
day11
类的继承
什么是继承
- 继承是一种新建类的方式,新建的类称为子类,被继承的类称为父类
- 继承的特性是:子类会遗传父类的属性
- 继承是类与类之间的关系
为什么用继承
- 使用继承可以减少代码的冗余
对象的继承
Python中支持一个类同时继承多个父类
class Parent1:
pass
class Parent2:
pass
class Sub1(Parent1, Parent2):
pass
- 使用__bases__方法可以获取对象继承的类
print(Sub1.__bases__)
(<class '__main__.Parent1'>, <class '__main__.Parent2'>)
print(Parent1.__bases__)
(<class 'object'>,)
类的分类
- 新式类
继承了object的类以及该类的子类,都是新式类
Python3中所有的类都是新式类
- 经典类
没有继承object的类以及该类的子类,都是经典类
只有Python2中才有经典类
继承与抽象
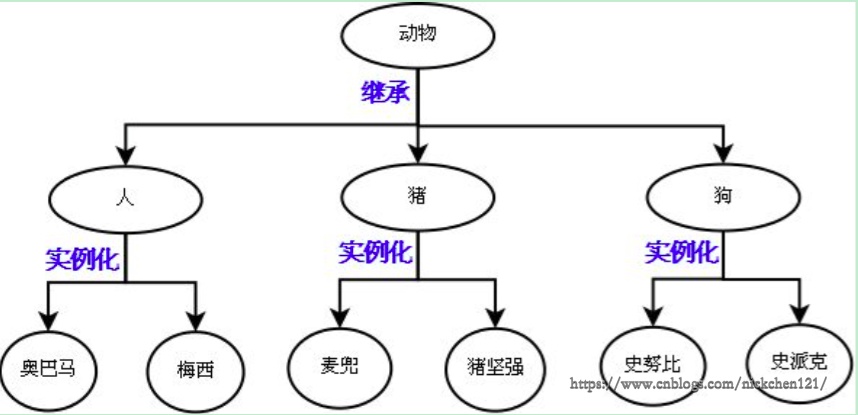
继承描述的是子类与父类之间的关系,是一种什么是什么的关系。要找出这种关系,必须先抽象再继承,抽象即抽取类似或者说比较像的部分。
抽象分成两个层次:
- 将奥巴马和梅西这俩对象比较像的部分抽取成类;
- 将人,猪,狗这三个类比较像的部分抽取成父类。
抽象最主要的作用是划分类别(可以隔离关注点,降低复杂度),如下图所示:

继承:基于抽象的结果,通过编程语言去实现它,肯定是先经历抽象这个过程,才能通过继承的方式去表达出抽象的结构。
抽象只是分析和设计的过程中,一个动作或者说一种技巧,通过抽象可以得到类,如下图所示:
继承的应用
- 牢记对象是特征与功能的集合体,我们可以拿选课系统举例
class OldboyPeople:
"""由于学生和老师都是人,因此人都有姓名、年龄、性别"""
school = 'oldboy'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class OldboyStudent(OldboyPeople):
def choose_course(self):
print('%s is choosing course' % self.name)
class OldboyTeacher(OldboyPeople):
def score(self, stu_obj, num):
print('%s is scoring' % self.name)
stu_obj.score = num
stu1 = OldboyStudent('tank', 18, 'male')
tea1 = OldboyTeacher('nick', 18, 'male')
- 对象查找属性的顺序:对象自己-》对象的类-》父类-》父类。。。
print(stu1.school)
oldboy
print(tea1.school)
oldboy
print(stu1.__dict__)
{'name': 'tank', 'age': 18, 'gender': 'male'}
tea1.score(stu1, 99)
nick is scoring
print(stu1.__dict__)
{'name': 'tank', 'age': 18, 'gender': 'male', 'score': 99}
属性查找练习
class Foo:
def f1(self):
print('Foo.f1')
def f2(self):
print('Foo.f2')
self.f1()
class Bar(Foo):
def f1(self):
print('Bar.f1')
obj = Bar()
obj.f2()
Foo.f2
Bar.f1
定义了两个类,一个是Foo,另一个是继承自Foo的Bar。代码的最后创建了一个Bar类的实例对象obj,并调用了obj的f2()方法。
在调用obj.f2()时,首先会在obj对象中查找属性f2,如果找不到,则继续在obj的类Bar中查找。找到了类Bar中的f2方法后,该方法会被调用。
在方法f2内部,先打印输出"Foo.f2",然后执行self.f1()。由于self代表当前对象obj,所以会在obj对象中查找属性f1。根据属性查找顺序,先在obj中查找,未找到后则到obj的类Bar中查找。在Bar类中找到了f1方法,于是调用了Bar类的f1方法。
最终输出的结果是:
Foo.f2
Bar.f1
因为在Bar类中重写了f1方法,所以调用f1时会优先调用Bar类中的f1方法,而不是继承自父类Foo的f1方法。
类的派生
派生
- 派生:子类中新定义的属性的这个过程叫做派生,并且需要记住子类在使用派生的属性时始终以自己的为准
派生方法一(类调用)
- 指名道姓访问某一个类的函数:该方式与继承无关
class OldboyPeople:
school = 'oldboy'
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
class OldboyStudent(OldboyPeople):
"""由于学生类没有独自的__init__()方法,因此不需要声明继承父类的__init__()方法,会自动继承"""
def choose_course(self):
print('%s is choosing course' % self.name)
class OldboyTeacher(OldboyPeople):
"""由于老师类有独自的__init__()方法,因此需要声明继承父类的__init__()"""
def __init__(self, name, age, gender, level):
OldboyPeople.__init__(self, name, age, gender)
self.level = level # 派生
def score(self, stu_obj, num):
print('%s is scoring' % self.name)
stu_obj.score = num
stu1 = OldboyStudent('tank', 18, 'male')
tea1 = OldboyTeacher('nick',18,'male',10)
print(stu1.__dict__)
{'name': 'tank', 'age': 18, 'gender': 'male'}
print(tea1.__dict__)
{'name': 'nick', 'age': 18, 'gender': 'male', 'level': 10}
派生方法二(super)
- 严格以来继承属性查找关系
- super()会得到一个特殊的对象,该对象就是专门用来访问父类中的属性的(按照继承的关系)
- super().init(不用为self传值)
- super的完整用法是super(自己的类名,self),在python2中需要写完整,而python3中可以简写为* super()
class OldboyPeople:
school = 'oldboy'
