第一个爬虫程序,抓取网页源码并保存为html文件
from urllib.request import urlopen
url = 'http://www.baidu.com'
res = urlopen(url)
# print (res.read ().decode('utf-8' ))
with open ('save_baidu.html' ,'w' ,encoding='utf-8' ) as f:
f.write (res.read ().decode('utf-8' ))
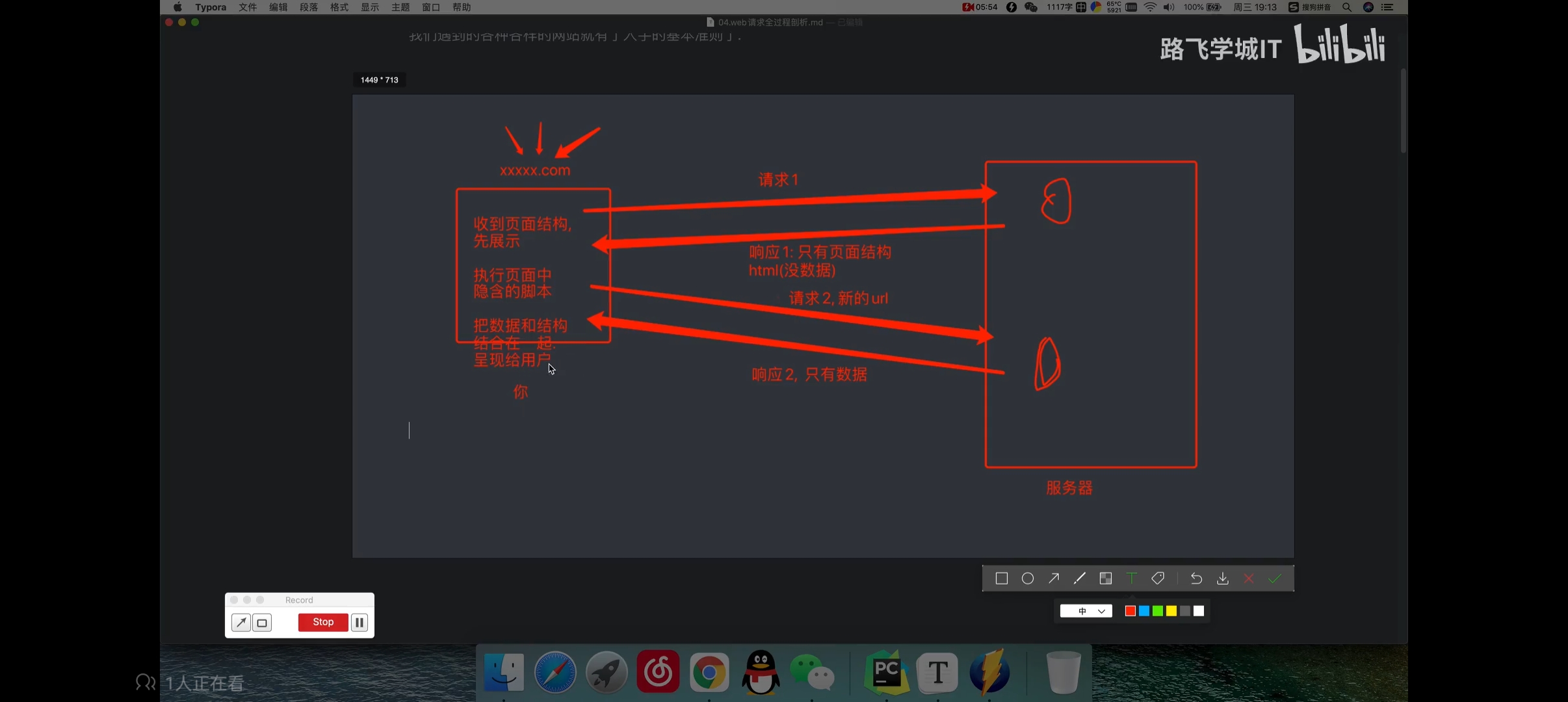
问题点: 百度的logo图片无法显示,抓取hao123也有同样的问题,某些图片无法显示
豆瓣发请求的方式
pip切换成国内镜像,比如清华源- 临时使用
pip install -i https:
- 设为默认
python -m pip install --upgrade pip # 先更新pip
pip config set global .index-url https:
使用requests库实现抓取百度网页源码
import requests
url = 'http://www.baidu.com'
res = requests.get(url)
res.encoding = 'utf-8'
print (res.text)
import requests
url = 'http://www.baidu.com'
res = requests.get(url)
res.encoding = 'utf-8'
with open ('baidu.html' ,'w' ,encoding='utf-8' ) as file:
file.write(res.text)
爬取搜狗搜索
必须设置User-Agent请求头,否则请求会被搜狗服务端拦截
import requests
text = input ('请输入搜索的内容: ' )
url = f'https://www.sogou.com/web?query={text} '
headers = {
'User-Agent' : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
res = requests.get(url,headers=headers)
print (res.text)
import requests
text = input ('请输入搜索的内容: ' )
url = 'https://fanyi.baidu.com/sug'
data = {
'kw' :text
}
headers = {
'User-Agent' : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
res = requests.post(url,data=data,headers=headers)
print (res.json())
查询字符串参数params参数示例,以豆瓣电影为例
import requests
url = 'https://movie.douban.com/j/search_subjects'
params = { # 抓包分析获取的参数
'type' :'movie' ,
'tag' :'热门' ,
'page_limit' :50 ,
'page_start' :0
}
headers = {
'User-Agent' : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
res = requests.get (url,params =params ,headers=headers)
print(res.json())
print(res.request.url) # https://movie.douban.com/j/search_subjects?type=movie&tag=热门&page_limit=50&page_start=0
https://movie.douban.com/top250
xpath常识介绍
以下是一些常见的匹配语法(以```lxml``文本为例)
from lxml import etree
lxml_text = '''
<book >
<id > 1</id >
<name > 野花遍地香</name >
<price > 1.23</price >
<nick > 臭豆腐</nick >
<author >
<nick id ="10086" > 周达强</nick >
<nick id ="10010" > 周芷若</nick >
<nick class ="jay" > 周杰伦</nick >
<nick class ="jolin" > 蔡依林</nick >
<div >
<nick > 不知道</nick >
</div >
</author >
<partner >
<nick id ="ppc" > 陈大胖</nick >
<nick id ="ppbc" > 陈小胖</nick >
</partner >
</book >
'''
et_obj = etree.XML(lxml_text)
# res = et_obj.xpath('/book')
# res = et_obj.xpath('/book/name')
# res = et_obj.xpath('/book/name/text()')[0] # 野花遍地香
# print(res)
# res = et_obj.xpath('/book//nick') # 8个元素
# res = et_obj.xpath('/book/*/nick/text()') # 6个孙元素
# res = et_obj.xpath('/book/author/nick[@class="jay"]/text()') # 匹配类名
res = et_obj.xpath('/book/partner/nick/@id') # 两个id值 list
