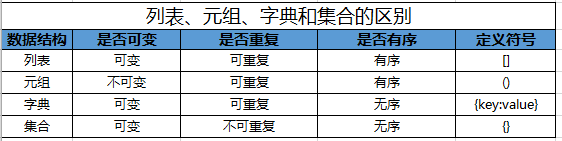
Python【第二篇】字符串、列表、元组、字典、集合
本节内容:
- pyc文件
- 字符串
- 列表操作
- 元组和字典
- 深浅copy
- 集合
一、pyc文件
都说解释器慢,Python也有想办法提高一下运行速度,那就是使用pyc文件。这点参考了JAVA的字节码做法,但并不完全类同。
我们编写的代码一般都会保存在以.py为后缀的文件中。在执行程序时,解释器逐行读取源代码并逐行解释运行。每执行一次,就重复一次这个过程,这其中耗费了大量的重复性的解释工作。为了减少这一重复性的解释工作,Python引入了pyc文件,pyc文件是将py文件的解释结果保存下来的文件,这样下次再运行的时候就不用再解释了,直接使用pyc文件就可以了,这无疑大大提高了程序运行速度。
对于pyc文件,必须知道以下几点:
- 对于当前调用的主程序不会生成pyc文件。
- 以import xxx或from xxx import xxx等方式导入主程序的模块才会生成pyc文件。
- 执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
- 每次使用pyc文件时,都会根据pyc文件的创建时间和源模块进行对比,如果源模块有修改,则重新创建pyc文件,并覆盖先前的pyc文件,如果没有修改,直接使用pyc文件代替模块。
- 代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
- pyc文件统一保存在模块所在目录的__pycache__文件夹内。
例子:
s2.py 和 s3.py,s3.py通过import导入s2.py后会生成对应的pyc文件,但是s3.py不会生成pyc文件

s2.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/3/7 14:10'
lit = list(range(1,101))
def countnumber():
sum1 = 0
sum2 = 0
for i in lit:
if i%2==0:
sum2+=i
else:
sum1+=i
sum =sum1-sum2
print(sum)
s3.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/3/7 14:54'
import s2
s2.countnumber()
二、字符串
字符串是Python中最常用的数据类型之一,使用单引号或双引号来创建字符串,使用三引号创建多行字符串;
字符串是一个有序的字符集合,用于存储和表示基本的文本信息。
特性:有序,不可变的序列类型(不能直接修改字符串本身);通过方括号加下标的方式,访问或者获取元素,当然也包括切片操作;
Python3全面支持Unicode编码,所有的字符串都是Unicode字符串,可以放心大胆的使用中文;
作用 ---> 名字,性别,籍贯,地址等描述信息
定义 ---> 通过单引号('..')或双引号("...")来定义,例如:name='test' 或者 name="test";
多行字符串使用三重引号:"""..."""或 '''...'''
book_str = '''
这是第一行
这是第二行
这是第三行
'''
必须优先掌握的字符串常用操作:
1、按索引取值(正向取+反向取) -->只能取
2、切片(顾头不顾尾,步长)
3、长度len
4、成员运算in和not in
5、移除空白 strip()
6、切分/分割split()
7、 find()查找字符串
8、 index()获取下标
9、 replce()替换字符串
10、len()返回字符串长度
11、lower()小写字符串
12、upper()大写字符串
13、startswith()字符串是否已xxx开头
14、endswith()字符串是否以xxx结尾
13、join()用于将序列中的元素已指定的字符串连接生成一个新的字符串
字符串颜色控制
有时候需要对有用的信息设置不同颜色来达到强调、凸出、美观的效果,在代码中用\033表示颜色;
格式:\033[显示方式;前景色;背景色m正文\033[0m ;

显示方式

例子:
import time
print('\033[1;31m')
print('登录信息'.center(46,"*"),'\033[0m')
print('\033[34m*HOST:\t','192.168.10.10')
print('*PORT:\t','80')
print('*User:\t','jack')
print('TIME:\t',time.strftime("%Y-%m-%d %X"))
print('\033[1;31m*'*50,'\033[0m')
print('\033[32m欢迎登录!\033[0m')
需要掌握的常用方法
strip(), lstrip(),rstrip()
lower(),upper()
