DOA-GAN: Dual-Order Attentive Generative Adversarial Network for Image Copy-move Forgery Detection and Localization
出处 :2020
作者 : 
摘要 : (复制粘贴检测)GAN with a dual-order attention model
-
生成器:
第一顺序注意力捕捉复制粘贴定位信息
第二顺序注意力为 patch co-occurence 寻找明显特征(discriminative feature)
-
从仿射矩阵提取 attention maps,用来融合 location-aware and co-occurrence features
-
判别器
确保定位结果更加准确
数据集 USC-ISI CMFD dataset [46]、 the CASIA CMFD dataset [46]、the CoMoFoD dataset [41]、COCO dataset [21].
实验环境
metrics 复制 presion、recall、F1 score
拼接 IOU F1 MCC
introduction
基于patch的方法 8 32 17
基于关键点的方法 49 33
基于不规则区域的方法 19 36
深度学习方法 44 22 46
本文提出双顺序注意力对抗生成网络(dual-order attentive Generative Adversarial Network)。
输入图像,然后基于每像素提取的特征向量计算仿射矩阵。设计双顺序注意力,生成 1st-order attention map \(A_1\)探索篡改的位置信息, 2nd-order attention map \(A_2\) 捕捉更准确的 patch 的相互依赖,由两个注意力图计算出最终的特征表示,再分别输入检测分支-->输出检测信心分数,输入定位分支-->输出预测 mask,标出源/目标区域
判别器判别预测结果和 ground truth 是否一致
仿射矩阵包含了 2nd-order 特征的统计数据,这启发我们探索\(A_2\) 来区分篡改区域和偶然的目标纹理相似。非对角元素的高值表明patch之间的复制-移动空间关系的高相似性,这启发我们探索\(A_1\) 来关注篡改区域。本文中,对仿射矩阵进行细化和规则化,取每一列的 top-k 值,形成 k 通道的 3D 张量。把张量输入 CNN ,形成1st-order attention map \(A_1\),关注源和目标区域。
本文的贡献如下:
- 提出一个双顺序注意力对抗生成网络来检测和定位图像复制粘贴篡改
- 1st-order注意力模型提取篡改区域注意力图,2nd-order 注意力模型提取像素依赖。提供更有区分力的特征描述
- 扩展实验表明我们方法的优越表现
related work
method

生成器是一个端到端的统一的结构,完成检测和定位任务。
输入图像 I ,使用 VGG19 的前四层提取分层特征,resize成相同大小,再拼接成\(F_{cat}\)。
计算仿射矩阵,经过双顺序注意力模型得到注意力图\(A_1\)\(A_2\) 。
参数不同的ASPP-1 和 ASPP-2 提取上下文特征 \(F_{aspp}^1\) \(F_{aspp}^2\) 。
\(A_1\)分别与 \(F_{aspp}^1\) \(F_{aspp}^2\)像素乘得到\(F_{atten}^1\) \(F_{atten}^2\) 。
\(A_2\) 分别与\(F_{atten}^1\) \(F_{atten}^2\) 做矩阵乘法得到\(F_{cooc}^1\) \(F_{cooc}^2\) 。
把四个特征融合,输入检测分支,得出检测分数(是篡改的可能性大小?)。输入定位分支,得到 mask 。(判别器的输入是 I 和 M )
3.1 generator network
输入图像 \(I\in \R^{H\times W\times 3}\),经过VGG19前三层提取特征图再resize成同样大小,拼接成 \(F_{cat}\in h \times w \times d\),令\(h=\frac{H}8\), \(w=\frac{W}8\) ,计算仿射矩阵 ,公式1
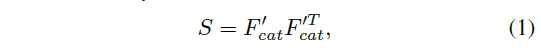
其中 \(F_{cat}^{'} \in \R^{hw \times d}\)
The Dual-Order Attention Module

提取 the copy-move aware region attention map \(A_1%\) 和 the co-occurrence attention map \(A_2\)。
在对一幅图像做自相关时,仿射矩阵的对角线上的值比较大。
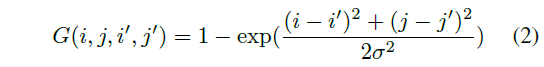
公式2 ,G使用高斯核减弱图像同一部份的相关性,得到新的仿射矩阵 $S^{'}=S \bigodot G $
使用[6]的 patch-matching 策略,计算 \(S^{'}\) 的 i 行的patch和 j 列的 patch 匹配的可能性。
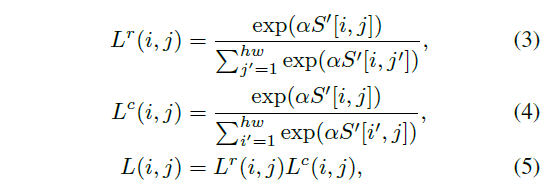
\(\alpha\)是一个可训练参数,初始化为3. \(L\in \R^{hw\times hw}\) 是最终的仿射矩阵。从 L 里取 top-k 的值,再 reshape 成 \(T\in\R^{h\times w\times k}\) ,把 T 输入注意力模型,如示意图

