为-1。如果设置成0或者一个负数,则这个值会被计算成log保留时间的十分之一。
4.yarn.nodemanager.remote-app-log-dir
日志被转移到的HDFS路径,默认值为/tmp/logs
5.yarn.nodemanager.remote-app-log-dir-suffix
日志被转移到的HDFS路径的子目录,默认为logs, 所以默认情况下日志会被存放在${yarn.nodemanager.remote-app-log-dir}/${user}/logs下。
其他参数可以参考https://hadoop.apache.org/docs/r2.4.1/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
接下来我们来验证一下,如果yarn.log-aggregation.retain-seconds设置成-1,也就是默认值,会不会进行日志聚集呢?
此时我在ResourceManager和NodeManager的yarn-site.xml都加入了以下的参数。
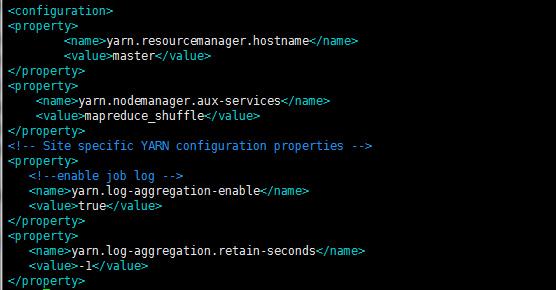
接下来重启yarn,并且跑一个MapReduce Job试试。
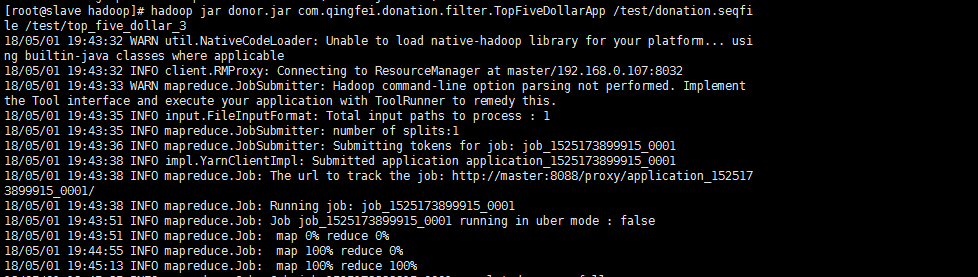
此时我们可以在jobhistory server中查看到这个job的log.
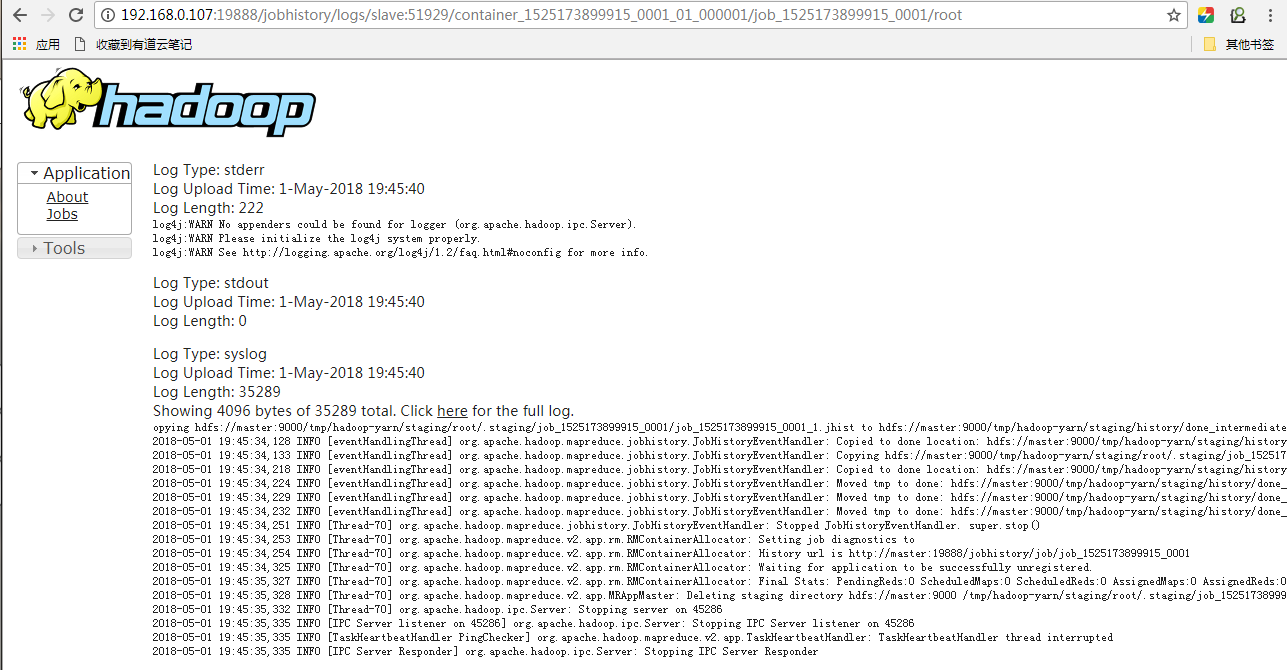
过十分钟左右再来查看,log还在,并且查看HDFS路径/tmp/logs/root/logs,所有的log文件都在此处。

参考文章:
https://blog.csdn.net/u011414200/article/details/50338073

 浙公网安备 33010602011771号
浙公网安备 33010602011771号