Python【第三篇】流程控制、文件操作、函数、装饰器
本节内容
- 流程控制
- 文件操作
- 函数
- 内置函数
- 迭代器、生成器、装饰器
一、流程控制
流程控制指的是代码运行逻辑、分支走向、循环控制、是真正体现程序执行顺序的操作。流程控制一般分为顺序执行、条件判断、循环控制。有什么输入就会有相应的输出,同一个输入不管执行多少次必然得到同样的输出,所有都是确定的、可控的。
顺序执行
虽然有各种流程判断、循环、跳转、控制、中断等等,但从根本上程序还是逐行顺序执行。
Python代码在执行过程中,遵循下面的基本原则:
普通语句,直接执行
遇到函数,将函数体载入内存,并不直接执行。
遇到类,执行类内部的普通语句,但是类的方法只载入,不执行。
遇到if、for等控制语句,按相应控制流程执行。
遇到@,break,continue等,按规定语法执行。
遇到函数、方法调用等,转而执行函数内部代码,执行完毕继续执行原有顺序代码。
if__name__ == '__main__':
很多时候,在python程序中看到这么一行语句,这里简单解释一下:首先,name是所有模块都会有的一个内置属性,一个模块的__name__值取决于你如何调用模块。
例如:有一个test.py文件,如果在a.py文件中使用import导入这个模块import test.py,那么test.py模块的__name__属性的值就是test,不带路径或者文件扩展名。但是很多时候,模块或者说脚本会像一个标准的程序直接运行,也就是类似python test.py这种方式,在这种情况下,__name__的值将是一个特别缺省值__main__。
根据上面的特性,可以用if__name__ == '__main__'来判断是否直接运行该py文件,如果是,那么if代码块下的语句就会被执行,如果不是,就不执行。该方法常用于对模块进行测试和调试,区分直接运行和被导入两种情况下的不同执行方式。
通过下面的例子,执行Python test.py看看实际的顺序执行方式:
test.py
import os
print("(1) 这里是开始")
class ClassOne:
print("(2)ClassOne类里面")
def __init__(self):
print("(3)ClassOne.__init__")
def __del__(self):
print("(4)ClassOne.__del__") # 所有执行完毕后,会执行的方法del
def method_x(self):
print("(5)ClassOne.method_x")
class ClassTwo:
print("(6)ClassTwo body")
class ClassThree:
print("(7)ClassThree boby")
def method_y(self):
print("(8)ClassThree.method_y")
class ClasssFour(ClassThree):
print("(9)ClassFour body")
def func():
print("func方法")
if __name__ == '__main__':
print("(11) ClassOne tests",30 * '.')
one = ClassOne()
one.method_x()
print("(12) ClassThree tests",30 * '.')
three = ClassThree()
three.method_y()
print("(13)ClassFour tests",30 * '.')
four = ClasssFour()
four.method_y()
print("(14) evaltime module end")
条件判断
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。
可以通过下面来简单了解条件语句的执行过程:
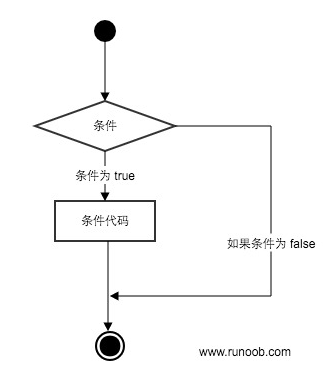
在Python语法中,使用if、elif和else三个关键字来进行条件判断。
if语句的一般形式如下所示:
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
实例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/4/8 14:06'
var1 = 100
if var1:
print ("1 - if 表达式条件为 true")
print (var1)
var2 = 0
if var2:
print ("2 - if 表达式条件为 true")
print (var2)
print ("Good bye!")
执行以上代码,输出结果为:
1 - if 表达式条件为 true
100
Good bye!
狗年龄计算判断:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/4/8 14:06'
age = int(input("请输入你家狗狗的年龄: "))
print("")
if age < 0:
print("你是在逗我吧!")
elif age == 1:
print("相当于 14 岁的人。")
elif age == 2:
print("相当于 22 岁的人。")
elif age > 2:
human = 22 + (age -2)*5
print("对应人类年龄: ", human)
### 退出提示
input("点击 enter 键退出")
以下为if中常用的操作运算符:
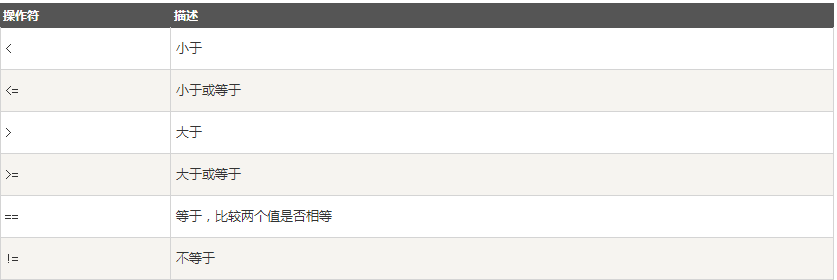
实例
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/4/8 14:06'
#程序演示了 == 操作符
print(5 == 6)
#使用变量
x = 5
y = 8
print(x == y)
实例(数字的比较运算)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/4/8 14:06'
# 该实例演示了数字猜谜游戏
number = 7
guess = -1
print("数字猜谜游戏!")
