
3.3、函数其他介绍
装饰器函数
1.介绍:装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用
装饰器=高阶函数+函数嵌套+闭包
2.装饰器的框架


from functools import wraps def deco(func): @wraps(func) #加在最内层函数正上方 def wrapper(*args,**kwargs): return func(*args,**kwargs) return wrapper
def outer(flag): def timer(func): def inner(*args,**kwargs): if flag: print('''执行函数之前要做的''') re = func(*args,**kwargs) if flag: print('''执行函数之后要做的''') return re return inner return timer @outer(False) def func(): print(111) func()
def wrapper1(func): def inner(): print('wrapper1 ,before func') func() print('wrapper1 ,after func') return inner def wrapper2(func): def inner(): print('wrapper2 ,before func') func() print('wrapper2 ,after func') return inner @wrapper2 @wrapper1 def f(): print('in f') f()
3.列子
装饰器的基本框架列子:
import time def timmer (func) : #func=test def wapper(): start_time=time.time() func() #就是在运行test() stop_time = time.time() print("函数的运行时间是%s" %(start_time-stop_time)) return wapper @timmer #test=timeer(test) def test(): time.sleep(2.5) print("函数运行完毕") test()
加上参数的装饰器的列子
def timmer (func): #func=test def wapper(*args,**kwargs): start_time=time.time() func(*args,**kwargs) #就是在运行test() stop_time = time.time() print("函数的运行时间是%s" %(start_time-stop_time)) return wapper @timmer #test=timeer(test) def test(name,age): time.sleep(2.5) print("test函数运行完毕,名字是(%s),年龄是(%s)" %(name,age,)) return test("陈",18) @timmer def test2 (name,age,gender): time.sleep(3) print("test2函数运行完毕,名字:(%s),年龄:(%s),性别:(%s)"%(name,age,gender)) test2("alex",18,"男")
加上返回值的装饰器的列子
import time def timer(func): def inner(*args,**kwargs): start = time.time() re = func(*args,**kwargs) print(time.time() - start) return re return inner @timer #==> func2 = timer(func2) def func2(a): print('in func2 and get a:%s'%(a)) return 'fun2 over' func2('aaaaaa') print(func2('aaaaaa'))
4. 防止装饰器失效
from functools import wraps def deco(func): @wraps(func) #加在最内层函数正上方 def wrapper(*args,**kwargs): return func(*args,**kwargs) return wrapper @deco def index(): '''哈哈哈哈''' print('from index') print(index.__doc__) print(index.__name__)
5.多个装饰器装饰同一个函数
def wrapper1(func): def inner(): print('wrapper1 ,before func') func() print('wrapper1 ,after func') return inner def wrapper2(func): def inner(): print('wrapper2 ,before func') func() print('wrapper2 ,after func') return inner @wrapper2 @wrapper1 def f(): print('in f') f()
迭代器
1.可迭代对象(Iterable)
可用于for循环的对象统称为可迭代对象 ,字符串,列表,元组,集合,字典,生成器 都是可迭代的。可以使用isinstance()来判断一个对象是否是Iterable对象
2.迭代器定义(Iterator):
可以被next()函数调用并不断返回下一个值的对象称为迭代器。
理解:实际上,Python中的Iterator对象表示的是一个数据流,Iterator可以被next()函数调用被不断返回下一个数据,直到没有数据可以返回时抛出StopIteration异常错误。可以把这个数据流看做一个有序序列,但我们无法提前知道这个序列的长度。同时,Iterator的计算是惰性的,只有通过next()函数时才会计算并返回下一个数据。
3、可迭代协议:可以被迭代要满足要求的就叫做可迭代协议。内部实现了__iter__方法
iterable:可迭代的------对应的标志
什么叫迭代?:一个一个取值,就像for循环一样取值
4、迭代器协议:内部实现了__iter__,__next__方法
迭代器大部分都是在python的内部去使用的,我们直接拿来用就行了
迭代器的优点:如果用了迭代器,节约内存,方便操作
dir([1,2].__iter__())是列表迭代器中实现的所有的方法,而dir([1,2])是列表中实现的所有方法,都是以列表的方式返回给我们,为了方便看清楚,我们把他们转换成集合,然后取差集,然而,我们看到列表迭代器中多出了三个方法,那么这三个方法都分别是干什么的呢?