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
class OldboyStudent(OldboyPeople):
def __init__(self, name, age, sex, stu_id):
super().__init__(name,age,sex)
self.stu_id = stu_id
def choose_courses(self):
print('%s is choosing course' % self.name)
stu1 = OldboyStudent('tank',19,'male',1)
print(stu1.__dict__)
{'name': 'tank', 'age': 19, 'sex': 'male', 'stu_id': 1}
类的组合
什么是组合
- 组合就是一个类的对象具备某一个属性,该属性的值是指向另外外一个类的对象
为什么用组合
- 组合是用来解决类与类之间代码冗余的问题
- 首先我们先写一个简单版的选课系统
class OldboyPeople:
school = 'oldboy'
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
class OldboyStudent(OldboyPeople):
def __init__(self, name, age, sex, stu_id):
OldboyPeople.__init__(self, name, age, sex)
self.stu_id = stu_id
def choose_course(self):
print('%s is choosing course' % self.name)
class OldboyTeacher(OldboyPeople):
def __init__(self, name, age, sex, level):
OldboyPeople.__init__(self, name, age, sex)
self.level = level
def score(self, stu, num):
stu.score = num
print('老师[%s]为学生[%s]打分[%s]' % (self.name, stu.name, num))
stu1 = OldboyStudent('tank', 19, 'male', 1)
tea1 = OldboyTeacher('nick', 18, 'male', 10)
stu1.choose_course()
tank is choosing course
tea1.score(stu1, 100)
老师[nick]为学生[tank]打分[100]
print(stu1.__dict__)
{'name': 'tank', 'age': 19, 'sex': 'male', 'stu_id': 1, 'score': 100}
如上设计了一个选课系统,但是这个选课系统在未来一定是要修改、扩展的,因此我们需要修改上述的代码
如何用组合
- 需求:假如我们需要给学生增添课程属性,但是又不是所有的老男孩学生一进学校就有课程属性,课程属性是学生来老男孩后选出来的,也就是说课程需要后期学生们添加进去的
- 实现思路:如果我们直接在学生中添加课程属性,那么学生刚被定义就需要添加课程属性,这就不符合我们的要求,因此我们可以使用组合能让学生未来添加课程属性
class Course:
def __init__(self, name, period, price):
self.name = name
self.period = period
self.price = price
def tell_info(self):
msg = """
课程名:%s
课程周期:%s
课程价钱:%s
""" % (self.name, self.period, self.price)
print(msg)
class OldboyPeople:
school = 'oldboy'
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
class OldboyStudent(OldboyPeople):
def __init__(self, name, age, sex, stu_id):
OldboyPeople.__init__(self, name, age, sex)
self.stu_id = stu_id
def choose_course(self):
print('%s is choosing course' % self.name)
class OldboyTeacher(OldboyPeople):
def __init__(self, name, age, sex, level):
OldboyPeople.__init__(self, name, age, sex)
self.level = level
def score(self, stu, num):
stu.score = num
print('老师[%s]为学生[%s]打分[%s]' % (self.name, stu.name, num))
# 创造课程
python = Course('python全栈开发', '5mons', 3000)
python.tell_info()
课程名:python全栈开发
课程周期:5mons
课程价钱:3000
linux = Course('linux运维', '5mons', 800)
linux.tell_info()
课程名:linux运维
课程周期:5mons
课程价钱:800
# 创造学生与老师
stu1 = OldboyStudent('tank', 19, 'male', 1)
tea1 = OldboyTeacher('nick', 18, 'male', 10)
# 将学生、老师与课程对象关联/组合
stu1.course = python
tea1.course = linux
stu1.course.tell_info()
课程名:python全栈开发
课程周期:5mons
课程价钱:3000
tea1.course.tell_info()
课程名:linux运维
课程周期:5mons
课程价钱:800
组合可以理解成多个人去造一个机器人,有的人造头、有的人造脚、有的人造手、有的人造躯干,大家都完工后,造躯干的人把头、脚、手拼接到自己的躯干上,因此一个机器人便造出来了
菱形继承问题
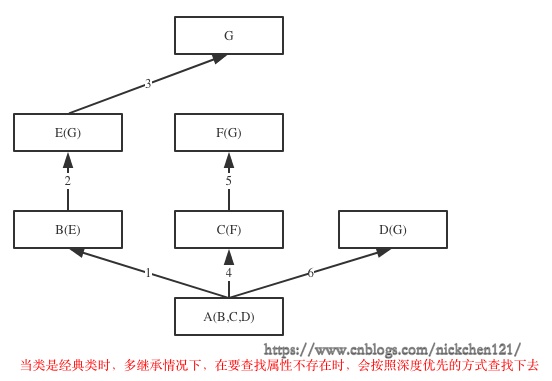
在Java和C#中子类只能继承一个父类,而Python中子类可以同时继承多个父类,如A(B,C,D)
如果继承关系为非菱形结构,则会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性
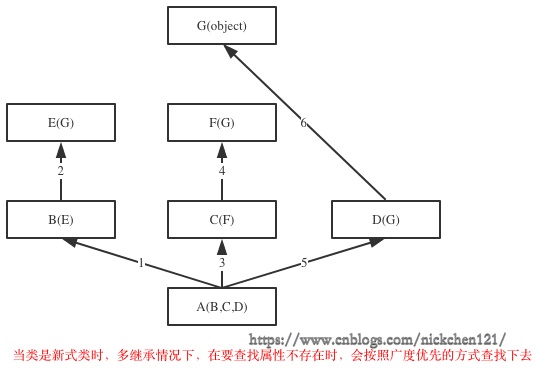
如果继承关系为菱形结构,即子类的父类最后继承了同一个类,那么属性的查找方式有两种:
- 经典类下:深度优先
- 广度优先:广度优先