startswith(),endswith()
format() 的三种玩法
split(),rsplit()
join()
replace()
isdigit()
例子
#strip() 默认移除左右两边空格
name = '*age**'
print(name.lstrip('*')) #去除字符串左边的*
# 输出age**
print(name.rstrip('*'))#去除字符串右边的*
#输出*age
print(name.strip('*'))#去除字符串左右两边的*
#输出age
#居中
names = 'alex li' ;
print(names.center(40,"-")) #居中
#判断有没有空格
print('' in names) #返回布尔类型
#lower,upper
name ='age'
print(name.lower()) #字符串小写
print(name.upper()) #字符串大写
#startswith,endswith
name ='jack_SB'
print(name.startswith('jack')) #字符串已jack开头 输出True
print(name.endswith('SB'))#字符串已SB结尾,输出True
#format字符串格式化的三种玩法
res = '{}{}{}'.format('tom',18,'alex') #输出:tom18alex
res_1 = '{1}{0}{1}'.format('tom',18,'alex')#输出:18tom18
res_2 = '{name}{age}{sex}'.format(sex='male',name='jack',age=25)#输出jack25male
#split
name = 'root:x:0:0::/root:/bin/bash'
print(name.split(':'))#默认分隔符为空格,
# 输出列表['root', 'x', '0', '0', '', '/root', '/bin/bash']
name_1 = 'C:/a/b/c/d.txt' #只想拿到顶级目录
print(name_1.split('/',1))#输出['C:', 'a/b/c/d.txt']把C:单独拿出来
name_2 ='a|b|c'
print(name_2.rsplit('|',1))#从右开始切分 输出['a|b', 'c']
#join将序列中的字符串元素拼接成字符串,可迭代对象必须都是字符串
tag = ' '
print(tag.join(['age','say','hello']))#输出:age say hello
#replace
name = 'jack sy:i have on tesla,my name is jack'
print(name.replace('jack','SB')) #将所有jack替换成SB
print(name.replace('jack','SB',1))#将第一个jack替换成SB
#isdigit,判断字符串是否为【数字】的方法
age = input(">>>:")
print(age.isdigit())
练习
# 写代码,有如下变量,请按照要求实现每个功能
name = " jackX"
# 1)移除 name 变量对应的值两边的空格,并输出处理结果
name = ' jackX'
a=name.strip()
print(a)
# 2) 判断 name 变量对应的值是否以 "ja" 开头,并输出结果
name='jackX'
if name.startswith('ja'):
print(name)
else:
print('no')
# 3) 判断 name 变量对应的值是否以 "X" 结尾,并输出结果
name='jackX'
if name.endswith('X'):
print(name)
else:
print('no')
# 4) 将 name 变量对应的值中的 “a” 替换为 “p”,并输出结果
name='jackX'
print(name.replace('a','p'))
# 5) 将 name 变量对应的值根据 “a” 分割,并输出结果。
name='jackX'
print(name.split('a'))
# 6) 将 name 变量对应的值变大写,并输出结果
name='jackX'
print(name.upper())
# 7) 将 name 变量对应的值变小写,并输出结果
name=' jackX'
print(name.lower())
# 8) 请输出 name 变量对应的值的第 2 个字符
name=' jackX'
print(name[1])
# 9) 请输出 name 变量对应的值的前 3 个字符?
name=' jackX'
print(name[:3])
# 10) 请输出 name 变量对应的值的后 2 个字符?
name=' jackX'
print(name[-2:])