Atrous Spatial Pyramid Pooling (ASPP) Block
用来提取上下文信息,本文发现两个ASPP可以有效学习两个任务,源和目标检测
Feature Fusion
合并 copy-move region aware attentive features 和 co-occurrence features,这 4 个特征向量可以好好利用 patch 间的依赖关系,并且基于相似度度量,远处像素能够对位置上的特征响应做出贡献
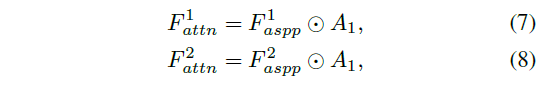
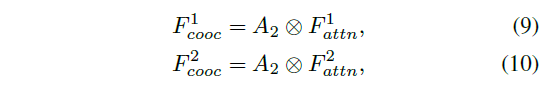
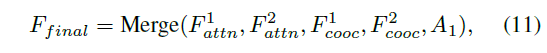
merge 操作指的是 concatenation
Detection Branch and Localization Branch
3.2 Discriminator Network
判别器的结构基于the Patch-GAN discriminator [18]。判别器用来预测图像中每一个NXN的 patch 是真是假
判别器的输入是 I 和 mask M,鉴别器被训练来分辨 ground truth mask 和predicted mask,而生成器试图欺骗鉴别器。
3.3 Loss Functions
损失函数由对抗损失、交叉熵损失和检测损失计算
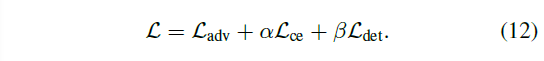
Adversarial Loss
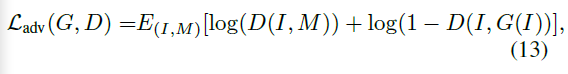
判别器 D 努力最大化目标,生成器 G 努力最小化目标
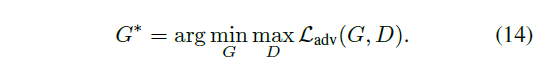
Cross-Entropy Loss
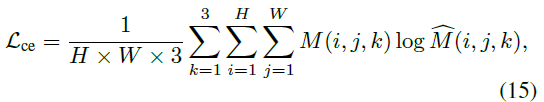
\(\widehat{M}=G(I)\) 是生成器的预测 mask,M 是 ground truth mask
Detection Loss
是检测分支的分数和真实标签间的二值交叉熵损失
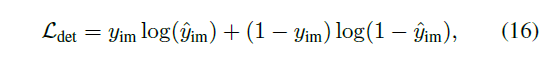
图像包含篡改,\(y_m=1\)。没有,\(y_m=0\)。\(\hat m_{im}\) 是检测分支的输出
3.4 Implementation Details
特征提取使用在 imagenet 上预训练的 VGG19 的前三层
ASPP 依据 DeepLabV3+ [5] 使用
第一顺序注意力里,k=20
生成器学习率0.001,判别器学习率0.0001,VGG19学习率0.0001,在5 epoches后减半学习率。在训练时,首先只优化3 epoch 生成器的交叉熵损失,然后优化所有损失。判别器损失=0.3时,冻结判别器,直到损失再增加。这确保了生成器和判别器以相似的速度学习,而判别器不会过度训练。
4 Experimental Results
数据集:
USC-ISI CMFD dataset [46] :训练、验证、测试分别有 80K 、10K、10K的图像
the CASIA CMFD dataset [46]:有1313 篡改图像和对应的1313原图
and the CoMoFoD dataset [41]:有5000篡改图像,200基础图像,25 个操作类别包括 5 种作和 5 个后处理方法
实验
检测用图像级,定位用像素级,指标是precion recall F1 score,3 个类别Pristine (background), Source, and Target
4.1 Experiments on the USC-ISI CMFD dataset
对比方法:
BusterNet [46]
ManTra-Net [47]
U-Net [38]
NA-GAN(没有注意力)
FOA-GAN(只用 1st-order 注意力)
SOA-GAN(只用 2nd-order 注意力)
DOA-GAN w/o \(L_{adv}\)(移除对抗损失)
DOA-GAN w/o \(L_{det}\)(移除检测损失)
使用 coco 的 10k 个原图和 USC-ISI 的 80k 个图像训练 DOA GAN
像素级评估,只在篡改图像上(不包括原始图像)计算每幅图的平均 precision、recall、F1 score,
图像级评估,使用 20k 图像(有篡改的和非篡改的 )
若预测分支输出分数>0.5,认为是篡改
对于 BusterNet 和 DOA-GAN w/o \(L_{det}\),若输出mask有>200像素是源或目标区域,认为图像是篡改
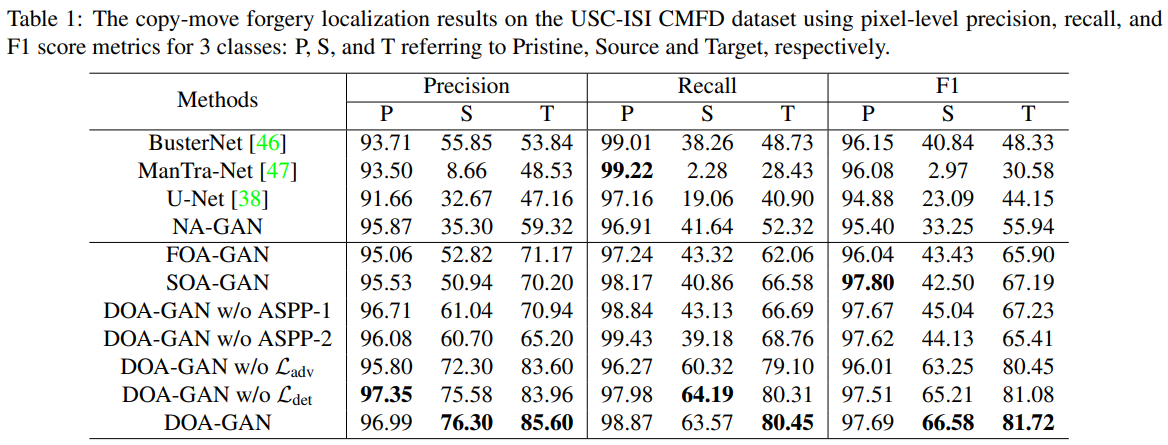
表1 是定位结果
本文生成三通道结果
表2 是检测结果
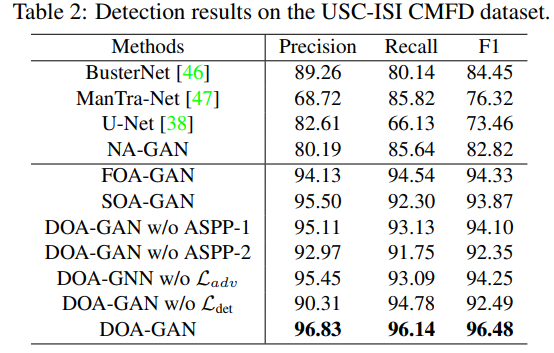
发现
- DOA-GAN w/o \(L_{adv}\) 的所有指标比 busternet 好
- DOA-GAN 比 DOA-GAN w/o \(L_{adv}\) 好,说明DOA的判别器的判别能力好
- DOA-GAN 比 DOA-GAN w/o \(L_{det}\) 好,说明DOA 的 det 损失好
- 除了在 pristine 上的 f1 score,DOA-GAN 比 FOA-GAN 和 SOA-GAN 好,说明两注意力互补提高检测定位表现
- DOA-GAN, SOA-GAN, 和 FOA-GAN 比 U-Net 和 NA-GAN 好,说明仿射计算的有效性
图5是可视化结果,DOA最好 。倒数第二张是DOA结果,最后一个是ground truth

