为金融场景而生的数据类型:Numeric
笔者曾做过数据库 Data Type 相关的设计和从 0 到 1 的源码实现,对 Numeric(与 Decimal 等价,都是标准 SQL 的一部分), Datetime, Timestamp, varchar … 等数据类型的设计、源码实现及在内存中计算原理有比较深的理解。
本篇基于 PostgreSQL 源码,解析 PostgreSQL 中 Numeric 类型的内存计算结构和磁盘存储结构。
c 源码 :https://github.com/postgres/postgres/blob/master/src/backend/utils/adt/numeric.c
头文件:https://github.com/postgres/postgres/blob/master/src/include/utils/numeric.h
精度的要求
在编程的过程中,大家可能对内置的 4 字节 float 和 8 字节 doulbe 类型比较熟悉,进行加减乘除运算。虽然浮点数是通过科学计数法来存储,但在二进制和十进制互相转换机制中,对一部分二进制数,其精度是有缺失的。
对于类似金融场景,动辄存储巨大的数值,以及对数据精度的高要求,哪怕再小的精度损失都是不可接受的。市面上各式各样的数据库基本都包含 Numeric 类型,通过字符串来精确存储每一位数,做到浮点数都做不到的精确计算。
Numeric 语法简介
NUMERIC(precision, scale)
-
precision:numeric 中全部数字个数的总和
-
scale:小数点后面的数字个数
例如:12.345,那么 precision 是 5、scale 是 3。
注意事项:
-
所有的整数都可以看成 scale 为 0 的 numeric;
-
precision 必须为正数,scale 可以为 0 或者正数;
-
numeric(precision) 语法,默认的 scale 是 0;
-
语法中不带任何参数,则任意 precision 和 scale 的值都可以被存储,只要不超过 precision 的最大值;
-
只要 numeric 中声明了 scale,则输入的值都要强制的去匹配这个 scale(即进行 round 操作,round 为四舍五入);
-
如果输入的 scale 数值溢出,则报错。
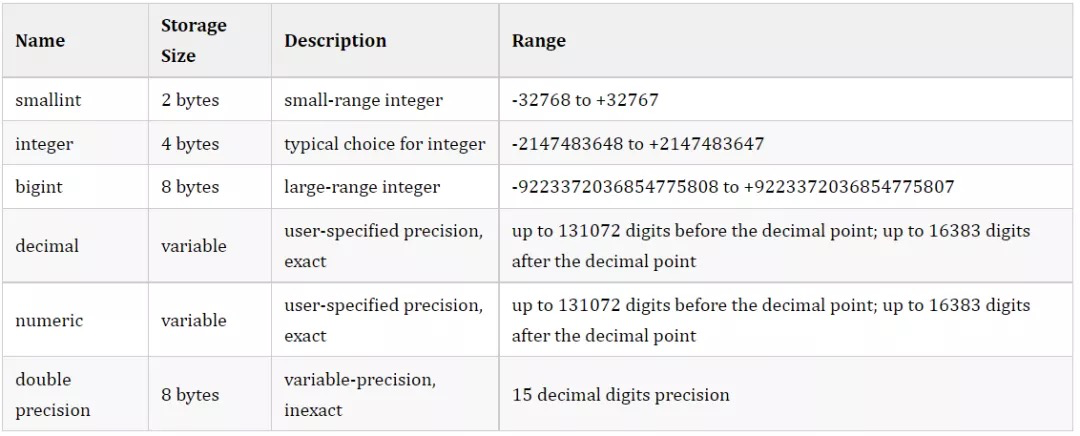
不指定精度的情况时各数值类型的取值范围【常见】:
Numeric 特殊值
除了正常的数值之外,numeric 还支持特殊的值:NaN( meaning "not-a-number")。当要将其当做常量用于 SQL 中时,需要打上引号,例如:
UPDATE table SET x = 'NaN'
SQL 中 Numeric 数据流向
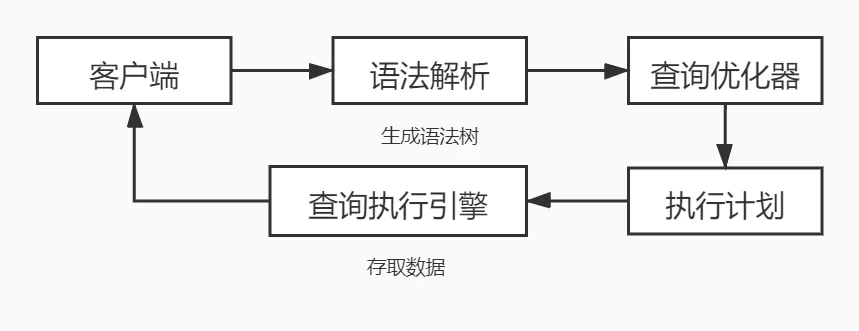
我们知道,一条 SQL 在数据库中的执行流程大致为:
CREATE TABLE test (
name VARCHAR(100) NOT NULL,
price NUMERIC(5,2)
);
INSERT INTO test (name, price)
VALUES ('Phone',500.215),
('Tablet',500.214);
以上述示例两条 SQL 为例,先建一张 test 表,并插入数据。这里我们关注写入的 Numeric 数字在内存中是如何表示,定义的 NUMERIC(5,2) 对应的数据结构在内存中如何表示。写入的数据在落入磁盘之后,其存储结构又是什么样的。
这里,数据在内存中的存储结构和落盘时的存储结构是不一样的,最终落盘时需要去掉内存中所占用的无效字节的。比如,varchar(100),假如在内存中分配 100 个字节,而实际只写入 “abc” 三个字节,那么它所分配的内存是 100 个字节,而落盘时没有用到的 97 个字节是要去掉的,最后 3 个字节写入磁盘时,还要做数据压缩。大家可以设想一下,如果内存中的存储结构不做任何处理直接写入到磁盘,如果数据量非常大,那会多浪费磁盘空间!
Numeric 磁盘存储结构解析