# 11) 请输出 name 变量对应的值中 “k” 所在索引位置?
name=' jackX'
print(name.index('k'))
# 12) 获取子序列,去掉最后一个字符。如: oldboy 则获取 oldbo。
name=' jackX'
a=name[:-1]
print(a)
4、列表list
列表是Python中最基本也是最常用的数据结构之一。列表中的每个元素都被分配一个数字作为索引,用来表示该元素在列表内所排在的位置 。第一个元素的索引是0,第二个索引是1,依次类推。
Python的列表是一个有序可重复的元素集合,可嵌套、迭代、修改、分片、追加、删除、成员判断。
从数据结构角度看,Python的列表是一个可变长度的顺序存储结构,每个位置存放的都是对象指针。
特性:
有序,支持嵌套,可变类型,通过切片索引读取数据。
列表基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 循环
- 包含
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
lis = [] #创建一个空列表
list1 = ['python','chemistry',2003,1000]
list2 = [1,2,3,4,5,6]
list3 = ['a','b','c','d']
list4 = [1,'a',[11,22],{"k1":"v1"}]
列表使用:
列表从0开始为每一个元素顺序创建下标索引,直到总长度减一。要访问它的某个元素,以方括号加下标值的方式即可。注意要确保索引不越界,如果访问的索引超过范围,会抛出异常。所以,一定要记得最后一个元素的索引是len(list)-1
#读取访问列表中的值
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5, 6, 7]
print ("list1[0]: ", list1[0])
print ("list2[1:5]: ", list2[1:5])
print ("list2[1:5:2]",list2[1:5:2]) #隔一个元素输出
#切片
# 切片指的是对序列进行截取,选取序列中的某一段。切片的语法是:list[start:end],以冒号分隔索引,start代表起点索引,end代表结束点索引。省略start表示0开始,省略end表示到列表的结尾。区间是左闭右开,也就是说[1:4]。
# 截取列表的索引为1/2/3的3个元素,不会截取索引为4的元素。分片不会修改原有的列表,可以将结果保存到新的变量,因此切片也是一种安全操作,常被用来复制,例如newlist = list[:]。
# 如果提供的是负整数下标,则从列表的最后开始往头部查找。例如-1表示最后一个元素,-3表示倒数第三个元素。
# 切片过程中还可以设置步长,已第二个冒号分隔,例如list[3:9:2],表示每隔多少距离取一个元素。
a = [1,2,3,4,5,6,7,8,9,10]
print(a[3:6])
print(a[:7])
s= a[:]
print(s)
s.remove(4)
print(s)
print(a[-1])
print(a[-3])
print(a[-5:])
print(a[1:8:2])
print(a[1:8:-2])
print(a[-8::-2])
print(a[-8::2])
多维列表(嵌套列表)
列表可以嵌套列表,形成多维列表,形如矩阵。其元素的引用方法是list[i][j][k]..... 当然也可以嵌套别的数据类型。
a = [[1,2,3],[4,5,6],[7,8,9]]
print(a[0][1])
a1 = [[1,2,3],[4,5,6],[7,8,9],{'k1':'v1'}]
print(a1[3]['k1'])
#列表的遍历
a = [1,2,3,4,5,6]
for i in a: #遍历每一个元素本身
print(i)
for i in range(len(a)):#遍历列表下标,通过下标标取值
print(i,a[i])
x = 9
if x in a: #进行是否属于列表成员的判断,该运算速度非常快
print("True")
else:
print("False")
#更新列表中的值 list1 = ['physics', 'chemistry', 1997, 2000]; list1[2] = 2001; #添加元素 append()方法 --->默认添加元素到列表最后 #删除列表元素(下标) list1 = ['physics', 'chemistry', 1997, 2000]; del list1[1] #删除指定索引上面的元素 del list1[2:3] #删除列表元素(下标,默认删除最后一个且获取删除值) list1.pop();#默认删除最后一个元素 name=list1.pop(1)#删除下标1上的元素,且获取删除值 #删除列表元素(元素名称) list1.remoe('physics')
列表的特殊操作
print([1,2,3] +[4,5,6]) #组合两个列表
print(['Hi']*4)#列表的乘法
print(3 in [1,2,3]) #判断元素是否存在列表中
for x in [1,2,3]:print(x)#迭代列表中的每个元素
针对列表常用的函数
Python 有很多内置的函数,可以操作列表。
len(list) 返回列表元素个数,也就是获取列表长度。
max(list) 返回列表元素最大值
min(list) 返回列表元素最小值
list(seq) 将序列转换为列表
count(obj) 统计某个元素在列表中出现的次数
append(obj) 在类别未尾添加新的对象
extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
index(obj) 从列表中找出某个值第一个匹配项的索引位置
insert(index,obj) 将对象插入列表