- 经典类:一条路走到黑,深度优先
- 新式类:不找多各类最后继承的同一个类,直接去找下一个父类,广度优先
class G(object):
# def test(self):
# print('from G')
pass
print(G.__bases__)
class E(G):
# def test(self):
# print('from E')
pass
class B(E):
# def test(self):
# print('from B')
pass
class F(G):
# def test(self):
# print('from F')
pass
class C(F):
# def test(self):
# print('from C')
pass
class D(G):
# def test(self):
# print('from D')
pass
class A(B, C, D):
def test(self):
print('from A')
obj = A()
(<class 'object'>,)
obj.test() # A->B->E-C-F-D->G-object
from A
C3算法与mro()方法
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,如:
print(A.mro())
[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.F'>, <class '__main__.D'>, <class '__main__.G'>, <class 'object'>]
for i in A.mro():
print(i)
<class '__main__.A'>
<class '__main__.B'>
<class '__main__.E'>
<class '__main__.C'>
<class '__main__.F'>
<class '__main__.D'>
<class '__main__.G'>
<class 'object'>
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
- 子类会先于父类被检查
- 多个父类会根据它们在列表中的顺序被检查
- 如果对下一个类存在两个合法的选择,选择第一个父类
super()方法详解
单独调用父类的方法
需求:编写一个类,然后再写一个子类进行继承,使用子类去调用父类的方法1。
class FatFather(object):
def __init__(self, name):
print('FatFather的init开始被调用')
self.name = name
print('FatFather的name是%s' % self.name)
print('FatFather的init调用结束')
def main():
ff = FatFather("胖子老板的父亲")
if __name__ == "__main__":
main()
FatFather的init开始被调用
FatFather的name是胖子老板的父亲
FatFather的init调用结束
下面来写一个子类,也就是胖子老板类,继承上面的类
# 胖子老板的父类
class FatFather(object):
def __init__(self, name):
print('FatFather的init开始被调用')
self.name = name
print('调用FatFather类的name是%s' % self.name)
print('FatFather的init调用结束')
# 胖子老板类 继承 FatFather 类
class FatBoss(FatFather):
def __init__(self, name, hobby):
print('胖子老板的类被调用啦!')
self.hobby = hobby
FatFather.__init__(self, name) # 直接调用父类的构造方法
print("%s 的爱好是 %s" % (name, self.hobby))
def main():
#ff = FatFather("胖子老板的父亲")
fatboss = FatBoss("胖子老板", "打斗地主")
在这上面的代码中,我使用FatFather.init(self,name)直接调用父类的方法。
运行结果如下:
if __name__ == "__main__":
main()
胖子老板的类被调用啦!
FatFather的init开始被调用
调用FatFather类的name是胖子老板
FatFather的init调用结束
胖子老板 的爱好是 打斗地主
super() 方法基本概念
描述
super() 函数是用于调用父类(超类)的一个方法。
super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。
语法
super(type[, object-or-type])
参数
- type -- 类
- object-or-type -- 类,一般是 self
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
# Python3.x 实例:
class A:
pass
class B(A):
def add(self, x):
super().add(x)
# Python2.x 实例:
class A(object): # Python2.x 记得继承 object
pass
class B(A):
def add(self, x):
super(B, self).add(x)
单继承使用super()
- 使用super() 方法来改写刚才胖子老板继承父类的 init 构造方法
# 胖子老板的父类
class FatFather(object):
def __init__(self, name):
print('FatFather的init开始被调用')
self.name = name
print('调用FatFather类的name是%s' % self.name)
print('FatFather的init调用结束')
# 胖子老板类 继承 FatFather 类
class FatBoss(FatFather):
def __init__(self, name, hobby):
print('胖子老板的类被调用啦!')
self.hobby = hobby
#FatFather.__init__(self,name) # 直接调用父类的构造方法
super().__init__(name)
print("%s 的爱好是 %s" % (name, self.hobby))
def main():
#ff = FatFather("胖子老板的父亲")
fatboss = FatBoss("胖子老板", "打斗地主")
从上面使用super方法的时候,因为是单继承,直接就可以使用了。
运行如下:
if __name__ == "__main__":
main()
胖子老板的类被调用啦!
