Python【第七篇】常用标准库
本篇大纲:
- os & sys
- random
- hashlib
- queue
- json & pickle
- shelve
- time & datetime
- re正则
常用标准库(又称内置模块)
Pyhon内置了大量、全面、高效和跨平台的标准库,提供了非常丰富的功能,能够满足大部分常见需求。并且很多都是用C语言编写、执行速度也很快。
我们尽量多学习这些标准库,理解和掌握它们然后使用它们,避免重复造轮子,增强开发能力,提高开发速度。
os
模块导入方式 ---> import os
os模块是Python标准库中的一个用于访问操作系统相关功能的模块,os模块提供了一种可移植的使用操作系统功能的方法。
os模块主要功能:系统相关、目录、文件操作、执行命令、管理进程(Linux相关,不做介绍)。
使用os模块时。如果抛出OSError异常、表明无效的路径名或文件名、或者路径名(文件名)无法访问、或者当前操作系统不支持该操作。
1、系统相关
os模块提供了一些操作系统相关的变量,在涉及操作系统相关的操作时,使用本模块提供的方法;
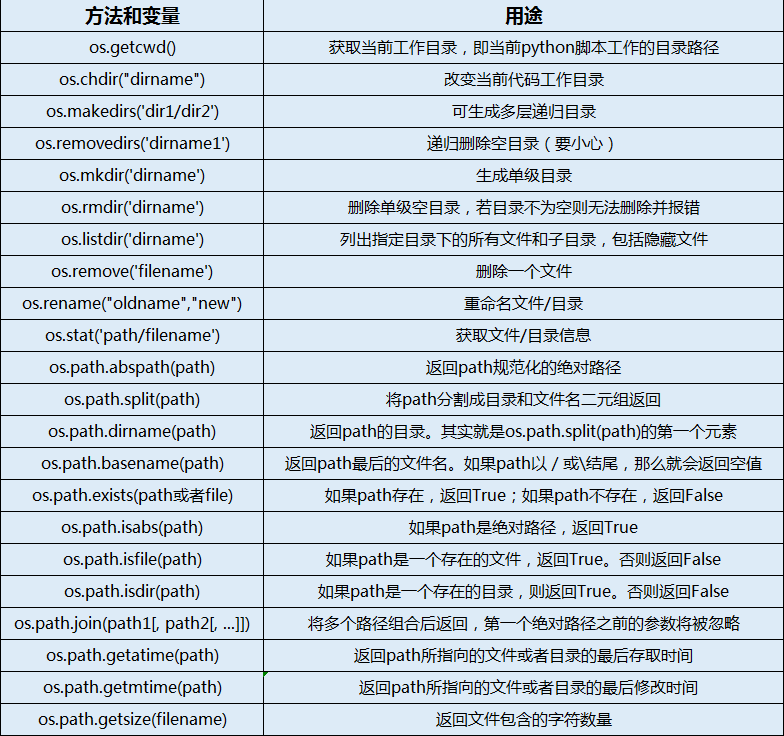
os模块中常用的方法和变量,以及用途解释;
import os
print(os.name) #查看当前操作系统的名称。windows平台下返回nt,Linux返回posix
print(os.environ)#获取系统环境变量,就是在计算机属性中添加配置的环境变量
print(os.sep) #当前平台路径分隔符。Windows下为'\'
2、文件和目录操作
os模块中包含了一系列文件操作相关的函数;
删除目录和文件
import os
import shutil #对文件和文件夹更高级的操作
os.rmdir(path) #只能删除空目录,含目录中创建空目录
os.remove(path) #只能删除目录下面的文件,不能删除目录
os.removedirs(path) #只能删除空目录
shutil.rmtree(path)#万能用法无论目录和子目录,是否为空、是否有文件都可以删除
#删除目录前先判断目录是否存在
if os.path.isdir('aa'):
os.rmdir('aa')
else:
print("目录aa不存在")
#删除文件前先判断文件是否存在
if os.path.isfile('name.txt'):
os.remove(path)
else:
print("文件不存在")
实例:
需求1:当前py文件中切换到其它目录,然后操作其它目录。
创建目录结构:
testdir
--dir1
--dir2
--dir3 -->test.py
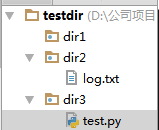
dir3目录-->test.py中写代码测试:
test.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2020/4/14 14:07'
import os
#获取当前目录的绝对路径
print(os.getcwd()) #当前目录:D:\testdir\dir3
os.chdir(r'../dir2') #目录切换到dir2目录中,下面的操作就是在dir2目录中操作。
print(os.getcwd()) #切换后输出目录为:D:\testdir\dir2
#以下操作就会添加到dir2目录中
with open("log.txt",'a+',encoding="utf-8") as ar:
ar.write("{0}".format("登录成功了"))
需求2:当前目录下的py文件中创建目录:
- 要求创建的目录需要在根目录下
- 新建目录已存在时就不需要创建。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2020/4/14 14:07'
import os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
"""
首先判断新建的目录是否已经存在:
存在就不用创建;
不存就需要创建;
"""
try:
if os.path.exists("{0}\{1}".format(BASE_DIR,'dir4')):#目录如果存在什么都不做