print(res)
from lxml import etree
html_text = '''
<!DOCTYPE html >
<html lang ="en" >
<head >
<meta charset ="utf-8" >
<meta http-equiv ="X-UA-Compatible" content ="IE=edge" >
<meta name ="viewport" content ="width=device-width,initial-scale=1.0" >
<title > Demo</title >
</head >
<body >
<ul >
<li > <a href ="http://www.baidu.com" > 百度</a > </li >
<li > <a href ="http://www.google.com" > 谷歌</a > </li >
<li > <a href ="http://www.sougou.com" > 搜狗</a > </li >
</ul >
<ol >
<li > <a href ="feiji" > 飞机</a > </li >
<li > <a href ="dapao" > 大炮</a > </li >
<li > <a href ="huoche" > 火车</a > </li >
</ol >
<div class ="job" > 黄飞鸿</div >
<div class ="common" > 胡辣汤</div >
</body >
</html >
'''
et_obj = etree.HTML(html_text)
li_list = et_obj.xpath('/html/body/ul//li')
for li in li_list:
url = li.xpath('./a/@href') # '.'表示当前路径,一定不能省略
text = li.xpath('./a/text()')
print(url,text)
利用cookie登录17k小说网
可以把session理解为一连串的请求,该会话可以维持cookie的运行
import requests
session = requests.session()
data = {
'loginName' :'anning' ,
'password' :'xxxxxx'
}
url = 'https://passport.17k.com/ck/user/login'
res = session.post(url,data=data)
print (res.text)
print (res.cookies)
import requests
session = requests.session()
data = {
'loginName' :'anning' ,
'password' :'xxxxxx'
}
url = 'https://passport.17k.com/ck/user/login'
session.post(url,data =data )
res = session.get ('https://user.17k.com/ck/author/shelf?page=1&appkey=xxxxx' )
print(res.json())
import requests
url = 'https://user.17k.com/ck/author/shelf?page=1&appkey=xxxxx'
headers = {
'Cookie' "浏览器拷贝过来的cookie"
}
res = requests.get (url,headers=headers)
print (res.text)
import requests
headers = {
'Cookie' : "remote_flag=0; sysUpdate=1; web_custom=no; hwType=1233; lyncFlag=off; ST=0; Language=chinese; protocalType=http; language=0; model=MX; passwd=QWRtaW4uYzBt; custome_made=NewRockTech"
}
url = 'http://192.168.151.152/frame.htm'
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
print (res.text)
防盗链处理,抓取梨视频- 网页地址: https://www.pearvideo.com/video_1782860
- xhr地址: https://www.pearvideo.com/videoStatus.jsp?contId=1782860&mrd=0.3301612883151268
- 真实视频地址: https://video.pearvideo.com/mp4/short/20230524/cont-1782860-71091692-hd.mp4
- 请求视频地址: https://video.pearvideo.com/mp4/short/20230524/1684897123340-71091692-hd.mp4
- 结论: 把 1684897123340(systemTime) 替换成 cont-1782860(网页地址取)
import requests
url = 'https://www.pearvideo.com/video_1782860'
