MySQL重温
三个概念
-
DB: 数据库
-
DBMS: 数据库管理系统(例如MySQL,SQL Server)
-
SQL: 语法
分类有两种
-
关系型数据库
-
非关系型数据库(NoSQL)
ORM(Object Relational Mapping) 思想
- 数据库中的一个表 <---> Java或Python中的一个类
- 表中的一条数据 <---> 类中的一个对象(或实例)
- 表中的一个列 <----> 类中的一个字段、属性(field)
表和表之间的关系
- 一对一
- 应用: 在实际的开发中应用不多,因为一对一可以创建成一张表
- 举例:设计学生表,学号、姓名、手机号码、班级、系别、身份证号码、家庭住址、籍贯、紧急联系人...
- 为什么要这么设计: 即一张表能搞定事情,设计成两张表?
- 查询一次的时候,需要查询整行的记录,而往往只需要查询几个字段而已,所以性能的开销大(但是查询操作简单)
- 拆为两个表:两个表的记录是一一对应关系。
- 基础信息表(常用信息):学号、姓名、手机号码、班级、系别
- 档案信息表(不常用信息):学号、身份证号码、家庭住址、籍贯、紧急联系人、...
- 一对多(多对一)
- 举例: 员工表 和 部门表
- 多对多
- 举例: 学生表 和 课程表
- 必须创建第三张表(联接表)
- 它将"多对多"关系划分为"两个 一对多关系"
- 把两个表的主键都插入到'联接表'
- 自我引用
- 举例: 员工表里面,有 员工编号 和 主管编号(引用'员工编号')
MySQL 安装问题
- 故障代码
ERROR 2059 (HY000): Authentication plugin 'caching_sha2_password' cannot be loaded:
- 解决办法一: 不使用cmd命令行,而是使用mysql自带的命令行,就不会报错了
- 解决办法二: 把MySQL8用户登录密码加密规则还原成mysql_native_password
#使用mysql数据库
USE mysql;
#修改'root'@'localhost'用户的密码规则和密码
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'abc123';
#刷新权限
FLUSH PRIVILEGES;
进入MySQL命令(参数之间的位置可以自由调整,不是固定死的)
mysql -h 主机名 -P 端口号 -u 用户名 -p密码
-- 例如
mysql -h localhost -P 3306 -u root -pabc123 # 这里我设置的root用户的密码是abc123
常用的查询命令
-- show create table table_name; # 查看'表'是如何创建
-- show create database database_name; # 查看'数据库'是如何创建
-- show variables like 'character_%'; # 查看编码集
导入数据库命令
- 方式一,命令行进入mysql,敲以下命令
mysql> source d:\mysqldb.sql
- 方式二,使用图形化工具,执行sql脚本
select语句之'dual(伪表)'
- dual 的意义在于'测试'
# 把'from dual'删去,效果是一样的
SELECT 1+1,2+2 FROM DUAL
字段取别名,可以有三种方式
-
规范使用 双引号 把别名包裹起来(使用单引号是不规范的)
-
而在处理日期字段的时候,规范使用 单引号 (使用双引号是不规范的)
SELECT last_name 姓名 FROM employees; # field define_name
SELECT last_name '姓名' FROM employees; # field 'define_name'
SELECT last_name AS '姓名' FROM employees; # field as ...
DISTINCT: 去重
- 最好只搭配一个字段,多个字段的结果一般没有意义
# 正确用法:查询所有的部门ID
SELECT DISTINCT department_id FROM employees;
# 错误用法: 搭配两个字段,没有意义(这里salary若有重复的,会被删除,也只保留一个salary)
select distinct department_id,salary from employees;
null参与运算
-
若null参与运算,返回的结果还是'null'
-
一般搭配 ifnull()函数使用
# 计算年薪示例 若 commission_pct为null,则替换为'0'
SELECT last_name 姓名,salary 月薪,salary*(1+IFNULL(commission_pct,0))*12 年薪 FROM employees;
