
二进制部署多Master高可用K8S集群-v1.18(一)
1.
2.部署环境信息和部署架构简介
1.集群节点信息和服务版本
使用Kubernetes1.19.7,所有节点机操作系统是Centos7.7。本文档部署中所需kubernetes相关安装包和镜像可提前在FQ服务器上下载,然后同步到k8s部署机器上。具体信息如下:
| ip地址 | 主机名 | 角色 |
| 172.31.46.86 | k8s-master01 | 主节点1、etc节点1,DNS节点 |
| 172.31.46.83 | k8s-master02 | 主节点2、etc节点2 |
| 172.31.46.78 | k8s-master03 | 主节点3、etc节点3 |
| 172.31.46.90 | k8s-node01 | 工作节点1 |
| 172.31.46.103 | k8s-node02 | 工作节点2 |
| 172.31.46.101 | k8s-node03 | 工作节点3 |
| 172.31.46.76 | k8s-ha01 | nginx节点1、harbor节点1 |
| 172.31.46.100 | k8s-ha02 | nginx节点2、harbor节点2 |
2.安装包的准备
k8s二进制包:https://dl.k8s.io/v1.18.15/kubernetes-server-linux-amd64.tar.gz
3.环境初始化准备
1.部署DNS服务bind9
#以下操作均在DNS节点k8s-master01操作 [root@k8s-master01 ~]# yum install bind bind-utils -y #修改并校验配置文件。 [root@k8s-master01 ~]# vim /etc/named.conf listen-on port 53 { 172.31.46.86; }; allow-query { any; }; forwarders { 172.16.100.13; }; #上一层DNS地址(网关或公网DNS) recursion yes; dnssec-enable no; dnssec-validation no [root@k8s-master01 ~]# named-checkconf #检查配置文件格式是否正确 #在域配置中增加自定义域 [root@k8s-master01 ~]# cat >>/etc/named.rfc1912.zones <<'EOF' #添加自定义主机域 zone "host.com" IN { type master; file "host.com.zone"; allow-update { 172.31.46.86; }; }; #添加自定义业务域(这个可以根据自己的业务添加,也可不添加) zone "zq.com" IN { type master; file "zq.com.zone"; allow-update { 172.31.46.86; }; }; EOF #host.com和zq.com都是我们自定义的域名,一般用host.com做为主机域 #zq.com为业务域,业务不同可以配置多个 #为自定义域host.com创建配置文件,后续加入新的集群节点,只需在配置文件中添加主机信息即可。 [root@k8s-master01 ~]# cat >/var/named/host.com.zone <<'EOF' $ORIGIN host.com. $TTL 600 ; 10 minutes @ IN SOA dns.host.com. dnsadmin.host.com. ( 2020041601 ; serial 10800 ; refresh (3 hours) 900 ; retry (15 minutes) 604800 ; expire (1 week) 86400 ; minimum (1 day) ) NS dns.host.com. $TTL 60 ; 1 minute dns A 172.31.46.86 k8s-master01 A 172.31.46.86 k8s-master02 A 172.31.46.83 k8s-master03 A 172.31.46.78 k8s-node01 A 172.31.46.90 k8s-node02 A 172.31.46.103 k8s-node03 A 172.31.46.101 k8s-ha01 A 172.31.46.76 k8s-ha02 A 172.31.46.100 EOF #为自定义域zq.com创建配置文件 [root@k8s-master01 ~]# cat >/var/named/zq.com.zone <<'EOF' $ORIGIN zq.com. $TTL 600 ; 10 minutes @ IN SOA dns.zq.com. dnsadmin.zq.com. ( 2020041601 ; serial 10800 ; refresh (3 hours) 900 ; retry (15 minutes) 604800 ; expire (1 week) 86400 ; minimum (1 day) ) NS dns.zq.com. $TTL 60 ; 1 minute dns A 172.31.46.86 EOF host.com域用于主机之间通信,所以要先增加上所有主机 zq.com域用于后面的业务解析用,因此不需要先添加主机 #再次检查配置并启动dns服务 [root@k8s-master01 ~]# named-checkconf [root@k8s-master01 ~]# systemctl start named [root@k8s-master01 ~]# ss -lntup|grep 53 #验证结果 [root@k8s-master01 ~]# dig -t A k8s-master02.host.com @172.31.46.86 +short 172.31.46.83 [root@k8s-master01 ~]# dig -t A k8s-master03.host.com @172.31.46.86 +short 172.31.46.78 #以下操作需要在集群所有节点操作 #修改集群节点的网络配置,使其绑定我们的DNS服务。 [root@k8s-master01 ~]# sed -i 's#^DNS.*#DNS1=172.31.46.86#g' /etc/sysconfig/network-scripts/ifcfg-eth0 [root@k8s-master01 ~]# systemctl restart network [root@k8s-master01 ~]# sed -i '/^nameserver.*/i search host.com' /etc/resolv.conf
[root@k8s-master01 ~]# sed -i 's#^nameserver.*#nameserver 172.31.46.86#g' /etc/resolv.conf #检查DNS配置,是否成功。 [root@k8s-master01 ~]# cat /etc/resolv.conf ; generated by /usr/sbin/dhclient-script search host.com nameserver 172.31.46.86 [root@k8s-master01 ~]# ping k8s-node01 PING k8s-node01.host.com (172.31.46.26) 56(84) bytes of data. 64 bytes from node3 (172.31.46.26): icmp_seq=1 ttl=64 time=0.813 ms [root@k8s-master01 ~]# ping k8s-ha02 PING k8s-ha02.host.com (172.31.46.3) 56(84) bytes of data. 64 bytes from 172.31.46.3 (172.31.46.3): icmp_seq=1 ttl=64 time=0.403 ms
2.基础环境配置
#以下操作需在所有集群节点操作 #1.主机名修改 [root@k8s-master01 ~]# hostnamectl set-hostname k8s-master01 #2.配置免密登录 #以下操作在节点k8s-master01操作 #本篇部署文档有很多操作都是在k8s-master01节点上执行,然后远程分发文件到其他节点机器上并远程执行命令,所以需要添加该节点到其它节点的ssh信任关系。 [root@k8s-master01 ~]# ssh-keygen -t rsa [root@k8s-master01 ~]# cp /root/.ssh/id_rsa.pub /root/.ssh/authorized_keys [root@k8s-master01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@k8s-master01 [root@k8s-master01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@k8s-master02 [root@k8s-master01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@k8s-master03 [root@k8s-master01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@k8s-node01 [root@k8s-master01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@k8s-node02 [root@k8s-master01 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub -p22 root@k8s-node03 #以下操作需在所有集群节点操作
3.关闭防火墙和SELinux [root@k8s-master01 ~]# systemctl stop firewalld && systemctl disable firewalld && systemctl status firewalld [root@k8s-master01 ~]# sed -ri 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config [root@k8s-master01 ~]# setenforce 0 && getenforce #4.安装依赖包(执行此操作前确定集群节点网络无问题,并配置好了epel源,这里如何配置epel源,我这里就不做演示了,国内建议用阿里的) [root@k8s-master01 ~]# yum -y install gcc gcc-c++ libaio make cmake zlib-devel openssl-devel pcre pcre-devel wget git curl lynx lftp mailx mutt rsync ntp net-tools vim lrzsz screen sysstat yum-plugin-security yum-utils createrepo bash-completion zip unzip bzip2 tree tmpwatch pinfo man-pages lshw pciutils gdisk system-storage-manager git gdbm-devel sqlite-devel chrony conntrack ipvsadm ipset jq iptables curl sysstat libseccomp wget socat git
#以下操作在节点k8s-master01操作
#5.配置全局环境变量(重要) 在所有节点上的profile文件的最后都需要添加下面的参数;注意集群IP和主机名更改为自己的服务器地址和主机名 [root@k8s-master01 ~]# vim /etc/profile #----------------------------K8S-----------------------------# # 生成 EncryptionConfig 所需的加密 key export ENCRYPTION_KEY=$(head -c 32 /dev/urandom | base64) #各机器 IP 数组包含Master与Node节点 export NODE_ALL_IPS=(172.31.46.86 172.31.46.83 172.31.46.78 172.31.46.90 172.31.46.103 172.31.46.101) #各机器IP 对应的主机名数组包含Master与Node节点 export NODE_ALL_NAMES=(k8s-master01 k8s-master02 k8s-master03 k8s-node01 k8s-node02 k8s-node03) # Master集群节点IP export MASTER_IPS=(172.31.46.86 172.31.46.83 172.31.46.78) # 集群中master节点IP对应的主机名数组 export MASTER_NAMES=(k8s-master01 k8s-master02 k8s-master03) # WORK集群数组IP export WORK_IPS=(172.31.46.90 172.31.46.103 172.31.46.101) # WORK集群IP对应主机名数组 export WORK_NAMES=(k8s-node01 k8s-node02 k8s-node03) #ETCD集群IP数组 export ETCD_IPS=(172.31.46.86 172.31.46.83 172.31.46.78) # ETCD集群节点IP对应主机名数组(这里是和master三节点机器共用) export ETCD_NAMES=(k8s-etcd1 k8s-etcd2 k8s-etcd3) # etcd 集群服务地址列表;注意IP地址根据自己的ETCD集群服务器地址填写 export ETCD_ENDPOINTS="https://172.31.46.86:2379,https://172.31.46.83:2379,https://172.31.46.78:2379" # etcd 集群间通信的 IP 