constId = url.split('_' )[1 ]
videoUrl = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd=0.3301612883151268' .format (constId)
res = requests.get(videoUrl)
print (res.text)
- 结果: 抓不到,视频实际是在线可以访问的,由此可以判断,遇到了反爬
{
"resultCode" :"5" ,
"resultMsg" :"该文章已经下线!" ,
"systemTime" : "1684897584882"
}
- 添加请求头尝试破解反爬,还是不行
......
headers = {
'User-Agent' : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
......
res = requests.get(videoUrl,headers=headers)
print (res.text)
{
"resultCode" :"5" ,
"resultMsg" :"该文章已经下线!" ,
"systemTime" : "1684898224498"
}
服务器的反爬策略,就是Referer参数,也称为溯源
- 正常用户访问视频的时候,都是先访问 https://www.pearvideo.com/video_1782860,然后点击视频播放
- 服务器一旦发现请求源没有 Referer参数,溯源失败,故拒绝请求
import requests
url = 'https://www.pearvideo.com/video_1782860'
constId = url.split('_' )[1 ]
headers = {
'User-Agent' : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36" ,
'Referer' :url
}
videoUrl = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd=0.3301612883151268' .format (constId)
res = requests.get(videoUrl,headers=headers)
print (res.text)
- 返回结果:
{
"resultCode" :"1" ,
"resultMsg" :"success" , "reqId" :"6deb8ee1-3ac1-4cc8-b767-6d373b6d7602" ,
"systemTime" : "1684898328565" ,
"videoInfo" :{"playSta" :"1" ,"video_image" :"https://image1.pearvideo.com/cont/20230524/cont-1782860-71057241.jpg" ,"videos" :{"hdUrl" :"" ,"hdflvUrl" :"" ,"sdUrl" :"" ,"sdflvUrl" :"" ,"srcUrl" :"https://video.pearvideo.com/mp4/short/20230524/1684898328565-71091692-hd.mp4" }}
}
下来的事情就简单了,拼接真实视频url,下载到本地
import requests
url = 'https://www.pearvideo.com/video_1782860'
constId = url.split('_' )[1 ]
headers = {
'User-Agent' : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36" ,
'Referer' :url
}
videoUrl = 'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd=0.3301612883151268' .format (constId)
res = requests.get(videoUrl,headers=headers)
obj = res.json()
srcUrl = obj['videoInfo' ]['videos' ]['srcUrl' ]
systemTime = obj['systemTime' ]
srcUrl = srcUrl.replace(systemTime,f'cont-{constId} ' )
with open ('pear.mp4' ,mode='wb' ) as f:
f.write(requests.get(srcUrl).content)
多进程,多线程案例,爬取591MM图片网站
- 进程是一个独立的内存模块,不受其他进程的影响
- 这点很重要,比如其他程序可以随便访问微信的进程么?如 果可以,安全隐患很大
- 通俗理解,就是'公司'
- 线程是实际干活的人,通俗理解就是'员工'
- 所以'进程' 和'线程' 其实就是'公司' 与'员工' 的关系
- 多进程和多线程,那就是 多家公司和多个员工
def func(name):
for i in range (3 ):
print (name,i)
if __name__ == '__main__' :
func ('Jim' )
func ('Kate' )
func ('LiLei' )
func ('Hanmeimei' )
- 输出结果: 一个一个依次执行,意味着后面的人必须得等前面的人把事情搞完才能做事情
如果前面的人一直在那边故障,那么 后面的人就是一直等...效率低是肯定的...