while guess != number:
guess = int(input("请输入你猜的数字:"))
if guess == number:
print("恭喜,你猜对了!")
elif guess < number:
print("猜的数字小了...")
elif guess > number:
print("猜的数字大了...")
if嵌套
在嵌套 if 语句中,可以把 if...elif...else 结构放在另外一个 if...elif...else 结构中。
if 表达式1:
语句
if 表达式2:
语句
elif 表达式3:
语句
else:
语句
elif 表达式4:
语句
else:
语句
实例
# !/usr/bin/python3
num=int(input("输入一个数字:"))
if num%2 == 0:
if num%3 == 0:
print ("你输入的数字可以整除 2 和 3")
else:
print ("你输入的数字可以整除 2,但不能整除 3")
else:
if num%3 == 0:
print ("你输入的数字可以整除 3,但不能整除 2")
else:
print ("你输入的数字不能整除 2 和 3")
条件判断的使用原则:
- 每个条件后面要使用冒号(:)作为判断行的结尾,表示接下来是满足条件(结果为True)后要执着的语句块。
- 除了if分支必须有,elif和else分支都可以根据情况省略。
- 使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
- 顺序判断每一个分支,任何一个分支首先被命中并执行,则其后面的使用分支被忽略,直接跳过。
循环控制
在处理业务的时候,并不是如果怎么样就怎么样,而是一直做某件事,直到全部做完,甚至永远做不玩。循环控制,就是让程序循环运行某一段代码直到满足退出条件,才能退出循环。
循环控制,就是让程序循环运行某一段代码直到满足退出的条件,才能退出循环。
Python用关键字for和while来进行循环控制;
Python循环语句的控制结构图:
while循环
while循环语句的控制结构图如下:
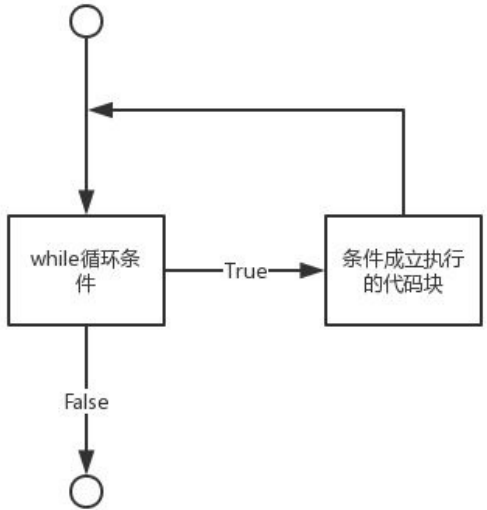
Python中while语句的一般形式:
while 判断条件:
语句
while循环用伪代码描述就是:当条件满足的时候,就一直运行while所管理的代码块,当条件不满足的时候,就结束while循环:
n = 100
sum = 0
counter = 1
while counter <= n:
sum+=counter
counter += 1
print("1 到 {0} 之和为:{1}".format(n,sum))
通常,在写循环条件或者循环体内设置退出条件,防止死循环,但有时候也需要无限循环。例如:web服务器响应客户端的实时请求;
while的else从句
while循环还可以增加一个else从句。当while循环正常执行完毕,会执行else语句。但如果是被break等机制强制提前终止的循环,不会执行else语句。注意else与while平级的缩进方式!
