Fighting Fake News: Image Splice Detection via Learned Self-Consistency阅读
摘要 : 拼接检测定位方法: 提出一个学习算法,在大型真实图像数据集上训练,算法使用 EXIF 元数据做监督信号,训练模型去判断图像是不是自-连续的。这仅仅是寻找一个真正通用的视觉取证工具的漫长过程中的一步。
作者 : 
出处 : ECCV 2018
数据集 columbia[41] carvalho[42] RT[43]
实验环境 Training the EXIF-Consistency and Image-Consistency networks took approximately 4 weeks on 4 GPUs. Running the full self-consistency model took approximately 16 s per image
metrics mean average precision(mAP)、permuted-mAP、class-balanced IOU (cIOU)
1 Introduction
使用 EXIF 元数据做监督信号,训练分类模型,决定一幅图的 patches是不是由一个图像流水线生成的。模型是自监督的,只在训练中使用了真实图像和他们的 EXIF 元数据。对每个EXIF标签分别使用一对照片学习一个一致性分类器,并将得到的分类器组合在一起来估计新输入图像中patch对的自一致性
主要贡献:
- 将图像取证作为学习自一致性(一种异常检测)中的违规检测问题
- 提出摄影元数据作为学习自我一致性的自由而丰富的监督信号
- 将我们的自一致性模型应用于拼接的检测和定位。我们还介绍了一个新的图像拼接数据集,从互联网上获得,并实验评估哪些摄影元数据是可预测的图像。

3 Learning Photographic Self-consistency
模型预测两个 patches 是否彼此一致。给定 \(P_i\) 和 \(P_j\),估计他们的 n 个元数据相同的概率\(x_1,x_2,x_3,...,x_n\),然后结合 n 个观测值估计 patches 的整体一致性 \(c_{ij}\)
在评估阶段,给模型输入篡改图像,衡量许多不同的patches间的一致性。尽管任何一对patch的一致性分数都是有噪声的,但是将许多观测数据聚集在一起,可以提供一个合理稳定的整体图像自一致性估计。
3.1 Predicting EXIF Attribute Consistency
使用 siamese network 预测一对 128×128 的 patches 有相同 EXIF 属性的概率,使用来自 flicker 的随机40万张图像,在5万多张图片的所有 EXIF 属性上预测(n=80)
siamese network 使用 shared resnet-50[37] sub-networks,每个生成4096维的向量,这些向量拼接在一起,通过有4096,2048,1024个单元的 4-层 MLP ,然后输出
图4是对模型有用的 EXIF 属性

3.2 Post-processing Consistency
拼接区域会重新调整大小,边缘光滑,图像重新压缩jpeg格式。如果网络可以预测出patches是否是不同的后处理,那么这是有力的不一致证据。在训练时,加了3个增强操作 re-JPEGing, Gaussian blur, and image resizing,一半时间对两个patches加同一个操作,另一半时间加不同的操作。我们提出3个额外的分类任务(上述增强操作),让模型预测一对patches是否是同一种参数增强,现在 n=83。
3.3 Combining Consistency Predictions
一对 patch i 和 j 的 EXIF 的一致性预测 83-维向量 X,评估整体一致性 \(c_{ij}=p_{\theta}(y|X)\) ,\(p_{\theta}\) 是有512个隐藏单元的2-层MLP。训练网络预测 i 和 j 是否来自同一训练图像(相同,y=1,不同,y=0)
3.4 Directly Predicting Image Consistency
另一种方法是训练与3.1结构类似的网络,直接预测这两个补丁是否来自同一幅图像。(Image-Consistency)
3.5 From Patch Consistency to Image Self-Consistency
给一副图像,采样450个patches。对于一个patch,可视化一个响应图,响应图是其与图像中其他patch的一致性。为了提高每个响应图的空间分辨率,我们对重叠patch的预测进行平均。如果存在拼接,那么图像未被篡改部分的大部分patch与被篡改区域的patch的一致性较低。
要为输入图像生成单个响应映射,我们需要在所有补丁响应映射中找到最一致的模式。使用 mean shift[39]。合并的响应图叫做 a consistensy map。也可以通过带normalized cuts[40] 的仿射矩阵可视化篡改区域
检测使用了深度网,定位用的传统方法吧。
为了帮助理解不同的EXIF属性在一致性预测方面的差异,我们为示例图像的每个标记创建了响应映射(图7)。
虽然单个标记提供了一个有噪声的一致性信号,但是合并的响应映射精确地定位了拼接区域。