pop(obj=list[-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
remove(obj) 移除列表中某个值的第一个匹配项
reverse() 反向列表中元素
sort([func]) 对原列表进行排序
copy() 复制列表
clear() 清空列表,等于del lis[:]
lis = ['a','b','c','d']
lis.append("A")
print(lis)
print(lis.count("a"))
lis.extend(["a","b"])
print(lis)
print(lis.index("b"))
print(lis.index("A"))
lis.insert(3,"E")
print(lis)
print(lis.pop())
lis.remove("c")
print(lis)
newlis = lis.copy()
print("newlis",newlis)
newlis.clear()
print(newlis)
lis.sort()
print(lis)
注意:其中append,insert,remove,reverse,pop或者sort等方法会修改列表本身,并且没有返回值(严格的说是返回None)
将列表当成堆栈
Python的列表特别合适、方便作为一个堆栈来使用。堆栈是一种特定的数据结构,最先进入的元素最后一个被释放(后进先出)。将列表的表头作为栈底,表尾作为栈顶,就形成了一个堆栈。用列表的append()方法可以把一个元素添加到堆栈
顶部,用不指定索引的pop()方法可以把一个元素重堆栈顶释放出来(也就是从列表尾部弹出一个元素)
例如:
stack = [3,4,5]
stack.append(6)
stack.append(7)
print(stack)
stack.pop()
print(stack)
stack.pop()
print(stack)
将列表当作队列
也可以把列表当成队列用。队列是一种先进先出的数据结构,但是用Python的列表做队列的效率并不高。
练习题: 1、#将列表中所有9的元素修改为9999 name = ["tian","xiang",9,"tianxiang","li","xiang","xiang","zhang",9,"sang","hehe"]; for i in range(name.count(9)): ele_index = name.index(9); name[ele_index]= 9999; 2、#将列表中所有9999的元素删除 for i in range(name.count(9999)): ele_index = name.index(9999); del name[ele_index]; print(name) 3、#所有元素翻倍 bag = [1,2,3,4,5,6] bag = [elem*2 for elem in bag] print(bag)#[2, 4, 6, 8, 10, 12] 4、#使用库来统计列表中每个元素出现的次数 from collections import Counter bag =[2,3,4,5,5,7,8,9,2,7] countr = Counter(bag) for i in range(len(bag)): print(i) 5、现有商品列表如下: products = [['iphone8',6888],['小米6',2466],['coffee',31],['Nike Shose',799]] 打印如下格式: ---------商品-------- 0.iphone8 6888 1.小米6 2466 2.coffee 31 3.Nike Shose 799 实现代码: for index,p in enumerate(products): print("{0}. {1} {2}".format(index,p[0],p[1])) 6、循环购买商品 需求: 用户输入商品编号,将商品添加到购物车中 用户输入q退出循环,且打印购物车中商品列表 products = [['iphone8',6888],['小米6',2466],['coffee',31],['Nike Shose',799]] shooping_cart = [] while True: print("---------商品--------") for index,p in enumerate(products): print("{0}.{1} {2}".format(index,p[0],p[1])) choice = input(">>>请输入商品编号,输入q退出:").strip() if choice.isdigit(): choice = int(choice) if choice >=0 and choice <len(products): shooping_cart.append(products[choice]) print("将商品 {0} 添加到购物车".format(products[choice])) else: print("商品不存在") continue elif choice=='q': if len(shooping_cart)>0: print("------您已购买以下商品------") for index,p in enumerate(shooping_cart): print("{0}.{1} {2}".format(index,p[0],p[1])) break 7、#两个字符串合并为1个列表 L2 = 'ABCDEFG' L3 = 'abcdef' blist = [] for m,n in zip(L2,L3): blist.append(m) blist.append(n) print(blist) 8、把两个字典的key()或者values(),分别对应输出到列表中可以用同样的方法: L2 = {'1':'A','2':'B','3':'C','4':'D'} L3 = {'5':'a','6':'b','7':'c','8':'d'} blist = [] for m,n in zip(L2.values(),L3.values()): print(m,n) blist.append(m) blist.append(n) print('字典L1的值对应字典L2的值输出:',blist)