number = 10
i = 0
while i < number:
print(i)
i+=1
else:
print("执行完毕")
下面是被打断的while循环,else不会执行:
number = 10
i = 0
while i < number:
print(i)
i += 1
if i == 7:
break
else:
print('执行完毕')
for循环
与while一样都是循环的关键字,但for循环通常用来遍历可迭代的对象,如一个列表或者一个字符串。
for循环的一般格式如下:
for <variable> in <sequence>:
<statements>
else:
<statements>
for ... in ...属于固定套路。
sum = 0
for x in [1,2,3,4,5,6,7,8,9,10]:
sum+=x
print(sum)
for循环的else子句
与while一样,for循环也可以有else子句。同样是正常结束循环时,else子句执行。被中途break时,则不执行。
循环的嵌套
if判断可以嵌套,while和for当然也可以嵌套。但是建议大家不要嵌套3层以上,那样的效率会很低。下面是一个嵌套for循环结合else子句的例子:
for n in range(2,100):
for x in range(2,n):
if n %x==0:
print(n,"等于",x,"*",n//x)
break
else:
print(n,'是质数')
break语句
通常情况下:循环要么执行出错,要么死循环,要么就只能老老实实等它把所有的元素循环一遍才能退出。如果想在循环过程中退出循环,怎么办?用break语句;
break只能用于循环体内。其效果是直接结束并退出当前循环,剩下未循环的工作全部被忽略和取消。注意当前两个字,Python的break只能退出一层循环,对于多层嵌套循环,不能全部退出。
for letter in "Hello world":
if letter == 'd':
break
print("当前字母为:",letter)
var = 10
while var > 0:
print('当前变量值为:',var)
var -= 1
if var == 5:
break
continue语句
与break不同,continue语句用于跳过当前循环的剩余部分代码,直接开始下一轮循环。它不会退出和终止循环,只是提前结束当前轮次的循环。同样的,continue语句只能用在循环内。
for letter in "Hello world":
if letter == 'o':
continue
print("当前字母为:",letter)
var = 10
while var > 0:
var -= 1
if var == 5:
continue
print('当前变量值为:',var)
二、文件操作
以上我们做的一切操作,都是在内存里面进行。如果断电或发生意外,那么工作成果将瞬间消失。此刻还缺少将数据保存到本地文件系统进行持久化的能力,通俗讲就是文件读写能力。
Python内置了一个open()方法,用于对文件进行读写操作。open()方法的返回值是一个file对象,可以将它赋值给一个变量(文件句柄)。
基本语法格式为:f = open(filename,mode)。
Python中,所有具有read和write方法的对象,都可以归类为file类型。而所有的file类型对象都可以使用open()方法打开,close方法结束和with上下文管理器管理。
filename ---> 一个包含了要访问的文件名称的字符串,通常是一个文件路径。
mode ---> 打开文件的模式,有很多种,默认是只读模式r。
文件操作流程:
- 打开文件,得到文件句柄并赋值给一个变量;
- 通过句柄对文件进行操作;
- 关闭文件
编码问题
读取非UTF-8编码的文件,需要给open()函数传入encoding参数;
文件句柄=Open("文件路径","模式",encoding='utf-8');
f = open(...)是由操作系统打开文件,那么如果没有为open指定编码,你们打开文件的默认编码就是操作系统说了算,操作系统会用自己默认编码打开文件,在windows下是gbk,在linux下是utf-8。
若要保证不乱码,文件以什么方式存的,就要以什么方式打开。
操作文件的方法
当我们用open方法打开一个文件时,将返回一个文件对象。这个对象内置了很多操作方法。下面假设,已经打开了一个f文件对象。
f = open('a.txt','r',encoding='utf-8')
#掌握
f.read(size) #size是一个可选的数字类型参数,用于指定读取的数据量。不写size或者未负值,就是读取所有内容,光标移动到文件末尾。
#如果文件体积较大,不要使用read()方法一次性读入到内存,而是read(512)这种一点一点读。
f.readline() #从文件中读取一行内容。如果返回一个空字符串,说明已经读取到最后一行。这种方法通常是读一行,处理一行并且不能回头,只能前进读过的行不能再读了。
f.readlines() #将文件中所有的行,一行一行全部读入到一个列表内,按顺序一个一个作为列表的元素,并返回这个列表。readlines方法会一次性将文件全部读入内存,所以存在一定风险。但是有个好处,每行都保存在列表中,随意存取。
f = open("1.txt","r") #遍历文件,这个方法很简单,不需要将文件一次性读出,但是同样提供一个很好的控制,与readline方法一样只能前进,不能回退。
for line in f:
print(line,end='')
#关闭打开文件
f.close()
几种不同的读取和遍历文件的方法比较,如果文件很小,read()一次性读取最方便,如果不能确定文件大小,反复调用read(size)比较保险,如果是配置文件,调用readlines()最方便。普通情况下使用for循环更好,速度更快。
f.write('1111\n222\n') #针对文本模式的写,需要自己写换行符。write()动作可以多次重复进行,其实都是在内存中的操作,并不会立刻写回硬盘,直到执行close()方法后,才会将所有的写入操作反映到硬盘上。
f.write('1111\n222\n'.encode('utf-8')) #针对b模式的写,需要自己写换行符
f.writelines(['333\n','444\n']) #文件模式
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式
#了解
f.readable() #文件是否可读
f.writable() #文件是否可读
f.closed #文件是否关闭
f.encoding #如果文件打开模式为b,则没有该属性
f.flush() #立刻将文件内容从内存刷到硬盘
f.name
现有文件(test.txt):
Somehow, it seems the love I knew was always the most destructive kind
不知为何,我经历的爱情总是最具毁灭性的的那种
Yesterday when I was young
昨日当我年少轻狂
The taste of life was sweet
生命的滋味是甜的
As rain upon my tongue
就如舌尖上的雨露
I teased at life as if it were a foolish game
我戏弄生命 视其为愚蠢的游戏
The way the evening breeze
就如夜晚的微风
May tease the candle flame
基本操作
f = open('test.txt') #打开文件
first_line = f.readline() #读取一行
print(first_line)
print('我是分割线'.center(50,'-'))
data = f.read() #读取剩余的所有内容,文件大时不要用;read()方法可以指定读取多少个字符;
print(data)
f.close() #关闭文件
replace() 替换方法,用于修改文件内容:replace("张三","李四") 第一个参数为原内容,第二个参数为修改后内容
打开文件的模式:
- r,只读模式 【默认模式,文件必须存在,不存在则抛出异常】
- w,只写模式 【不可读;不存在则创建;存在则清空内容;】
- a,追加模式 【不可读; 不存在则创建;存在则只追加内容;】
- x, 文件存在报错,不存在,创建并写内容;
"+" 表示可以同时读写某个文件
- r+ 读写 ----> 先读后写,已读的模式打开,后面可以追加 。 (常用)
- w+ 写读 ----> 在读写之前都会清空文件的内容。(建议不要使用)
- a+ 追写 ----> 先追加后读,已读模式打开,文件不存在时会创建文件,永远只能在文件的末尾写入;追加内容相同时,可以重复追加。(常用)
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
b 对于非文本文件,我们只能使用b模式,b表示以字节的方式操作(而所有文件都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jpg格式、视频文件的avi格式)
- rb
- wb
- ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
其它方法
f = open('test.txt','r+')
f.readlines() #将所有内容一次性读取到列表中,大数据效率低
for line in f: #一行行读取文件
print(line)
f.close()
ps:seek()方法 :指定当前指针位置 ; tell()方法:查看当前指针位置
with语句
为了避免打开文件后忘记关闭,可以通过管理上限为
with open('text.txt','r+') as f:
.....