生成器
列表的生成:
>>>>L= [x*x for x in range(10)]
>>>>L
[0,1,4,9,16,25,36,49,64,81]
1.生成器的定义:在Python中,这种一边循环一边计算的机制,称为生成器:generator。(本质就是一个迭代器)
元素的获取
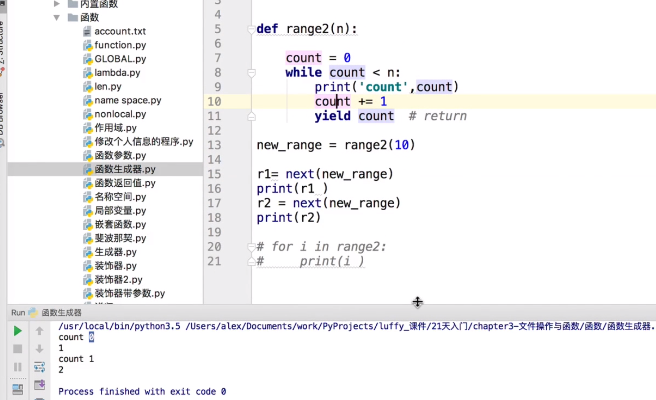
1.通过 next()打印出generator的每一个元素,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误
通过next()获取
2.使用for循环获取元素
>>> g = (x * x for x in range(10)) >>> for n in g: ... print(n) ... 9 49
2.创建:
1.把一个列表生成式的[]改成(),就创建了一个generator
>>> g = (x * x for x in range(10)) >>> g <generator object <genexpr> at 0x1022ef630> 2.通过函数实现
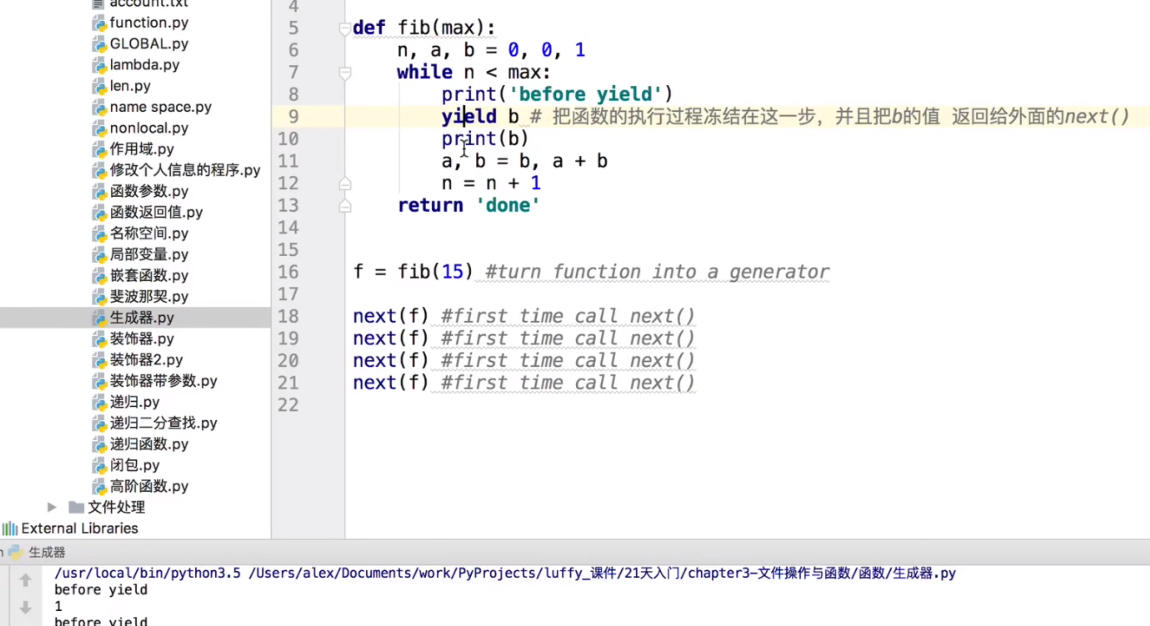
##除第一个和第二个数外,任意一个数都可由前两个数相加得到:1, 1, 2, 3, 5, 8, 13, 21, 34, ... def fib(max): n, a, b = 0, 0, 1 while n < max: yield b a, b = b, a + b n = n + 1 return 'done' f = fib(6) f <generator object fib at 0x104feaaa0> ##如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:在generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。 将函数中的return换成yield就是生成器 # 函数 def func(): print('这是函数func') return '函数func' func() # 生成器 def func1(): print('这是函数func1') yield '函数func' func1()
__next__()来执行生成器
def func(): print("111") yield 222 gener = func() # 这个时候函数不会执⾏. ⽽是获取到⽣成器 ret = gener.__next__() # 这个时候函数才会执⾏. yield的作⽤和return⼀样. 也是返回数据 print(ret) 结果: 222
send方法:send和__next__()一样都可以让生成器执行到下一个yield
def eat(): for i in range(1,10000): a = yield '包子'+str(i) print('a is',a) b = yield '窝窝头' print('b is', b) e = eat() print(e.__next__()) print(e.send('大葱')) print(e.send('大蒜'))
send和__next__()区别:
send 和 next()都是让生成器向下走一次
send可以给上一个yield的位置传递值,不能给最后一个yield发送值,在第一次执行生成器的时候不能使用send()
第一次调用的时候使用send()也可以但是send的参数必须是None
def func1(): print('这是函数func1') f1 = yield '你好' print(f1) f2 = yield '我好' print(f2) f = func1() f.__next__() f.send('大家好')
yield from:在python3中提供一种可以直接把可迭代对象中的每一个数据作为生成器的结果进行返回