4.2 Experiments on the CASIA CMFD dataset
CASIA 没有提供源和目标的标记,所以把DOA的最后一层卷积层替换为1通道的输出
使用 coco 和 USC-ISI 数据集训练 DOA GAN 和 busternet
对比方法:前三个是传统方法
a block-based CMFD with Zernike moment features (denoted as “Block-ZM”) [39]
an adaptive segmentation based CMFD (denoted as “Adaptive-Seg”) [36]
a discrete cosine transform (DCT) coefficients based CMFD (denoted as “DCT-Match”) [12]
densefield [8]
busternet
像素级表现,计算每幅阳性图像的p r f
图像级检测,输出mask>200像素篡改,认为这幅图篡改,使用篡改图像和对应真图进行检测,
表3是结果
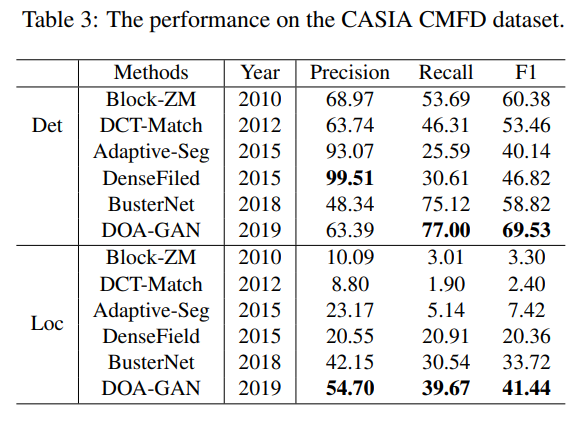
表中buester结果与46不同,因为本文仅在上述数据集上训练busternet
图6是可视化结果 (densefield 是什么??)