with支持同时打开多个文件
whith open('log1') as obj1, open('log2','w') as obj2:
s = obj1.read()
obj2.write(s)
进度条
import sys,time
for i in range(20):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.1)
修改文件中指定内容
test.txt
Oh, yesterday when I was young
噢 昨日当我年少轻狂
So many, many songs were waiting to be sung
有那么那么多甜美的曲儿等我歌唱
So many wild pleasures lay in store for me
有那么多肆意的快乐等我享受 -->修改为【等着张三去享受】
And so much pain my eyes refused to see
还有那么多痛苦 我的双眼却视而不见
There are so many songs in me that won't be sung
我有太多歌曲永远不会被唱起
I feel the bitter taste of tears upon my tongue
我尝到了舌尖泪水的苦涩滋味
The time has come for me to pay for yesterday
终于到了付出代价的时间 为了昨日
When I was young
修改.py
思路:
先找到需要修改的行,然后修改;
同时打开两个文件,一个读一个写;
f = open("yesterday",'r',encoding="utf-8",)
f_new = open("yesterday2",'w',encoding='utf-8',)
for line in f:
if line.strip()==' ':continue;
elif "肆意的快乐等我享受" in line: #找到需要修改的地方
line = line.replace("肆意的快乐等我享受","肆意的快乐等张三去享受")
f_new.write(line)
f.close()
f_new.close()
二、函数
本节内容:
- 背景
- 定义函数
- 函数返回值
- 参数:
普通参数
指定参数
默认参数
动态参数(*args)、(**kwargs)
万能参数(*args,**kwargs)
- 函数内容补充
- 三元运算&lambda表达式
- Python内置函数
1、背景
在学习函数之前,一直遵循面向过程编程,即:根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制;
2、函数
什么是函数?函数(function)是用于完成特定任务的程序代码。在面向对象编程的类中,函数通常被称作方法。不同函数在程序中扮演着不同角色,起着不同作用,执行不同的动作。例如print()函数可以将对象打印到屏幕上,还有
一些函数能够返回一个值以供程序使用,例如len()将可计算长度的对象的元素个数返回给程序。
3、为什么要使用函数呢?
减少重复代码,提高代码的重复利用率。如果程序中需要多次使用某种特定功能,那么只需要编写一个合适的函数就可以了。程序可以在任何需要的地方调用该函数,并且同一个函数可以在不同的程序中调用,例如print()和input()函数一样。
函数能封装内部实现,保护内部数据,实现对用户的透明。
即使某种功能在程序中只使用一次,将其以函数的形式实现也有必要,因为函数使得程序模块化,从一团散沙变成整齐方队从而有利于程序的阅读、调用、修改和完善。
使程序变得易维护。
4、定义一个函数
可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以def关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- Return[expression]结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None
5、语法
def functionname(parameters):
"函数_文档字符串"
function_suite
return expression
PS:return作用:1、返回值 2、终断执行;
例子:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Tian
import time
def logger():
time_format = '%Y-%m-%d %X' #添加时间
time_current = time.strftime(time_format)
with open('a.txt','a+') as f:
f.write('%send action333\n'%time_current)
def test1():
print("in the test1")
logger()
def test2():
print("in th test2")
logger()
test1()
test2()
5、return函数返回值
函数返回值作用:需要知道函数的执行结果,因为后面的程序可能需要根据执行结果来进行不同操作;
return可以返回什么?
什么都不返回,仅仅return : return
数字/字符串/任意数据类型 --->return 'hello'
一个表达式 ---> return 1+2
一个判断语句 ---> return 100>99
一个变量 ---> return a
一个函数调用 ---> return func()
返回自己 ---> return self
多个返回值,已逗号分隔--> return a,1+2,"hello"
简而言之,函数可以return几乎任意Python对象。
如何接收函数的返回值?