着重号``
- 用来包裹'sql关键字',避免歧义
# order 本身就是mysql的关键字,不加着重号包裹起来,就会报错!
SELECT * FROM `order`;
命令,描述表的结构信息
desc table_name
SQL 运算注意事项
- '+'号只有一个作用,就是运算
SELECT 100 + '1' FROM DUAL # 结果为 101,sql会作'隐式转换'
SELECT 100 + 'a' FROM DUAL # 结果为 100,'a'被转换为 0
SELECT 100 + NULL FROM DUAL # 结果为 null,null 参与运算,一定为 null
比较运算符
-
只返回三种结果
-
0,条件不成立
-
1,条件成立
-
null,有null参与
-
SELECT 0='a'; # 结果为 1,'a'被隐式转换成0
SELECT 0=NULL; # 结果为 null,有null参与,立即返回null
# 结果: 一行数据都没有,只有三个字段名
SELECT last_name,salary,commission_pct FROM employees WHERE commission_pct=NULL;
'''
- 解析: where条件"commission_pct=NULL" 就相当于'比较运算符',若比较的结果为1,那么就把该条记录展示出来,其他结果不予展示
- 显然,每个字段和 null 进行比较,根本不会返回1,所以,一行数据都不会显示
'''
- 安全等于"<=>": 为 null 而生
- 按照以前的惯例,只要null参与运算,那么结果一定为null
- 使用 "<=>" 以后,null参与运算,就不一定返回 null,也可以返回'1',例如 null<=>null 结果为 1
### 上述示例把'='换成'<=>',就有结果了
SELECT last_name,salary,commission_pct FROM employees WHERE commission_pct<=>NULL;
### 还可以有以下两种写法:
SELECT last_name,salary,commission_pct FROM employees WHERE commission_pct IS NULL; # 推荐
# 和 IFNULL(commission_pct,0) 区别开来
SELECT last_name,salary,commission_pct FROM employees WHERE ISNULL(commission_pct);
least/greatest: 最小值和最大值
SELECT LEAST('a','b','c') AS 最小值,GREATEST('a','b','c') AS 最大值
最小值 最大值
a c
### max和min有类似的用法
SELECT max(salary) AS 最大值,min(salary) AS 最小值 from employees;
between...and...:查找一定范围内的条件
- 包含左右边界(边界的顺序不可随便调换,会报错)
# 查询工资在6000~8000的员工信息
SELECT last_name,salary FROM employees WHERE salary BETWEEN 6000 AND 8000
in/not in...: 查找满足某个点的条件
# 查找 员工编号为 10/20/30的员工信息
SELECT last_name,department_id FROM employees WHERE department_id IN (10,20,30)
like: 模糊匹配
-
'%': 任意多个字符(0个,1个,多个)
-
'_': 任意单个字符
-
'': 转义(也可以使用escape关键字来指明'转义字符',比如换成'$')
# 名字包含'a'的员工信息
SELECT last_name FROM employees WHERE last_name LIKE '%a%';
# 第二个字符是'a'的员工信息
SELECT last_name FROM employees WHERE last_name LIKE '_a%';
# 第二个字符是'_'的员工信息(注意是反斜杠'\')
SELECT last_name FROM employees WHERE last_name LIKE '_\_%';
# 替换默认的转义字符'\'为'$'(一般不这么搞)
SELECT last_name FROM employees WHERE last_name LIKE '_$_%' ESCAPE '$';
regexp \ rlike: 正则表达式(先简单了解一下)
# 1 1 0
SELECT 'shkdfs' REGEXP '^s','sdfsjdsft' REGEXP 't$','shksdfsdf' REGEXP 'hx' FROM DUAL;
"XOR":表示'异或'