4.3 Experiments on the CoMoFoD dataset
表4是结果
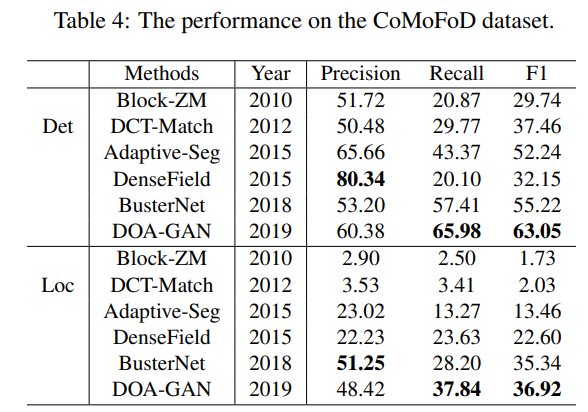
这个数据集里有许多操作和后处理如旋转缩放形变压缩模糊噪声等
图8是f1分数,

图9是检测正确的数目
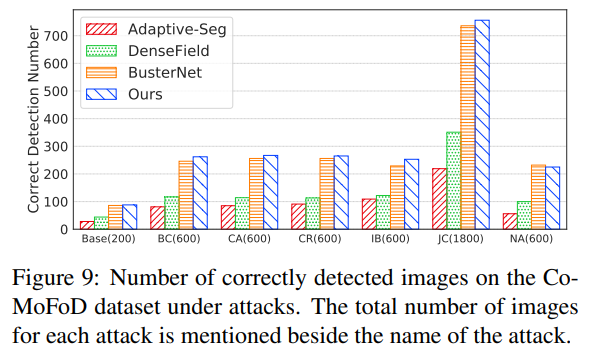
像素f1分数>30%,认为是检测正确
4.4 Discussion
缺点:从复制一部分背景粘贴到同一背景,不好检测。缩放程度太大,不好检测

第一个背景太同一, 第二个篡改区域小
5 Extension to Other Manipulation Types
DOA是在同一图像计算仿射矩阵,很容易扩展到在两幅图计算矩阵(拼接篡改,视频复制粘贴)
对比方法
DMVN[45]
DMAC[23]
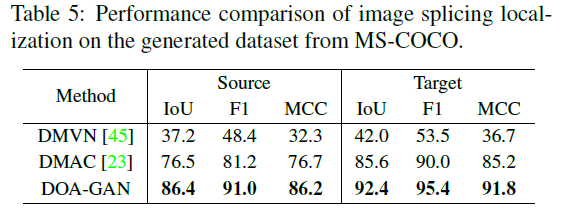
拼接检测:在23的生成数据集上训练,在ms-coco上测试,表5是结果
视频复制粘贴:视为帧间拼接
视频目标分割数据集:
DAVIS [34]
SegTrackV2 [42]
Youtube-object [35]
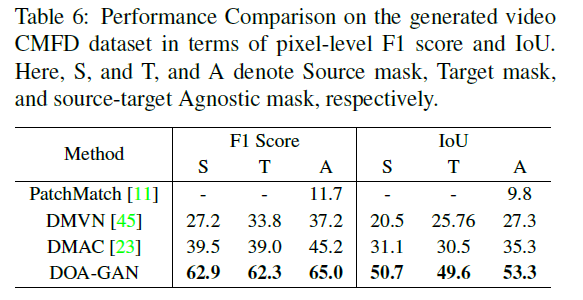
表6是结果,DOA最好
结论:
以后研究 共显著性定位检测和卫星图像的图像级篡改