9、列表推导式
作用:使用列表推导式生成指定列表或根据现列表根据某些条件生成新列表。有三种用法场景。
9.1、生成指定范围的数值列表:语法格式:list = [Expression for var in rang]
例如:生成包含10个随机数的列表,要求数据范围在10到100(包括)之间
li = [random.randint(10,100) for i in range(10)]
print(li)
9.2、根据列表生成指定需求的列表:语法格式:newlist = [Expression for var in list]
例如:定义一个记录商品价格的列表,然后应用列表推导式生成一个将全部商品价格打五折的列表
price = [888,500,652,75]
sale = [int(i*0.5) for i in price]
print(sale)
9.3、从列表中返回条件的元素组成新的列表:语法格式:newlist =[Expression for var in list if condition]
例如:定义一个列表记录商品价格,然后用列表推导式生成一个商品价格高于5000的列表
price_1 =[1200,5300,2988,6200,150]
sale_1 = [x for x in price_1 if x>5000]
print("原列表:,price_1)
print("价格高于5000的:",sale)
列表综合练习题
#需求1:管理qq好友且打印出来
fellow = ['李二牛','张三丰','韩信','刘邦']
print("********我的好友**********")
print(fellow[0])
print(fellow[1])
print(fellow[2])
print(fellow[3])
#需求2:删除和添加qq好友
fellow = ['李二牛','张三丰','韩信','刘邦']
print("********我的好友**********")
for i in fellow:
print(i)
print("********我的好友**********")
fellow.remove('韩信')
fellow.remove('张三丰')
for j in fellow:
print(j)
#需求3,qq好有添加备注
fellow = ['李二牛','张三丰','韩信','刘邦']
print("********我的好友**********")
print("{0} {1}".format(fellow[0],'Svip'))
print("{0} {1}".format(fellow[1],'Svip'))
print("{0} {1}".format(fellow[2],'Svip'))
#需求4,统计qq好友并排序
fellow = ['李二牛','张三丰','韩信','刘邦']
print("********我的好友**********")
print("我的好友共计:{0}人".format(len(fellow)))
fellow.sort()
print(fellow) #升序
fellow.sort(reverse=True)#降序
print(fellow)
#5、编写一个程序把最喜欢的5首歌输入到列表,然后输出。然后为其中一首歌添加歌手信息
mysone = input("请输入你喜欢的歌曲:")
mylist = [mysone]
mysong = input("请输入你喜欢的歌曲:")
mylist.append(mysong)
mysong = input("请输入你喜欢的歌曲:")
mylist.append(mysong)
mysong = input("请输入你喜欢的歌曲:")
mylist.append(mysong)
mysong = input("请输入你喜欢的歌曲:")
mylist.append(mysong)
print(mylist)
mylist[1] ="{0} 作者:{1}".format(mylist[1],"成龙")
print(mylist)
#需求7,解决千年虫问题
year = [89,98,00,75,68,37,58,90]
for index,value in enumerate(year):
if str(value)!='0':
year[index] ="19{0}".format(value)
else:
year[index] ="200{0}".format(value)
year.sort()
print(year)
#需求8,创建qq周报将上周和本周运动周报相加,例如:上周1 + 本周1 ,上周2+本周2 依次类推
thisweek = [4235,10111,8447,9566,9788,8951,9808] #本周运动周报
lastweekon = [4235,5612,8447,11250,9211,9985,3783] #上周运动周报
sumweek = []
for a,b in zip(thisweek,lastweekon):
sum1 = a +b
sumweek.append(sum1)
sumweek.sort()
print("升序",sumweek)
sumweek.sort(reverse=True)
print("降序",sumweek)
#需求9,将一周内的最大值和最小值插入对应星期元素的后面
day = ['周日','周一','周二','周三','周四','周五','周六']
thisweek = [4235,10111,8447,9566,9788,8951,980833]
x = thisweek.index(max(thisweek))