pass
else:
os.mkdir("{0}\{1}".format(BASE_DIR,'dir4')) #目录不存在就创建目录
except Exception as er:
print("创建目录失败:{0}".format(er))
sys
sys模块主要是针对与Python解释器相关的变量和方法,不是主机操作系统。
导入方式:import sys
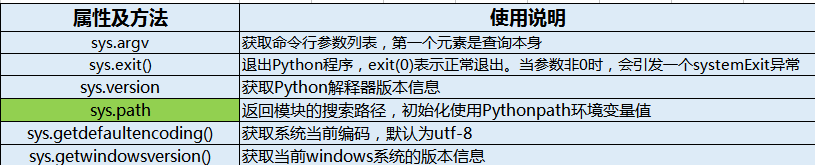
PS:常用到sys.path:sys.path是一个目录列表,供Python从中查找模块。在Python启动时,sys.path根据内建规则和PYTHONPATH变量进行初始化。
random
random模块用于生成伪随机数。计算机中的随机数是随机函数按照一定算法模拟产生的,其结果是确定的,是可以预测的。
所以用计算机随机函数所产生的(随机数)并不随机,是伪随机数,绝对不可以用来生成密码。
计算机的伪随机数是由随机种子根据一定的计算方法计算出来的数值。所以,只要计算方法一定,随机种子一定你们测试的随机数就是固定的。如果用户不设置随机种子,你们随机种子默认来自系统时钟。
random常用方法:
import random
#针对整数的方法
print(random.randrange(1,5)) #随机产生1到4之间的整数
print(random.randrange(0,101,2))#0-100的偶数
print(random.randint(1,5)) #随机产生1到5之间的随机整数
#针对序列类型的方法
li = ['33','88','刘德华','黄晓明','99','100']
print(random.choice(li)) #从非空序列中随机选取一个元素
print(random.choices(li,k=3))#从空序列中随机选择3个元素,k参数可以自定义获取几个元素。返回列表
random.shuffle(li) #对序列重新洗牌,改变原序列
print("序列洗牌:",li)
print(random.sample(li,k=2))#随机抽取K个不重复的元素,返回列表类型
#例子:
#生成一个包含大写字母A-Z和数字0-9的随机4位验证码
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print(checkcode)
#生成指定长度字母数字随机序列代码
import random,string
def gen_random_string(length):
#数字的个数随机产生
num_of_numeric = random.randint(1,length-1)
#剩下都是字母
num_of_letter = length - num_of_numeric
#随机生成数字
numerics = [random.choice(string.digits) for i in range(num_of_numeric)]
#随机生成字母
letters = [random.choice(string.ascii_letters) for i in range(num_of_letter)]
#结合两者
all_chars = numerics + letters
#洗牌
random.shuffle(all_chars)
#生成最终字符串
result = ''.join([i for i in all_chars])
return result
if __name__ == '__main__':
print(gen_random_string(64))
hashlib模块
Hash即哈希。把任意长度的输入,通过某种hash算法,变换成固定长度的输出,该输出就是散列值。
MD5是最常见的摘要算法,速度很快生成结果是固定的16字节,通常用一个32位的16进制字符串表示。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'tian'
__data__ = '2019/12/19 18:04'
import hashlib
m = hashlib.md5()
m.update('hello'.encode('utf8'))
print(m.hexdigest()) #输出:5d41402abc4b2a76b9719d911017c592