FatFather的init开始被调用
调用FatFather类的name是胖子老板
FatFather的init调用结束
胖子老板 的爱好是 打斗地主
那么为什么说单继承直接使用就可以呢?因为super()方法如果多继承的话,会涉及到一个MRO
(继承父类方法时的顺序表) 的调用排序问题。
下面可以打印一下看看单继承的MRO顺序(FatBoss.mro)。
# 胖子老板的父类
class FatFather(object):
def __init__(self, name):
print('FatFather的init开始被调用')
self.name = name
print('调用FatFather类的name是%s' % self.name)
print('FatFather的init调用结束')
# 胖子老板类 继承 FatFather 类
class FatBoss(FatFather):
def __init__(self, name, hobby):
print('胖子老板的类被调用啦!')
self.hobby = hobby
#FatFather.__init__(self,name) # 直接调用父类的构造方法
super().__init__(name)
print("%s 的爱好是 %s" % (name, self.hobby))
def main():
print("打印FatBoss类的MRO")
print(FatBoss.__mro__)
print()
print("=========== 下面按照 MRO 顺序执行super方法 =============")
fatboss = FatBoss("胖子老板", "打斗地主")
上面的代码使用 FatBoss.mro 可以打印出 FatBoss这个类经过 python解析器的 C3算法计算过后的继承调用顺序。
运行如下:
if __name__ == "__main__":
main()
打印FatBoss类的MRO
(<class '__main__.FatBoss'>, <class '__main__.FatFather'>, <class 'object'>)
=========== 下面按照 MRO 顺序执行super方法 =============
胖子老板的类被调用啦!
FatFather的init开始被调用
调用FatFather类的name是胖子老板
FatFather的init调用结束
胖子老板 的爱好是 打斗地主
从上面的结果 (<class 'main.FatBoss'>, <class 'main.FatFather'>, <class 'object'>) 可以看出,super() 方法在 FatBoss 会直接调用父类是 FatFather ,所以单继承是没问题的。
那么如果多继承的话,会有什么问题呢?
多继承使用super()
假设再写一个胖子老板的女儿类,和 胖子老板的老婆类,此时女儿需要同时继承 两个类(胖子老板类,胖子老板老婆类)。
因为胖子老板有一个爱好,胖子老板的老婆需要干活干家务,那么女儿需要帮忙同时兼顾。
此时女儿就是需要继承使用这两个父类的方法了,那么该如何去写呢?
下面来看看实现代码:
# 胖子老板的父类
class FatFather(object):
def __init__(self, name, *args, **kwargs):
print()
print("=============== 开始调用 FatFather ========================")
print('FatFather的init开始被调用')
self.name = name
print('调用FatFather类的name是%s' % self.name)
print('FatFather的init调用结束')
print()
print("=============== 结束调用 FatFather ========================")
# 胖子老板类 继承 FatFather 类
class FatBoss(FatFather):
def __init__(self, name, hobby, *args, **kwargs):
print()
print("=============== 开始调用 FatBoss ========================")
print('胖子老板的类被调用啦!')
#super().__init__(name)
## 因为多继承传递的参数不一致,所以使用不定参数
super().__init__(name, *args, **kwargs)
print("%s 的爱好是 %s" % (name, hobby))
print()
print("=============== 结束调用 FatBoss ========================")
# 胖子老板的老婆类 继承 FatFather类
class FatBossWife(FatFather):
def __init__(self, name, housework, *args, **kwargs):
print()
print("=============== 开始调用 FatBossWife ========================")
print('胖子老板的老婆类被调用啦!要学会干家务')
#super().__init__(name)
## 因为多继承传递的参数不一致,所以使用不定参数
super().__init__(name, *args, **kwargs)
print("%s 需要干的家务是 %s" % (name, housework))
print()
print("=============== 结束调用 FatBossWife ========================")
# 胖子老板的女儿类 继承 FatBoss FatBossWife类
class FatBossGril(FatBoss, FatBossWife):
def __init__(self, name, hobby, housework):
print('胖子老板的女儿类被调用啦!要学会干家务,还要会帮胖子老板斗地主')
super().__init__(name, hobby, housework)
def main():
print("打印FatBossGril类的MRO")
print(FatBossGril.__mro__)
print()
print("=========== 下面按照 MRO 顺序执行super方法 =============")
gril = FatBossGril("胖子老板", "打斗地主", "拖地")
if __name__ == "__main__":
main()
打印FatBossGril类的MRO
(<class '__main__.FatBossGril'>, <class '__main__.FatBoss'>, <class '__main__.FatBossWife'>, <class '__main__.FatFather'>, <class 'object'>)
=========== 下面按照 MRO 顺序执行super方法 =============
胖子老板的女儿类被调用啦!要学会干家务,还要会帮胖子老板斗地主
=============== 开始调用 FatBoss ========================
胖子老板的类被调用啦!