print("x是多啊啊",x)
y = thisweek.index(min(thisweek))
print("y是都是啊",y)
print("max最大值是",max(thisweek))
day.insert(x+1,max(thisweek))
day.insert(y+1,min(thisweek))
print(day)
#需求10 步数超过8000步即为达标,分别输出本周,上周高于8000步的步数值和日期,最后输出上周和本周总步数
thisweek = [4235,10111,8447,9566,9788,8951,9808]
weekday = ['周日','周一','周二','周三','周四','周五','周六']
thislist1 = []
thislist2 = []
for itme in thisweek:
if itme > 8000:
thislist1.append(itme)
i = thisweek.index(itme)
thislist2.append(weekday[i])
print("本周高于8000步的步数值:",thislist1)
print("本周高于8000步的日期",thislist2)
#上周高于8000步的步数值和日期
lastweekon = [4235,5612,8447,11250,9211,9985,3783]
lastlist1 = []
lastlist2 = []
for item in lastweekon:
if item > 8000:
lastlist1.append(item)
i = lastweekon.index(item)
lastlist2.append(weekday[i])
print("上周高于8000步的步数值:",lastlist1)
print("上周高于8000步的日期",lastlist2)
print("上周和本周大于8000步的总和:{0}".format(sum(lastlist1+thislist1)))
#循环嵌套列表推导式,先遍历列表a在遍历字符串b,对a有一个条件判断
a = [-3,-2,1,3,5,7,9,10]
b = 'abc'
d = [(x,y) for x in a
for y in b
if x > 0 ]
print(d)
#循环过程中删除列表元素引发bug
data = [11,22,33,44,55,66,77,88]
for i in data:
if i==33 or i==44:
data.remove(i)
print(data)
#错误44没有被删除,因为这个列表中,33被删除后,后面的元素前移,又因为44紧接着33,所以判断44时,已经发送变化,44被忽略了
#修改方法,将要被删除的元素存储在一个临时列表中。
data_1 = [11,22,33,44,55,66,77,88]
list_temp = []
for j in data_1:
if j==33 or j==44:
list_temp.append(j)
print("需要删除的列表中",list_temp)
for h in list_temp:
if h==33 or h==44:
data_1.remove(h)
print("最后的值:",data_1)
#生成一组1-10之间不重复的四位验证码
import random
list = [i for i in range(1,9)]
list_1 = random.sample(list,4)
list_2 = [str(x) for xin list_1]
print("".join(list_2))
元组(Tuple又称不可变列表)
元组也是序列结构,但是是一种不可变序列,简单理解为内容不可变的列表,除了在内部元素不可修改的区别外,元组和列表的用法差不多。
元组和列表相同的操作:
- 使用方括号加下标访问元素
- 切片(形成新元组对象)
- count()和index()
- len()、max()、min()、tuple()
元组中不允许的操作(元组中没有的功能)
- 修改、新增元素
- 删除某个元素(但可以删除整个元组)
- 所有会对元组内部元素发生修改动作的方法。例如,元组没有remove,append,pop等方法。
作用:如果一些数据不想被人修改, 可以存成元组,比如身份证列表
创建元组
tup1 = ()
元组中包含一个元素时,需要在元素后面添加逗号
tup1 =(50,)
元组常用功能:
- 读取元组(通过索引)
- 删除元组(元素是不允许删除,使用del删除整个元组)
元组只保证它的一级子元素不可变,对于嵌套的元素内部,不保证不可变
tup = ('a','b',['A','B'])
tup[2][0] = 'x'
tup[2][1] = 'Y'
print(tup)
所以在使用元组的时候,尽量使用数字、字符串和元组这种不可变的数据类型作为元组的元素,这样就能确保元组不发生变化。
字典(Dictionary)
使用场景:字典看似简单,实际使用起来博大精深、灵活万变、特别合适存储那些需要一一对应的数据类型。但是它的无序特点,在很多时候又让人非常头疼,因此Python内置一个collections标准库,在这里有一个OrderedDict
有序字典类,可以实现字典的有序控制;
字典是另一种可变容器模型,且可存储任意类型的对象。采用键值对(key:value)的形式,根据key的值计算value的地址,具有非常快的查取和插入速度,但它是无序的,包含的元素个数不限,值的类型也可以是其它任何数据类型;
- 特性:
- 无顺序
- 去重
- 查询速度快,比列表快多了
- 比list占用内存多
字典的每个键值(key===>value)用冒号(:)分割,每个对之间用逗号(,)分割,整个字典都包括在花括号中;
d ={key1 : value1 , key2 : value2}
键必须是唯一的,但值则不必;
值可以取如何数据类型,但键必须是不可变的,如字符串、数字或元组。