结构体 NumericData 是最终落到磁盘上的结构,如下,可以看到 NumericData 包含了 NumericLong 和 NumericShort 的 union 字段:
struct NumericLong
{
uint16 n_sign_dscale; /* Sign + display scale */
int16 n_weight; /* Weight of 1st digit */
NumericDigit n_data[FLEXIBLE_ARRAY_MEMBER]; /* Digits */
};
struct NumericShort
{
uint16 n_header; /* Sign + display scale + weight */
NumericDigit n_data[FLEXIBLE_ARRAY_MEMBER]; /* Digits */
};
union NumericChoice
{
uint16 n_header; /* Header word */
struct NumericLong n_long; /* Long form (4-byte header) */
struct NumericShort n_short; /* Short form (2-byte header) */
};
struct NumericData
{
int32 vl_len_; /* varlena header (do not touch directly!) */
union NumericChoice choice; /* choice of format */
};
结构体 NumericLong
struct NumericLong
{
uint16 n_sign_dscale; /* Sign + display scale */
int16 n_weight; /* Weight of 1st digit */
NumericDigit n_data[FLEXIBLE_ARRAY_MEMBER]; /* Digits */
};
**uint16 n_sign_dscale **:第一个字节中高两位 bit 用于保存正负号。
若为 0x0000:则符号位正
若为 0x4000:则符号位负
若为 0xC000:则为 NaN
剩余的 14 个 bit 用来保存 display scale(终端界面可显示的范围)
int16 n_weight :保存权值。这里要解释下权值在这里的含义。在这里 numeric 是用一组 int16 数组表示的,每一个元素用 int16 表示 4 位数字,也就是最大保存 9999。那么基数 base 值就是 10000。这里的权值的 base 值就是 10000(10 进制的权值 base 值是 10,二进制是 2)。
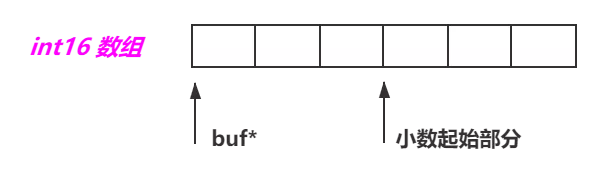
**NumericDigit n_data[FLEXIBLE_ARRAY_MEMBER] **:动态数组(也有叫柔性数组的,在这里统一称动态数组吧),是 C99 之后添加的一个特性。这个特性是在这个结构体中,动态数组并不占用任何空间,其长度由 NumericData 中的 vl_len_ 决定。
这里看到有 long 和 short 两个结构体,对于早期的 PostgreSQL 版本,使用的是 long 的存储方式,后面进行了优化,改进成 short 的存储方式,改进之后的版本为了保持向前兼容,能依然读取之前版本存储的数据,保留了 long 类型的存储方式。
结构体 NumericShort
struct NumericShort
{
uint16 n_header; /* Sign + display scale + weight */
NumericDigit n_data[FLEXIBLE_ARRAY_MEMBER]; /* Digits */
};
uint16 n_header :保存符号、dynamic scale和权值的信息。
若为 0xC000 则意味着该 Numeric 为 NaN
剩余的 14 个 bit 中,1 个用来保存符号,6 个保存 dynamic scale,7 个用来保存权值 weight。