- 比如有两个条件,那么满足条件1以后,就不能满足条件2(一个为真以后,另外一个必定为假)
# 如果 department_id=50,那么该条记录的 salary 一定小于/等于 6000
# 如果 salary>6000,那么该条记录的 department_id 一定不等于50
SELECT last_name,department_id,salary FROM employees WHERE department_id=50 XOR salary>6000
练习示例
### 查询名字中包含'a'和'k'的员工信息
# 或者这么写也可以: WHERE last_name LIKE '%a%' AND last_name LIKE '%k%'
SELECT last_name FROM employees WHERE last_name LIKE '%a%k%' OR last_name LIKE '%k%a%'
### 查询名字中以'e'结尾的员工信息
SELECT last_name FROM employees WHERE last_name LIKE '%e'
SELECT last_name FROM employees WHERE last_name REGEXP 'e$'
排序: order by xxx desc/asc
-
desc: descend
-
asc: ascend(默认行为)
SELECT department_id,last_name,salary FROM employees ORDER BY salary DESC;
- 取'别名'注意事项,只能在order by 使用,where 中不能用,会报错
# 正确示例
SELECT department_id,last_name,salary AS 工资 FROM employees ORDER BY 工资 DESC;
# 错误示例: Unknown column '工资' in 'where clause'
SELECT department_id,last_name,salary AS 工资 FROM employees WHERE 工资>6000 ORDER BY 工资 DESC;
'''
- 出错的原因: 和 sql 执行的顺序有关系,先执行where语句,然而此时的where语句,根本不知道'工资'是谁,所以报错了
'''
- 二级排序示例
# 先按照工资降序排,如果工资一样,则按照部门ID升序排
SELECT department_id,last_name,salary AS 工资 FROM employees ORDER BY 工资 DESC,department_id;
分页: 分批获取数据
# 获取前20条记录
SELECT * FROM employees LIMIT 0,20
# 每页显示20条记录,此时显示第二页的数据
SELECT * FROM employees LIMIT 20,20
# 每页显示20条记录,此时显示第三页的数据
SELECT * FROM employees LIMIT 40,20
- 小结公式: 从第几页开始,显示多少条数据
# 从第pageNo页开始,显示pageSize条数据
LIMIT (pageNo-1) * pageSize,pageSize
- 注意where...order by...limit 的声明顺序
# 查询工资最高的那一条记录
# select last_name,max(salary) from employees;
SELECT last_name,salary FROM employees ORDER BY salary DESC LIMIT 1;
- offset:从第几个位置开始,往后面查询
# 显示第32,33条数据
SELECT * FROM employees LIMIT 31,2
SELECT * FROM employees LIMIT 2 OFFSET 31
多表连接查询之迪尔卡乘积
- 出错原因: 缺少连接条件
## 以下两种写法都可以
- SELECT department_name,employee_id FROM departments,employees;
- SELECT department_name,employee_id FROM departments CROSS JOIN employees;
-
纠正: 使用正确的连接条件即可
-
注意事项: 如果有 n 个表连接查询,至少需要 n-1 个条件
### 这里给'表'取了'别名'以后,都要使用'别名';若继续使用'原名'会报错
SELECT d.department_name,e.employee_id FROM departments AS d,employees AS e
WHERE d.`department_id`=e.`department_id`;