4 Results
4.1 Benchmarks
数据集
columbia[41]:180个相关的简单拼接
carvalho[42]:94幅图像
Realistic Tampering[43]:220图像,拼接后还有后处理操作。这个数据集中也有复制粘贴图像
in-the-wild:本文提出的新数据集,从网站收集的201个图像
reddit photoshop battles[44]:是一个用户创造和分享图片的在线社区
the scene completion data from Hays and Efros [1]:其中包括inpainting结果、mask 和总共 55 幅图像的源图像
metric
mean average precision(mAP):
例如:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于主题 2,平均准确率为(1/1+2/3+3/5+0+0)/3=0.7555。则MAP= (0.83+0.7555)/2=0.79。”
MRR是把标准答案在被评价系统给出结果中的排序取倒数作为它的准确度,再对所有的问题取平均。
permuted-mAP
class-balanced IOU (cIOU):Intersection over Union per class (用于测量真实和预测之间的相关度,相关度越高,该值越高)
对比方法:
Color Filter Array (CFA) [45]:检测色彩模式人工伪影
JPEG DCT [46]:检测 JPEG 系数的不一致
Noise Variance (NOI) [47]:使用小波检测异常噪声
以上方法的数据来自[48]
E-MFCN [17]:使用拼接图象和mask训练,使用FCN预测拼接mask和边界
为评估新数据集,使用前3数据集训练了一个标准FCN分类拼接像素
最后,我们提出了self-consistency 模型的两种变体:
1是Camera-Classification,直接预测是哪个相机模型产生了给定patch。我们通过从测试图像中采样图像patch,并将最频繁预测的相机指定为自然图像,其他的都指定为拼接区域,来评估相机分类模型的输出。当每个patch预测的相机模型一致时,我们认为图像是可以被篡改的。
2是Image-Consistency,直接预测两个patch是不是来自同一幅图像(Sect. 3.4)。如果一幅图像的组成补丁被预测来自不同的图像,那么它就被认为可能被篡改了。这些模型的评估与我们的完全EXIF-Consistency模型执行的方式相同
使用在imageNet上预训练的ResNet50,batch size=128,adam learning rate of 10−4
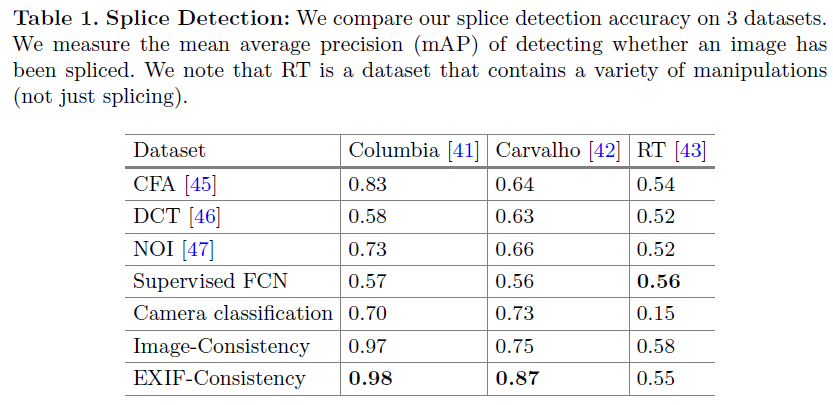
4.3 Splice Detection
数据集:Columbia, Carvalho, and Realistic Tampering
表1是检测结果,比监督学习FCN还要好
4.4 Splice Localization
表3 在全部的Columbia and Carvalho datasets数据集上评估
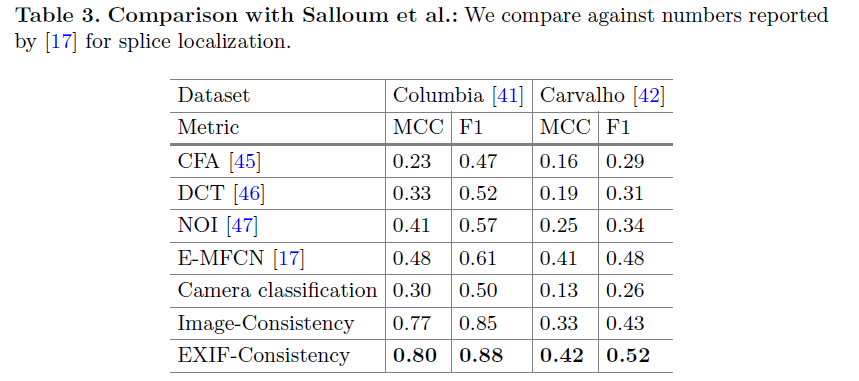
表2,本文模型在训练不用篡改图像的情况下还比使用篡改图像的对比方法好

