Galera Cluster PXC
Galera Cluster介绍
Galera Cluster优点:
多主架构:真正的多点读写的集群,在任何时候读写数据,都是最新的。
同步复制:改善集群不同节点之间数据同步效率,基本没有延迟,在数据库挂掉之后,数据不会丢失。
并发复制:从节点APPLY数据时,支持并行执行,更好的性能。
故障切换:在出现数据库故障时,因支持多点写入,切换容易。
热插拔:在服务期间,如果数据库挂了,只要监控程序发现的够快,不可服务时间就会非常少。在节点故障期间,因为集群是多主架构因此单个节点本身对集群的影响非常小。
自动节点克隆:在新增节点,或者停机维护时,增量数据或者基础数据不需要人工手动备份提供,Galera Cluster会自动拉取在线节点数据复制给新增节点,最终集群会变为一致。
对应用透明:集群的维护,对应用程序是透明的。
Galera Cluster 缺点:
1)任何提交结果的事务会在集群中生成一个全局的事务ID(唯一)需要全局验证通过,才会在其他节点上执行,则集群性能由集群中最差性能节点决定(一般集群节点配置都是一样的)原则:Galera Cluster建议三个节点不得超过8个节点 。
2)新节点加入或延后较大的节点重新加入需全量拷贝数据(SST,State Snapshot Transfer),作为donor( 贡献者,如:同步数据时的提供者)的节点在同步过程中无法提供读写。如果节点数据与集群在线节点数据相差不大则进行增量复制。
3)只支持innodb存储引擎的表。
工作原理:
在数据进行修改时会开启事务(MyISan不支持事务),提交事务结果后会生成一个基于集群的全局性事务ID,事务结果不会立即反馈给用户而是发往集群中的节点验证这个事务是否能够被执行(避免在同一时间多个节点对数据进行相同操作所造成的"堵车"现象),如果能则进行同步复制,不能则反馈操作失败的结果。
Galera Cluster包括两个组件
1)Galera replication library (galera-3)
2)WSREP:MySQL extended with the Write Set Replication
WSREP复制实现(两个解决方案):
1)PXC:Percona XtraDB Cluster,是Percona对Galera的实现
参考仓库:
https://mirrors.tuna.tsinghua.edu.cn/percona/release/$releasever/RPMS/$basearch ###这是编写yum仓库的pxc包的获取路径不可直接访问。
2)MariaDB Galera Cluster:
参考仓库:
https://mirrors.tuna.tsinghua.edu.cn/mariadb/mariadb5.5.X/yum/centos7-amd64/
注意:两者都需要至少三个节点,不能安装mysql server 或 mariadb-server。
PXC 原理:
1)PXC最常使用如下4个端口号:
3306:数据库对外服务的端口号
4444:请求SST的端口号
4567:组成员之间进行沟通的端口号
4568:用于传输IST的端口号
2)PXC中涉及到的重要概念和核心参数:群中节点的数量:整个集群中节点数量应该控制在最少3个、最多8个的范围内。少3个节点是为了防止出现脑裂现象,因为只有在2个节点下才会出现此现象。脑裂现象的标志就是输入任何命令,返回的结果都是unknown command。节点在集群中,会因新节点的加入或故障、同步失效等原因发生状态的切换。
3)节点状态的变化阶段:
open:节点启动成功,尝试连接到集群时的状态
primary:节点已处于集群中,在新节点加入并选取donor进行数据同步时的状态
joiner:节点处于等待接收同步文件时的状态
synced:节点正常提供服务时的状态,表示已经同步完成并和集群进度保持一致
donor:节点处于为新加入的节点提供全量数据时的状态(节点处于donor状态不会向外提供服务)
备注:donor节点就是数据的贡献者,如果一个新节点加入集群,此时又需要大量数据的SST数据传输,就有可能因此而拖垮整个集群的性能,因此在生产环境中,如果数据量较小,还可以使用SST全量数据传输,但如果数据量很大就不建议使用这种方式,可以考虑先建立主从关系,然后再加入集群。
3)节点的数据传输方式:
SST:State Snapshot Transfer,全量数据传输
IST:Incremental State Transfer,增量数据传输
SST数据传输有xtrabackup、mysqldump和rsync三种方式,而增量数据传输就只有一种方式xtrabackup,但生产环境中一般数据量较小时,可以使用SST全量数据传输,但也只使用xtrabackup方法。
4)GCache模块:在PXC中一个特别重要的模块,它的核心功能就是为每个节点缓存当前最新的写集。如果有新节点加入进来,就可以把新数据的增量传递给新节点,而不需要再使用SST传输方式,这样可以让节点更快地加入集群中,涉及如下参数:
gcache.size:缓存写集增量信息的大小,它的默认大小是128MB,通过wsrep_provider_options参数设置,建议调整为2GB~4GB范围,足够的空间便于缓存更多的增量信息。
gcache.mem_size:GCache中内存缓存的大小,适度调大可以提高整个集群的性能
gcache.page_size:如果内存不够用(GCache不足),就直接将写集写入磁盘文件中
实战案例:Percona XtraDB Cluster(PXC 5.7)
1)实验环境:
1.版本目前不支持CentOS 8
2.关闭防火墙和SELinux,保证时间同步。
3.注意:如果已经安装MySQL,必须卸载。
pxc1:10.0.0.50
pxc2:10.0.0.55
pxc3:10.0.0.60
pxc4:10.0.0.65(模拟扩容)
2)安装 Percona XtraDB Cluster 5.7
vim /etc/yum.repos.d/pxc.repo
[percona]
name=percona_repo
baseurl = https://mirrors.tuna.tsinghua.edu.cn/percona/release/$releasever/RPMS/$basearch
enabled = 1
gpgcheck = 0
<为pxc1 pxc2 pxc3节点安装PXC 5.7 ,这个组件提供mysql-client及mysql-server>
yum install Percona-XtraDB-Cluster-57 -y
3)在各个节点上分别配置mysql及集群配置文件由 /etc/my.cnf 提供
vim /etc/percona-xtradb-cluster.conf.d/wsrep.cnf
1.修改前
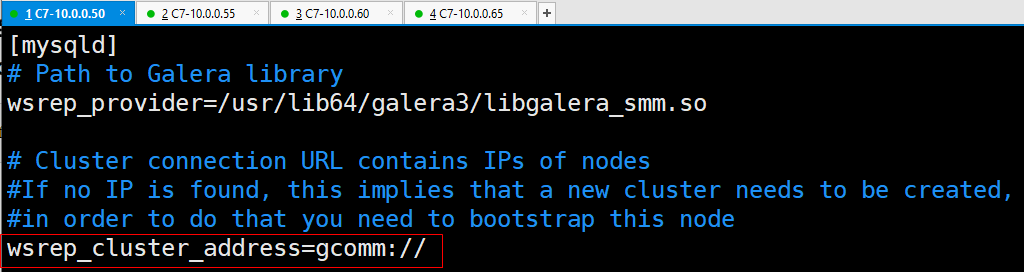
<修改后,添加要加入集群的节点IP>