Jim 0
Jim 1
Jim 2
Kate 0
Kate 1
Kate 2
LiLei 0
LiLei 1
LiLei 2
Hanmeimei 0
Hanmeimei 1
Hanmeimei 2
from threading import Thread
def func (name ):
for i in range (10 ):
print (name,i)
if __name__ == '__main__' :
task1 = Thread(target=func,args=('JimGreen' ,))
task2 = Thread(target=func,args=('KateGreen' ,))
task3 = Thread(target=func,args=('King' ,))
task1.start()
task2.start()
task3.start()
- 结果:
......
JimGreen KateGreen6
0JimGreen
KateGreen 71
JimGreenKateGreen 82
JimGreenKateGreen 93
from concurrent.futures import ThreadPoolExecutor
def func (name ):
for i in range (10 ):
print (name,i)
if __name__ == '__main__' :
with ThreadPoolExecutor(10 ) as thread_pool:
for i in range (100 ):
thread_pool.submit(func,f'JimGreen{i} ' )
import time
from concurrent.futures import ThreadPoolExecutor
def func (name,run_time ):
time.sleep(run_time)
print ('我是 ' , name)
return name
def fn (res ):
print (res.result())
if __name__ == '__main__' :
with ThreadPoolExecutor(10 ) as thread_pool:
thread_pool.submit(func, 'JimGreen' , 2 )
thread_pool.submit(func, 'KateGreen' , 1 )
thread_pool.submit(func, 'King' , 3 )
- 结果:
我是 KateGreen
我是 JimGreen
我是 King
import time
from concurrent.futures import ThreadPoolExecutor
def func (name,run_time ):
time.sleep(run_time)
print ('我是 ' , name)
return name
def fn (res ):
print (res.result())
if __name__ == '__main__' :
with ThreadPoolExecutor(10 ) as thread_pool:
thread_pool.submit(func,'JimGreen' ,2 ).add_done_callback(fn)
thread_pool.submit(func,'KateGreen' ,1 ).add_done_callback(fn)
thread_pool.submit(func,'King' ,3 ).add_done_callback(fn)
- 结果:
我是 KateGreen
KateGreen
我是 JimGreen
JimGreen
我是 King
King
- 缺点: callback执行的顺序是不确定的,返回值的顺序是不确定的(上述demo加了时间差,所以顺序执行)
import time
from concurrent.futures import ThreadPoolExecutor
def func (name,run_time ):
time.sleep(run_time)
print ('我是 ' , name)
return name
def fn (res ):
print (res.result())
if __name__ == '__main__' :
with ThreadPoolExecutor(10 ) as thread_pool:
res = thread_pool.map (func,['JimGreen' ,'KateGreen' ,'King' ],[2 ,1 ,3 ])
for r in res:
print (r)
- 结果: 上面list 的顺序,就是返回值的顺序, 'JimGreen' ,'KateGreen' ,'King'
我是 KateGreen
我是 JimGreen
JimGreen
KateGreen
我是 King
King
多进程和线程池和队列的使用,爬取591MM网- 终极目标: 下载当前页所有的图片
- 拆分两个'进程' 来处理
- 进程1: 获取图片的下载链接,往'队列' 丢
- 进程2: 下载图片
- 创建'线程池' ,定义一个'下载函数' ,往'线程池' 提交'下载函数'
- '下载链接' 由该进程从'队列' 里面取,取完传给'下载函数'
from concurrent.futures.thread import ThreadPoolExecutor
from multiprocessing import Process, Queue
from concurrent.futures import ThreadPoolExecutor
from urllib import parse
import requests
def get_img_src (queen ):