m.update('tian'.encode('utf8'))
print(m.hexdigest())#32802f06fe68b2ac061ee2a695906295
m2 = hashlib.md5()
m2.update('helloalvin'.encode('utf8'))
print(m2.hexdigest())#92a7e713c30abbb0319fa07da2a5c4af
以上加密算法虽然厉害,但存在缺陷。通过撞库可以反解。所以在加密算法中添加自定义key(即加盐)再来做加密。
hash = hashlib.md5('tian'.encode('utf8'))#加了盐tian
hash.update('hello'.encode('utf-8'))
print(hash.hexdigest())
模拟撞库破解密码
passwds = [
'123456a',
'123456abc',
'zhang123456',
'li123456',
'123456li',
'tian'
]
def make_passwd_dic(passwds):
dic = {}
for pas in passwds:
m = hashlib.md5()
m.update(pas.encode('utf-8'))
dic[pas] = m.hexdigest()
return dic
def break_code(cryptorgaph,passwd_dic):
print(passwd_dic)
for k,v in passwd_dic.items():
if v == cryptograph:
print("密码是===>\033[46m%s\033[0m" %k)
cryptograph = '834e8bc4d74592e3b999100c157215f5'
break_code(cryptograph,make_passwd_dic(passwds))
Queue
Python的Queue模块中提供了同步的、线程安全的队列类:
class queue.Queue(maxsize = 0) #先入先出队列。maxsize是队列里最多能同时存在多少个元素个数,如果队列满了,则会暂时阻塞队列,直到有消费者取值元素。maxsize参数的值如果小于或等于零,表示队列元素个数不设上限。
class queue.LifoQueue(maxsize = 0)#后入先出
class queue.PriorityQueue(maxsize = 0)#存储数据时可设置优先级的队列。元素的优先顺序是按sorted(list(entries))[0]的结果来定义的,而元素的结构形式通常是(priority_number,data)类型的元组.
Queue对象
三种队列类的对象都提供了一下通用的方法:
Queue.qsize() 返回当前队列内元素的个数。
Queue.empty() 队列为空则返回True,否则返回False。
Queue.full() 与empty()方法正好相反。
Queue.put(item,block=True,timeout=None) #默认block=True,timeout=None
item参数表示具体要放入队列的元素,block和timeout两个参数配合使用。其中block=True,timeout=None,队列阻塞,直到有空槽出现。当block=True,timeout=整数N,如果在等待了N秒后,队列还没有空槽,则弹出Full异常;
如果block = False,则timeout参数别忽略,队列有空槽则立即放入,如果没有空槽弹出Full异常。
Queue.put_nowait(item) 等同于put(item,Fals)
Queue.get(block=True,timeout=None) #默认block=True,timeout=None
从队列内删除并返回一个元素。如果block = True,timeout = None队列会阻塞,直到有可提供的元素。如果timeout指定为一个正整数N,则在N秒内如果队列内没有可供弹出的元素,则抛出Empty异常。如果block = False,timeout参数会被忽略,
此时队列内如果有元素则直接弹出,无元素可弹,则抛出Empty异常.