=============== 开始调用 FatBossWife ========================
胖子老板的老婆类被调用啦!要学会干家务
=============== 开始调用 FatFather ========================
FatFather的init开始被调用
调用FatFather类的name是胖子老板
FatFather的init调用结束
=============== 结束调用 FatFather ========================
胖子老板 需要干的家务是 拖地
=============== 结束调用 FatBossWife ========================
胖子老板 的爱好是 打斗地主
=============== 结束调用 FatBoss ========================
从上面的运行结果来看,我特意给每个类的调用开始以及结束都进行打印标识,可以看到。
每个类开始调用是根据MRO顺序进行开始,然后逐个进行结束的。
还有就是由于因为需要继承不同的父类,参数不一定。
所以,所有的父类都应该加上不定参数*args , **kwargs ,不然参数不对应是会报错的。
注意事项
- super().__init__相对于类名.init,在单继承上用法基本无差
- 但在多继承上有区别,super方法能保证每个父类的方法只会执行一次,而使用类名的方法会导致方法被执行多次,可以尝试写个代码来看输出结果
- 多继承时,使用super方法,对父类的传参数,应该是由于python中super的算法导致的原因,必须把参数全部传递,否则会报错
- 单继承时,使用super方法,则不能全部传递,只能传父类方法所需的参数,否则会报错
- 多继承时,相对于使用类名.__init__方法,要把每个父类全部写一遍, 而使用super方法,只需写一句话便执行了全部父类的方法,这也是为何多继承需要全部传参的一个原因
练习
class Parent(object):
x = 1
class Child1(Parent):
pass
class Child2(Parent):
pass
print(Parent.x, Child1.x, Child2.x)
1 1 1
Child1.x = 2
print(Parent.x, Child1.x, Child2.x)
1 2 1
Parent.x = 3
print(Parent.x, Child1.x, Child2.x)
3 2 3
类的多态和多态性
多态
多态指的是一类事物有多种形态,(一个抽象类有多个子类,因而多态的概念依赖于继承)
- 序列数据类型有多种形态:字符串,列表,元组
- 动物有多种形态:人,狗,猪
动物的多种形态
# 动物有多种形态:人类、猪、狗
class Animal:
def run(self): # 子类约定俗称的必须实现这个方法
raise AttributeError('子类必须实现这个方法')
class People(Animal):
def run(self):
print('人正在走')
class Pig(Animal):
def run(self):
print('pig is walking')
class Dog(Animal):
def run(self):
print('dog is running')
peo1 = People()
pig1 = Pig()
d1 = Dog()
peo1.run()
pig1.run()
d1.run()
人正在走
pig is walking
dog is running
import abc
class Animal(metaclass=abc.ABCMeta): # 同一类事物:动物
@abc.abstractmethod # 上述代码子类是约定俗称的实现这个方法,加上@abc.abstractmethod装饰器后严格控制子类必须实现这个方法
def talk(self):
raise AttributeError('子类必须实现这个方法')
class People(Animal): # 动物的形态之一:人
def talk(self):
print('say hello')
class Dog(Animal): # 动物的形态之二:狗
def talk(self):
print('say wangwang')
class Pig(Animal): # 动物的形态之三:猪
def talk(self):
print('say aoao')
peo2 = People()
pig2 = Pig()
d2 = Dog()
peo2.talk()
pig2.talk()
d2.talk()
say hello
say aoao
say wangwang
文件的多种形态
# 文件有多种形态:文件、文本文件、可执行文件
import abc
class File(metaclass=abc.ABCMeta): # 同一类事物:文件
@abc.abstractmethod
def click(self):
pass
class Text(File): # 文件的形态之一:文本文件
def click(self):
print('open file')
class ExeFile(File): # 文件的形态之二:可执行文件
def click(self):
print('execute file')
text = Text()
exe_file = ExeFile()
text.click()
exe_file.click()
open file
execute file
多态性
注意:多态与多态性是两种概念
多态性是指具有不同功能的函数可以使用相同的函数名,这样就可以用一个函数名调用不同内容的函数。在面向对象方法中一般是这样表述多态性:向不同的对象发送同一条消息,不同的对象在接收时会产生不同的行为(即方法)。也就是说,每个对象可以用自己的方式去响应共同的消息。所谓消息,就是调用函数,不同的行为就是指不同的实现,即执行不同的函数。
动物形态多态性的使用
# 多态性:一种调用方式,不同的执行效果(多态性)
def func(obj):
obj.run()
func(peo1)
func(pig1)
func(d1)
人正在走
pig is walking
dog is running
# 多态性依赖于:继承
# 多态性:定义统一的接口
def func(obj): # obj这个参数没有类型限制,可以传入不同类型的值
obj.talk() # 调用的逻辑都一样,执行的结果却不一样
func(peo2)
func(pig2)
func(d2)
say hello
say aoao
say wangwang
文件形态多态性的使用
def func(obj):
obj.click()
func(text)
func(exe_file)
open file
execute file
序列数据类型多态性的使用
def func(obj):
print(len(obj))
func('hello')
func([1, 2, 3])
func((1, 2, 3))
5
3
3
综上可以说,多态性是一个接口(函数func)的多种实现(如obj.run(),obj.talk(),obj.click(),len(obj))
多态性的好处
其实大家从上面多态性的例子可以看出,我们并没有增加新的知识,也就是说Python本身就是支持多态性的,这么做的好处是什么呢?