def func(): lst = ['卫龙','老冰棍','北冰洋','牛羊配'] yield from lst g = func() for i in g: print(i) ##有个小坑,yield from 是将列表中的每一个元素返回,所以 如果写两个yield from 并不会产生交替的效果 def func(): lst1 = ['卫龙','老冰棍','北冰洋','牛羊配'] lst2 = ['馒头','花卷','豆包','大饼'] yield from lst1 yield from lst2 g = func() for i in g: print(i)
三元表达式
列表推导式
递归、匿名函数
定义:在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
def fact(n): if n==1: return 1 return n * fact(n - 1) fact(5) #打印结果为 120 #计算过程: ===> fact(5) ===> 5 * fact(4) ===> 5 * (4 * fact(3)) ===> 5 * (4 * (3 * fact(2))) ===> 5 * (4 * (3 * (2 * fact(1)))) ===> 5 * (4 * (3 * (2 * 1))) ===> 5 * (4 * (3 * 2)) ===> 5 * (4 * 6) ===> 5 * 24 ===> 120
递归次数的限制:最大递归层数做了一个限制:997,但是可以通过导入sys模块的方式来修改改变限制的次数(sys模块:所有和python相关的设置和方法)列如:
import sys sys.setrecursionlimit(1500)#修改递归层数 def recursion(n): print(n) recursion(n+1) recursion(1) #打印结果 1 2 3 .....1497
递归的特性:必须有一个明确的结束条件(return),要不就变成死循环了,每次进入更深一层递归时,问题规模相比上一次递归都应有所减少,递归的执行效率不高,递归层次过多会导致栈的溢出。
列子:
def calc(n): v=int(n/2) print(v) if v==0: return calc(v) calc(10) #打印结果 5 2 1 0 *******体会******** def calc(n): v=int(n/2) if v==0: return calc(v) print(v) calc(10) #打印结果 1 2 5
递归的作用:求斐波那契数列,汉诺塔,多级评论树,二分查找,求阶乘等
# N! = 1 * 2 * 3 * ... * N def fact(n): if n == 1: return 1 return n * fact(n-1) fact(n)
def move(n, a, b, c): if n == 1: print('move', a, '-->', c) else: move(n-1, a, c, b) move(1, a, b, c) move(n-1, b, a, c) move(4, 'A', 'B', 'C')
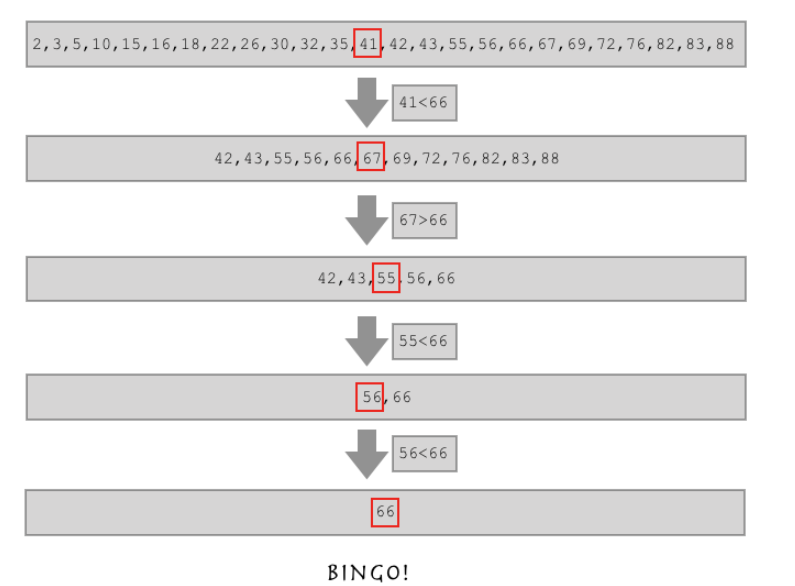
这就是二分查找,从上面的列表中可以观察到,这个列表是从小到大依次递增的有序列表。
按照上面的图就可以实现查找了
l = [2, 3, 5, 10, 15, 16, 18, 22, 26, 30, 32, 35, 41, 42, 43, 55, 56, 66, 67, 69, 72, 76, 82, 83, 88] def find(l,aim): mid=len(l)//2#取中间值,//长度取整(取出来的是索引) if l[mid]>aim:#判断中间值和要找的那个值的大小关系 new_l=l[:mid]#顾头不顾尾 return find(new_l,aim)#递归算法中在每次函数调用的时候在前面加return elif l[mid]<aim: new_l=l[mid+1:] return find(new_l,aim) else: return l[mid] print(find(l,66))