**NumericDigit n_data[FLEXIBLE_ARRAY_MEMBER] **:参考上文柔性数组描述。
联合体 NumericChoice
union NumericChoice
{
uint16 n_header; /* Header word */
struct NumericLong n_long; /* Long form (4-byte header) */
struct NumericShort n_short; /* Short form (2-byte header) */
};
uint16 n_header :这个占两个字节的变量包含有很多信息。如果 n_header 第一个字节最高两个 bit 位的值为:
0x8000:则采用 NumericShort 存储格式
0xC000:则为 NaN
除此之外,则采用 NumericLong 存储格式。
结构体 NumericData
struct NumericData
{
int32 vl_len_; /* varlena header (do not touch directly!) */
union NumericChoice choice; /* choice of format */
};
int32 vl_len_ :用来保存动态数组的长度,这个数组是 NumericLong 或者 NumericShort 结构体中定义的动态数组。
Numeric 内存计算结构解析
typedef struct NumericVar
{
int ndigits; /* # of digits in digits[] - can be 0! */
int weight; /* weight of first digit */
int sign; /* NUMERIC_POS, NUMERIC_NEG, or NUMERIC_NAN */
int dscale; /* display scale */
NumericDigit *buf; /* start of palloc'd space for digits[] */
NumericDigit *digits; /* base-NBASE digits */
} NumericVar;
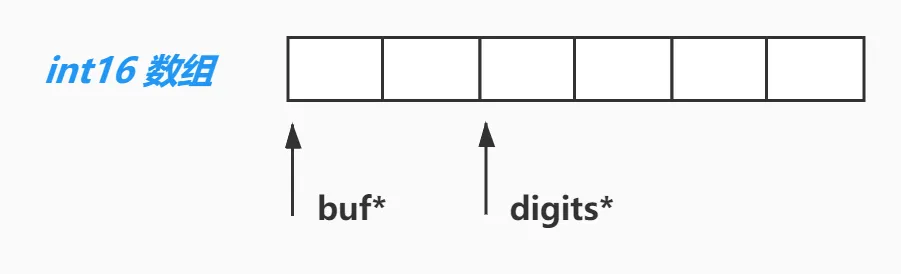
NumericVar 是用来做算术运算的格式,在 digit-array 部分同存储格式一样,但是在 header 部分更复杂。下面分别作分析:
-
buf:指向实际为 NumericVar 申请的内存 start 位置
-
digits:指向实际使用时的第一个数字的位置(这里的元素是 int16,非 0)
- buf 跟 digts 之间一般预留一到两个元素(int16)作为可能的 carry(进位)用,当然,考虑到实际 numeric 中 leading 部分可能有好多 0,意味着 buf 跟 digits 之间可以相隔好多个元素
-
dscale:display scale 的缩写,表示 numeric 小数点后有多少个十进制数
- 就目前的版本,总是 >= 0,dscale 的值可能比实际存储的小数位数要大,这意味多出来的部分是 0(trailing zeros),同时也意味着在写入磁盘时,是不会把无意义的 0 写进去的(节约磁盘空间)
-
rscale:这里提一个在函数计算时用到的变量,result scale 的缩写,保存目标计算结果的精度,总是 >= 0
- rscale 并不保存在 NumericVar 中,实际值是根据输入的 dscales 确定的
-
sign:标记正负号或者 NAN
-
weight:权值,权值是进制的(位数 -1)幂
- 比如 9999 9999 9999.9999,占用三个 int16,权值是 2(原理跟 10 进制权值一样的算法,只是 int16 的基数值是 10000)
-
ndigits:在 digits[ ] 数组中的 int16 的个数
关注“青云技术社区”公众号,后台回复关键字“云原生实战”,即可加入课程交流群。

作者
高日耀 资深数据库内核研发、MySQL 系列产品内核开发
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号