- 增加了程序的灵活性:以不变应万变,不论对象千变万化,使用者都是同一种形式去调用,如func(animal)
- 增加了程序额可扩展性:通过继承Animal类创建了一个新的类,使用者无需更改自己的代码,还是用func(animal)去调用
class Cat(Animal): # 属于动物的另外一种形态:猫
def talk(self):
print('say miao')
def func(animal): # 对于使用者来说,自己的代码根本无需改动
animal.talk()
cat1 = Cat() # 实例出一只猫
func(cat1) # 甚至连调用方式也无需改变,就能调用猫的talk功能
say miao
差异
多态:同一种事物的多种形态,动物分为人类,猪类(在定义角度)
多态性:一种调用方式,不同的执行效果(多态性)
类的封装
从封装本身的意思去理解,封装就好像是拿来一个麻袋,把小猫,小狗,小王八,还有egon一起装进麻袋,然后把麻袋封上口子。但其实这种理解相当片面
封装什么
- 你钱包的有多少钱(数据的封装)
- 你的性取向(数据的封装)
- 你撒尿的具体功能是怎么实现的(方法的封装)
为什么要封装
封装数据的主要原因是:保护隐私(作为男人的你,脸上就写着:我喜欢男人,你害怕么?)
封装方法的主要原因是:隔离复杂度(快门就是傻瓜相机为傻瓜们提供的方法,该方法将内部复杂的照相功能都隐藏起来了,比如你不必知道你自己的尿是怎么流出来的,你直接掏出自己的接口就能用尿这个功能)
提示:在编程语言里,对外提供的接口(接口可理解为了一个入口),就是函数,称为接口函数,这与接口的概念还不一样,接口代表一组接口函数的集合体。
两个层面的封装
封装其实分为两个层面,但无论哪种层面的封装,都要对外界提供好访问你内部隐藏内容的接口(接口可以理解为入口,有了这个入口,使用者无需且不能够直接访问到内部隐藏的细节,只能走接口,并且我们可以在接口的实现上附加更多的处理逻辑,从而严格控制使用者的访问)
第一个层面
第一个层面的封装(什么都不用做):创建类和对象会分别创建二者的名称空间,我们只能用类名.或者obj.的方式去访问里面的名字,这本身就是一种封装
注意:对于这一层面的封装(隐藏),类名.和实例名.就是访问隐藏属性的接口
第二个层面
第二个层面的封装:类中把某些属性和方法隐藏起来(或者说定义成私有的),只在类的内部使用、外部无法访问,或者留下少量接口(函数)供外部访问。
在python中用双下划线的方式实现隐藏属性(设置成私有的)
类中所有双下划线开头的名称如__ x都会自动变形成:_类名__x的形式:
class A:
__N = 0 # 类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N
def __init__(self):
self.__X = 10 # 变形为self._A__X
def __foo(self): # 变形为_A__foo
print('from A')
def bar(self):
self.__foo() # 只有在类内部才可以通过__foo的形式访问到.
这种自动变形的特点:
- 类中定义的__ x只能在内部使用,如self.__ x,引用的就是变形的结果。
- 这种变形其实正是针对内部的变形,在外部是无法通过__x这个名字访问到的。
- 在子类定义的__ x不会覆盖在父类定义的__x,因为子类中变形成了:_ 子类名__ x,而父类中变形成了:_父类名__x,即双下滑线开头的属性在继承给子类时,子类是无法覆盖的。
注意:对于这一层面的封装(隐藏),我们需要在类中定义一个函数(接口函数)在它内部访问被隐藏的属性,然后外部就可以使用了
这种变形需要注意的问题是:
- 这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:类名_ 属性,然后就可以访问了,如a._ A__ N
# 对象测试
a = A()
print(a._A__N)
0
# 对象测试
print(a._A__X)
10
# 类测试
print(A._A__N)
0
# 类测试
try:
print(A._A__X) # 对象私有的属性
except Exception as e:
print(e)
type object 'A' has no attribute '_A__X'
- 变形的过程只在类的定义时发生一次,在定义后的赋值操作,不会变形
a = A()
print(a.__dict__)
{'_A__X': 10}
a.__Y = 1
print(a.__dict__)
{'_A__X': 10, '__Y': 1}
- 在继承中,父类如果不想让子类覆盖自己的方法,可以将方法定义为私有的
# 正常情况
class A:
def fa(self):
print('from A')
def test(self):
self.fa()
class B(A):
def fa(self):
print('from B')
b = B()
b.test()
from B
# 把fa定义成私有的,即__fa
class A:
def __fa(self): # 在定义时就变形为_A__fa
print('from A')
def test(self):
self.__fa() # 只会与自己所在的类为准,即调用_A__fa
class B(A):
def __fa(self):
print('from B')
b = B()
b.test()
from A
私有模块
python并不会真的阻止你访问私有的属性,模块也遵循这种约定,如果模块中的变量名_private_module以单下划线开头,那么from module import *时不能被导入该变量,但是你from module import _private_module依然是可以导入该变量的
其实很多时候你去调用一个模块的功能时会遇到单下划线开头的(socket._socket,sys._home,sys._clear_type_cache),这些都是私有的,原则上是供内部调用的,作为外部的你,一意孤行也是可以用的,只不过显得稍微傻逼一点点
python要想与其他编程语言一样,严格控制属性的访问权限,只能借助内置方法如__ getattr__,详见面向对象高级部分。
练习
- 多态是在定义角度
- 多态性是在调用角度(使用角度)
class A:
def fa(self):
print('from A')
def test(self):
self.fa()
class B(A):
def fa(self):
print('from B')
b = B()
b.test()
from B
class A:
def __fa(self):
print('from A')
def test(self):
self.__fa()
class B(A):
def __fa(self):
print('from B')
b = B()
b.test()
from A
类的property特性
什么是 property特性
- property装饰器用于将被装饰的方法伪装成一个数据属性,在使用时可以不用加括号而直接使用
# ############### 定义 ###############
class Foo:
def func(self):
pass
# 定义property属性
@property
def prop(self):
pass
# ############### 调用 ###############
foo_obj = Foo()
foo_obj.func() # 调用实例方法
foo_obj.prop # 调用property属性
如下的例子用于说明如何定一个简单的property属性:
class Goods(object):
@property
def size(self):
return 100
g = Goods()
print(g.size)
100
property属性的定义和调用要注意一下几点:
-
定义时,在实例方法的基础上添加 @property 装饰器;并且仅有一个self参数
-
调用时,无需括号
简单示例
对于京东商城中显示电脑主机的列表页面,每次请求不可能把数据库中的所有内容都显示到页面上,而是通过分页的功能局部显示,所以在向数据库中请求数据时就要显示的指定获取从第m条到第n条的所有数据 这个分页的功能包括:
- 根据用户请求的当前页和总数据条数计算出 m 和 n
- 根据m 和 n 去数据库中请求数据
# ############### 定义 ###############
class Pager:
def __init__(self, current_page):