### 练习: 多表查询以下字段: last_name,employee_id,department_name,city
SELECT e.last_name,e.employee_id,d.department_name,l.city FROM employees AS e,departments AS d,locations AS l
WHERE e.`department_id`=d.`department_id` AND d.`location_id`=l.`location_id`
自关联查询
- 查询 员工的last_name,employee_id以及其管理者的 last_name,employee_id
SELECT em.last_name,em.employee_id,mm.employee_id,mm.last_name FROM employees em,employees mm
WHERE em.employee_id=mm.manager_id
内连接 和 外连接
-
内连接:两个表的交集部分
-
外连接:两个表的交集部分+左表/右表 部分 或者干脆两个表的全部
### 典型的内连接示例(sql92语法): 查询所有员工的 last_name 和 department_name
SELECT last_name,department_name FROM employees e,departments d
WHERE e.`department_id`=d.`department_id`
### 典型的内连接示例(sql99语法): 使用 inner join...on 连接条件(inner可以省略)
### 比如这里若设计三表查询,就在 inner join ...on....即可
SELECT last_name,department_name FROM employees e INNER JOIN departments d
ON e.`department_id`=d.`department_id`
### 外连接: left/right [outer] join
# left outer join: 这里 outer 可以省略
# 查询结果: 比起'内连接',多出了一行,null 那一行
SELECT last_name,department_name FROM employees e LEFT JOIN departments d
ON e.`department_id`=d.`department_id`
## 右外连接:结果是122行,employees 表(数据量少)被使用 Null 填充
SELECT last_name,department_name FROM employees e RIGHT JOIN departments d
ON e.`department_id`=d.`department_id`
- 小结: 外连有点类似于'长短脚',如果以'长脚'为主,那么多出来的部分,就会被 null 填充
### 满外连接"FULL JOIN",所有表的并集: mysql 不支持,会报语法错误
SELECT last_name,department_name FROM employees e FULL JOIN departments d
ON e.`department_id`=d.`department_id`
七种sql join 实现图
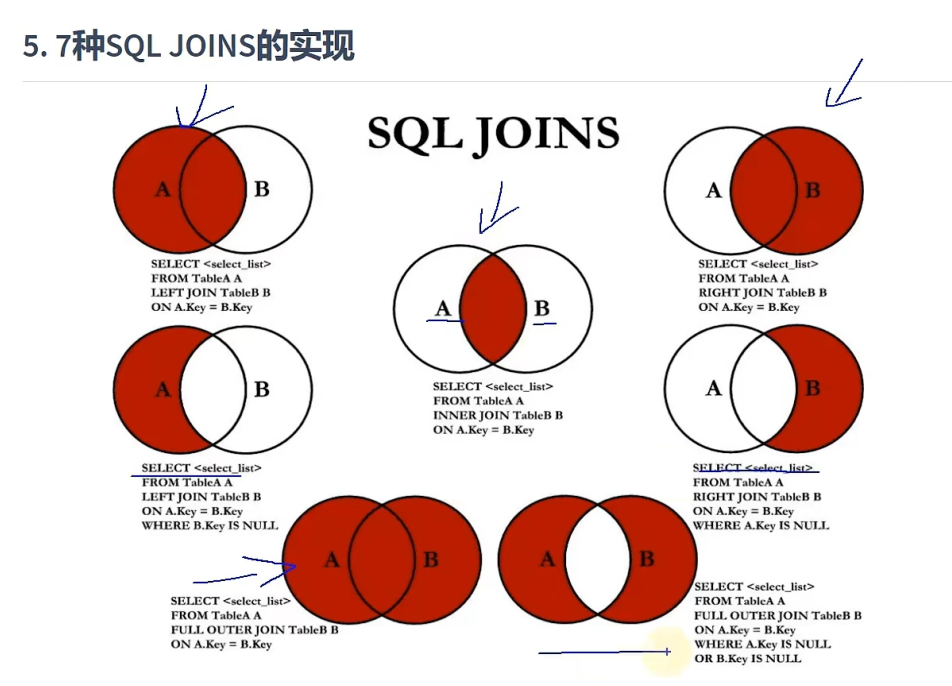
union/union all: 实现满外连接
- union: 删除重复的部分,效率相对低
- A表+重复部分+B表
- union all: 保留重复的部分,效率相对高
- A表+重复部分+重复部分+B表
- 注意事项:
- 两个表的 列数和数据类型 必须相同,并且相互对应
- 语法:
select column,... from tb1
union [all]
select column,... from tb2
- demo演示
# 左外,107条记录
SELECT last_name,employee_id,department_name FROM employees e LEFT JOIN departments d
ON e.`department_id`=d.`department_id`
# 右外,122条记录
SELECT last_name,employee_id,department_name FROM employees e RIGHT JOIN departments d
ON e.`department_id`=d.`department_id`
# 交集部分(内连),106条记录
SELECT last_name,employee_id,department_name FROM employees e JOIN departments d
ON e.`department_id`=d.`department_id`
