正则表达式
?: ?= ?!非捕获元的使用
正则表达式中()表示捕获分组,()会把每个分组里的匹配的值保存起来,多个匹配值可以通过数字n来查看(n是一个数字,表示第n个捕获组的内容)。
- ?: 是用来消除使用圆括号匹配被缓存的副作用。
- ?= 正向预查,在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串。
exp1(?=exp2) 查找exp2 前面的exp1
runoob(?:(?=[\d]+))
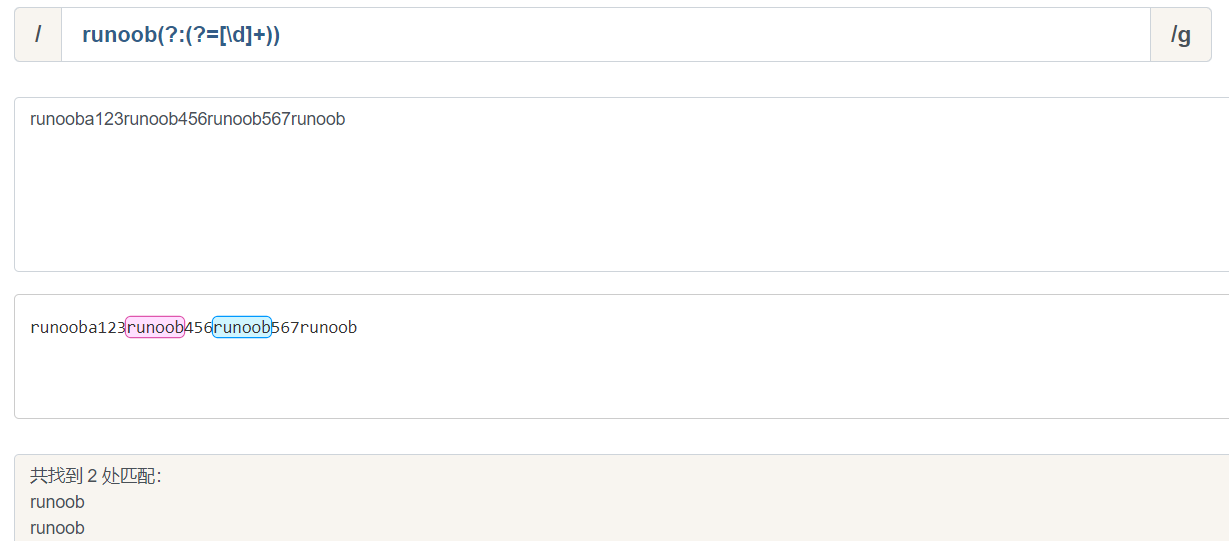
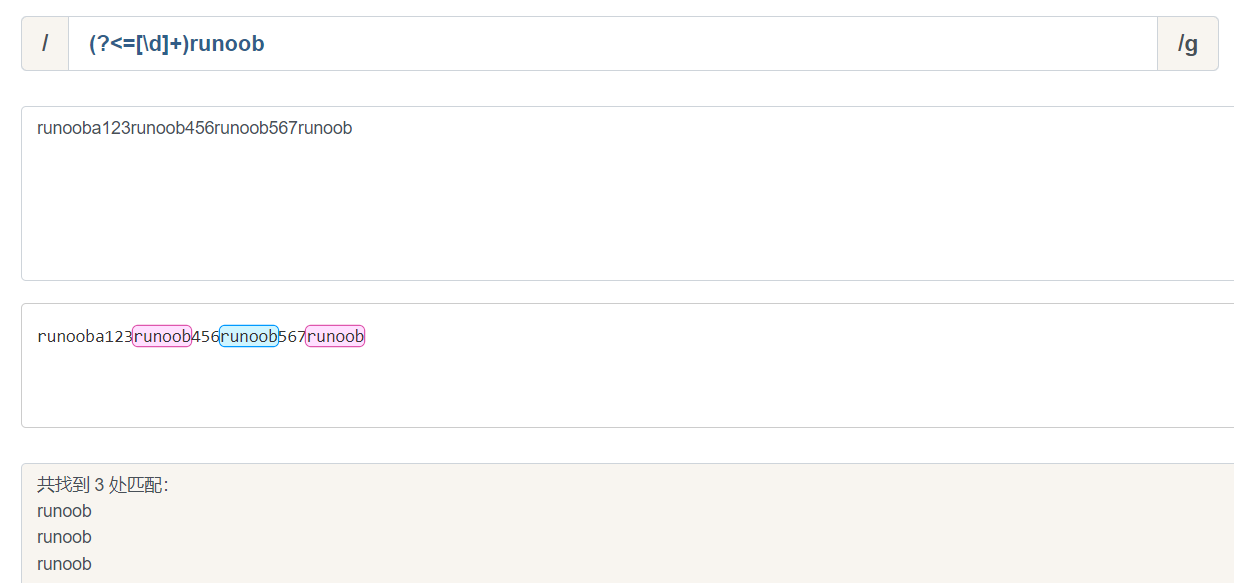
- ?<= (?<=exp2)exp1 查找exp2 后面的exp1
(?<=[\d]+)runoob
- ?! exp1(?!exp2) 查找后面不是exp2的exp1