和端口;注意此处改为自己的实际ETCD所在服务器主机名 export ETCD_NODES="k8s-etcd1=https://172.31.46.86:2380,k8s-etcd2=https://172.31.46.83:2380,k8s-etcd3=https://172.31.46.78:2380" # kube-apiserver 的反向代理(kube-nginx)地址端口 export KUBE_APISERVER="https://172.31.46.47:8443" # 节点间互联网络接口名称;根据自己服务器网卡实际名称进行修改 export IFACE="eth0" # etcd 数据目录 export ETCD_DATA_DIR="/data/k8s/etcd/data" # etcd WAL 目录,建议是 SSD 磁盘分区,或者和 ETCD_DATA_DIR 不同的磁盘分区 export ETCD_WAL_DIR="/data/k8s/etcd/wal" # k8s 各组件数据目录 export K8S_DIR="/data/k8s/k8s" ## DOCKER_DIR 和 CONTAINERD_DIR 二选一 # docker 数据目录 export DOCKER_DIR="/data/k8s/docker" # containerd 数据目录 export CONTAINERD_DIR="/data/k8s/containerd" ## 以下参数一般不需要修改 # TLS Bootstrapping 使用的 Token,可以使用命令 head -c 16 /dev/urandom | od -An -t x | tr -d ' ' 生成 BOOTSTRAP_TOKEN="41f7e4ba8b7be874fcff18bf5cf41a7c" # 最好使用 当前未用的网段 来定义服务网段和 Pod 网段 # 服务网段,部署前路由不可达,部署后集群内路由可达(kube-proxy 保证) SERVICE_CIDR="10.254.0.0/16" # Pod 网段,建议 /16 段地址,部署前路由不可达,部署后集群内路由可达(flanneld 保证) CLUSTER_CIDR="172.30.0.0/16" # 服务端口范围 (NodePort Range) export NODE_PORT_RANGE="30000-32767" # kubernetes 服务 IP (一般是 SERVICE_CIDR 中第一个IP) export CLUSTER_KUBERNETES_SVC_IP="10.254.0.1" # 集群 DNS 服务 IP (从 SERVICE_CIDR 中预分配) export CLUSTER_DNS_SVC_IP="10.254.0.2" # 集群 DNS 域名(末尾不带点号) export CLUSTER_DNS_DOMAIN="cluster.local" # 将二进制目录 /opt/k8s/bin 加到 PATH 中 export PATH=/opt/k8s/bin:$PATH
#将配置传给各Master集群节点和ETCD集群和worker节点服务器,并执行source命令是其配置生效 [root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo $i;scp /etc/profile root@$i:/etc/;ssh root@$i "source /etc/profile";done 6.配置时间同步 master01节点去同步互联网时间,其他节点与master01节点进行时间同步 下面的网段表示哪个网段的机器到这台服务器同步时间,这里写集群节点所在的IP [root@k8s-master01 ~]# vim /etc/chrony.conf allow 172.31.46.0/24 #其他节点关闭ntpd服务,我们这里使用chronyd服务 [root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "systemctl stop ntpd && systemctl disable ntpd && systemctl status ntpd";done #然后启动在master01上启动时间服务 [root@k8s-master01 ~]# systemctl start chronyd.service [root@k8s-master01 ~]# systemctl enable chronyd.service [root@k8s-master01 ~]# systemctl status chronyd.service #登入除master01节点外的各个节点服务器,把下面标红的默认同步时间服务地址注释掉,加下面加入mater01节点的地址(也就是自建的时间服务器地址) vim /etc/chrony.conf #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst server 172.31.46.86 iburst 所有节点启动服务 [root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "systemctl restart chronyd.service && systemctl enable chronyd.service && systemctl status chronyd.service";done 检查时间同步状态 ^*表示已经同步
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "chronyc sources ";done
上面如果返回^?,注意在服务端的配置中第29行设置同步,Serve time even if not synchronized to any NTP server.,打开注释即可,即:local stratum 10
调整系统 TimeZone(时区)
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "timedatectl set-timezone Asia/Shanghai";done
将当前的 UTC 时间写入硬件时钟
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "timedatectl set-local-rtc 0";done
重启依赖于系统时间的服务
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "systemctl restart rsyslog && systemctl restart crond";done
7.关闭交换分区
如果不关闭交换分区,会导致K8S服务无法启动
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "swapoff -a && free -h|grep Swap";done
永久关闭
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "sed -ri 's@/dev/mapper/centos-swap@#/dev/mapper/centos-swap@g' /etc/fstab && grep /dev/mapper/centos-swap /etc/fstab";done
8.优化系统内核
必须关闭tcp_tw_recycle,否则和 NAT 冲突,会导致服务不通;关闭 IPV6,防止触发 docker BUG;
[root@k8s-master01 ~]# cat > /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
net.ipv4.neigh.default.gc_thresh1=1024
net.ipv4.neigh.default.gc_thresh2=2048
net.ipv4.neigh.default.gc_thresh3=4096
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
[root@k8s-master01 ~]# cat > /etc/modules-load.d/netfilter.conf <<EOF
# Load nf_conntrack.ko at boot
nf_conntrack
EOF
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";scp /etc/modules-load.d/netfilter.conf root@$i:/etc/modules-load.d/;done
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";scp /etc/sysctl.d/kubernetes.conf root@$i:/etc/sysctl.d/;done
#接着在所有节点执行重启操作,重启之后执行sysctl -p
[root@k8s-master01 ~]# reboot
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "modprobe br_netfilter;sysctl -p /etc/sysctl.d/kubernetes.conf";done
9.配置环境变量
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "echo 'PATH=/opt/k8s/bin:$PATH' >>/root/.bashrc && source /root/.bashrc";done
10.创建相关的目录
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "mkdir -p /opt/k8s/{bin,work} /etc/{kubernetes,etcd}/cert";done
11.关闭无关服务
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "systemctl stop postfix && systemctl disable postfix";done
12.升级系统内核
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm";done
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "yum --enablerepo=elrepo-kernel install -y kernel-lt";done
设置开机从新内核启动
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "grub2-set-default 0";done
13.添加docker用户
在每台服务器上添加Docker用户
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo ">>> $i";ssh root@$i "useradd -m docker";done
[root@k8s-master01 ~]# for i in ${NODE_ALL_IPS[@]};do echo $i;ssh root@$i "id docker";done
3.重启所有服务器
在所有节点执行如下命令
[root@k8s-master01 ~]# sync && reboot
4.创建CA根证书和秘钥
以下操作在节点k8s-master01操作
将该证书分发至所有节点,包括master和node
1、安装cfssl工具集 **注意:**所有命令和文件在k8s-master1上在执行,然后将文件分发给其他节点 [root@k8s-master01 ~]# mkdir -p /opt/k8s/cert && cd /opt/k8s [root@k8s-master01 k8s]# wget https://github.com/cloudflare/cfssl/releases/download/v1.4.1/cfssl_1.4.1_linux_amd64 [root@k8s-master01 k8s]# mv cfssl_1.4.1_linux_amd64 /opt/k8s/bin/cfssl [root@k8s-master01 k8s]# wget https://github.com/cloudflare/cfssl/releases/download/v1.4.1/cfssljson_1.4.1_linux_amd64 [root@k8s-master01 k8s]# mv cfssljson_1.4.1_linux_amd64 /opt/k8s/bin/cfssljson [root@k8s-master01 k8s]# wget https://github.com/cloudflare/cfssl/releases/download/v1.4.1/cfssl-certinfo_1.4.1_linux_amd64 [root@k8s-master01 k8s]# mv cfssl-certinfo_1.4.1_linux_amd64 /opt/k8s/bin/cfssl-certinfo [root@k8s-master01 k8s]# chmod +x /opt/k8s/bin/* [root@k8s-master01 k8s]# export PATH=/opt/k8s/bin:$PATH 2.创建根证书(CA) 创建配置文件 [root@k8s-master01 k8s]# cd /opt/k8s/work [root@k8s-master01 work]# cat > ca-config.json <<EOF { "signing": { "default": { "expiry": "87600h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "876000h" } } } } EOF 创建证书签名请求文件 [root@k8s-master01 work]# cat > ca-csr.json <<EOF { "CN": "kubernetes-ca", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "k8s", "OU": "opsnull" } ], "ca": { "expiry": "876000h" } } EOF 生成CA证书和私钥 [root@k8s-master01 work]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca [root@k8s-master01 work]# ls ca* ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem 3、分发证书文件 将生成的 CA 证书、秘钥文件、配置文件拷贝到所有节点的 /etc/kubernetes/cert 目录下: [root@k8s-master1 work]# for node_all_ip in ${NODE_ALL_IPS[@]} do echo ">>> ${node_all_ip}" ssh root@${node_all_ip} "mkdir -p /etc/kubernetes/cert" scp ca*.pem ca-config.json root@${node_all_ip}:/etc/kubernetes/cert done