一个简单的字典实例:
dict={"Alice" :"2341,"Beth" :"9102"}
字典的基本操作
id_db= {
37788888:{
'name':'tianxinag',
'age' : 25,
'addr':'陕西'
},
22999332:{
'name':'山炮',
'age' : 26,
'addr':'河南'
},
2299933:{
'name':'二炮',
'age' : 31,
'addr':'河北'
}
}
#添加
id_db[229944]="苍井空"
id_db[2299933]['qq_of_wife'] = 3888899
#修改
id_db[2299933]['name']='张三'
#删除
del id_db[2299933]['addr'] #删除
id_db[2299933].pop('addr') #删除二
#查找
info ={'student01:'zhngshan','student02':'lishi','student03':'wangwu'}
>>>"student01" in info #标准用法
True
>>>info.get('student02') #获取
lishi
>>>info['student02'] #获取
lishi
>>>info['student05'] #如果一个key不存在,就报错,get不会报错,返回None
dic2 ={
'name':'zhanganngn',
37788888:{
'name':'wangwnang',
'age' : 25,
'addr':'陕西'
},
}
id_db.update(dic2) #覆盖
print(id_db)
#循环
for k,v in id_db.items(): #同时获取字典key和values效率低,小数据这么写
print(k,v)
#循环2
for key in id_db: #同时获取字典key和values,这样写效率高;
print(key,id_db[key])
多级字典嵌套及操作
data ={
"广东":{
"广州":{
"番禺":["市桥","易发街"],
"海珠":["客村","客村立交"],
"天河":["珠江新城","广州塔"]},
"深圳":{
"宝安":["福永镇","富士康"],
"布吉":["观澜","本田汽车"],}
},
"陕西":{
"西安":{
"咸阳":["机场","机场快线"],
},
"汉中":{
"洋县":["城管","唐塔路"],
"城固":["机场","汉中机场"]
},
"宝鸡":{
"三水":["家具城","汽车城"]},},}
data['陕西']['宝鸡']['三水'][1]+="可以用爬虫" #将可以爬虫【添加到】汽车城后面
print(data["陕西"]["宝鸡"]["三水"])
输出:['家具城', '汽车城可以用爬虫']
#其它姿势
#values
data.values() #输出字典values
#keys
data.keys() #输出字典keys
深浅copy
import copy
#浅copy
n1 =['tianxiang','jack',11,222,33]
n3 =copy.copy(n1)
n1[1]="Tian"
print(n1)
print(n3)
输出:"列表n1" --->['tianxiang', 'Tian', 11, 222, 33]
"列表n3" --->['tianxiang', 'jack', 11, 222, 33]
# 浅copy后,两个列表是相互独立的,修改其中任何一个列表,对另一个列表没有任何影响;
#浅copy默认只能copy一层,遇到列表中嵌套列表,只能copy嵌套列表中的内存地址,需要使用深copy;
n2 =["tianxiang","jack",11,222,33,[1,2,3]]
n5 =copy.deepcopy(n2) #深copy后,修改列表中嵌套的列表元素值,相互不影响;
n5[5][0]=11
print(n2)
print(n5)
输出:
['tianxiang', 'jack', 11, 222, 33, [1, 2, 3]]
['tianxiang', 'jack', 11, 222, 33, [11, 2, 3]]
deepcopy列表中嵌套列表,两个列表相互独立,修改元素互相不影响;
例如:列表中嵌套列表使用浅copy,修改元素会同时修改两个列表中的元素,所有不能使用浅copy
n2 =["tianxiang","jack",11,222,33,[1,2,3]]
n2 =["tianxiang","jack",11,222,33,[1,2,3]]
n5 =copy.copy(n2) #浅copy后,修改copy后的列表中嵌套列表元素,会同时修改原列表中列表元素;
n5[5][0]=11
print(n2)
print(n5)
输出: ['tianxiang', 'jack', 11, 222, 33, [11, 2, 3]]
['tianxiang', 'jack', 11, 222, 33, [11, 2, 3]]
ps:列表或字典中,存在嵌套关系时,想通过copy获得两份完全独立的列表或字典,必须使用【deepcopy】,因为浅copy只copy了嵌套列表或字典中的内存地址,修改新列表或字典嵌套元素中的值,会同时更新原列表或元素嵌套中的值;
列表或字典中,没有嵌套关系时,使用浅copy就可以了;
str、list、dict、tuple 更优用法
1、将list中每个元素赋值给一个变量
name,age,date = ['Bob',20,'2018-1-29']
2、同时获取下标和元素,输出为元组
a,b,c = enumerate(['a','b','c'])
print(a,b,c)
#输出(0, 'a') (1, 'b') (2, 'c')
3、元组中每个元素赋值给一个变量
a,b,c = ('a','b','c')
print(a,b,c)
#a b c
4、字典每个元素赋值给一个变量