Queue.get_nowait() 等同于get(False)
下面两个方法用于跟踪排队的任务是否被消费者守护经常完全处理:
Queue.task_done() 表示先进的队列任务已完成。由消费者线程使用。
Queue.join() 阻塞队列,直到队列内的所有元素被获取和处理。
每当有消费者线程调用task_done()方法表示一个任务被完成时, 未完成任务的计数将减少。 当该计数变成0的时候, join()方法将不再阻塞。
这些队列都实现了锁,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
Queue模块中常用的方法:
- Queue.qsize()返回队列的大小
- Queue.empty()如果队列为空,返回True,反之False
- Queue.full()如果队列满了,返回True,反之False
- Queue.full与maxsize大小对应
- Queue.get([block[,timeout]])获取队列,timeout等待时间
- Queue.get_nowait()相当Queue.get(False)
- Queue.put(itme)写入队列,timeout等待时间
- Queue.put_nowait(item)相当Queue.put(item,False)
- Queue.task_done()在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join()实际上意味着等到队列为空,再执行别的操作
实例展示
import queue q = queue.Queue(5) #先进先出队列,最大5个元素 q.put(1) q.put(2) q.put(3) print(q.get()) print(q.get()) print(q.get()) print(q.get()) #阻塞了block=True,timeout=None
------------------------------------------------
q = queue.Queue(5)
print(q.maxsize) #队列里最多能存放的元素个数
print(q.qsize()) #获取队列里面元素的个数
print(q.empty())#队列为空时返回True
print(q.full())#队列为空时返回False
q.put(123)
q.put('abc')
q.put(['1','2','3'])
q.put({"name":"tian"})
q.put(None)
# q.put("6") #阻塞了
print(q.qsize())#5
print(q.empty())#False
print(q.full())#True
----------------------------------------------------
q = queue.LifoQueue() #先进后出
q.put(1)
q.put(2)
q.put(3)
print(q.get()) #输出:3
print(q.get()) #输出:2
print(q.get()) #输出:1
---------------------------------------------------
q = queue.PriorityQueue() #优先级队列,每个元素都带有一个优先值,值越小越早出去
q.put((3,'tian'))
q.put((1,'xiang'))
q.put((2,'hehe'))
print(q.get()) #(1, 'xiang')优先值为1,
print(q.get()) #(2, 'hehe')优先值为2
q.put((4,'li'))
print(q.get()) #(3, 'tian')
实例:
import queue
import threading
import time
exiFlag = 0
class myThread(threading.Thread):
def __init__(self,threadID,name,q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print("开启线程:{0}".format(self.name))
process_data(self.name,self.q)
print("\n退出线程:{0}".format(self.name))
def process_data(threadName,q):
while not exiFlag:
queueLock.acquire()
if not workQueue.empty():#如果队列为空返回True,相反返回False
data = q.get()
queueLock.release()
print("{0}processing{1}".format(threadName,data))
else:
queueLock.release()
time.sleep(1)
threadList = ['Thread-1','Thread-2','Thread-3']
nameList = ['One','Two','Three','Four','Five']
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
#创建线程
for tName in threadList:
thread = myThread(threadID,tName,workQueue)
thread.start()