4.部署ETCD集群
#以下操作在节点k8s-master01操作
1.下载和分发 etcd 二进制文件
**注意:**我这里ETCD与K8S-Master集群节点都在同一机器上部署的
[root@k8s-master01 ~]# cd /opt/k8s/work/ [root@k8s-master01 work]# tar -zxvf etcd-v3.4.10-linux-amd64.tar.gz [root@k8s-master01 work]# for node_ip in ${ETCD_IPS[@]} do echo ">>> ${node_ip}" scp etcd-v3.4.10-linux-amd64/etcd* root@${node_ip}:/opt/k8s/bin ssh root@${node_ip} "chmod +x /opt/k8s/bin/*" done
2.创建etcd证书和私钥
1.创建证书签名请求
注意:这里的IP地址一定要根据自己的实际ETCD集群IP填写
[root@k8s-master01 ~]# cd /opt/k8s/work [root@k8s-master01 work]# cat > etcd-csr.json <<EOF { "CN": "etcd", "hosts": [ "127.0.0.1", "172.31.46.86", "172.31.46.83", "172.31.46.78" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "k8s", "OU": "opsnull" } ] } EOF
2.生成证书和私钥
[root@k8s-master01 work]# cfssl gencert -ca=/opt/k8s/work/ca.pem \ -ca-key=/opt/k8s/work/ca-key.pem \ -config=/opt/k8s/work/ca-config.json \ -profile=kubernetes etcd-csr.json | cfssljson -bare etcd [root@k8s-master01 work]# ls etcd*pem etcd-key.pem etcd.pem
3.分发证书和私钥至各etcd节点
[root@k8s-master01 work]# for node_ip in ${ETCD_IPS[@]} do echo ">>> ${node_ip}" ssh root@${node_ip} "mkdir -p /etc/etcd/cert" scp etcd*.pem root@${node_ip}:/etc/etcd/cert/ done
3.创建 etcd 的 systemd unit 模板文件
[root@k8s-master01 work]# cat > etcd.service.template <<EOF [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target Documentation=https://github.com/coreos [Service] Type=notify WorkingDirectory=${ETCD_DATA_DIR} ExecStart=/opt/k8s/bin/etcd \\ --data-dir=${ETCD_DATA_DIR} \\ --wal-dir=${ETCD_WAL_DIR} \\ --name=##ETCD_NAME## \\ --cert-file=/etc/etcd/cert/etcd.pem \\ --key-file=/etc/etcd/cert/etcd-key.pem \\ --trusted-ca-file=/etc/kubernetes/cert/ca.pem \\ --peer-cert-file=/etc/etcd/cert/etcd.pem \\ --peer-key-file=/etc/etcd/cert/etcd-key.pem \\ --peer-trusted-ca-file=/etc/kubernetes/cert/ca.pem \\ --peer-client-cert-auth \\ --client-cert-auth \\ --listen-peer-urls=https://##ETCD_IP##:2380 \\ --initial-advertise-peer-urls=https://##ETCD_IP##:2380 \\ --listen-client-urls=https://##ETCD_IP##:2379,http://127.0.0.1:2379 \\ --advertise-client-urls=https://##ETCD_IP##:2379 \\ --initial-cluster-token=etcd-cluster-0 \\ --initial-cluster=${ETCD_NODES} \\ --initial-cluster-state=new \\ --auto-compaction-mode=periodic \\ --auto-compaction-retention=1 \\ --max-request-bytes=33554432 \\ --quota-backend-bytes=6442450944 \\ --heartbeat-interval=250 \\ --election-timeout=2000 Restart=on-failure RestartSec=5 LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF
4.为各ETCD节点创建和分发 etcd systemd unit 文件
1.替换模板文件中的变量
[root@k8s-master01 work]# for (( i=0; i < 3; i++ )) do sed -e "s/##ETCD_NAME##/${ETCD_NAMES[i]}/" -e "s/##ETCD_IP##/${ETCD_IPS[i]}/" etcd.service.template > etcd-${ETCD_IPS[i]}.service done [root@k8s-master01 work]# ls *.service etcd-172.31.46.78.service etcd-172.31.46.83.service etcd-172.31.46.86.service
2.分发生成的 systemd unit 文件
#文件重命名为 etcd.service; [root@k8s-master1 work]# for node_ip in ${ETCD_IPS[@]} do echo ">>> ${node_ip}" scp etcd-${node_ip}.service root@${node_ip}:/etc/systemd/system/etcd.service done
3.检查配置文件
#登录到各ETC节点中,执行下面命令,确认脚本文件中的IP地址和数据存储地址是否都正确 [root@k8s-master01 work]# ls /etc/systemd/system/etcd.service /etc/systemd/system/etcd.service [root@k8s-master01 work]# vim /etc/systemd/system/etcd.service
5.启动ETCD服务器
[root@k8s-master01 work]# for node_ip in ${ETCD_IPS[@]} do echo ">>> ${node_ip}" ssh root@${node_ip} "mkdir -p ${ETCD_DATA_DIR} ${ETCD_WAL_DIR} && chmod 0700 /data/k8s/etcd/data" ssh root@${node_ip} "systemctl daemon-reload && systemctl enable etcd && systemctl restart etcd" done
6.检查启动结果
[root@k8s-master01 work]# for node_ip in ${ETCD_IPS[@]} do echo ">>> ${node_ip}" ssh root@${node_ip} "systemctl status etcd|grep Active" done 确保启动后没有报错,注意:状态为running并不代表ETCD各节点之间通信正常
7.验证服务状态
任一etcd节点执行以下命令
[root@k8s-master01 work]# for node_ip in ${ETCD_IPS[@]} do echo ">>> ${node_ip}" /opt/k8s/bin/etcdctl \ --endpoints=https://${node_ip}:2379 \ --cacert=/etc/kubernetes/cert/ca.pem \ --cert=/etc/etcd/cert/etcd.pem \ --key=/etc/etcd/cert/etcd-key.pem endpoint health done
各服务节点全部为healthy,则代表etcd集群状态正常
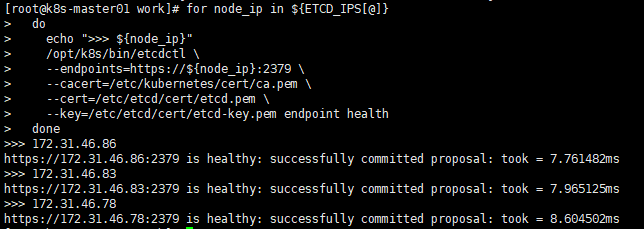
8.查看当前leader
[root@k8s-master01 work]# /opt/k8s/bin/etcdctl \ -w table --cacert=/opt/k8s/work/ca.pem \ --cert=/etc/etcd/cert/etcd.pem \ --key=/etc/etcd/cert/etcd-key.pem \ --endpoints=${ETCD_ENDPOINTS} endpoint status
可以看到当前ETCD集群leader为:172.31.46.83这台服务器

5.部署kubectl命令行工具
#以下操作在节点k8s-master01操作
1.下载和分发 kubectl 二进文件
我们这里这里将上面下载好的二进制文件传到服务器上,并解压
[root@k8s-master01 work]# tar -zxvf kubernetes-server-linux-amd64.tar.gz 分发到其他Master集群node节点 [root@k8s-master01 work]# for node_all_ip in ${NODE_ALL_IPS[@]} do echo ">>> ${node_all_ip}" scp kubernetes/server/bin/kubectl root@${node_all_ip}:/opt/k8s/bin/ ssh root@${node_all_ip} "chmod +x /opt/k8s/bin/*" done
2.创建admin证书和私钥
1.创建证书签名请求 [root@k8s-master01 ~]# cd /opt/k8s/work [root@k8s-master01 work]# cat > admin-csr.json <<EOF { "CN": "admin", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "system:masters", "OU": "opsnull" } ] } EOF 2.生成证书和私钥 [root@k8s-master01 work]# cfssl gencert -ca=/opt/k8s/work/ca.pem \ -ca-key=/opt/k8s/work/ca-key.pem \ -config=/opt/k8s/work/ca-config.json \ -profile=kubernetes admin-csr.json | cfssljson -bare admin [root@k8s-master01 work]# ls admin* admin.csr admin-csr.json admin-key.pem admin.pem
3.创建kubeconfig文件
1.设置集群参数 [root@k8s-master01 work]# kubectl config set-cluster kubernetes \ --certificate-authority=/opt/k8s/work/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=kubectl.kubeconfig 2.设置客户端参数 [root@k8s-master01 work]# kubectl config set-credentials admin \ --client-certificate=/opt/k8s/work/admin.pem \ --client-key=/opt/k8s/work/admin-key.pem \ --embed-certs=true \ --kubeconfig=kubectl.kubeconfig 3.设置上下文参数 [root@k8s-master01 work]# kubectl config set-context kubernetes \ --cluster=kubernetes \ --user=admin \ --kubeconfig=kubectl.kubeconfig 4.设置默认上下文 [root@k8s-master01 work]# kubectl config use-context kubernetes --kubeconfig=kubectl.kubeconfig