# 用户当前请求的页码(第一页、第二页...)
self.current_page = current_page
# 每页默认显示10条数据
self.per_items = 10
@property
def start(self):
val = (self.current_page - 1) * self.per_items
return val
@property
def end(self):
val = self.current_page * self.per_items
return val
# ############### 调用 ###############
p = Pager(1)
print(p.start) # 就是起始值,即:m
0
print(p.end) # 就是结束值,即:n
10
从上述可见Python的property属性的功能是:property属性内部进行一系列的逻辑计算,最终将计算结果返回。
property属性的两种方式
- 装饰器 即:在方法上应用装饰器(推荐使用)
- 类属性 即:在类中定义值为property对象的类属性(Python2历史遗留)
装饰器
在类的实例方法上应用 @property 装饰器
Python中的类有经典类和新式类,新式类的属性比经典类的属性丰富。( 如果类继object,那么该类是新式类 )
经典类,具有一种 @property 装饰器:
# ############### 定义 ###############
class Goods:
@property
def price(self):
return "laowang"
# ############### 调用 ###############
obj = Goods()
result = obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值
print(result)
laowang
新式类,具有三种 @property 装饰器:
#coding=utf-8
# ############### 定义 ###############
class Goods:
"""python3中默认继承object类
以python2、3执行此程序的结果不同,因为只有在python3中才有@xxx.setter @xxx.deleter
"""
@property
def price(self):
print('@property')
@price.setter
def price(self, value):
print('@price.setter')
@price.deleter
def price(self):
print('@price.deleter')
# ############### 调用 ###############
obj = Goods()
obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值
@property
obj.price = 123 # 自动执行 @price.setter 修饰的 price 方法,并将 123 赋值给方法的参数
@price.setter
del obj.price # 自动执行 @price.deleter 修饰的 price 方法
@price.deleter
注意:
- 经典类中的属性只有一种访问方式,其对应被 @property 修饰的方法
- 新式类中的属性有三种访问方式,并分别对应了三个被 @property、@方法名.setter、@方法名.deleter 修饰的方法
由于新式类中具有三种访问方式,我们可以根据它们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
class Goods(object):
def __init__(self):
# 原价
self.original_price = 100
# 折扣
self.discount = 0.8
@property
def price(self):
# 实际价格 = 原价 * 折扣
new_price = self.original_price * self.discount
return new_price
@price.setter
def price(self, value):
self.original_price = value
@price.deleter
def price(self):
print('del')
del self.original_price
obj = Goods()
print(obj.price) # 获取商品价格
80.0
obj.price = 200 # 修改商品原价
print(obj.price)
160.0
del obj.price # 删除商品原价
del
类属性方式
创建值为property对象的类属性
注意:当使用类属性的方式创建property属性时,经典类和新式类无区别
class Foo:
def get_bar(self):
return 'laowang'
BAR = property(get_bar)
obj = Foo()
reuslt = obj.BAR # 自动调用get_bar方法,并获取方法的返回值
print(reuslt)
laowang
property方法中有个四个参数
- 第一个参数是方法名,调用 对象.属性 时自动触发执行方法
- 第二个参数是方法名,调用 对象.属性 = XXX 时自动触发执行方法
- 第三个参数是方法名,调用 del 对象.属性 时自动触发执行方法
- 第四个参数是字符串,调用 对象.属性.doc ,此参数是该属性的描述信息
#coding=utf-8
class Foo(object):
def get_bar(self):
print("getter...")
return 'laowang'
def set_bar(self, value):
"""必须两个参数"""
print("setter...")
return 'set value' + value
def del_bar(self):
print("deleter...")
return 'laowang'
BAR = property(get_bar, set_bar, del_bar, "description...")
obj = Foo()
obj.BAR # 自动调用第一个参数中定义的方法:get_bar
getter...
'laowang'
obj.BAR = "alex" # 自动调用第二个参数中定义的方法:set_bar方法,并将“alex”当作参数传入
setter...
desc = Foo.BAR.__doc__ # 自动获取第四个参数中设置的值:description...
print(desc)
description...
del obj.BAR # 自动调用第三个参数中定义的方法:del_bar方法
deleter...