threads.append(thread)
threadID += 1
#填充队列
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
#等待队列清空
while not workQueue.empty():
pass
#通知线程可以退出了
exiFlag = 1
#等待所有线程完成
for t in threads:
t.join()
print("退出主线程")
json&pickle
用于序列化的两个模块
json
- json用于字符串和Python数据类型之间进行转换。
- json是一种轻量级的数据交换格式。
- json是跨语言、跨平台,但只能对Python的基本数据类型做操作,对Python的类就无能为力。
- json格式和Python中的字典非常像。
- json的数据要求用双引号将字符串引起来,并且不能有多余的逗号。
pickle
- 用于python特有的类型 和 python的数据类型间进行转换
使用方法
json模块的使用其实很简单,对于绝大多数场合下,我们只需要使用下面四个方法就可以了:dumps、dump、loads、load
方法 功能
json.dump(obj,fp) 将python数据类型转换并保存到json格式的文件内
json.dumps(obj) 将python数据类型转换为json格式的字符串
json.load(fp) 从json格式的文件中读取数据并转换为python的类型
json.loads(s) 将json格式的字符串转换为python的类型
import json
data = {'k1':123,'k2':'Hello'}
j_str = json.dumps(data) #将python的字典转换所有程序语言都认识的字符串
print(j_str)
with open("rsult.json",'w') as fp: #将python的字典转换为所有程序语言都认识的字符串,并写入文件
json.dump(data,fp)
pickle
import pickle
data = {'k1':123,'k2':'Hello'}
#pickle.dumps将数据通过特殊的形式转换为只有python语言认识的字符串
p_str = pickle.dumps(data)
print(p_str)
dic2 = pickle.loads(p_str) #将只有python语言认识的字符串转换为字典
print(dic2)
#pickle.dump 将数据通过特殊的形式转换为只有python语言认识的字符串,并写入文件
with open('result.pk','wb') as fp:
pickle.dump(data,fp)
with open('result.pk','rb') as fr: #将保存在result.pk文件中,内容只有python语言认识的字符串,读出且转换为字典
data = pickle.load(fr)
print(data)
shelve模块
shelve是一个简单好用的shelve持久化模块。
shelve模块已类似字典的方式将Python对象持久化,依赖于pickle模块,但比pickle用起来简单。当我们写程序的时候人工不想用关系数据库那么重量级的程序去存储数据,可以简单的使用shelve.
shelve使用起来和字典类似,也是用key来访问的,键为普通字符串,值则可以是如何Python数据类型,并且支持所有字典类型的操作。
shelve模块最主要的两个方法:
#创建或打开一个shelve对象
shelve.open(filename,flag='c',protocol=None,writeback=False)
#同步并关闭shelve对象
shelve.close()
#每次使用完毕,都必须确保shelve对象被关闭。同样可以使用with语句。
with shelve.open('spam') as db:
db['eggs'] = 'eggs'
import shelve
d = shelve.open('a') #打开一个文件
class Test:
def __init__(self,n):
self.n = n
t = Test(123)
t2 = Test(123334)
name = ['tian','li','test']
d['test'] = name #持久化列表
d['t1'] = t #持久化类
d['t2'] = t2
d.close()
time & datetime模块
time
在Python中,用三种方式来表示时间,分别是时间戳、格式化时间字符串、结构化时间
- 时间戳(timestamp):也就是1970年1月1日之后的秒,例如1576831128.6161795,可以通过time.time()获得。时间戳是一个浮点数,可以进行加减运算,但请注意不要让结果超过取值范围。
- 格式化时间字符串(string_time):也就是年月日时分秒这样的我们常见的时间字符串,例如:2017-09-26 21:45,可以通过time.localtime()获得。
- 结构化时间(struct_time):一个包含了年月日时分秒的多元元组,例如:time.struct_time(tm_year=2017,tm_mon=9,tm_mday=26,tm_hour=9,tm_sec=50,tm_wday=1,tm_yday=269,tm_isdst=0),可以通过time.strftime('%Y-%m-%d')获得。
结构化时间(struct_time)
使用time.localtime()方法可以获得一个结构化时间元组