l = [2, 3, 5, 10, 15, 16, 18, 22, 26, 30, 32, 35, 41, 42, 43, 55, 56, 66, 67, 69, 72, 76, 82, 83, 88] def func(l, aim,start = 0,end = len(l)-1): mid = (start+end)//2#求中间的数 if not l[start:end+1]:#如果你要找的数不在里面,就return'你查找的数字不在这个列表里面' return '你查找的数字不在这个列表里面' elif aim > l[mid]: return func(l,aim,mid+1,end) elif aim < l[mid]: return func(l,aim,start,mid-1) elif aim == l[mid]: print("bingo") return mid index = func(l,55) print(index) # print(func(l,41))
尾递归优化:使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)(#相当于存放数据的盒子)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。解决递归调用栈溢出的方法是通过尾递归优化。在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况
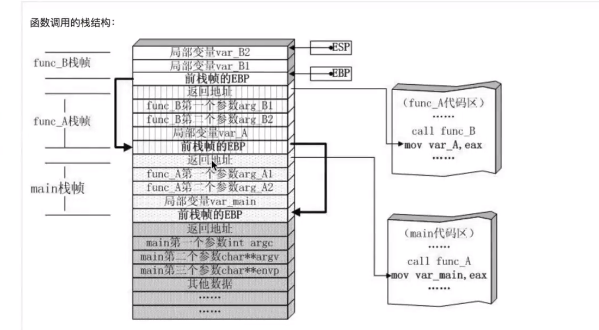
列子:
def cal(n): print(n) return cal(n+1) cal(n) #不是所有的语言都支持,在python里不支持尾递归优化
小结
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。
针对尾递归优化的语言可以通过尾递归防止栈溢出。尾递归事实上和循环是等价的,没有循环语句的编程语言只能通过尾递归实现循环。
Python标准的解释器没有针对尾递归做优化,任何递归函数都存在栈溢出的问题。
匿名函数与三元运算
一、匿名函数:也叫lambda表达式
1.匿名函数的核心:一些简单的需要用函数去解决的问题,匿名函数的函数体只有一行
2.参数可以有多个,用逗号隔开
3.返回值和正常的函数一样可以是任意的数据类型
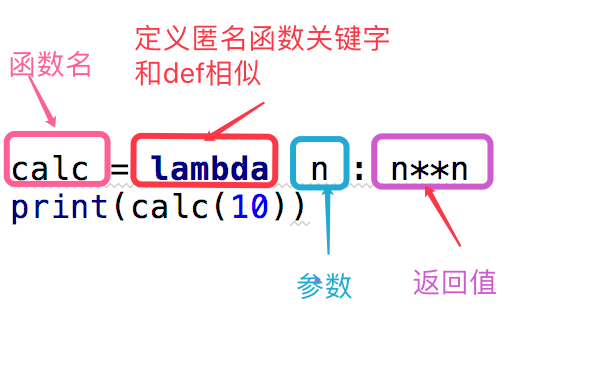
语法:
请把下面的函数转换成匿名函数 def add(x,y) return x+y add() 结果: sum1=lambda x,y:x+y print(sum1(5,8))
与map的应用:
l=[1,2,3,4] # def func(x): # return x*x # print(list(map(func,l))) print(list(map(lambda x:x*x,l)))
filter函数的小应用:
l=[15,24,31,14] # def func(x): # return x>20 # print(list(filter(func,l))) print(list(filter(lambda x:x>20,l)))
二、三元运算
python的三元运算格式:
result=值1 if x<y else 值2 这个是什么意思呢,就是结果=值1 if 条件1 else 值2
>>> def f(x,y): return x - y if x>y else abs(x-y) #如果x大于y就返回x-y的值 ,否则就返回x-y的绝对值 >>> f(3,4) #3<4,不满足if 条件,它返回else里面的绝度值 >>> f(4,3) >>> def f(x,y): return 1 if x>y else -1 #如果x大于y就返回x-y的值 ,否则就返-1 >>> f(3,4) #3小于4 , 返回-1 -1 >>> f(4,3) #4大于3,返回1 >>>