4.分发kubeconfig文件
[root@k8s-master1 work]# for node_all_ip in ${NODE_ALL_IPS[@]} do echo ">>> ${node_all_ip}" ssh root@${node_all_ip} "mkdir -p ~/.kube" scp kubectl.kubeconfig root@${node_all_ip}:~/.kube/config done
5.确保kubectl已经可以使用
#登录集群中所有节点,测试执行如下命令确保Master节点和Work节点的kubectl命令都可以使用
[root@k8s-master01 work]# kubectl --help
6.部署master节点前期基础组件环境准备
kubernetes master 节点运行如下组件:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
kube-apiserver、kube-scheduler 和 kube-controller-manager 均以多实例模式运行:
- kube-scheduler 和 kube-controller-manager 会自动选举产生一个 leader 实例,其它实例处于阻塞模式,当 leader 挂了后,重新选举产生新的 leader,从而保证服务可用性;
- kube-apiserver 是无状态的,可以通过 kube-nginx 进行代理访问从而保证服务可用性;
注意: 如果三台Master节点仅仅作为集群管理节点的话,那么则无需部署docker、kubelet、kube-proxy组件;但是如果后期要部署mertics-server(集群核心监控数据的聚合器。通俗地说,它存储了集群中各节点的监控数据,并且提供了API以供分析和使用)、istio组件(提供一种简单的方式来为已部署的服务建立网络,该网络具有负载均衡、服务间认证、监控等功能,而不需要对服务的代码做任何改动。)服务时会出现无法运行的情况,所以还是建议master节点也部署docker、kubelet、kube-proxy组件
1.下载程序包并解压 这里因为我们在上面部署kubectl命令行工具下载过相关二进制文件包了,并进行了解压了。所以我们这里直接执行如下命令就OK了 [root@k8s-master01 ~]# cd /opt/k8s/work/kubernetes/ [root@k8s-master01 kubernetes]# ll total 33164 drwxr-xr-x 2 root root 6 Jan 13 21:40 addons -rw-r--r-- 1 root root 32661131 Jan 13 21:40 kubernetes-src.tar.gz -rw-r--r-- 1 root root 1297747 Jan 13 21:40 LICENSES drwxr-xr-x 3 root root 17 Jan 13 21:36 server [root@k8s-master01 kubernetes]# tar -zxvf kubernetes-src.tar.gz 2.分发二进制文件 将解压后的二进制文件拷贝到所有的K8S-Master集群的节点服务器上 将kuberlet,kube-proxy分发给所有worker节点,存储目录/opt/k8s/bin [root@k8s-master01 ~]# cd /opt/k8s/work [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" scp kubernetes/server/bin/{apiextensions-apiserver,kube-apiserver,kube-controller-manager,kube-proxy,kube-scheduler,kubeadm,kubectl,kubelet,mounter} root@${node_ip}:/opt/k8s/bin/ ssh root@${node_ip} "chmod +x /opt/k8s/bin/*" done [root@k8s-master01 work]# for node_ip in ${WORK_IPS[@]} do echo ">>> ${node_ip}" scp kubernetes/server/bin/{kube-proxy,kubelet} root@${node_ip}:/opt/k8s/bin/ ssh root@${node_ip} "chmod +x /opt/k8s/bin/*" done
7.部署kube-apiserver集群
1.创建 kubernetes-master 证书和私钥
#hosts 字段指定授权使用该证书的 IP 和域名列表,这里列出了 master 节点 IP、kubernetes 服务的 IP 和域名; [root@k8s-master01 ~]# cd /opt/k8s/work/ [root@k8s-master01 work]# cat > kubernetes-csr.json <<EOF { "CN": "kubernetes-master", "hosts": [ "127.0.0.1",
"172.31.46.47", "172.31.46.86", "172.31.46.83", "172.31.46.78", "${CLUSTER_KUBERNETES_SVC_IP}", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local.", "kubernetes.default.svc.${CLUSTER_DNS_DOMAIN}." ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "k8s", "OU": "opsnull" } ] } EOF #生成证书和私钥 [root@k8s-master01 work]# cfssl gencert -ca=/opt/k8s/work/ca.pem \ -ca-key=/opt/k8s/work/ca-key.pem \ -config=/opt/k8s/work/ca-config.json \ -profile=kubernetes kubernetes-csr.json | cfssljson -bare kubernetes [root@k8s-master01 work]# ls kubernetes*pem kubernetes-key.pem kubernetes.pem #将生成的证书和私钥文件拷贝到所有 master 节点 [root@k8s-master1 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" ssh root@${node_ip} "mkdir -p /etc/kubernetes/cert" scp kubernetes*.pem root@${node_ip}:/etc/kubernetes/cert/ done
2.创建加密配置文件
[root@k8s-master01 work]# cat > encryption-config.yaml <<EOF kind: EncryptionConfig apiVersion: v1 resources: - resources: - secrets providers: - aescbc: keys: - name: key1 secret: ${ENCRYPTION_KEY} - identity: {} EOF 将加密配置文件拷贝到 master 节点的 /etc/kubernetes 目录下 [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" scp encryption-config.yaml root@${node_ip}:/etc/kubernetes/ done
3.创建和分发审计策略文件
[root@k8s-master01 work]# cat > audit-policy.yaml <<EOF apiVersion: audit.k8s.io/v1beta1 kind: Policy rules: # The following requests were manually identified as high-volume and low-risk, so drop them. - level: None resources: - group: "" resources: - endpoints - services - services/status users: - 'system:kube-proxy' verbs: - watch - level: None resources: - group: "" resources: - nodes - nodes/status userGroups: - 'system:nodes' verbs: - get - level: None namespaces: - kube-system resources: - group: "" resources: - endpoints users: - 'system:kube-controller-manager' - 'system:kube-scheduler' - 'system:serviceaccount:kube-system:endpoint-controller' verbs: - get - update - level: None resources: - group: "" resources: - namespaces - namespaces/status - namespaces/finalize users: - 'system:apiserver' verbs: - get # Don't log HPA fetching metrics. - level: None resources: - group: metrics.k8s.io users: - 'system:kube-controller-manager' verbs: - get - list # Don't log these read-only URLs. - level: None nonResourceURLs: - '/healthz*' - /version - '/swagger*' # Don't log events requests. - level: None resources: - group: "" resources: - events # node and pod status calls from nodes are high-volume and can be large, don't log responses # for expected updates from nodes - level: Request omitStages: - RequestReceived resources: - group: "" resources: - nodes/status - pods/status users: - kubelet - 'system:node-problem-detector' - 'system:serviceaccount:kube-system:node-problem-detector' verbs: - update - patch - level: Request omitStages: - RequestReceived resources: - group: "" resources: - nodes/status - pods/status userGroups: - 'system:nodes' verbs: - update - patch # deletecollection calls can be large, don't log responses for expected namespace deletions - level: Request omitStages: - RequestReceived users: - 'system:serviceaccount:kube-system:namespace-controller' verbs: - deletecollection # Secrets, ConfigMaps, and TokenReviews can contain sensitive & binary data, # so only log at the Metadata level. - level: Metadata omitStages: - RequestReceived resources: - group: "" resources: - secrets - configmaps - group: authentication.k8s.io resources: - tokenreviews # Get repsonses can be large; skip them. - level: Request omitStages: - RequestReceived resources: - group: "" - group: admissionregistration.k8s.io - group: apiextensions.k8s.io - group: apiregistration.k8s.io - group: apps - group: authentication.k8s.io - group: authorization.k8s.io - group: autoscaling - group: batch - group: certificates.k8s.io - group: extensions - group: metrics.k8s.io - group: networking.k8s.io - group: policy - group: rbac.authorization.k8s.io - group: scheduling.k8s.io - group: settings.k8s.io - group: storage.k8s.io verbs: - get - list - watch # Default level for known APIs - level: RequestResponse omitStages: - RequestReceived resources: - group: "" - group: admissionregistration.k8s.io - group: apiextensions.k8s.io - group: apiregistration.k8s.io - group: apps - group: authentication.k8s.io - group: authorization.k8s.io - group: autoscaling - group: batch - group: certificates.k8s.io - group: extensions - group: metrics.k8s.io - group: networking.k8s.io - group: policy - group: rbac.authorization.k8s.io - group: scheduling.k8s.io - group: settings.k8s.io - group: storage.k8s.io # Default level for all other requests. - level: Metadata omitStages: - RequestReceived EOF 分发审计策略文件 [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" scp audit-policy.yaml root@${node_ip}:/etc/kubernetes/audit-policy.yaml done