## 只要左表的部分,其余删除(在"左外"的基础上,减去'交集部分',即减去"内连")
# 107-106=1,这条记录什么呢?原来是 department_id = null 的记录,筛选出来即可
SELECT last_name,employee_id,department_name FROM employees e LEFT JOIN departments d
ON e.`department_id`=d.`department_id`
WHERE e.`department_id` IS NULL
# 只要右表的部分,其余删除:122-106=16
SELECT last_name,employee_id,department_name FROM employees e RIGHT JOIN departments d
ON e.`department_id`=d.`department_id`
WHERE e.`department_id` IS NULL
# 满外连接(所有): 左外+union all+右外: 107+122=229
SELECT last_name,employee_id,department_name FROM employees e LEFT JOIN departments d
ON e.`department_id`=d.`department_id`
UNION ALL
SELECT last_name,employee_id,department_name FROM employees e RIGHT JOIN departments d
ON e.`department_id`=d.`department_id`
# 满外连接(删除重复): 左外+union+右外,重复的部分106条记录,左表只剩1条记录,右表只剩16条记录:1+16+106=123
SELECT last_name,employee_id,department_name FROM employees e LEFT JOIN departments d
ON e.`department_id`=d.`department_id`
UNION
SELECT last_name,employee_id,department_name FROM employees e RIGHT JOIN departments d
ON e.`department_id`=d.`department_id`
# 删除两表交集的部分,其余保留("只要左表部分"+union all +'只要右表部分'):1+16=17条记录
SELECT last_name,employee_id,department_name FROM employees e LEFT JOIN departments d
ON e.`department_id`=d.`department_id`
WHERE e.`department_id` IS NULL
UNION ALL
SELECT last_name,employee_id,department_name FROM employees e RIGHT JOIN departments d
ON e.`department_id`=d.`department_id`
WHERE e.`department_id` IS NULL
自然连接: nature join
-
可以理解为sql92的'等值连接'
-
帮你自动查询两张表中所有相同的字段,然后进行等值连接
-
缺点:查询有局限性,比如以下示例,只仅仅想查询'department_id'相等的,NATURAL 就不适用了
# 32 条记录
SELECT last_name,employee_id,department_name FROM employees e JOIN departments d
ON e.`department_id`=d.`department_id`
AND e.`manager_id`=d.`manager_id`
# 一模一样的效果: NATURAL JOIN
SELECT last_name,employee_id,department_name FROM employees e NATURAL JOIN departments d
using 指定字段实现等值连接
- 作用: 简化SQL代码,上述示例可以修改成如下这个样子
# 代码简约
SELECT last_name,employee_id,department_name FROM employees e JOIN departments d
USING (department_id,manager_id)
聚合函数: 处理一组数据,只返回一个值
- 常见的聚合函数
- max
- min
- avg
- sum
- count
- demo演示
# 操作每组数据,只返回一个结果
SELECT AVG(salary),SUM(salary),MIN(salary),MAX(salary) FROM employees
-
count(): 查询指定字段出现的次数(统计个数,'null'会被忽略)
- 一般用于统计'行数': 该字段出现多少次,就有多少行!
