Beautifulsoup模块
查看目录
- 介绍
- 基本使用
- 遍历文档树
- 搜索文档树
- 总结
- 实例
介绍
BeautifulSoup是Python的一个库,最主要的功能就是从网页上爬取需要的数据。BeautifulSoup将html解析为对象进行处理,全部页面转变为字典或列表,相对于正则表达式的方式,大大简化处理过程。
目前Beautiful Soup3已经停止开发,官网推荐使用Beautiful Soup4 已经移值到bs4
安装 Beautiful Soup
pip3 install Beautifulsoup4
#安装解释器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是lxml,根据操作系统不同,可以选择下列方式来安装;
pip3 install lxml
Beautifulsoup默认支持Python的标准HTML解析库,还支持一些第三方解析库,下面列出主要解析器的优缺点;
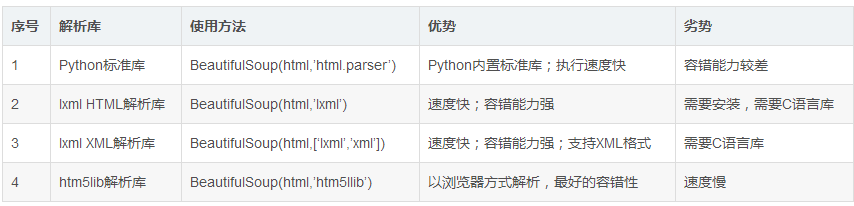
Beautifulsoup中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
基本使用
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#基本使用:容错处理,文档的容错能力指的是在html代码不完整的情况下,使用该模块可以识别该错误。使用BeautifulSoup解析上述代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc,'lxml') #具有容错功能
res=soup.prettify() #处理好缩进,结构化显示
print(soup.title) #<title>The Dormouse's story</title>
print(soup.title.name)#打印标签名title
print(soup.title.string)#打印标签中的值:The Dormouse's story
print(soup.title.parent.name)#title上级标签
print(soup.p) #<p class="title"><b>The Dormouse's story</b></p>
print(soup.p['class'])#['title']
print(soup.a) #<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>
print(soup.find_all('a'))#所有a标签放到list中
print(soup.find(id="link3"))#id="link3"的标签
#文档中找到所有<a>标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
#从文档中获取所有文字内容
print(soup.get_text())
# The Dormouse's story
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
遍历文档树
遍历文档树:直接通过标签名字选择,特点是选择速度快,但如果存在多个相同的标签时只返回第一个
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#1、用法
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc,'lxml')
print(soup.p) #存在多个相同标签则只返回第一个
print(soup.a) #存在多个相同的标签则只返回第一个
#2、获取标签的名称
print(soup.p.name) #p
#3、获取标签属性
print(soup.p.attrs)#{'class': ['title']}
#4、获取标签的内容
print(soup.p.string) #p标签下的文本,没有文本就为None
print(soup.p.strings)#对象,取到p下所有的文本内容
print(soup.p.text) #取到p下所有的文本内容
for line in soup.stripped_strings: #去掉空白
print(line) #打印所有字符串
#5、嵌套选择
print(soup.head.title.string)
print(soup.body.a.sting)#None,a标签没有字符串
#6、子节点、子孙节点
print(soup.p.centents)
print(soup.p.children)
for i,child in enumerate(soup.p.children):
print(i,child)
print(soup.p.descendants)#获取子孙节点,p下面所有的标签都会选择出来
for i,child in enumerate(soup.p.descendants):
print(i,child)
#7、父节点、祖先节点
print(soup.a.parent) #获取a标签的父节点
print(soup.a.parents) #找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲...
#8、兄弟节点
print(soup.a.next_sibling) #下一个兄弟
print(soup.a.previous_sibling) #上一个兄弟
print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象
print(soup.a.previous_siblings) #上面的兄弟们=>生成器对象
搜索文档树
1、过滤器
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#1、用法
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc,'lxml')
#1、五种过滤器:字符串、正则、列表、True、方法
#1.1、字符串:即标签名
print(soup.find_all('b'))
#1.2、正则表达式
import re
print(soup.find_all(re.compile('^b'))) #找出b开头的标签,结果有body和b标签
#1.3、列表:如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回,下面代码找到文档中所有<a>标签和<b>标签
print(soup.find_all(['a','b']))
#1.4 True:可以匹配任何值,下面代码查找到所有tag,但是不会返回字符串节点
print(soup.find_all(True))
for tag in soup.find_all(True):
print(tag.name)
#1.5、方法:如果没有合适过滤器,还可以定义一个方法,方法只接受一个元素参数,如果这个方法返回True表示当前元素匹配并且被找到,如果不是则返回False
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
print(soup.find_all(has_class_but_no_id))
CSS选择器
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title">
<b>The Dormouse's story</b>
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
<div class='panel-1'>
<ul class='list' id='list-1'>
<li class='element'>Foo</li>
<li class='element'>Bar</li>
<li class='element'>Jay</li>
</ul>
<ul class='list list-small' id='list-2'>
<li class='element'><h1 class='yyyy'>Foo</h1></li>
<li class='element xxx'>Bar</li>
<li class='element'>Jay</li>
</ul>
</div>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
#1、用法
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc,'lxml')
#1、CSS选择器
print(soup.p.select('.sister'))
print(soup.select('.sister span'))
print(soup.select('#link1'))
print(soup.select("#link1 span"))
print(soup.select("#list-2 .element.xxx"))
print(soup.select("#list-2")[0].select('.element'))
# 2、获取属性
print(soup.select('#list-2 h1')[0].attrs)
#3、获取内容
print(soup.select('#list-2 h1')[0].get_text())
修改文档树:链接:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id40
总结:
1、推荐使用lxml解析库
2、选择器:标签选择器、find与find_all ,css选择器 , 建议使用css选择器