4.创建后续访问 metrics-server 或 kube-prometheus 使用的证书
1.创建证书签名请求 [root@k8s-master01 work]# cat > proxy-client-csr.json <<EOF { "CN": "aggregator", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "k8s", "OU": "opsnull" } ] } EOF 2.生成证书和私钥 [root@k8s-master01 work]# cfssl gencert -ca=/etc/kubernetes/cert/ca.pem \ -ca-key=/etc/kubernetes/cert/ca-key.pem \ -config=/etc/kubernetes/cert/ca-config.json \ -profile=kubernetes proxy-client-csr.json | cfssljson -bare proxy-client [root@k8s-master01 work]# ls proxy-client*.pem proxy-client-key.pem proxy-client.pem 3.将生成的证书和私钥文件拷贝到所有 master 节点 [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" scp proxy-client*.pem root@${node_ip}:/etc/kubernetes/cert/ done
5.创建kube-apiserver systemd unit 模板文件
[root@k8s-master01 work]# cat > kube-apiserver.service.template <<EOF [Unit] Description=Kubernetes API Server Documentation=https://github.com/GoogleCloudPlatform/kubernetes After=network.target [Service] WorkingDirectory=${K8S_DIR}/kube-apiserver ExecStart=/opt/k8s/bin/kube-apiserver \\ --advertise-address=##MASTER_IP## \\ --default-not-ready-toleration-seconds=360 \\ --default-unreachable-toleration-seconds=360 \\ --feature-gates=DynamicAuditing=true \\ --max-mutating-requests-inflight=2000 \\ --max-requests-inflight=4000 \\ --default-watch-cache-size=200 \\ --delete-collection-workers=2 \\ --encryption-provider-config=/etc/kubernetes/encryption-config.yaml \\ --etcd-cafile=/etc/kubernetes/cert/ca.pem \\ --etcd-certfile=/etc/kubernetes/cert/kubernetes.pem \\ --etcd-keyfile=/etc/kubernetes/cert/kubernetes-key.pem \\ --etcd-servers=${ETCD_ENDPOINTS} \\ --bind-address=##MASTER_IP## \\ --secure-port=6443 \\ --tls-cert-file=/etc/kubernetes/cert/kubernetes.pem \\ --tls-private-key-file=/etc/kubernetes/cert/kubernetes-key.pem \\ --insecure-port=0 \\ --audit-dynamic-configuration \\ --audit-log-maxage=15 \\ --audit-log-maxbackup=3 \\ --audit-log-maxsize=100 \\ --audit-log-truncate-enabled \\ --audit-log-path=${K8S_DIR}/kube-apiserver/audit.log \\ --audit-policy-file=/etc/kubernetes/audit-policy.yaml \\ --profiling \\ --anonymous-auth=false \\ --client-ca-file=/etc/kubernetes/cert/ca.pem \\ --enable-bootstrap-token-auth \\ --requestheader-allowed-names="aggregator" \\ --requestheader-client-ca-file=/etc/kubernetes/cert/ca.pem \\ --requestheader-extra-headers-prefix="X-Remote-Extra-" \\ --requestheader-group-headers=X-Remote-Group \\ --requestheader-username-headers=X-Remote-User \\ --service-account-key-file=/etc/kubernetes/cert/ca.pem \\ --authorization-mode=Node,RBAC \\ --runtime-config=api/all=true \\ --enable-admission-plugins=NodeRestriction \\ --allow-privileged=true \\ --apiserver-count=3 \\ --event-ttl=168h \\ --kubelet-certificate-authority=/etc/kubernetes/cert/ca.pem \\ --kubelet-client-certificate=/etc/kubernetes/cert/kubernetes.pem \\ --kubelet-client-key=/etc/kubernetes/cert/kubernetes-key.pem \\ --kubelet-https=true \\ --kubelet-timeout=10s \\ --proxy-client-cert-file=/etc/kubernetes/cert/proxy-client.pem \\ --proxy-client-key-file=/etc/kubernetes/cert/proxy-client-key.pem \\ --service-cluster-ip-range=${SERVICE_CIDR} \\ --service-node-port-range=${NODE_PORT_RANGE} \\ --logtostderr=true \\ --v=2 Restart=on-failure RestartSec=10 Type=notify LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF
6.为各节点创建和分发 kube-apiserver systemd unit 文件
1.创建systemd unit 文件 [root@k8s-master01 work]# for (( i=0; i < 3; i++ )) do sed -e "s/##NODE_NAME##/${NODE_ALL_NAMES[i]}/" -e "s/##MASTER_IP##/${MASTER_IPS[i]}/" kube-apiserver.service.template > kube-apiserver-${MASTER_IPS[i]}.service done [root@k8s-master01 work]# ls kube-apiserver*.service kube-apiserver-172.31.46.78.service kube-apiserver-172.31.46.83.service kube-apiserver-172.31.46.86.service 2.分发生成的 systemd unit 文件 [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" scp kube-apiserver-${node_ip}.service root@${node_ip}:/etc/systemd/system/kube-apiserver.service done
7.启动 kube-apiserver 服务
[root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" ssh root@${node_ip} "mkdir -p ${K8S_DIR}/kube-apiserver" ssh root@${node_ip} "systemctl daemon-reload && systemctl enable kube-apiserver && systemctl restart kube-apiserver" done
8.检查 kube-apiserver 运行状态
[root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" ssh root@${node_ip} "systemctl status kube-apiserver |grep 'Active:'" done
9.检查集群信息
[root@k8s-master01 work]# kubectl cluster-info
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
Unable to connect to the server: dial tcp 172.31.46.47:8443: connect: no route to host
[root@k8s-master01 work]# kubectl get all --all-namespaces
Unable to connect to the server: dial tcp 172.31.46.47:8443: connect: no route to host
#查看集群状态信息 [root@k8s-master01 work]# kubectl get componentstatuses
Unable to connect to the server: dial tcp 172.31.46.47:8443: connect: no route to host
#出现上面的信息没事,是因为我们还没有配置vip172.31.46.47,这个我们会在下面api-server高可用方案里配置

8. 基于nginx四层代理(kube-apiserver 高可用方案)
这里采用nginx 4 层透明代理功能实现 K8S 节点( master 节点和 worker 节点)高可用访问 kube-apiserver。控制节点的 kube-controller-manager、kube-scheduler 是多实例(3个)部署,所以只要有一个实例正常,就可以保证高可用;搭建nginx+keepalived环境,对外提供一个统一的vip地址,后端对接多个 apiserver 实例,nginx 对它们做健康检查和负载均衡;kubelet、kube-proxy、controller-manager、scheduler 通过vip地址访问 kube-apiserver,从而实现 kube-apiserver 的高可用;
1.安装和配置nginx
下面操作在172.31.46.76、172.31.46.100两个节点机器上同样操作,也就是上面规划的k8s-ha01和k8s-ha02节点。