# 返回结果: 107,35(null被忽略)
SELECT COUNT(salary),COUNT(commission_pct) FROM employees
### count(1)/count(*): 统计'行数'
# 分析:当count(1)/count(*)的时候,该行会返回1,所以累积下来,就是'行数'
### 公式 avg = sum/count,以下两个结果是相等的
SELECT AVG(salary),SUM(salary)/COUNT(1) FROM employees
- 典型示例:统计所有人的平均奖金率
# 正常思路
SELECT SUM(commission_pct)/COUNT(*) FROM employees
# 有null值的,替换成0再参与计算,否则不准确,因为那些Null的记录不会参与计算,从而无法满足需求
SELECT AVG(IFNULL(commission_pct,0)),SUM(commission_pct)/COUNT(IFNULL(commission_pct,0)) FROM employees
分组函数: group by
-
作用: 对字段进行分组,每组只返回一个结果
-
典型示例: 求 各部门的平均工资
SELECT department_id,AVG(salary) FROM employees GROUP BY department_id
### 求各个部门和各个工种(job_id)的平均工资
# 先对部门进行分组,然后再对job_id进行分组,从而出结果
SELECT department_id,job_id,AVG(salary) FROM employees GROUP BY department_id,job_id
### 注意事项,这里如果写成以下的样子,虽然出结果了,但是不准确
# 因为,该结果集部门只对应了一个工种,而实际上,部门里面有多个工种
SELECT department_id,job_id,AVG(salary) FROM employees GROUP BY department_id
### - 规律: select中'非聚合函数'的字段,必须出现在group by 后面,反之,group by 后面的字段可以不出现在 select中
-
with rollup: 在所有查询出的分组记录之后增加一条记录
该记录对聚合函数的字段,再次汇总计算所有记录一次- 注意事项: with rollup 和 order by 互斥,不要一起使用
### 计算各部门的平均工资
# with rollup 多出一行记录,统计 所有部门(所有人)的平均工资
SELECT department_id,AVG(salary) FROM employees GROUP BY department_id WITH ROLLUP
# with rollup相当于: SELECT AVG(salary) FROM employees;
having: 分组之后再进行过滤数据
- 引入场景:查询各个部门中最高工资比10000高的部门信息
# 错误演示,报错信息: Invalid use of group function,where 不能接 聚合函数
SELECT department_id,AVG(salary) FROM employees WHERE AVG(salary)>10000 GROUP BY department_id
- 如果要接聚合函数,必须使用 having,它的位置放在 GROUP BY 后面
SELECT department_id,AVG(salary) FROM employees GROUP BY department_id HAVING AVG(salary)>10000
-
注意事项: HAVING 一般都与 GROUP BY 搭配使用,测试中,单独使用 HAVING 是没有意义的
-
练习: 查询部门id为10,20,30,40部门中最高工资比10000高的部门信息
# 写法一: 在刚才示例基础上,加上where过滤条件即可(推荐)
SELECT department_id,MAX(salary) FROM employees WHERE department_id IN (10,20,30,40) GROUP BY department_id HAVING MAX(salary)>10000
# 写法二: 在having里面写所有的过滤条件(一模一样的结果)
SELECT department_id,MAX(salary) FROM employees GROUP BY department_id HAVING MAX(salary)>10000 AND department_id IN (10,20,30,40)
- 小结:
- 当过滤条件中有聚合函数时,此过滤条件必须写在 having 中
- - 当过滤条件中没有聚合函数时,此过滤条件写在 having/where 都可以,建议写在where(执行效率高)
子查询
- 引入示例: 谁的工资比Abel高
# 写法一:先查询 Abel 的工资,然后再进行比较
SELECT salary,last_name FROM employees WHERE last_name = 'Abel' # 返回结果:11000
SELECT salary,last_name FROM employees WHERE salary > 11000 # 返回10行记录
# 写法二:自关联
SELECT e.salary,e.last_name FROM employees e,employees em WHERE e.`salary` > em.`salary` AND em.`last_name` = 'Abel' # 返回10行记录
# 写法三:子查询
SELECT salary,last_name FROM employees WHERE salary > (
SELECT salary FROM employees WHERE last_name = 'Abel' # 这里只能select salary,不能再添加其他字段
);
单行子查询练习示例
# 查询工资大于149号员工工资的员工的信息
SELECT * FROM employees WHERE salary > (
SELECT salary FROM employees WHERE employee_id =149
)
# 返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
SELECT last_name,job_id,salary FROM employees
WHERE job_id = (SELECT job_id FROM employees WHERE employee_id = 141)
