
ICCV2019 oral:Wavelet Domain Style Transfer for an Effective Perception-distortion Tradeoff in Single Image Super-Resolution
引言
基于低分辨率的图像恢复高分辨图像具有重要意义,近年来,利用深度学习做单张图像超分辨主要有两个大方向:1、减小失真度(distortion, 意味着高PSNR)的图像超分辨,这类方法主要最小化均方误差;2、提高感知质量(perception)的图像。这类方法主要利用GAN来做约束,使得生成的图像和真实的高分辨率图像尽可能符合相同分布。这两大方向存在一种tradeoff,因为通常低失真度(高PSNR)的图像往往感知质量不高,不符合人眼认知,而高感知质量(本文用NRQM指标度量,高NRQM)的图像,用PNSR指标衡量较低。如下图:
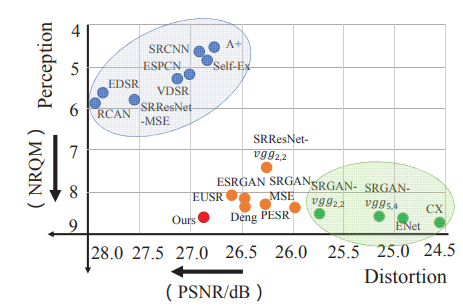
当前有工作考虑分别用两个网络训练生成低失真度和高感知质量的图像,再进行插值融合。然而图像的objective quality和perception quality由图像的不同部分影响,如果将目标图像作为整体优化,提高objective quality时,perception quality会下降,反之亦然。因此本文提出一种新的两图像(低失真度和高感知图像)融合策略。本文利用小波变换将图像分解成低频部分和高频部分,低频部分影响objective quality,高频部分影响perception quality.
Motivation(动机)
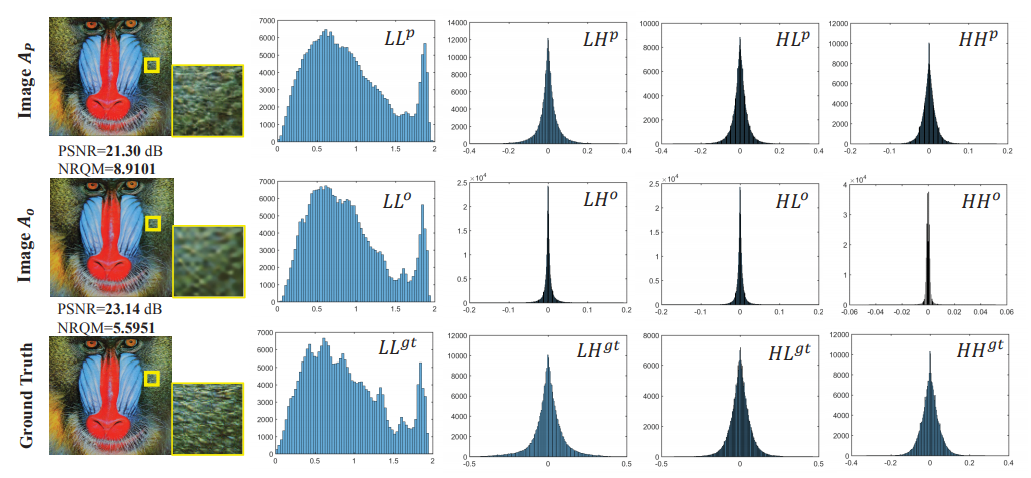
论文将利用CX算法得到的高分辨图像$A_p$(high perception quality)、EDSR算法得到的高分辨图像$A_o$(high objective quality)、GroundTruth进行Haar小波分解,得到一个低频子带和三个高频自带,并展示它们的直方图,发现$A_o$图像低频部分和GroundTruth对应的低频部分分布很接近,而$A_p$的三个高频子带的分布和GroundTruth对应的高频子带分布很接近。
算法:
将$A_o$分解为 $LL^{o}, LH^{o}, HL^{o}, HH^{o}$, $A_p$分解为$LL^{p}, LH^{p}, HL^{p}, HH^{p}$, 融合后的图像子带$LL^{r}$, $LH^{r}$, $HL^{r}$, $HH^{r}$.算法总体框架如下:
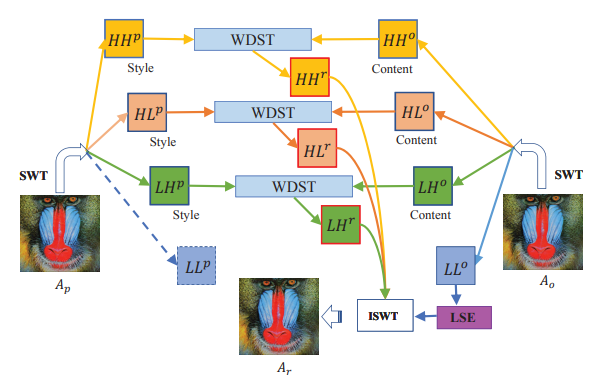
利用LSE网络,以$LL^{o}$作为输入恢复$LL^{r}$,利用WDST网络,以$LH^{o}$,$LH^{p}$,$LH^{r}$作为网络输入,其中$LH^{r}$作为可训练参数(具体细节后面再说)。$HL^{r}$,$HH^{r}$同理可得。
LSE网络如下:

WDST网络如下:
第一部分:重构$LL^{r}$
考虑GroundTruth的$LL^{gt}$子带和$LL^{o}$最相似,直接用$LL^{o}$恢复。利用VDSR网络思想,网络学习$LL^{gt}$和$LL^{o}$的残差。损失函数如下:
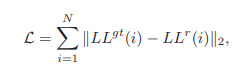
其中$LL^{r}$为$LL^{o}$和网络的输出。重构网络为LSE网络。
训练细节:
网络的训练以学习率1e-3,SGD优化算法(动量为0.9,衰减因子1e-4),梯度裁剪完成。
第二部分:重构$LH^{r}$, $HL^{r}$, $HH^{r}$
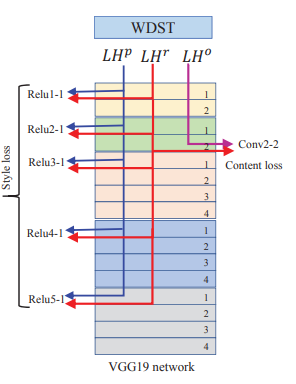
拿$LH^{r}$举例,用$LH^{o}$和$LH^{p}$融合得到$LH^{r}$.考虑到$LH^{p}$中的小波系数内容比$LH^{o}$的丰富,非0系数更多,期望将$LH^{p}$中的细节小波系数变换到$LH^{o}$中,因此将$LH^{p}$作为风格输入(style input),$LH^{o}$作为内容输入(content input)。不同于传统的风格迁移算法——输入是像素值,这里的输入小波系数,因此首先将小波系数归一化到0-1(值减去最小值,再除以最大值)
损失函数有三个:content loss($L_c$), style loss($L_s$)和$L_1$范数损失(保持重构小波系数的稀疏性)。如下:

其中
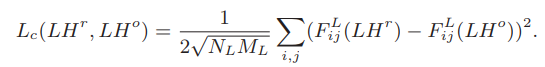
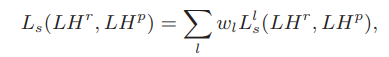
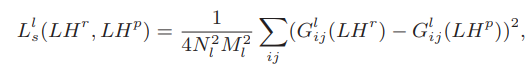
这里实际上是基于预训练的VGG作为WDST网络,只有一个参数是可训练的,那就是$LH^{r}$.
训练细节:用的L-BFGS优化算法.$\alpha=1e-3, \omega=0.2, \beta=1, \gamma=1e-5$
实验结果
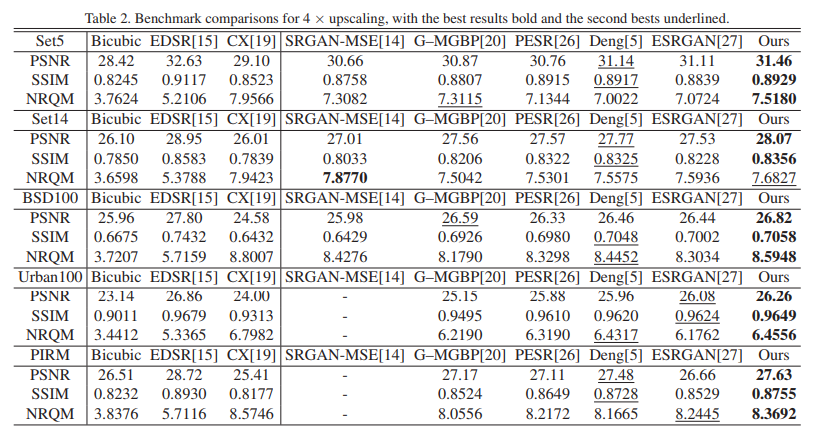
定量结果(PSNR/NRQM):
定性结果:


对比实验:
1、考虑不同小波分解产生的影响:
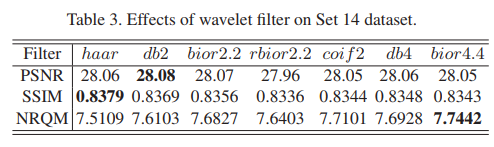
根据实验可以看出,用不同小波分解对实验结果影响不大。
2、不同高频子带重构,对最终的影响
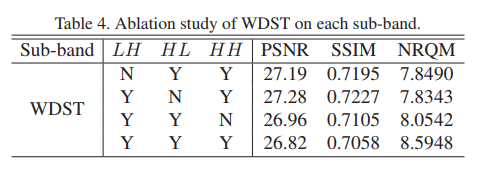
可以看出三个高频子带都有贡献,相比于$LH, HL$,$HH$的贡献最小,因为$HH$为对角方向信息,不如$LH, HL$他们携带的信息多。
相关链接