import time
lt = time.localtime()
print(lt)
#time.struct_time(tm_year=2019, tm_mon=12, tm_mday=20, tm_hour=16, tm_min=48, tm_sec=38, tm_wday=4, tm_yday=354, tm_isdst=0)
print(lt[3]) #获取小时输出16
print(lt[2:5]) #日、时、分输出:(20,16,55)
print(lt.tm_wday)#获取keytm_wday的值,输出为:4

格式化时间字符串
使用time.strftime('%Y-%m-%d %H:%M:%S')方法可以获得一个格式化时间字符串。
print(time.strftime("%Y-%m-%d %H:%M:%S"))
#输出:2019-12-20 17:03:26
time模块主要方法
1、time.sleep(t)
time.sleep(2) #暂停2秒
2、time.time()
返回当前系统时间戳。时间戳可以做算术运算。
import time
time.time() #返回当前系统时间戳。时间戳可以做算术运算。
print(time.time())#1576832797.8446538
#计算程序运行时间
def func():
time.sleep(1.14)
t1 = time.time()
func()
t2 = time.time()
print(t2 - t1)
print(t2 + 100)
print(t1 - 10)
print(t1 * 2)
3、time.localtime(seconds=None)
将一个时间戳转换为当前时区的结构化时间。如果seconds参数未提供,则以当前时间为准,即time.time()
import time
print(time.localtime()) #已当前时间为准
print(time.localtime(1406391907))#设置参数时间为准
print(time.localtime(time.time()+1000)) #当前时间加1000秒
4、time.ctime(seconds=None)
将时间戳转换为本地时间的格式字符串。默认使用time.time()作为参数。
print(time.ctime()) #将时间戳转换为本地时间的格式字符串。默认使用time.time()作为参数。
#输出:Fri Dec 20 17:19:33 2019
print(time.ctime(time.time()))
print(time.ctime(1406391907))
#Sun Jul 27 00:25:07 2014
print(time.ctime(time.time() + 10000))
5、time.asctime([t])
把一个结构化时间转换为Fri Dec 20 17:28:14 2019这种形式的格式化时间字符串。默认将time.localtime()作为参数。
print(time.asctime()) #默认将time.localtime()作为参数.
#Fri Dec 20 17:28:14 2019
6、time.mktime(t)
将一个结构化的时间转换为时间戳。time.mktime()执行与gmtime(),localtime()相反的操作,它接收struct_time对象作为参数,返回用秒数表示时间的浮点数。
print(time.mktime(time.localtime()))
#1576834674.0
7、time.strftime()
返回格式化字符串表示的当地时间。如果未指定t,默认传入time.localtime()
print(time.strftime("%Y-%m-%d %H:%M:%S"))
#2019-12-20 17:39:29
8、time.strptime()
将格式化时间字符串转换成结构化时间。
stime = "2018-09-26 15:35:30" st = time.strptime(stime,"%Y-%m-%d %H:%M:%S") print(st)
#time.struct_time(tm_year=2018, tm_mon=9, tm_mday=26, tm_hour=15, tm_min=35, tm_sec=30, tm_wday=2, tm_yday=269, tm_isdst=-1)
for item in st:
print(item)
输出>>>:
2018
9
26
15
35
30
2
269
-1
时间格式之间的转换
Python的三种类型时间格式,可以相互转换
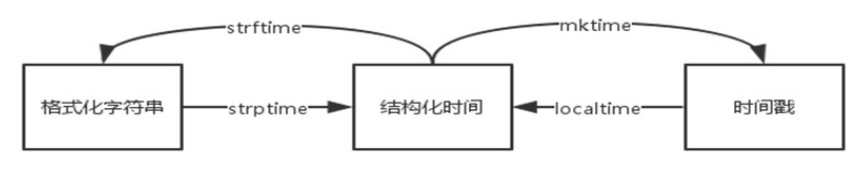
import time t = time.time() #t是一个时间戳 time.gmtime(t - 10000) #t减去1万秒,然后转换成UTC结构化时间 lt = time.localtime(t - 10000)#t减去1万秒,然后转换为中国本地结构化时间 print(lt) print(time.mktime(lt)) #将本地结构化时间转换为时间戳 st = time.strftime("%Y-%m-%d %H:%M:%S",lt) #将本地结构化时间转换为时间字符串 print(st) lt2 = time.strptime(st,"%Y-%m-%d %H:%M:%S") #将时间字符串转换结构化时间 print(lt2)
datetime
与time模块相比datetime模块提供的接口更直观、易用、功能也更强大。