AND salary > (SELECT salary FROM employees WHERE employee_id = 143)
# 返回公司工资最少的员工的last_name,job_id和salary
SELECT last_name,job_id,salary FROM employees
WHERE salary = (
SELECT MIN(salary) FROM employees
)
# 查询与141号或174号员工的manager_id和department_id相同的其他员工的employee_id,manager_id,department_id
SELECT employee_id, manager_id, department_id
FROM employees
WHERE manager_id IN
(SELECT manager_id
FROM employees
WHERE employee_id IN (174,141))
AND department_id IN
(SELECT department_id
FROM employees
WHERE employee_id IN (174,141))
AND employee_id NOT IN(174,141);
# 查询最低工资大于50号部门最低工资的部门id和其最低工资
SELECT department_id,MIN(salary) FROM employees
GROUP BY department_id
HAVING MIN(salary) > (SELECT MIN(salary) FROM employees WHERE department_id = 50 GROUP BY department_id)
- 子查询中的空值问题
# 这里例子不会报错,但是不会返回任何结果, job_id = null,所以没有返回结果
SELECT last_name, job_id FROM employees
WHERE job_id = (
SELECT job_id
FROM employees
WHERE last_name = 'Haas'
);
- 非法使用子查询
# 报错: subquery returns more than 1 row(子查询返回不止一个值,sql无法处理)
SELECT employee_id, last_name FROM employees
WHERE salary = (SELECT MIN(salary) FROM employees GROUP BY department_id);
多行子查询
- 多行比较操作符
- IN: 等于列表中的任意一个
- ANY(SOME): 需要和单行比较操作符一起使用,和子查询返回的某一个值比较
- ALL: 需要和单行比较操作符一起使用,和子查询返回的所有值比较
- 注意 IN 和 ANY 的区别
# 返回 其它job_id中 比 job_id为‘IT_PROG’部门任一工资低的员工 的 员工号、姓名、job_id 以及salary
SELECT employee_id,last_name,job_id,salary FROM employees
WHERE salary < ANY( # 注意搭配符号'< ANY',这里若 ANY 丢了,就变成单行子查询,会报错
SELECT salary FROM employees WHERE job_id = 'IT_PROG'
)
AND job_id <> 'IT_PROG'
# 返回 其它job_id中 比 job_id为‘IT_PROG’部门"所有"工资低的员工 的 员工号、姓名、job_id 以及salary
SELECT employee_id,last_name,job_id,salary FROM employees
WHERE salary < ALL( # 修改之处
SELECT salary FROM employees WHERE job_id = 'IT_PROG'
)
AND job_id <> 'IT_PROG'
# 查询平均工资最低的部门id
SELECT department_id FROM employees GROUP BY department_id HAVING AVG (salary) =
(SELECT MIN (avg_sal) FROM
(SELECT AVG (salary) avg_sal FROM employees GROUP BY department_id) dept_avg_sal)
# 空值问题
SELECT last_name FROM employees
WHERE employee_id NOT IN (
SELECT manager_id
FROM employees);
关联子查询
- 定义:如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,
并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为关联子查询
# 查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id(看不懂)
SELECT last_name,salary,department_id FROM employees em WHERE salary > (
SELECT AVG(salary) FROM employees WHERE department_id = em.department_id
)
- 在from 中使用子查询
SELECT last_name,salary,e1.department_id
FROM employees e1,(SELECT department_id,AVG(salary) dept_avg_sal FROM employees GROUP
BY department_id) e2
WHERE e1.`department_id` = e2.department_id
AND e2.dept_avg_sal < e1.`salary`;
- 在ORDER BY 中使用子查询
# 查询员工的id,salary,按照department_name 排序
SELECT employee_id,salary
FROM employees e
ORDER BY (
SELECT department_name
FROM departments d
WHERE e.`department_id` = d.`department_id`
);
- 小结: 在 SELECT 中,除了 GROUP BY 和 LIMIT 之外,其他位置都可以声明子查询

 浙公网安备 33010602011771号
浙公网安备 33010602011771号