调用函数的时候,可以将函数的返回值保存在变量中。
def func():
pass
return "我是返回值"
result = func()
#同时返回多个值的函数,需要相应个数的变量来接收,变量之间用逗号分隔;
def func():
return 1,[2,3],"haha"
a,b,c = func()
例子:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Tian
import time
def test01():
pass
def test02():
return 0
def test3():
print("in the test3")
return 1,'hello',['alex','wupeiqi'],{'name':'alex'}
t1 = test01()
t2 = test02()
t3 = test3()
print(t1)
print(t2)
print(t3)
总结:
返回值数=0 :返回None
返回值数 =1:返回object
返回值数>1 : 返回tuple
6、函数调用
定义一个函数只给了函数一个名称,指定了函数里包含的参数和代码块结构。这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从Python提示符执行。
形参 ---> 只有在被调用时才分配内存单元,在调用结束后,即刻释放分配的内存。形参只在函数内部调用,外部是无法调用;
实参 ---> 可以是变量、常量、函数、表达式,无论实参是何种类型,在进行函数调用时,都必须有确定的值,以便将这些值传递给形参。因此必须预先赋值。

无参数调用
#定义函数
def show():
print();
return;
#函数调用
show()
1个参数调用
#定义函数
def show(arg):
print(arg);
return arg;
#函数调用
show(22)
位置参数&关键字参数
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Tian
def test(x,y):
print(x)
print(y)
test(y = 1,x = 2) # (关键字参数)与形参顺序无关
test(1,2) # (位置参数)与形参一一对应
# test(x = 1,2) #关键字参数,不能放在位置参数前面
test(3,y = 3) #正确
PS:关键参数不能放在,位置参数前面
7、函数的参数
1)、普通参数(严格按照顺序,将实际参数赋值给形式参数);
2)、默认参数(必须放置在参数列表的最后);
3)、指定参数(将实际参数赋值给制定的形式参数);
4)、动态参数
* 默认将传入的位置参数,全部当成一个元素放置在形参元组中; 若 实参 f1(*[11,22,33,44]) 会把传入列表中的每一个元素,单独放置形参列表中;
** 默认将传入的关键字参数,全部当成一个元素放置在形参字典中; 若 实参 f1(**{'k1':'v1','k2':'v2'}) 会把字典中每一个元素,单独放置形参字典中 ;
5)、万能参数 (1个*在前面,**两个放后面)
def f1(*args,**kwargs):
print(args)
print(kwargs)
f1(11,22,33,44,55,k1 = 'v1',k2='v2')
#自动把11,22,33,44添加到*args,把k1='v1',k2='v2'添加到**kwargs;
8、利用动态参数实现format功能
format格式化输出
#第一种
s = "i am {0},age{1}".format('tian',24)
s1 = "i am {0},arg{1}".format(*["tian",19])
print(s)
print(s1)
#第二中
s2 = "i am {name},age{age}".format(name="alec",age=18) #默认传值给**kwargs,顺序可以改变了;
print(s2)
dic = {'name':'tian','age':18}
s3 = "i am {name},age{age}".format(**dic) #直接传入字典,需加**
print(s3)
9、函数内容补充
1 #调用相同函数名
2
3 def f1(a1,a2):
4 return a1 + a2;
5
6 def f1(a1,a2):
7 return a1* a2;
8
9 res = f1(8,8)
10 print(res)
11
13 输出结果:64 执行第2个函数
14
15 列表输出值是多少>
16 def f1(a1):
17 a1.append(99)
18 li =[11,22,33,44]
19
20 f1(li)
21 print(li)
22
23 输出:[11,22,33,44,99],因为函数的参数传递的是引用;
ps:函数的参数传递的是引用
10、变量作用域
作用域指的是变量的有效范围。变量并不是在哪个位置都可以访问的,访问权限取决于这个变量是在哪里赋值的,也就是在哪个作用域的。
变量的作用域从代码结构形式来看,有块级、函数、类、模块、包等由小到大的级别。但是在Python中,没有块级作用域,也就是类似if语句块、for语句块、with上下文管理器等等是不存在作用域;
>>>if True: #if语句块是没有作用域
x = 1
>>>x
1
>>>def func(): #函数有作用域
a = 8
>>>a
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
a
NameError: name 'a' is not defined
从上面的的例子中,可以发现,在if语句内定义的变量X,可以被外部服务,而在函数func()中定义的变量a,则无法在外部服务。
通常,函数内部的变量无法被函数外部服务,但内部可以访问;类内部的变量无法被外部服务,但类的内部可以。通俗来讲,就是内部代码可以访问外部变量,而外部代码通常无法访问内部变量。
全局变量 和 局部变量
定义在函数内部的变量拥有一个局部作用域,被叫做局部变量,定义在函数外的拥有全局作用域的变量,称为全局变量。(类、模块等同理);
所谓的局部变量是相对的。局部变量也有可能是更小范围内的变量的外部变量;
局部变量只能在被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都被加入到作用域中;
a = 1 #全局变量,所有作用域都可读
def f1():
b = 18 ; #局部变量
print(a) #可以访问全局变量a,无法访问内部的c
def inner():
c = 3 #更改局部的变量