1.下载和编译 nginx 官方nginx下载地址:https://nginx.org/download/nginx-1.15.3.tar.gz 由于国内通过官方地址下载很慢,所以我这里使用国内源进行下载 [root@k8s-ha01 ~]# mkdir /opt/k8s/work -p [root@k8s-ha01 ~]# yum -y install gcc pcre-devel zlib-devel openssl-devel wget lsof [root@k8s-ha01 ~]# cd /opt/k8s/work [root@k8s-ha01 work]# wget https://mirrors.huaweicloud.com/nginx/nginx-1.15.3.tar.gz [root@k8s-ha01 work]# tar -xzvf nginx-1.15.3.tar.gz [root@k8s-ha01 work]# cd nginx-1.15.3 [root@k8s-ha01 nginx-1.15.3]# mkdir nginx-prefix [root@k8s-ha01 nginx-1.15.3]# ./configure --with-stream --without-http --prefix=$(pwd)/nginx-prefix --without-http_uwsgi_module --without-http_scgi_module --without-http_fastcgi_module 解决说明: --with-stream:开启 4 层透明转发(TCP Proxy)功能; --without-xxx:关闭所有其他功能,这样生成的动态链接二进制程序依赖最小; 继续编译和安装: [root@k8s-ha01 nginx-1.15.3]# make && make install 2.验证编译的 nginx [root@k8s-ha01 nginx-1.15.3]# ./nginx-prefix/sbin/nginx -v nginx version: nginx/1.15.3 查看 nginx 动态链接的库: [root@k8s-ha01 nginx-1.15.3]# ldd ./nginx-prefix/sbin/nginx linux-vdso.so.1 => (0x00007ffeab3f9000) libdl.so.2 => /lib64/libdl.so.2 (0x00007fbe69175000) libpthread.so.0 => /lib64/libpthread.so.0 (0x00007fbe68f59000) libc.so.6 => /lib64/libc.so.6 (0x00007fbe68b8c000) /lib64/ld-linux-x86-64.so.2 (0x00007fbe69379000) 由于只开启了 4 层透明转发功能,所以除了依赖 libc 等操作系统核心 lib 库外,没有对其它 lib 的依赖(如 libz、libssl 等),这样可以方便部署到各版本操作系统中; 3.安装和部署 nginx [root@k8s-ha01 nginx-1.15.3]# mkdir -p /opt/k8s/kube-nginx/{conf,logs,sbin} [root@k8s-ha01 nginx-1.15.3]# cp /opt/k8s/work/nginx-1.15.3/nginx-prefix/sbin/nginx /opt/k8s/kube-nginx/sbin/kube-nginx [root@k8s-ha01 nginx-1.15.3]# chmod a+x /opt/k8s/kube-nginx/sbin/* 配置 nginx,开启 4 层透明转发功能: [root@k8s-ha01 nginx-1.15.3]# vim /opt/k8s/kube-nginx/conf/kube-nginx.conf worker_processes 2; events { worker_connections 65525; } stream { upstream backend { hash $remote_addr consistent; server 172.31.46.86:6443 max_fails=3 fail_timeout=30s; server 172.31.46.63:6443 max_fails=3 fail_timeout=30s; server 172.31.46.78:6443 max_fails=3 fail_timeout=30s; } server { listen 8443; proxy_connect_timeout 1s; proxy_pass backend; } } [root@k8s-ha01 nginx-1.15.3]# vim /etc/security/limits.conf # 文件底部添加下面四行内容 * soft nofile 65525 * hard nofile 65525 * soft nproc 65525 * hard nproc 65525 4.配置 systemd unit 文件,启动服务 [root@k8s-ha01 nginx-1.15.3]# vim /etc/systemd/system/kube-nginx.service [Unit] Description=kube-apiserver nginx proxy After=network.target After=network-online.target Wants=network-online.target [Service] Type=forking ExecStartPre=/opt/k8s/kube-nginx/sbin/kube-nginx -c /opt/k8s/kube-nginx/conf/kube-nginx.conf -p /opt/k8s/kube-nginx -t ExecStart=/opt/k8s/kube-nginx/sbin/kube-nginx -c /opt/k8s/kube-nginx/conf/kube-nginx.conf -p /opt/k8s/kube-nginx ExecReload=/opt/k8s/kube-nginx/sbin/kube-nginx -c /opt/k8s/kube-nginx/conf/kube-nginx.conf -p /opt/k8s/kube-nginx -s reload PrivateTmp=true Restart=always RestartSec=5 StartLimitInterval=0 LimitNOFILE=65536 [Install] WantedBy=multi-user.target [root@k8s-ha01 nginx-1.15.3]# systemctl daemon-reload && systemctl enable kube-nginx && systemctl restart kube-nginx [root@k8s-ha01 nginx-1.15.3]# lsof -i:8443 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME kube-ngin 20267 root 5u IPv4 2075418 0t0 TCP *:pcsync-https (LISTEN) kube-ngin 20268 nobody 5u IPv4 2075418 0t0 TCP *:pcsync-https (LISTEN) kube-ngin 20269 nobody 5u IPv4 2075418 0t0 TCP *:pcsync-https (LISTEN)
2.安装和配置keepalived
下面操作在172.31.46.22、172.31.46.3两个节点机器上操作,也就是上面规划的k8s-ha01和k8s-ha02节点。
1.编译安装keepalived (两个节点上同样操作) [root@k8s-ha01 ~]# cd /opt/k8s/work/ [root@k8s-ha01 work]# wget https://www.keepalived.org/software/keepalived-2.0.16.tar.gz [root@k8s-ha01 work]# tar -zvxf keepalived-2.0.16.tar.gz [root@k8s-ha01 work]# cd keepalived-2.0.16 [root@k8s-ha01 keepalived-2.0.16]# ./configure [root@k8s-ha01 keepalived-2.0.16]# make && make install [root@k8s-ha01 keepalived-2.0.16]# cp keepalived/etc/init.d/keepalived /etc/rc.d/init.d/ [root@k8s-ha01 keepalived-2.0.16]# cp /usr/local/etc/sysconfig/keepalived /etc/sysconfig/ [root@k8s-ha01 keepalived-2.0.16]# mkdir /etc/keepalived [root@k8s-ha01 keepalived-2.0.16]# cp /usr/local/etc/keepalived/keepalived.conf /etc/keepalived/ [root@k8s-ha01 keepalived-2.0.16]# cp /usr/local/sbin/keepalived /usr/sbin/ [root@k8s-ha01 keepalived-2.0.16]# echo "/etc/init.d/keepalived start" >> /etc/rc.local 2.配置keepalived 172.31.46.76(也就是k8s-ha01节点上的keepalived配置内容) [root@k8s-ha01 ~]# cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak [root@k8s-ha01 ~]# >/etc/keepalived/keepalived.conf [root@k8s-ha01 ~]# vim /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { notification_email { ops@wangshibo.cn tech@wangshibo.cn } notification_email_from ops@wangshibo.cn smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id master-node } vrrp_script chk_http_port { script "/opt/chk_nginx.sh" interval 2 weight -5 fall 2 rise 1 } vrrp_instance VI_1 { state MASTER interface eth0 mcast_src_ip 172.31.46.76 virtual_router_id 51 priority 101 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 172.31.46.47 } track_script { chk_http_port } } 另一个节点172.31.46.100上的keepalived配置内容为: [root@k8s-ha02 ~]# cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak [root@k8s-ha02 ~]# >/etc/keepalived/keepalived.conf [root@k8s-ha02 ~]# vim /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { notification_email { ops@wangshibo.cn tech@wangshibo.cn } notification_email_from ops@wangshibo.cn smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id slave-node } vrrp_script chk_http_port { script "/opt/chk_nginx.sh" interval 2 weight -5 fall 2 rise 1 } vrrp_instance VI_1 { state MASTER interface eth0 mcast_src_ip 172.31.46.100 virtual_router_id 51 priority 99 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 172.31.46.47 } track_script { chk_http_port } } 3.配置两个节点的nginx监控脚本(该脚本会在keepalived.conf配置中被引用) [root@k8s-ha01 ~]# vim /opt/chk_nginx.sh #!/bin/bash counter=$(ps -ef|grep -w kube-nginx|grep -v grep|wc -l) if [ "${counter}" = "0" ]; then systemctl start kube-nginx sleep 2 counter=$(ps -ef|grep kube-nginx|grep -v grep|wc -l) if [ "${counter}" = "0" ]; then /etc/init.d/keepalived stop fi fi [root@k8s-ha01 ~]# chmod 755 /opt/chk_nginx.sh 4.启动两个节点的keepalived服务 [root@k8s-ha01 ~]# /etc/init.d/keepalived start Starting keepalived (via systemctl): [ OK ] [root@k8s-ha01 ~]# ps -ef|grep keepalived root 5272 1 0 17:04 ? 00:00:00 /usr/local/sbin/keepalived -D root 5273 5272 0 17:04 ? 