#时间加减
import datetime
import time
print(datetime.datetime.now()) #输出当前日期和时间
#2019-12-27 12:21:13.529771
print(datetime.date.fromtimestamp(time.time())) #将时间戳直接转换成日期格式
print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
print(datetime.datetime.now() + datetime.timedelta(minutes=30))#当前时间+30分
c_time = datetime.datetime.now()
print('c_time',c_time)
print(c_time.replace(minute=3,hour=2))#时间替换
# 2019-12-27 12:30:03.139063
# 2019-12-27
# 2019-12-30 12:30:03.139063
# 2019-12-24 12:30:03.139063
# 2019-12-27 15:30:03.139063
# 2019-12-27 13:00:03.139063
# c_time 2019-12-27 12:30:03.139063
# 2019-12-27 02:03:03.139063
re模块
re模块用于对Python的正则表达式的操作:
正则字符串&匹配参数规则
1 import re
2
3 字符
4 . 匹配除\n换行符以外的任意一个字符
5 \w 匹配字母、数字、下划线、汉字 例如:[A-Za-z0-9]
6 \s 匹配任意空白符、\t、\n、\r,re.search("\s+","ab\tc1\n3").group 结果:\t
7 \d 匹配数字0-9
8 \b 匹配非数字
9 ^ 匹配字符开头
10 $ 匹配字符结尾
11
12 次数
13 * 匹配*号前的字符0次或多次
14 print(re.findall('ab*','cabb3abcbbac')) #结果为['abb', 'ab', 'a']
15 + 匹配前一个字符1次或多次
16 print(re.findall('ab+','ab+cd+add+bba'))#结果为['ab']
17 ? 匹配前一个字符1次或0次
18 {m} 匹配前一个字符m次
19 {n,m} 匹配前一个字符n到m次,
20 print(re.findall('ab{1,3}','abb abc abbcbb'))#结果为['abb', 'ab', 'abb']
21 | 匹配|左或|右的字符
22 print(re.search('abc|ABC','ABCBabcCD').group()) #结果为ABC
23 (...)分组匹配
24 print(re.search("(abc){2}a(123|456)c","abcabca456c").group())#结果为abcabca456c
25 \A 只从字符串开头匹配,
26 print(re.search("\Abc",'abcdeabc')) #输出None
最常用的匹配语法
re.match() 从给定字符串的开头进行匹配,如果匹配成功就返回一个匹配对象,如果匹配不成功则返回None,使用group()方法,可以将匹配到的字符串输出。
re.search() 给定字符串内查找,返回第一个匹配到的字符串。返回值类型和使用方法与match()是一样的,唯一区别就是查找的位置不用固定在文本的开头。
re.findall() 给定字符串全文查找, 把所有匹配到的字符放到列表中返回。
re.splitall() 以匹配到的字符当做列表分隔符。
re.sub() 类似字符串的replace()方法,用指定的内容替换匹配到的字符,可以指定替换次数;
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone)
print ("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print ("电话号码 : ", num)
# 正则表达式
print(re.findall('alex','yuangangalexpjjjjljl') )# 匹配字符串中所有符合字符,且返回列表,字符串中寻找alex;
# 元字符 .^ $ * + ? {} [] | () \ 元字符在[]中括号中无特殊意义,除了这3个[-^\]外
# 反斜杠后面跟元字符去除特殊功能;
# 反斜杠后面跟普通字符实现特殊功能;
print(re.findall("al.x","yangnnanfalfxllllll")) #.匹配除换行以为的任意1个字符;
print(re.findall("al.x","yyyyyal/nxllllllll")) #.换行符
print(re.findall("^alex","ealexyyyyallalexkkkkkk")) #^起始位置匹配
print(re.findall("alex$","ajaljfaljflalexllllalex")) #$终止位置匹配
print(re.findall("al.*x","aaiiiaiialeSxlllsiidiaii")) #匹配*0个或多个,和【.*】一起使用
print(re.findall("al.+x","aaiiiaiialxwxlllsiidiaii")) #+ 匹配1到多次