src = 'xxx'
queen.put(src)
print ('往队列丢东西完毕' )
queen.put('完事了' )
def download (url ):
print ('开始下载' )
name = url.split('/' )[-1 ]
with open ('./img/' + name,mode='wb' ) as f:
res = requests.get(url)
f.write(res.content)
print ('下载完毕' )
def download_img (queen ):
with ThreadPoolExecutor(10 ) as t:
while 1 :
src = queen.get()
if src == '完事了' :
break
t.submit(download,src)
if __name__ == '__main__' :
q = Queue()
p1 = Process(target=get_img_src,args=(q,))
p2 = Process(target=download_img,args=(q,))
p1.start()
p2.start()
url = 'http://www.baidu.com/mntt/6.html'
href = '88.html'
res = parse.urljoin(url,href)
print (res)
异步协程
- 线程内部创建一个 event_loop 去 '轮询'
- 在一个循环中,event_loop一个个任务'轮询' 过去,如果发现任务'阻塞' ,就把该任务从线程中先踢掉,把别的任务丢进去
- 以此类推,保证线程在高效运行,CPU不得不一直理你...从而实现程序高效运行
async def func () '异步函数' ,返回值是一个coroutine对象(即'协程对象' ),类似'生成器'
print ('Jim Green' )
if __name__ == '__main__' :
func () 'func' was never awaited
func () def gen ():
yield 1
if __name__ == '__main__' :
g = gen()
print (g)
async def func () print ('Jim Green' )
if __name__ == '__main__' :
res = func () print (res) # <coroutine object func at 0x00000214C7CE8940 >import asyncio
async def func ():
print ('Jim Green' )
if __name__ == '__main__' :
f = func()
event_loop = asyncio.get_event_loop()
event_loop.run_until_complete(f)
- 结果: Jim Green
import asyncio
async def func ():
print ('Jim Green' )
if __name__ == '__main__' :
f = func()
asyncio.run(f)
- 结果: Jim Green
def fun1():
print ('我是fun1' )
print ('fun1运行结束' )
def fun2 ():
print ('我是fun2' )
print ('fun2运行结束' )
def fun3 ():
print ('我是fun3' )
print ('fun3运行结束' )
if __name__ == '__main__' :
fun1 ()
fun2 ()
fun3 ()
- 结果:
我是fun1
fun1运行结束
我是fun2
fun2运行结束
我是fun3
fun3运行结束
import asyncio
async def fun1 ():
print ('我是fun1' )
print ('fun1运行结束' )
async def fun2 ():
print ('我是fun2' )
print ('fun2运行结束' )
async def fun3 ():
print ('我是fun3' )
print ('fun3运行结束' )
if __name__ == '__main__' :
f1 = fun1()
f2 = fun2()
f3 = fun3()
tasks = [f1,f2,f3]
asyncio.run(asyncio.wait(tasks))
- 结果:
我是fun3
fun3运行结束
我是fun1
fun1运行结束
我是fun2
fun2运行结束
模拟堵塞时间(这里不能使用time.sleep,无法看出异步效果,程序还是会等),如下
import asyncio
async def fun1 ():
print ('我是fun1' )
await asyncio.sleep(1 )
print ('fun1运行结束' )
async def fun2 ():
print ('我是fun2' )
await asyncio.sleep(2 )
print ('fun2运行结束' )
async def fun3 ():
print ('我是fun3' )
await asyncio.sleep(3 )
print ('fun3运行结束' )
if __name__ == '__main__' :
f1 = fun1()
f2 = fun2()
f3 = fun3()
tasks = [f1,f2,f3]
asyncio.run(asyncio.wait(tasks))
- 结果:先运行fun3,发现阻塞了,然后把fun1塞到线程执行,依次类推...
然后发现,fun1不阻塞了,就先执行fun1,再依次类推...