runoob(?:(?![\d]+))
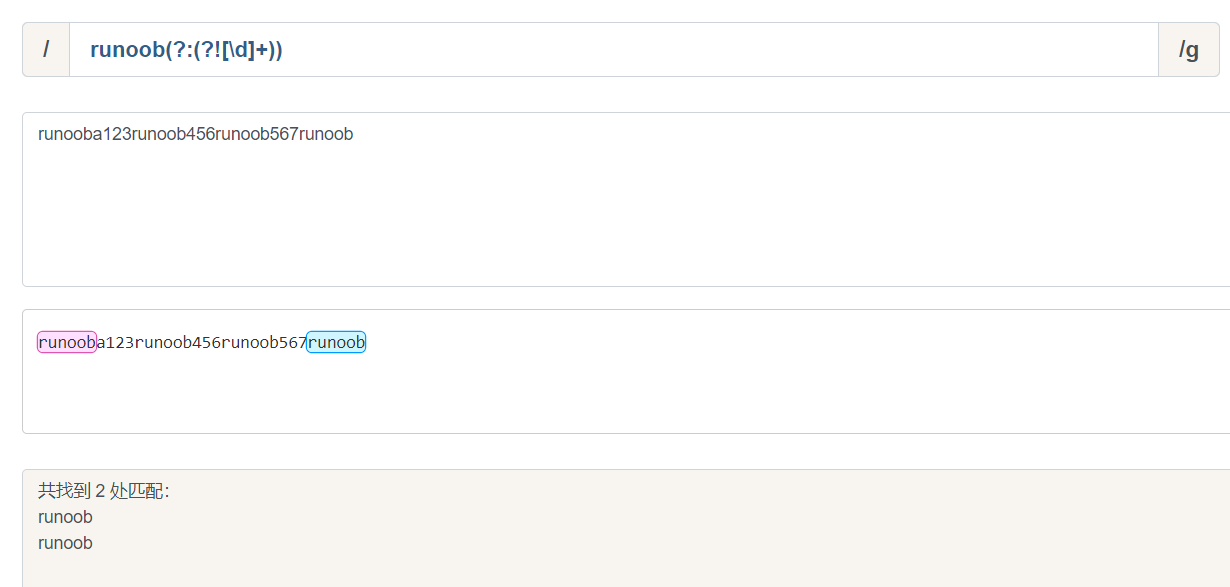
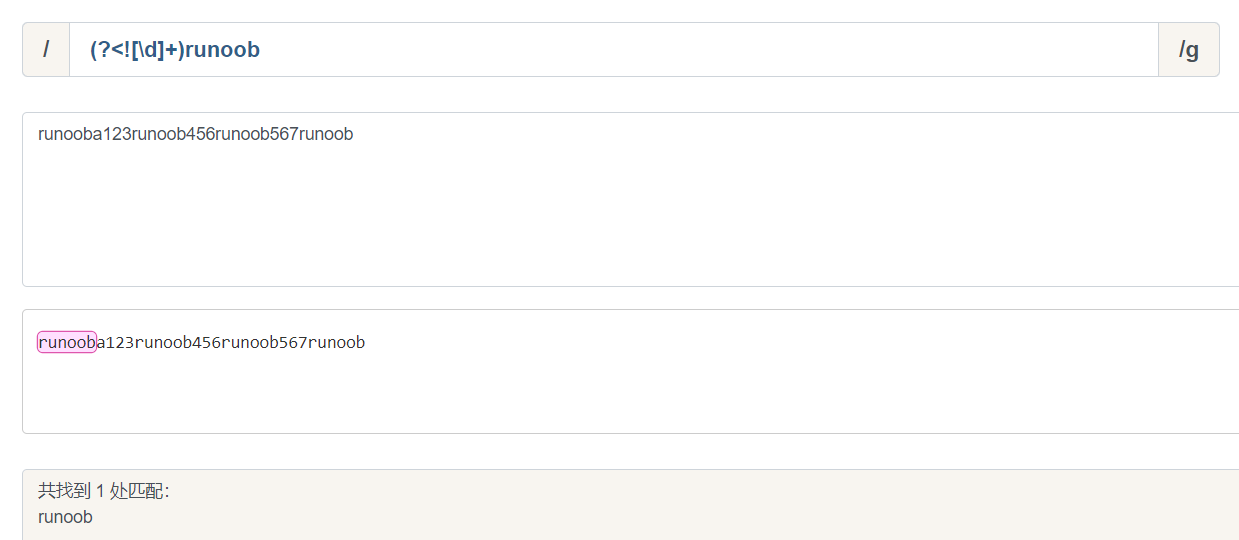
- ?<! (?<!exp2)exp1 查找前面不是exp2的exp1
(?<![\d]+)runoob
反向引用
对一个正在表达式模式或部分模式两边添加圆括号将导致相关匹配到一个临时缓冲区,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓存区标号从1开始,最多可存储99个捕获的子表达式。每个缓冲区都可以使用\n访问,其中n为一个表示特定缓冲区的以为或两位十进制。
可以使用非捕获元字符?:、 ?=、?!来重写捕获,忽略对相关匹配的保存。