print(re.findall("al.?x","aaiiiaiialxlllsiidiaii")) #? 匹配 0 到 1 次
print(re.findall("al.{1,9}x","aaiiiaiialeSxlllsiidiaii")) # {}匹配范围1到5次,{,6}从零开始,{1,}任意多次
print(re.findall("a[bc]d","acd")) #[bc]或的作用:匹配abd 或 acd,
print(re.findall("a[a-z]d","aed")) #[a-z]匹配任意1个小写字母
print(re.findall("a[a-z]+d","aebbdd")) #[a-z]匹配任意1个或多个小写字母
print(re.findall("a[^f]d","add")) #[^f]除了f以外的字母
print(re.findall("a[\d]d","a9d")) #\d[0-9]数字,\w[a-zA-Z0-9_]匹配任意字母数字和下划线
print(re.findall("a\wd","a_d")) #\w[a-zA-Z0-9_]匹配任意字母数字和下划线
print(re.findall('I','I am handsIome'))
print(re.findall(r'I\b','I am hangdIome')) #只想匹配字母I ,通过\b实现
# 正则中的函数
# findall匹配成功后返回一个列表;
# match,从字符串的开头匹配只匹配开头位置;匹配成功只返回结果,如果要获取匹配到的结果值需要 group
# search(),从字符串的任意位置开始匹配;
compile()
a=re.match('com','comwww.runconmoob').group()
print(a)
a1= re.match('com','comwww.rncommmood')
print(a1.span()) #从头匹配,匹配到第一个字符串的小标;
a = re.search("com","ww.runcomlllcoml")
print(a.span())
a = re.split("\d+",'one1tow2ther3for4') #数字分割符
print(a)
a = re.search(r"\\com","www.run\comoob").group() #加r原生字符串
print(a)
a = re.search(r"\bblow","blow").group()
print(a)
a = re.search(r"\dblow","3blow").group() #加r原生字符串
print(a)
# 正则分组:去已经匹配到的数据中再提取数据;
orgin="has abanbnannnbnan000 hal daf00119eeeaa"
# r = re.match("h\w+",orgin)
r = re.match("h(\w+)",orgin)
r = re.match("h(?P<name>\w+)",orgin) #groupdict的key值:?P<name>
print(r.group()) #获取匹配到的所有结果,match匹配到什么,就放到group()中;
print(r.groups()) #获取模型中匹配到的分组结果
print(r.groupdict())#获取模型中匹配到分组结果
findall分组
r = re.findall("h\w+",orgin)
orgin="hasaabc dfuojqw halaabc m098u29341"
r = re.findall("h(\w+)aabc",orgin) #输出分组内的内容as和al
r = re.findall("h(\w+)a(ab)c",orgin)
print(r)
split()分组
1、无分组
origin = "hello alex bcd alex lge alex acd 19 "
r = re.split("alex",origin,1) #匹配到但是没有取值
print(r)
# 有分组
r1 = re.split("a(le)x",origin,1)
print(r1)
练习
import re
iput = input("请输入手机号码:").strip()
phone = re.search(r"^1[3-9]\d\d{8}$",iput)
if phone:
print(phone.group())
else:
print("输入错误,请重新输入")
email = input("请输入邮箱:")
pattern = re.search(r"\w{0,19}@\w{1,13}\.[com,cn,net]{1,3}",email)
if pattern:
print(pattern.group())
else:
print("输入错误")
print(re.findall(r'href="(.*?)"','<a href="http://www.baidu.com">点击</a>'))
print(re.findall(r'href="(.*)"','<a href="http://www.baidu.com">点击</a>'))
print(re.findall(r'href="(?:.*)"','<a href="http://www.baidu.com">点击</a>'))
print(re.findall('(?:ab)+123','ababab123')) #?:可以让结果为匹配的全部内容
shutil.rmtree(path)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号