我是fun3
我是fun1
我是fun2
fun1运行结束
fun2运行结束
fun3运行结束
import asyncio
import time
async def fun1():
print ('我是fun1' )
await asyncio.sleep (1 )
print ('fun1运行结束' )
async def fun2 ():
print ('我是fun2' )
await asyncio.sleep (2 )
print ('fun2运行结束' )
async def fun3 (): # 最耗时的任务,程序运行的时间以它为准
print ('我是fun3' )
await asyncio.sleep (3 )
print ('fun3运行结束' )
if __name__ == '__main__' :
start = time.time ()
f1 = fun1 ()
f2 = fun2 ()
f3 = fun3 ()
tasks = [f1,f2,f3]
asyncio.run (asyncio.wait (tasks))
print (time.time () - start) # 3.01s
import asyncio
import time
async def download (url,t ):
print ('我要下载了' )
await asyncio.sleep(t)
print ('我下载完了' )
async def main ():
pass
if __name__ == '__main__' :
asyncio.run(main())
import asyncio
import time
async def download (url,t ):
print ('我要下载了: {}' .format (url))
await asyncio.sleep(t)
print ('我下载完了: {}' .format (url))
async def main ():
urls = [
'http://www.baidu.com' ,
'http://www.sina.com' ,
'http://www.sougou.com' ,
]
tasks = []
for url in urls:
tasks.append(download(url,3 ))
await asyncio.wait(tasks)
if __name__ == '__main__' :
asyncio.run(main())
- 结果:
我要下载了: http://www.sina.com
我要下载了: http://www.sougou.com
我要下载了: http://www.baidu.com
我下载完了: http://www.sina.com
我下载完了: http://www.sougou.com
我下载完了: http://www.baidu.com
异步协程爬虫的套路模板- 扫url,拿到一堆url
- 循环url,创建任务
- 把任务丢给协程函数处理,统一await
import asyncio
async def fun1 ():
print ('我是fun1' )
await asyncio.sleep(1 )
print ('fun1运行结束' )
return '我是fun1的返回值'
async def fun2 ():
print ('我是fun2' )
await asyncio.sleep(2 )
print ('fun2运行结束' )
return '我是fun2的返回值'
async def fun3 ():
print ('我是fun3' )
await asyncio.sleep(3 )
print ('fun3运行结束' )
return '我是fun3的返回值'
async def main ():
f1 = fun1()
f2 = fun2()
f3 = fun3()
tasks = [
asyncio.create_task(f1),
asyncio.create_task(f2),
asyncio.create_task(f3),
]
await asyncio.wait(tasks)
if __name__ == '__main__' :
asyncio.run(main())
- 运行结果:
我是fun1
我是fun2
我是fun3
fun1运行结束
fun2运行结束
fun3运行结束
研究await asyncio.wait(tasks)的返回值
import asyncio
async def fun1():
......
async def fun2():
......
async def fun3():
......
async def main():
......
done , pending = await asyncio.wait(tasks)
print (done )
print (pending)
if __name__ == '__main__' :
......
- 结果:
{<Task finished name='Task-2' coro=<fun1() done , defined at D:/Python/crawler/Demos/SaveWebPage/demo.py:48> result='我是fun1的返回值' >, <Task finished name='Task-3' coro=<fun2() done , defined at D:/Python/crawler/Demos/SaveWebPage/demo.py:54> result='我是fun2的返回值' >, <Task finished name='Task-4' coro=<fun3() done , defined at D:/Python/crawler/Demos/SaveWebPage/demo.py:60> result='我是fun3的返回值' >}
set ()
- 所以可以遍历'done' ,获取任务的返回值
......
async def main():
......
done , pending = await asyncio.wait(tasks)
for task in done :
print (task.result())+
- 结果:
我是fun1的返回值
我是fun2的返回值
我是fun3的返回值
注意事项:asyncio.wait(tasks)的返回结果是无序的,若想依据tasks的顺序,而返回结果,可以使用gather()
async def main ():
......
tasks = [
asyncio.create_task (f3),
asyncio.create_task (f2),
asyncio.create_task (f1),
]
res = await asyncio.gather (*tasks)
print (res)
# 以下作对比
# done, pending = await asyncio.wait (tasks)
# print (done) # set对象(无序,不重复),存储一个个任务对象
# print (pending) # 标识,指示程序的运行状态
# for task in done:
# print (task.result ())
- 结果:
......
我是fun3的返回值
我是fun2的返回值
我是fun1的返回值
return_exceptions=False参数:
- 值为 False 时,若任务中有'异常' ,所有的任务都停止执行(默认行为)
- 值为 True 时,若任务中有'异常' ,返回该任务的异常信息,其他任务正常执行(爬虫中太重要了...)
import asyncio
async def fun1 ():
......
async def fun2 ():
......
async def fun3 ():
print ('我是fun3' )
print (1 /0 )
await asyncio.sleep(3 )
......
async def main ():
......
res = await asyncio.gather(*tasks,return_exceptions=True )
print (res)
......
if __name__ == '__main__' :
......
