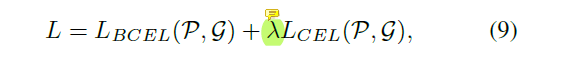Multi-scale Interactive Network for Salient Object Detection
Multi-scale Interactive Network for Salient Object Detection
CVPR20
摘要
本文提出MINet。在编码器中使用聚合交互模块AIM(aggregate interaction modules)来聚合相邻level的特征,由于仅使用小的up/down采样率,引入了很少噪声。在解码器中使用自交互模型SIM(self-interaction module)来利用multi-scale特征。
由于尺度变化造成类别不平衡,这削弱了交叉熵的效果,也造成预测的空间不一致性。因此本文提出consistency-enhanced loss强调前景背景的差异,保持类间一致性。
网络结构
图2左列是encoder-transport layer的连接方式,右列是transport layer-decoder的连接方式。
图中d是AIM聚合交互模块,h是SIM自交互模块

图3是整体的结构,图示是采用VGG16做特征提取,本文移除vgg的最后一个max-pooling层来保持最后一个卷积层的细节信息。每个AIM利用相邻level的特征,为本分辨率(主分支)提供有效的补充。SIM从特定level提取multi-scale特征,FU由conv+bn+relu组成,FU融合SIM的特征,并输入到前一层里。
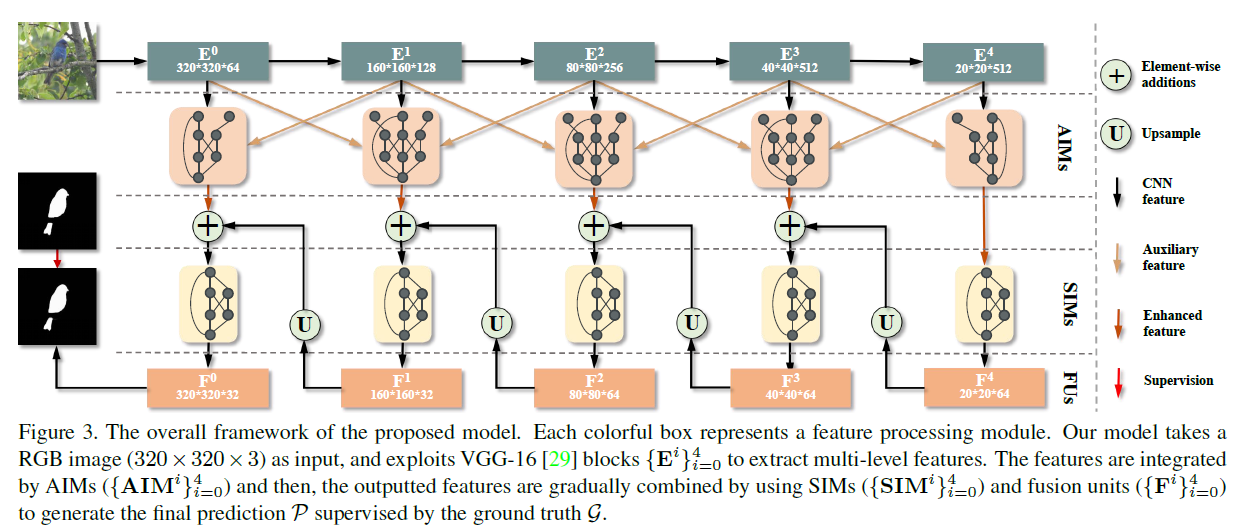
输入320x320x3的图像, 使用vgg16提取multi-level特征,使用AIM聚合特征,通过SIM和FU进一步处理,在 g 的监督下生成预测 p。
在AIM中主分支B1,SIM中主分支B0均由辅助分支补充信息,
AIMs
受[54]启发,提出AIM,
图4是聚合交互模块的细节图

在不同level做融合会增强不同分辨率图的表达能力:在浅层融合可进一步增强细节信息并抑制噪声。在中间层融合可以同时考虑语义信息和细节信息,且网络会自动调整不同信息的比例。在顶层融合考虑相邻分辨率时会挖掘丰富的语义信息。
f 表示vgg提取的特征,在transformation步做conv+bn+relu。在interaction步通过pooling+近邻插值+conv将辅助分支(B0 B2)合并到B1支。通过conv把三支fuse,同时有一个残差连接。
如公式1,I是identity mapping,M是brach merging。第一行公式的+号表示残差连接

SIMs
图5是自交互模块的细节图
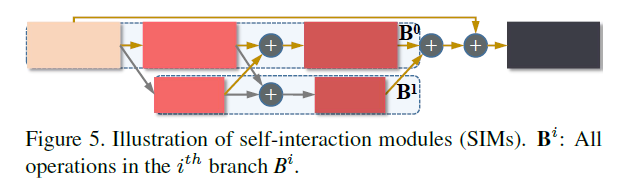
也遵循transformation-interaction-fusion策略,先使用升/降采样把特征图的分辨率统一。
公式2,+号表示SIM的残差连接
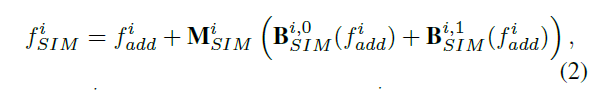
公式3,

\(f_{add}\)指本层AIM和后一层SIM+FU输出的特征的相加结果。
consistency-enhanced loss
CEL loss 用于解决类别不均衡问题
预测输出p,如公式4

 ,p是01之间的概率,N是batch_size个数。
,p是01之间的概率,N是batch_size个数。
本文提出CEL损失,如公式6,使用预测和gt的交集除以他们的并集。当预测结果和gt相差最大时,loss=1;相差很小时,loss也小。
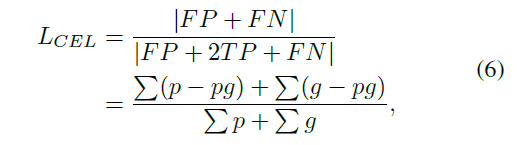
导数公式对比如下,
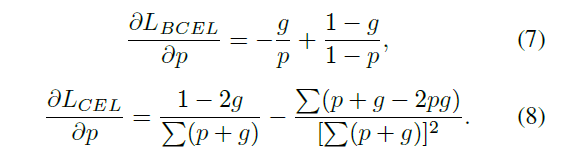
CEL的偏导公式里除了1-2g,其他的项是image-specific,考虑了全局约束。而BCEL的项是position-specific,只在乎独立的像素点的预测。
总的loss如下,简便起见权重=1