由于类属性方式创建property属性具有3种访问方式,我们可以根据它们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
class Goods(object):
def __init__(self):
# 原价
self.original_price = 100
# 折扣
self.discount = 0.8
def get_price(self):
# 实际价格 = 原价 * 折扣
new_price = self.original_price * self.discount
return new_price
def set_price(self, value):
self.original_price = value
def del_price(self):
del self.original_price
PRICE = property(get_price, set_price, del_price, '价格属性描述...')
obj = Goods()
obj.PRICE # 获取商品价格
80.0
obj.PRICE = 200 # 修改商品原价
print(obj.PRICE)
160.0
del obj.PRICE # 删除商品原价
综上所述:
-
定义property属性共有两种方式,分别是【装饰器】和【类属性】,而【装饰器】方式针对经典类和新式类又有所不同。
-
通过使用property属性,能够简化调用者在获取数据的流程
property+类的封装
class People:
def __init__(self, name):
self.__name = name
@property # 查看obj.name
def name(self):
return '<名字是:%s>' % self.__name
peo1 = People('nick')
print(peo1.name)
<名字是:nick>
try:
peo1.name = 'EGON'
except Exception as e:
print(e)
can't set attribute
应用
私有属性添加getter和setter方法
class Money(object):
def __init__(self):
self.__money = 0
def getMoney(self):
return self.__money
def setMoney(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
使用property升级getter和setter方法
class Money(object):
def __init__(self):
self.__money = 0
def getMoney(self):
return self.__money
def setMoney(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
# 定义一个属性,当对这个money设置值时调用setMoney,当获取值时调用getMoney
money = property(getMoney, setMoney)
a = Money()
a.money = 100 # 调用setMoney方法
print(a.money) # 调用getMoney方法
100
使用property取代getter和setter方法
重新实现一个属性的设置和读取方法,可做边界判定
class Money(object):
def __init__(self):
self.__money = 0
# 使用装饰器对money进行装饰,那么会自动添加一个叫money的属性,当调用获取money的值时,调用装饰的方法
@property
def money(self):
return self.__money
# 使用装饰器对money进行装饰,当对money设置值时,调用装饰的方法
@money.setter
def money(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
a = Money()
a.money = 100
print(a.money)
100
类和对象的绑定方法及非绑定方法
类中定义的方法大致可以分为两类:绑定方法和非绑定方法。其中绑定方法又可以分为绑定到对象的方法和绑定到类的方法。
绑定方法
对象的绑定方法
在类中没有被任何装饰器修饰的方法就是 绑定到对象的方法,这类方法专门为对象定制。
class Person:
country = "China"
def __init__(self, name, age):
self.name = name
self.age = age
def speak(self):
print(self.name + ', ' + str(self.age))
p = Person('Kitty', 18)
print(p.__dict__)
{'name': 'Kitty', 'age': 18}
print(Person.__dict__['speak'])
<function Person.speak at 0x0000012B2F17E840>
speak即为绑定到对象的方法,这个方法不在对象的名称空间中,而是在类的名称空间中。
通过对象调用绑定到对象的方法,会有一个自动传值的过程,即自动将当前对象传递给方法的第一个参数(self,一般都叫self,也可以写成别的名称);若是使用类调用,则第一个参数需要手动传值。
p = Person('Kitty', 18)
p.speak() # 通过对象调用
Kitty, 18
Person.speak(p) # 通过类调用
Kitty, 18
类的绑定方法
类中使用 @classmethod 修饰的方法就是绑定到类的方法。这类方法专门为类定制。通过类名调用绑定到类的方法时,会将类本身当做参数传给类方法的第一个参数。
class Operate_database():
host = '192.168.0.5'
port = '3306'
user = 'abc'
password = '123456'
@classmethod
def connect(cls): # 约定俗成第一个参数名为cls,也可以定义为其他参数名
print(cls)
print(cls.host + ':' + cls.port + ' ' + cls.user + '/' + cls.password)
Operate_database.connect()
<class '__main__.Operate_database'>
192.168.0.5:3306 abc/123456
Operate_database().connect() # 输出结果一致
<class '__main__.Operate_database'>
192.168.0.5:3306 abc/123456
非绑定方法
在类内部使用 @staticmethod 修饰的方法即为非绑定方法,这类方法和普通定义的函数没有区别,不与类或对象绑定,谁都可以调用,且没有自动传值的效果。
import hashlib
class Operate_database():
def __init__(self, host, port, user, password):
self.host = host
self.port = port
self.user = user
self.password = password
@staticmethod
def get_passwrod(salt, password):
m = hashlib.md5(salt.encode('utf-8')) # 加盐处理
m.update(password.encode('utf-8'))
return m.hexdigest()
hash_password = Operate_database.get_passwrod('lala', '123456') # 通过类来调用
print(hash_password)
f7a1cc409ed6f51058c2b4a94a7e1956
p = Operate_database('192.168.0.5', '3306', 'abc', '123456')
hash_password = p.get_passwrod(p.user, p.password) # 也可以通过对象调用
print(hash_password)
0659c7992e268962384eb17fafe88364
绑定方法小结
如果函数体代码需要用外部传入的类,则应该将该函数定义成绑定给类的方法
如果函数体代码需要用外部传入的对象,则应该将该函数定义成绑定给对象的方法
非绑定方法小结
如果函数体代码既不需要外部传入的类也不需要外部传入的对象,则应该将该函数定义成非绑定方法/普通函数


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现