a,b,c = {'a':1,'b':2,'c':3}
print(a,b,c) #输出key
#c a b
5、字符串中每个元素赋值给一个变量
a,b,c = 'abc'
print(a,b,c)
#a b c
6、生成器
#生成器
a,b,c =[ x + 1 for x in range(3)]
print(a,b,c)#1 2 3
如果可迭代对象包含的元素和前面赋值变量数量不一致,则会报错。但是可用通过*来表示多个元素。
7、星号的使用
first,*new,last = [94,85,73,46]
print(new)#输出[85,73]
8、压包过程 使用zip函数实现
a = ['a','b','c']
b = [1,2,3]
for i in zip(a,b):
print(i)
#输出:('a', 1)('b', 2)('c', 3)
9、压包和解包混合使用
两个列表相加,元素必须都为int类型
a = [2,3,4]
b = [1,2,3]
for i,j in zip(a,b):
print(i+j)
#输出:3,5,7
set集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了;
- 关系测试,测试两组数据之前的交集、差集、并集等关系
- 集合是无序的
优先掌握操作:
1、长度len
2、成员运算in和not in
3、|合集 &交集 -差集 ^对称差集
list_1 = [1,4,5,6,7,8,7,9]
list_1 =set(list_1) #去重
print(list_1)
list_2 = set([2,6,0,66,22,8,4])
#交集
list_3 = list_1 & list_2 # list_1 和 list_2的交集
#并集,元素不重复
list_5 =list_1 | list_2
#求差集()
list_6 =list_1 - list2 #在list_1中,但不在list_2中
#对称差集
list_7 = list_1 ^ list_2 # 在list_1或list_2中,但不会同时出现在二者中;
#基本操作
list_1.add(999) #添加一项元素
list_1.update([55,77,888]) #添加多项
#remove()可以删除一项
list_1.remove('999')
len(list_1) #长度
list_1 in list_2
#list_1是否是 list_2的成员
加强训练习题
关系运算:
有两个结合,pythons和linuxs分别为python课程和linux课程
pythons = {'django','scrapy','html','mysql','CSS'}
linuxs = {'django','django','vi'}
1、求出即学了pythons又报名linuxs的课程名
2、求出所有课程的名字集合
3、求出只在pythons中的课程
4、求出没有同时在pythons和linuxs中的课程
pythons = {'django','scrapy','html','mysql','CSS'}
linuxs = {'django','django','vi'}
#求出即在pythons又在linuxs中的课程
print(pythons & linuxs)
#输出:{'django'}
#求出所有的课程,去重
print(pythons | linuxs)
#输出{'CSS', 'vi', 'scrapy', 'mysql', 'html', 'django'}
#求出只在pythons中的课程
print(pythons - linuxs)
#输出:{'scrapy', 'html', 'mysql', 'CSS'}
#求出没有同时存在pythons和linuxs中的课程
print(pythons ^ linuxs)
#{'vi', 'scrapy', 'html', 'mysql', 'CSS'}
去重
#去重,不用保持原来顺序
l = [1,'a','b',1,'a']
print(set(l)) #去重
#去重,并保持原来的顺序
#方法一:不用集合
l2 = [1,'a','b',1,'a']
li = []
for i in l2:
if i not in li:
li.append(i)
print(li)
#方法二:用集合
l3 =[]
s =set()
for i in l2:
if i not in s:
s.add(i)
l3.append(i)
print(l3)
#同上方法,去除文件中重复行
import os
with open('db.txt','r',encoding='utf-8') as read_f,open('.db.txt.swap','w',encoding='utf-8') as write_f:
s=set()
for line in read_f:
if line not in s:
s.add(line)
write_f.write(line)
os.remove('db.txt')
os.rename('.db.txt.swap','db.txt')
#列表中元素为可变类型,去重,保持原来顺序
l=[
{'name':'egon','age':18,'sex':'male'},
{'name':'alex','age':73,'sex':'male'},
{'name':'egon','age':20,'sex':'female'},
{'name':'egon','age':18,'sex':'male'},
{'name':'egon','age':18,'sex':'male'},
]
s = set()
l1 = []
for item in l:
val =(item['name'],item['age'],item['sex'])
print(val)
if val not in s:
s.add(val)
l1.append(item)
print(l1)