print(a) #可以访问全局变量
print(b) #b对于inner函数来说,就是外部变量
print(c)
函数内部修改外面的全局变量?使用global关键字
global:指当前变量使用外部的全局变量
例子:
total = 0 #total是一个全局变量
def plus(arg1,arg2):
global total #使用global关键字声明此处的total引用外部的total
total = arg1 + arg2
print("函数内部变量total=",total)
print("函数内的total的内存地址是:",id(total))
return total
plus(10,20)
print("函数外部全局变量total=" ,total)
print("函数外的total的内存地址是:",id(total))
PS : 全局变量,所有作用域都可读;
对全局变量进行【重新赋值】,需要global;
特殊:列表字典,可修改,不可重新赋值;
全局变量必须【大写】
11、三元运算&匿名函数(lambda )表达式
三元运算又称三目运算:是对if...else的简写
if 1==1:
name ="alex"
else:
name ="大王"
#写成三元运算符
name ="alex" if 1==1 else "SB"
lambda只是一个表达式,函数的简单表示方式
func = lambda a : a+1
ret = func(99)
print(ret)
解释:创建形式参数a,函数内容a+1,并把结果return
12、高阶函数
函数参数接收另一个函数作为参数,这种函数称为高阶函数
def add(x,y,f):
return f(x) + f(y)
res = add(3,-6,abs)
print(res)
13、内置函数

由于Python内置函数的强大、丰富、方便、在此进行介绍:
abs() #求绝对值
print(abs(-1)
输出>>>1
f = abs
print(f(-1))
#输出>>>1
abs = id
print(abs(1))
#输出>>>497727152
以abs()函数为例,展示两个特性:内置函数是可以被赋值给其它变量的,同样也可以将其他对象赋值给内置函数,这时就完全变了。所以,内置函数不是Python关键字,要注意对它们的保护,不要使用和内置函数重名的变量名,这会让代码
混乱,容易发生难以排查的错误;
all()
接收一个可迭代对象,如果对象里的所有元素的bool运算值都是True,那么放True,否则False。
print(all([1,1,1]))
#输出>>True
print(all([1,1,0]))
#输出>>False
any()
接收一个可迭代对象,如果迭代对象里有一个元素的bool运算值是True,那么放True,否则False。与all()是一对兄弟。
print(any([0,0,1]))
#输出>>True
print(any([0,0,0]))
#输出>>False
chr() --->数字与ascii码关系,print(chr(65)) 输出>>A
ord() --->字母与ascii码关系,print(ord("A")) 输出>>65
dir() --->快速查看一个对象提供了那些功能,例如:print(dir(dict)) #快速查看字典提供了那些功能;
bytes()
将对象转换成字节类型:
s = '张三'
m = bytes(s,encoding='utf-8')
print(m)
str()
将对象转换成字符串类型,同样也可以指定编码方式。例如:str(bytes对象,encoding='utf-8')
i = 2
print(str(i))
b = b"haha"
print(str(b))#输出:b'haha'
print(str(b,encoding="utf-8"))#输出:haha
classmethod()、staticmethod()、property()
用于生成类的方法、静态方法和属性的函数
delattr()、setattr()、hasattr() 反射后面会详解
dir()
显示对象所有的属性和方法。
divmod()
除法,同时返回商和余数的元组
print(divmod(10,3))
#输出:(3,1)
print(divmod(11,4))
#输出:(2,3)
enumerate()
枚举函数,在迭代对象的时候,额外提供一个序列号的输出。注意:enumerate(li,1)中的1表示从1开始序号,默认从0开始。第二个参数才是你想要的序号开始,不是第一个参数。
dic = {
"k1" : "v1",
"k2" : "v2",
"k3" : "v3"
}
for i ,key in enumerate(dic,1):
print(i,"\t",key)
输出: 1 k2
2 k3
3 k1
通常用于对那些无法提供序号的迭代对象使用,但对于字典依然是无序的。
eval()
将字符串直接解读并执行。例如:print(eval("6*9")) #输出54
isinstance()
判断一个对象是否是某个类的实例。
print(isinstance("titi",str))#输出:True
print(isinstance(1,str)) #输出:False
issubclass()
issubclass(a,b)判断a是否是b的子类。
class Foo:
pass
class Goo(Foo):
pass
print(issubclass(Goo,Foo))#True
iter()
制造一个迭代器,使其具备next()能力。
map()
映射函数,使用指定的函数,处理可迭代对象,并将结果保存在一个map对象中;
使用格式:obj = map(func,iterable),func是某个函数名,iterable是一个可迭代对象。
li = [1,2,3]
data = map(lambda x :x*100,li)
print(type(data))#输出<class 'map'>
data = list(data)#输出:[100, 200, 300]
print(data)
filter()
过滤器,用法和map类似。在函数中设定过滤的条件,逐一循环对象中的元素,将返回值为True时的元素留下(不是留下返回值),形成一个filter类型的迭代器。
def f1(x):
if x > 3:
return True
else:
return False
li = [1,2,3,4,5]
data = filter(f1,li)
print(type(data)) #输出<class 'filter'>
print(list(data)) #输出[4, 5]
zip()
组合对象,将对象逐一配对。