- 结果:
我是fun3
我是fun2
我是fun1
fun1运行结束
fun2运行结束
[ZeroDivisionError('division by zero' ), '我是fun2的返回值' , '我是fun1的返回值' ]
- 修改 return_exceptions=False ,则一旦有任务异常,所有任务都停止
Traceback (most recent call last):
......
print (1 /0 )
ZeroDivisionError: division by zero
我是fun3
我是fun2
我是fun1
import asyncio
async def download (url ):
pass
async def main ():
url_list = [
'https://www.aclas.com/uploadfile/product/21231670506968.png' ,
'https://www.aclas.com/uploadfile/product/41156486784605.png' ,
'https://www.aclas.com/uploadfile/product/24734781209975.png' ,
'https://www.aclas.com/uploadfile/product/4245587878342.png'
]
tasks = []
for url in url_list:
task = asyncio.create_task(download(url))
tasks.append(tasks)
await asyncio.wait(tasks)
if __name__ == '__main__' :
asyncio.run(main())
'''
- 扫出一堆url
- 创建任务
- wait统一处理
'''
import asyncio
import aiohttp
import aiofiles
async def download (url ):
file_name = url.split('/' )[-1 ]
async with aiohttp.ClientSession() as request:
async with request.get(url) as res:
content = await res.content.read()
async with aiofiles.open (file_name,mode='wb' ) as f:
await f.write(content)
async def main ():
url_list = [
'https://www.aaaa.png' ,
'https://www.bbb.png' ,
'https://www.ccc.png' ,
'https://www.ddd.png'
]
tasks = []
for url in url_list:
task = asyncio.create_task(download(url))
tasks.append(task)
await asyncio.wait(tasks)
if __name__ == '__main__' :
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
- https://blog.csdn.net/weixin_45787528/article/details/115450809
扒光一部小说需要多长时间
import requests
import asyncio
import aiohttp
import aiofiles
from lxml import etree
def get_every_chapter_url (url ):
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' ,
}
res = requests.get(url, headers=headers, verify=False )
tree = etree.HTML(res.text)
href_list = tree.xpath('xxx' )
return href_list
async def download_one (url ):
while True :
try :
async with aiohttp.ClientSession() as session:
async with session.get(url) as res:
page_source = await res.text()
tree = etree.HTML(page_source)
title = tree.xpath('xxx' )
content = "\n" .join(tree.xpath('yyy/text()' )).replace("\u3000" , '' )
async with aiofiles.open (f'./xxx/{title} .txt' ,mode='w' ,encoding='utf-8' ) as f:
await f.write(content)
break
except :
print ('报错了,重试一下' ,url)
print ('下载完毕' ,url)
async def download (href_list ):
tasks = []
for href in href_list:
t = asyncio.create_task(download_one(href))
tasks.append(t)
await asyncio.wait(tasks)
def main ():
url = 'https://www.zanghaihua.org/mingchaonaxieshier/'
href_list = get_every_chapter_url(url)
asyncio.run(download(href_list))
if __name__ == '__main__' :
main()
网易云音乐下载
找到某首歌曲,点击播放 ,看看发送了那些ajax 请求
- url: https://music.163.com/
- ajax解析:
- 请求网址: https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token=
- data数据解析:
- 音乐下载地址url: "http://m701.music.126.net/20230627115337/df87135b4a1dca059c3a9fb5826896dd/jdyyaac/obj/w5rDlsOJwrLDjj7CmsOj/28895064476/4524/15b8/27b5/e0e337ca04d33820651b87ba8368d532.m4a"
- 检验: 直接复制到浏览器,播放正常,说明该地址正确
- 访问url
- 获取音频的下载地址
- 下载音频(逻辑和下载图片是一样的)
- 这是一个post请求
-需携带表单数据
- params: xxxxxxxxxxxxxxxxxx
- encSecKey:yyyyyyyyyyyyyyyyy
所以,我们要发请求的时候,必须携带上述两个表单参数,关键点在于,这两个参数值是如何生成的?




【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版
· 2分钟学会 DeepSeek API,竟然比官方更好用!
· .NET 使用 DeepSeek R1 开发智能 AI 客户端
· DeepSeek本地性能调优
· 一文掌握DeepSeek本地部署+Page Assist浏览器插件+C#接口调用+局域网访问!全攻略