图8 本文方法可视化

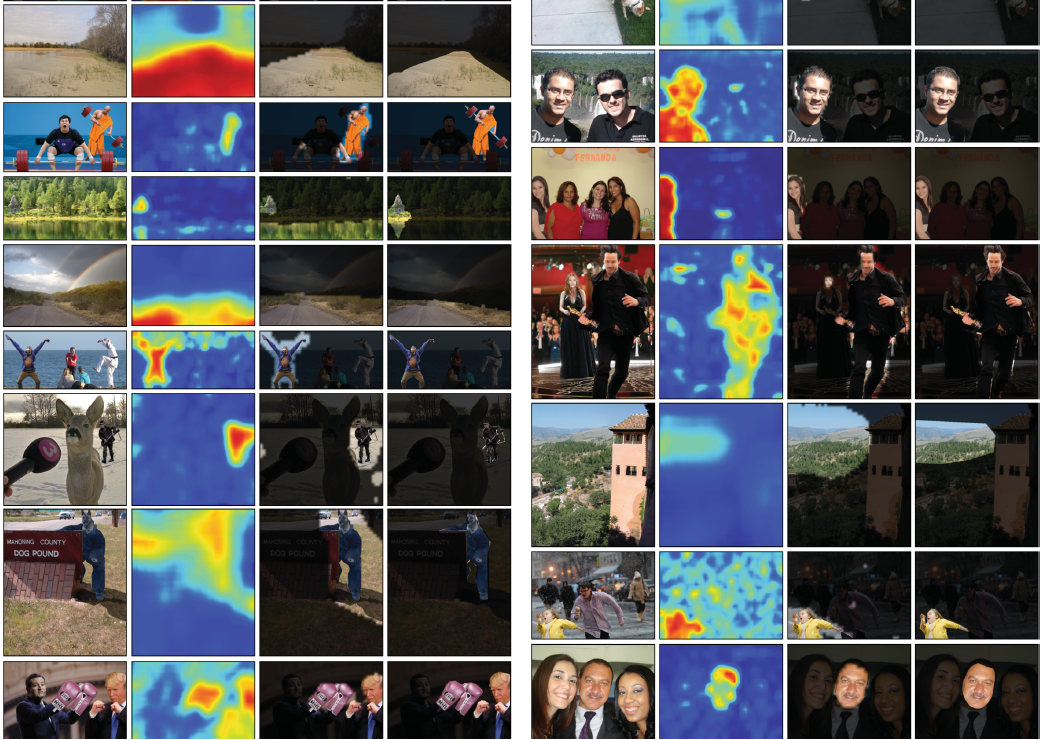

图11 和其他方法的对比

图10 失败的图像


 浙公网安备 33010602011771号
浙公网安备 33010602011771号