list_1 = [1,2,3]
list_2 = ['a','b','c']
s = zip(list_1,list_2)
print(list(s)) #输出[(1, 'a'), (2, 'b'), (3, 'c')]
组合3个对象
list_1 = [1,2,3]
list_2 = ['a','b','c','d']
list_3 = ['aa','bb','cc','dd']
s = zip(list_1,list_2,list_3)
print(list(s)) #输出:[(1, 'a', 'aa'), (2, 'b', 'bb'), (3, 'c', 'cc')]
长度不一致,多余的会被抛弃,以最短的为基础
list_1 = [1,2,3]
list_2 = ['a','b','c','d']
s = zip(list_1,list_2)
print(list(s))#输出[(1, 'a'), (2, 'b'), (3, 'c')]
具体例子:
filter()
输出大于22,普通方法: def f1(args): result = [] for item in args: if item >22: result.append(item) return result li =[11,22,33,44,55] ret =f1(li) print(ret) #输出大于22,filter()方法 # filter(函数,可迭代的对象) def f2(a): if a>22: return True li = [11,22,33,44,55,66] #filter内部,循环第二个参数,让每一个循环元素执行函数,如果函数返回值True,表示元素合法; ret=filter(f2,li) print(list(ret))
#filter的lambda形式 ;
li = [11,22,33,44,55,66]
result = filter(lambda a:a>33,li)
print(list(result))
总结 : filter 函数返回True时,将元素添加到结果中;
map 将函数返回值添加到结果中;
chr()ASCII码
6位随机验证码
import rangdom
list = []
for i in range(6):
r = random.randrange(0,6)
if r == 2 or r == 4:
num = rangdom.randrange(0,10)
list.append(str(num))
else:
temp = random.randrange(65,91)
c = chr(temp)
list.append(c)
result ="".join(list)
print(result)
divmod()分页函数
#分页函数,同时获取商和余数 #共:97页,每页显示10条,需要多少页; r = divmod(97,10) print(r) 输出:(9,7)
n1,n2 =divmod(97,10) print(n1,n2) 输出:9 和 7
isinstance() 用于判断,对象是否是某个类的实例
#a是不是str的实例 a = "tian" r = isinstance(a,str) print(r) 输出:True
zip()函数将列表中的每一个元素单独放在一个列表中
#拿出下面列表中所有的字符串
l1 =["alex",11,22,33]
l2 =["is",11,22,33]
l3 =["sb",11,22,33]
r =zip(l1,l2,l3)
temp = list(r)[0]
ret =' '.join(temp)
print(ret)
#指定读取2个字符
f = open("test,log","r");
ret = read(2);
print(ret)
迭代器
在介绍迭代器之前,先说明下迭代的概念:
迭代--->通过for循环遍历对象的每一个元素的过程。
Python的for语法功能非常强大,可以遍历任何可迭代的对象。
迭代器是一种可以被遍历的对象,并且能作用于next()函数。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往后遍历不能回溯,不像列表,可以随时获取后面的数据,也可以返回头取前面的数据;
迭代器通常实现两个基本的方法:iter() 和 next()。字符串、列表、元组对象,自定义对象都可用于创建迭代器;
lis = [1,2,3,4]
it = iter(lis)
print(next(it))
#1
print(next(it))
#2
print(next(it))
#3
print(next(it))
#4
print(next(it))#当后面没有元素可以next的时候,报错
或者使用for循环遍历迭代器
lis = [1,2,3,4]
it = iter(lis) #创建迭代器对象
for x in it: #使用for循环遍历迭代对象
print(x,end=" ")
为了让自定义的类成为一个迭代器,需要在类里实现__iter()__和__next()__方法。
总结:Python的迭代器表示的是一个元素流,可用被next()函数调用并不断返回下一个元素,直到没有元素时抛出StopIteration错误。可用把这个元素流看做是一个有序序列,但却不能提前知道序列的长度,只能不断通过
next()函数得到下一个元素,所以迭代器可以节省内存和空间。
迭代器(Iterator)和可迭代(Iterable)的区别:
- 凡是可作用于for循环的对象都是可迭代类型;
- 凡是可作用于next()函数的对象都是迭代器类型;
- list、dict、str等是可迭代的但不是迭代器,因为next()函数无法调用它们。可以通过iter()函数将它们转换成迭代器;
- Python的for循环本质上就是通过不断调用next()函数实现的;
生成器
通过列表生成式,可以直接创建一个列表,但是受到内存限制,列表容量肯定是有限的。如果创建一个包含100万个元素的列表,不仅占用很大内存空间,且仅仅只访问前面几个元素,那么后面绝大多数元素占用的空间都白白浪费。
所以,如果列表元素可以按照某种算法推算出来,在循环过程中不断推算出后续的元素,这样就不比创建完整的list,从而节省大量的空间。在python中,这种一边循环一边计算的机制,称为生成器:generator。
python3中range()就是生成器;
创建生成器的方法有很多种,第一种最简单:
li =(i+1 for i in range(10))
print(li)
# <generator object <genexpr> at 0x00710648>
print(next(li)) #1
print(next(li)) #2
...