3、获取属性attrs和文本值get_text()的方法
实例
需求:获取京东图书【计算机与互联网】销量榜中图书名称、作者、前100名图书价格、出版社等信息保存到列表且打印出来;
获取图书评价内容,统计好评率、差评率、中评率,全部率;
#!/usr/bin/env python # -*- coding: utf-8 -*- __author__ = 'tian' __data__ = '2019/5/21 14:49' import requests import json import re from bs4 import BeautifulSoup #解析HTML模块 rankings_list = [] #保存排行数据的列表 class Crawl: def __init__(self): self.url = "https://book.jd.com/booktop/0-0-0.html?category=3287-0-0-0-10001-{page}" self.headers = {'user-agent': 'Mozilla/5.0(Windows NT 6.1;Win64;x64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/71.0.3578.98 Safari/537.36'} self.book_name_list = [] #保存图书名称的列表 self.press_list = [] #保存出版社列表 self.item_url_list = []#保存排行中每本书的地址 self.jd_id_list = [] #保存京东id的列表 def get_rankings(self): #网页的页数 page = 1 #将100个京东商品的id组建成一个字符串 self.jd_id_str_100 = '' while True: if page == 6:break #发送网络请求,获取服务器响应 response = requests.get(self.url.format(page=page),headers = self.headers) response.encoding = 'GBK' html = BeautifulSoup(response.text,'lxml') #解析html代码,需要安装lxml库 #获取图书所有的信息 book_list = html.find('div',{'class','m m-list'}).select('li') page += 1 #每页20个京东id jd_id_str_20 = '' for i in book_list: jd_id = i.find('a',{'class','btn btn-default follow'}).get('data-id')#获取图书的id book_name = i.find('a',{'class','p-name'}).text #获取图书名称 prees = i.find('div',{'class','p-detail'}).find_all('dl')[1].dd.text #获取出版社 #获取图书对应的详情页地址 item_url = i.find('div',{'class','p-img'}).find('a').get('href') item_url = "http:{0}".format(item_url)#组建完整的详情页地址 self.book_name_list.append(book_name) #将图书名称添加到列表 self.press_list.append(prees)#将出版社添加至列表 self.item_url_list.append(item_url)#将详情页地址添加到列表 self.jd_id_list.append(jd_id) #将排行中每本图书的京东id添加到列表 #京东商品id jd_id_str = 'J_{0},'.format(jd_id) jd_id_str_20 += jd_id_str #将获取到的100个京东id连接成字符串作为获取价格的请求参数 self.jd_id_str_100 += jd_id_str_20 # print(self.jd_id_list) # print(self.book_name_list) # print(self.press_list) # print(self.item_url_list) print("获取都的jd_id_list",self.jd_id_list) return self.jd_id_str_100 #获取前100名图书价格 def get_price(self,id): rankings_list.clear() #清空排行榜数据列表 price_url = 'http://p.3.cn/prices/mgets?type=1&skuIds={id_str}' #获取价格的网络请求地址 response = requests.get(price_url.format(id_str=id)) #将京东id作为参数发送获取前100名图书价格 price = response.json() #获取价格json数据,该数据为list类型 for index,item in enumerate(price): #书名 book_name = self.book_name_list[index] #出版社 press = self.press_list[index] #京东价格 jd_price = item['op'] #定价 ding_price = item['m'] #每本书的地址 item_url = self.item_url_list[index] #每本书的京东id jd_id = self.jd_id_list[index] #将所有的数据添加到列表 rankings_list.append((index+1,book_name,jd_price,ding_price,press,item_url,jd_id)) #获取评价内容,score参数差评1、中评2、好评3、0位全部 def get_evaluation(self,score,id): #好评率 self.good_rate_show = None #评论请求地址参数,callback为对应书名json的id #productiId书名对应的京东id #score评价等级参数差评1、中评2、好评3,0为全部 #sortType类型,6为时间排序,5位推荐排序 #pageSize每页显示评论10条 #page页数 params = { 'callback':'fetchJSON_comment98vv35', 'productId':id, 'score':score, 'sortType':6, 'pageSize':10, 'isShadowSku':0, 'page':0, } #评论请求地址 url = 'https://sclub.jd.com/comment/productPageComments.action' header = { "user-agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36", "referer":"https://item.jd.com/12148832.html"} #发送请求 evaluation_response = requests.get(url,params=params,headers=header) if evaluation_response.status_code == 200: evaluation_response = evaluation_response.text try: #去除json外层的括号与名称 t = re.search(r'({.*})',evaluation_response).group(0) except Exception as er: print('评价的json数据匹配异常!') j = json.loads(t) commentSummary = j['comments'] if self.good_rate_show == None: self.good_rate_show = j['productCommentSummary']['goodRateShow'] print("好评率啊:",self.good_rate_show) for comment in commentSummary: #评价内容 c_contetn = comment['content'] #时间 c_time = comment['creationTime'] #京东昵称 c_name = comment['nickname'] #通过哪种平台购买 c_client = comment['userClientShow'] #会员级别 c_userLevelName = comment['userLevelName'] #好评1 差评 2-3 中评 4-5 c_score = comment['score'] #判断没有指定的评价内容时 if len(commentSummary)==0: #返回好评率与无 return self.good_rate_show,'无' else: #根据不同需求返回不同数据,这里仅返回好评率与最新的评价时间 return self.good_rate_show,commentSummary[0]['creationTime'] if __name__ == '__main__': obj = Crawl() rest = obj.get_rankings() rest_1 = obj.get_evaluation('0','12169220') print(rest_1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号