00:00:00 /usr/local/sbin/keepalived -D root 5485 5200 0 17:05 pts/0 00:00:00 grep --color=auto keepalived 查看vip情况. 发现vip默认起初会在ha01节点上 [root@k8s-ha01 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether fa:16:3e:c2:12:da brd ff:ff:ff:ff:ff:ff inet 172.31.46.76/24 brd 172.31.46.255 scope global noprefixroute dynamic eth0 valid_lft 41140sec preferred_lft 41140sec inet 172.31.46.47/32 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::f816:3eff:fec2:12da/64 scope link valid_lft forever preferred_lft forever 5.测试vip故障转移 [root@k8s-ha01 ~]# /etc/init.d/keepalived stop Stopping keepalived (via systemctl): [ OK ] [root@k8s-ha01 ~]# ps -ef |grep keepalived root 6136 5200 0 17:07 pts/0 00:00:00 grep --color=auto keepalived [root@k8s-ha01 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether fa:16:3e:c2:12:da brd ff:ff:ff:ff:ff:ff inet 172.31.46.76/24 brd 172.31.46.255 scope global noprefixroute dynamic eth0 valid_lft 41017sec preferred_lft 41017sec inet6 fe80::f816:3eff:fec2:12da/64 scope link valid_lft forever preferred_lft forever [root@k8s-ha02 keepalived-2.0.16]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether fa:16:3e:4b:cb:24 brd ff:ff:ff:ff:ff:ff inet 172.31.46.100/24 brd 172.31.46.255 scope global noprefixroute dynamic eth0 valid_lft 26175sec preferred_lft 26175sec inet 172.31.46.67/32 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::f816:3eff:fe4b:cb24/64 scope link valid_lft forever preferred_lft forever 测试发现: 当ha01(主)节点的keepalived服务挂掉,vip会自动漂移到ha02(从)节点上 当ha01(主)节点的keepliaved服务恢复后,从将vip资源从ha02(从)节点重新抢占回来(keepalived配置文件中的priority优先级决定的) 并且当两个节点的nginx挂掉后,keepaived会引用nginx监控脚本自启动nginx服务,如启动失败,则强杀keepalived服务,从而实现vip转移。
9.部署高可用kube-controller-manager集群
该集群包含 3 个节点,启动后将通过竞争选举机制产生一个 leader 节点,其它节点为阻塞状态。当 leader 节点不可用时,阻塞的节点将再次进行选举产生新的 leader 节点,从而保证服务的可用性。
为保证通信安全,本文档先生成 x509 证书和私钥,kube-controller-manager 在如下两种情况下使用该证书:
- 与 kube-apiserver 的安全端口通信;
- 在安全端口(https,10252) 输出 prometheus 格式的 metrics;
1.创建和分发kube-controller-manager 证书和私钥
1.创建证书签名请求 [root@k8s-master01 ~]# cd /opt/k8s/work [root@k8s-master01 work]# cat > kube-controller-manager-csr.json <<EOF { "CN": "system:kube-controller-manager", "key": { "algo": "rsa", "size": 2048 }, "hosts": [ "127.0.0.1", "172.31.46.86", "172.31.46.83", "172.31.46.78" ], "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "system:kube-controller-manager", "OU": "opsnull" } ] } EOF 2.生成证书和私钥 [root@k8s-master01 ~]# cd /opt/k8s/work [root@k8s-master01 work]# cfssl gencert -ca=/opt/k8s/work/ca.pem \ -ca-key=/opt/k8s/work/ca-key.pem \ -config=/opt/k8s/work/ca-config.json \ -profile=kubernetes kube-controller-manager-csr.json | cfssljson -bare kube-controller-manager [root@k8s-master01 work]# ls kube-controller-manager*pem kube-controller-manager-key.pem kube-controller-manager.pem 3.将生成的证书和私钥分发到所有 master 节点 [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" scp kube-controller-manager*.pem root@${node_ip}:/etc/kubernetes/cert/ done
2.创建和分发kubeconfig 文件
[root@k8s-master01 ~]# cd /opt/k8s/work [root@k8s-master01 work]# kubectl config set-cluster kubernetes \ --certificate-authority=/opt/k8s/work/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=kube-controller-manager.kubeconfig [root@k8s-master01 work]# kubectl config set-credentials system:kube-controller-manager \ --client-certificate=kube-controller-manager.pem \ --client-key=kube-controller-manager-key.pem \ --embed-certs=true \ --kubeconfig=kube-controller-manager.kubeconfig [root@k8s-master01 work]# kubectl config set-context system:kube-controller-manager \ --cluster=kubernetes \ --user=system:kube-controller-manager \ --kubeconfig=kube-controller-manager.kubeconfig [root@k8s-master01 work]# kubectl config use-context system:kube-controller-manager --kubeconfig=kube-controller-manager.kubeconfig #分发 kubeconfig 到所有 master 节点 [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}"
scp kube-controller-manager.kubeconfig root@${node_ip}:/etc/kubernetes/kube-controller-manager.kubeconfig done
3.创建和分发 kube-controller-manager systemd unit 模板文件
[root@k8s-master01 work]# cat > kube-controller-manager.service.template <<EOF [Unit] Description=Kubernetes Controller Manager Documentation=https://github.com/GoogleCloudPlatform/kubernetes [Service] WorkingDirectory=${K8S_DIR}/kube-controller-manager ExecStart=/opt/k8s/bin/kube-controller-manager \\ --profiling \\ --cluster-name=kubernetes \\ --controllers=*,bootstrapsigner,tokencleaner \\ --kube-api-qps=1000 \\ --kube-api-burst=2000 \\ --leader-elect \\ --use-service-account-credentials\\ --concurrent-service-syncs=2 \\ --bind-address=##NODE_IP## \\ --secure-port=10252 \\ --tls-cert-file=/etc/kubernetes/cert/kube-controller-manager.pem \\ --tls-private-key-file=/etc/kubernetes/cert/kube-controller-manager-key.pem \\ --port=0 \\ --authentication-kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \\ --client-ca-file=/etc/kubernetes/cert/ca.pem \\ --requestheader-allowed-names="aggregator" \\ --requestheader-client-ca-file=/etc/kubernetes/cert/ca.pem \\ --requestheader-extra-headers-prefix="X-Remote-Extra-" \\ --requestheader-group-headers=X-Remote-Group \\ --requestheader-username-headers=X-Remote-User \\ --authorization-kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \\ --cluster-signing-cert-file=/etc/kubernetes/cert/ca.pem \\ --cluster-signing-key-file=/etc/kubernetes/cert/ca-key.pem \\ --experimental-cluster-signing-duration=876000h \\ --horizontal-pod-autoscaler-sync-period=10s \\ --concurrent-deployment-syncs=10 \\ --concurrent-gc-syncs=30 \\ --node-cidr-mask-size=24 \\ --service-cluster-ip-range=${SERVICE_CIDR} \\ --pod-eviction-timeout=6m \\ --terminated-pod-gc-threshold=10000 \\ --root-ca-file=/etc/kubernetes/cert/ca.pem \\ --service-account-private-key-file=/etc/kubernetes/cert/ca-key.pem \\ --kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \\ --logtostderr=true \\ --v=2 Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target EOF #为各Master节点创建和分发 kube-controller-mananger systemd unit 文件 #替换模板文件中的变量 [root@k8s-master01 work]# for (( i=0; i < 3; i++ )) do sed -e "s/##NODE_NAME##/${NODE_ALL_NAMES[i]}/" -e "s/##NODE_IP##/${MASTER_IPS[i]}/" kube-controller-manager.service.template > kube-controller-manager-${NODE_ALL_IPS[i]}.service done 分发至给Master节点 [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" scp kube-controller-manager-${node_ip}.service root@${node_ip}:/etc/systemd/system/kube-controller-manager.service done