PS:把一个列表生成式[]改成(),就创建了一个generator;
生成器打印元素需要不断调用next(li)一个个元素打印,直到算到最后一个元素,没有更多元素时抛出StopIteration的错误;
使用for循环输出生成器元素
li = (i+1 for i in range(10))
for i in li:
print(i)
1
2
3
4
5
6
7
8
9
10
PS:使用for循环来迭代,不需要关心StopIteration的错误。
生成器非常强大,如果推算的算法比较复杂时,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现;
例如斐波那契数列,除第1个和第2个数外,任意一个数都是前两个数相加:
1,1,2,3,5,8,13,21,34, ...
def fib(max):
n,a,b = 0,0,1
while n<max:
print(b)
a,b = b,a+b
n+=1
fib(10)
将上面的函数变成生成器,只需要将print(b)改成yield就可以
def fib(max):
n,a,b = 0,0,1
while n<max:
yield b
a,b = b,a+b
n+=1
rest=fib(10)
print(rest)#<generator object fib at 0x021F05D0>
print(rest.__next__())
print(rest.__next__())
PS :函数里面加了yield就是一个生成器,此时使用函数的调用方式去调用就会返回个生成器对象:<generator object fib at 0x021F05D0>
在执行过程中冻结在yield这一步,且把yield后的值返回给外面next();
装饰器
装饰器从字面上理解,就是装饰对象的器件。可以在不修改原有代码的情况下,为被装饰的对象增加新的功能或者附加限制条件或者帮助输出。装饰器有很多种,有函数的装饰器,类装饰器。
体现在设计模式中的装饰模式,强调的是开放封闭原则。
装饰器语法--->@ + 函数名--->装饰器
@dec
def func():
pass
在进行装饰器的介绍之前,必须明确几个概率和原则:
Python程序是从上往下顺序执行的,而且遇到函数的定义代码块是不会立即执行,只有等到该函数别调用时,才会执行其内部的代码块。
def foo():
print("foo函数被运行了!")
#如果就这样,foo里的语句是不会被执行的,程序只是简单的将定义代码块读入内存中。
#foo() 只有调用了,才会执行。
由于顺序执行的原因,如果你真的对同一个函数定义了两次,那么后面的定义会覆盖前面的定义。因此,在Python中代码的放置位置是有区别的,不能随意摆放,通常函数体要放在调用的语句之前。
需要先搞清楚几样东西:函数名、函数体、返回值、函数的内存地址、函数名加括号、函数名被当作参数、函数名加括号被当成参数、返回函数名、返回函数名加括号。
def outer(func):
def inner():
print("我是内层函数!")
return inner
def foo():
print("我是原始函数!")
outer(foo)
outer(foo())
#函数名: foo、outer、inner
#函数体: 函数的整个代码结构
#返回值: return后面的表达式
#函数的内存地址:id(foo)、id(outer)等等
#函数名加括号:对函数进行调用,例如:foo()、outer(foo)
#函数名作为参数:outer(foo)中的foo本事是个函数,但作为参数被传递给了outer函数
#函数名加括号被当做参数:其实就是先调用了函数,再将它的返回值当做别的函数的参数,例如:outer(foo())
#返回函数名:return inner
#返回函数名加括号:return inner(),其实就是先执行inner函数,再将其返回值作为别的函数的返回值。
装饰器机制分析
下面以f1函数为例,对装饰器的运行机制进行分析:
def outer(func):
def inner(*args,**kwargs):
print('认证成功');
result = func(*args,**kwargs)
print('日志添加成功')
return result
return inner
@outer #装饰器
def f1(arg):
print(arg)
功能:
1、自动执行outer函数并且将其下面的函数名f1当作参数传递 ;
2、将outer函数返回值,重新赋值给f1 ;
例:


LOGIN_USER ={'is_login':False}
def outer(func):
def inner(*args,**kwargs):
if LOGIN_USER['is_login']:
r=func();
return r;
else:
print("请登录")
return inner
@outer
def order():
print('欢迎{0}登录'.format(LOGIN_USER['current_user']))
@outer
def changpwd():
print("欢迎{0}登录".format(LOGIN_USER['current_user']))
@outer
def manager():
print("欢迎{}登录".format(LOGIN_USER['current_user']))
def login(user,pwd):
if user =='tian' and pwd =='123':
LOGIN_USER['is_login'] =True;
LOGIN_USER['current_user']=user
print(LOGIN_USER)
manager();
def main():
while True:
inp = input("1:后台管理;2:登录\n")
if inp == '1':
manager()
elif inp=='2':
username = input("请输入用户名:").strip().lower();
pwd = input("请输入密码:")
login(username,pwd)
if __name__ == '__main__':
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号