2.修改前
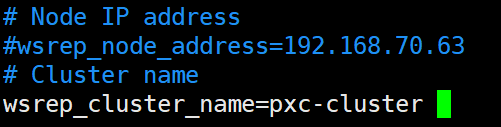
<修改后,修改集群名称>
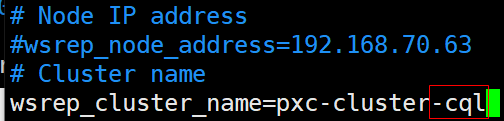
3.修改前

修改后,修改节点名称(因为是第一个节点因此不做变动,往后的第2、3 节点按顺序修改。)
<4.修改前>
<修改后,修改成当前节点的IP>
<5.修改前>
<修改后,此选项添加一个用户节点间能够相互进行数据复制的账号(类似于权限是replication slave 的账号)
注意:
1.不同的节点所用的IP不同
2.不同节点所用的节点编号也不相同。
注意:尽管Galera Cluster不再需要通过binlog的形式进行同步,但还是建议在配置文件中开启二进制日志功能,原因是后期如果有新节点需要加入,老节点通过SST全量传输的方式向新节点传输数据,很可能会拖垮集群性能,所以让新节点先通过binlog方式 change master to 完成同步后再加入集群会是一种更好的选择。
4)启动集群中的第一个节点
systemctl enable --now mysql@bootstrap.service ###第一个节点第一次启动使用,后续disable 掉。
systemctl start mysqld ###后续使用mysqld启动节点加入集群中。
5)启动后通过日志查看随机密码
grep "temporary password" /var/log/mysqld.log
<进入mysql后修改密码>
alter user 'root'@'localhost' identified by '123456';
6)通过集群变量,查看集群信息。
<查看当前节点和集群配置信息>
SHOW VARIABLES LIKE 'wsrep%'\G
<查看集群状态信息,核心参数为wsrep_cluster_size(也就是当前集群中的节点数量)>
SHOW STATUS LIKE 'wsrep%'\G

7)启动其他节点
systemctl start mysql ###建议设置为开机自启。
测试环节:
注意事项:
1)第一个节点第一次使用 systemctl enable --now mysql@bootstrap.service 启动,后续disable掉如果宕机则使用mysqld加入集群中并设置为开机自启。
2)第一个节点宕机后,需启动mysqld 才能重新加入节点中。
3)实际生产中数据量巨大的情况下建议开启bin-log功能,以便提供给扩容的新节点change master to 功能,如此一来避免了直接加入集群中进行全量复制导致集群的性能拉跨。
posted on 2021-06-25 04:39 1251618589 阅读(9) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号