4.启动kube-controller-manager服务
[root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" ssh root@${node_ip} "mkdir -p ${K8S_DIR}/kube-controller-manager" ssh root@${node_ip} "systemctl daemon-reload && systemctl enable kube-controller-manager && systemctl restart kube-controller-manager" done
5.检查服务运行状态
[root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" ssh root@${node_ip} "systemctl status kube-controller-manager|grep Active" done #kube-controller-manager 监听 10252 端口,接收 https 请求 [root@k8s-master01 work]# netstat -lnpt | grep kube-cont tcp 0 0 172.31.46.86:10252 0.0.0.0:* LISTEN 21668/kube-controll
6.查看输出的 metrics
注意:以下命令在 任意kube-controller-manager 节点上执行。 curl -s --cacert /opt/k8s/work/ca.pem --cert /opt/k8s/work/admin.pem --key /opt/k8s/work/admin-key.pem https://172.31.46.86:10252/metrics |head

7.查看当前的 leader
[root@k8s-master01 work]# kubectl get endpoints kube-controller-manager --namespace=kube-system -o yaml
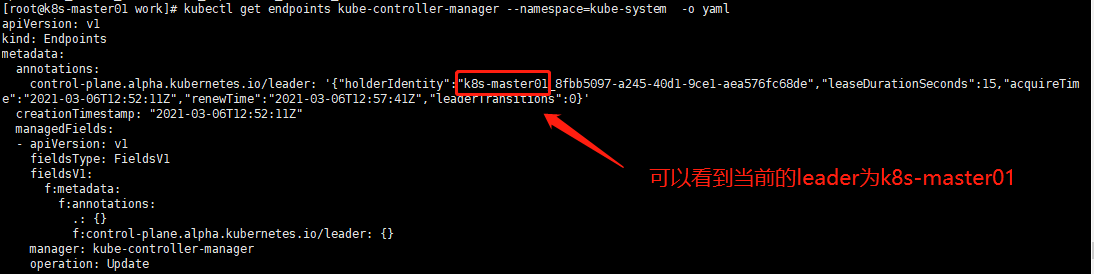
10.部署高可用 kube-scheduler 集群
1.创建和分发 kube-scheduler 证书和私钥
1.创建证书签名请求 #注意hosts填写自己服务器master集群IP [root@k8s-master01 ~]# cd /opt/k8s/work [root@k8s-master01 work]# cat > kube-scheduler-csr.json <<EOF { "CN": "system:kube-scheduler", "hosts": [ "127.0.0.1", "172.31.46.86", "172.31.46.83", "172.31.46.78" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "system:kube-scheduler", "OU": "opsnull " } ] } EOF 2.生成证书和私钥 [root@k8s-master01 work]# cfssl gencert -ca=/opt/k8s/work/ca.pem \ -ca-key=/opt/k8s/work/ca-key.pem \ -config=/opt/k8s/work/ca-config.json \ -profile=kubernetes kube-scheduler-csr.json | cfssljson -bare kube-scheduler [root@k8s-master01 work]# ls kube-scheduler*pem kube-scheduler-key.pem kube-scheduler.pem 3.将生成的证书和私钥分发到所有 master 节点 [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" scp kube-scheduler*.pem root@${node_ip}:/etc/kubernetes/cert/ done
2.创建和分发 kubeconfig 文件
kube-scheduler 使用 kubeconfig 文件访问 apiserver,该文件提供了 apiserver 地址、嵌入的 CA 证书和 kube-scheduler 证书
1.创建kuberconfig文件
[root@k8s-master01 ~]# cd /opt/k8s/work
[root@k8s-master01 work]# kubectl config set-cluster kubernetes \
--certificate-authority=/opt/k8s/work/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-scheduler.kubeconfig
[root@k8s-master01 work]# kubectl config set-credentials system:kube-scheduler \
--client-certificate=kube-scheduler.pem \
--client-key=kube-scheduler-key.pem \
--embed-certs=true \
--kubeconfig=kube-scheduler.kubeconfig
[root@k8s-master01 work]# kubectl config set-context system:kube-scheduler \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=kube-scheduler.kubeconfig
[root@k8s-master01 work]# kubectl config use-context system:kube-scheduler --kubeconfig=kube-scheduler.kubeconfig
2.分发 kubeconfig 到所有 master 节点
[root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]}
do
echo ">>> ${node_ip}"
scp kube-scheduler.kubeconfig root@${node_ip}:/etc/kubernetes/kube-scheduler.kubeconfig
done
3.创建 和分发kube-scheduler 配置文件
1.创建kube-scheduler配置文件 [root@k8s-master01 ~]# cd /opt/k8s/work [root@k8s-master01 work]# cat <<EOF | sudo tee kube-scheduler.yaml apiVersion: kubescheduler.config.k8s.io/v1alpha1 kind: KubeSchedulerConfiguration clientConnection: kubeconfig: "/etc/kubernetes/kube-scheduler.kubeconfig" leaderElection: leaderElect: true EOF 2.分发 kube-scheduler 配置文件到所有 master 节点 [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" scp kube-scheduler.yaml root@${node_ip}:/etc/kubernetes/ done
4.创建 kube-scheduler systemd unit 模板文件
[root@k8s-master01 ~]# cd /opt/k8s/work [root@k8s-master01 work]# cat > kube-scheduler.service.template <<EOF [Unit] Description=Kubernetes Scheduler Documentation=https://github.com/GoogleCloudPlatform/kubernetes [Service] WorkingDirectory=${K8S_DIR}/kube-scheduler ExecStart=/opt/k8s/bin/kube-scheduler \\ --config=/etc/kubernetes/kube-scheduler.yaml \\ --bind-address=##NODE_IP## \\ --secure-port=10259 \\ --port=0 \\ --tls-cert-file=/etc/kubernetes/cert/kube-scheduler.pem \\ --tls-private-key-file=/etc/kubernetes/cert/kube-scheduler-key.pem \\ --authentication-kubeconfig=/etc/kubernetes/kube-scheduler.kubeconf ig \\ --client-ca-file=/etc/kubernetes/cert/ca.pem \\ --requestheader-allowed-names="" \\ --requestheader-client-ca-file=/etc/kubernetes/cert/ca.pem \\ --requestheader-extra-headers-prefix="X-Remote-Extra-" \\ --requestheader-group-headers=X-Remote-Group \\ --requestheader-username-headers=X-Remote-User \\ --authorization-kubeconfig=/etc/kubernetes/kube-scheduler.kubeconfi g \\ --logtostderr=true \\ --v=2 Restart=always RestartSec=5 StartLimitInterval=0 [Install] WantedBy=multi-user.target EOF
5.为各节点创建和分发 kube-scheduler systemd unit 文件
[root@k8s-master01 work]# for (( i=0; i < 3; i++ )) do sed -e "s/##NODE_NAME##/${NODE_ALL_NAMES[i]}/" -e "s/##NODE_IP##/${MASTER_IPS[i]}/" kube-scheduler.service.template > kube-scheduler-${MASTER_IPS[i]}.service done [root@k8s-master01 work]# ls kube-scheduler*.service kube-scheduler-172.31.46.78.service kube-scheduler-172.31.46.83.service kube-scheduler-172.31.46.86.service 分发 systemd unit 文件到所有 master 节点: [root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" scp kube-scheduler-${node_ip}.service root@${node_ip}:/etc/systemd/system/kube-scheduler.service done
6.启动kube-scheduler 服务
[root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" ssh root@${node_ip} "mkdir -p ${K8S_DIR}/kube-scheduler" ssh root@${node_ip} "systemctl daemon-reload && systemctl enable kube-scheduler && systemctl restart kube-scheduler" done
7.检查服务运行状态
[root@k8s-master01 work]# for node_ip in ${MASTER_IPS[@]} do echo ">>> ${node_ip}" ssh root@${node_ip} "systemctl status kube-scheduler|grep Active" done
8.查看输出的 metrics
**注意:**以下命令在 kube-scheduler 节点上执行。
kube-scheduler 监听 10251 和 10259 端口:
- 10251:接收 http 请求,非安全端口,不需要认证授权;
- 10259:接收 https 请求,安全端口,需要认证授权;
两个接口都对外提供 /metrics 和 /healthz 的访问。
[root@k8s-master01 work]# netstat -lnpt |grep kube-sch tcp 0 0 172.31.46.86:10259 0.0.0.0:* LISTEN 30742/kube-schedule tcp6 0 0 :::10251 :::* LISTEN 30742/kube-schedule [root@k8s-master01 work]# curl -s http://172.31.46.86:10251/metrics |head
9.查看当前的leader
[root@k8s-master01 work]# kubectl get endpoints kube-scheduler --namespace=kube-system -o yaml
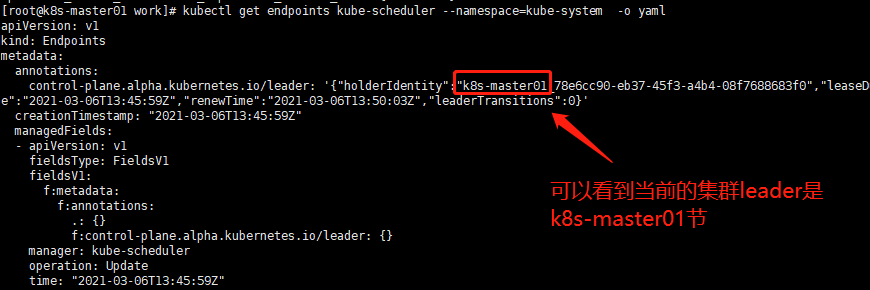

 浙公网安备 33010602011771号
浙公网安备 33010602011771号