反向引用的最简单,最有用的应用之一,是提供查找文本中两个相同的相邻单词的匹配项的能力。
例如匹配This is is my test test sample.中 is is / test test
/(\b[A-z]+) \1\b/igm
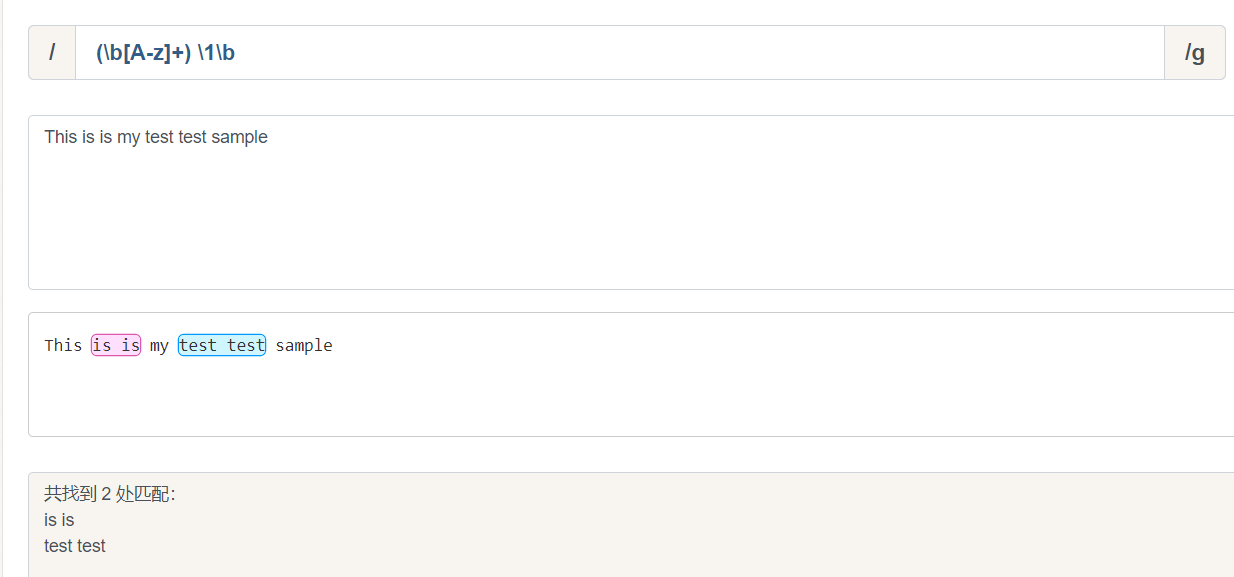
g: 全局匹配
i: 忽略大小写
m: 多行匹配
反向应用还可以将通过资源指示符(URI)分解其组件。假定将下面的URI分解为协议(ftp,http 等等),域地址和页/路径:
/(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)/
https://i.cnblogs.com/posts/edit;postId=17374059


 浙公网安备 33010602011771号
浙公网安备 33010602011771号