Image splicing forgery detection combining coarse to refined convolutional neural network and adaptive clustering阅读
摘要 : 拼接检测方法:
- a coarse-to- refined convolutional neural network ( C2RNet ):从不同尺度的图像 patch 提取未篡改区域和篡改区域的图像属性差异
- 为降低计算开销,提出 an image-level CNN 来替换 patch-level CNN
- diluted adaptive clustering:在 C2RNet 定位可疑篡改区域后,应用自适应聚类方法去除错误区域,生成最终检测结果
出处 : ELSEVIER Information Sciences ,Available online September 2019
数据集 CASIA[35] COLUMB[14] FORENSICS[10]
实验环境 a computer with an Intel Xeon E5-2603 v4 CPU and an NVIDIA GTX TITAN X GPU. tensorflow
metrics the averages of the precision 、recall 、f1-score
1 introduction
基于基本的图像属性[6 7 36],36 在 chroma 色度图像中计算灰度共生矩阵检测拼接,43介绍了chroma 色度空间与常用的RGB和 luminate 亮度空间的比较
设备属性[11 14 17 18 25],14提出了一种基于几何不变量的真伪对比拼接图像分类方法,25发现重新采样和插值的痕迹可以用来定位篡改区域,[18]考虑了对光响应的非均匀性分析,并着重于小伪造的检测。
压缩属性[3 16 21 23 40],Lin等。 [21]探索了隐藏在JPEG格式图像中的离散余弦变换(DCT)系数中的双重量化效应,以检测拼接的伪造区域。此外,罗等[23]引入了JPEG误差分析,即量化和舍入误差,以进行伪造检测。
哈希技术[32 34 37 39],Yan等。 [39]提出了一种基于四元数的图像哈希算法来检测伪造图像中的颜色变化。
上面提到的方法通常着重于指定的图像属性,因此在实际应用中具有以下局限性:(1)如果一些隐藏过程(例如整体模糊操作),基于基本图像属性的检测方法可能会失败。在伪造拼接后应用。 (2)如果设备噪声的强度较弱,则基于成像设备属性的检测方法可能无效。 (3)基于图像压缩特性的检测方法只能检测JPEG格式的图像伪造。 (4)最后,基于散列技术的检测方法需要依赖于原始未篡改图像的散列,因此不能严格分类为盲伪造检测的一种。
在[29,42]中,首先使用CNN来判断图像是否被篡改。 [29]中提出的方法可以判断原图像是否已被篡改,但无法定位修改后的区域。在[42]中,尽管作者试图找到被篡改的区域,但检测到的区域显示为由白色方形块组成的不准确的粗糙区域。
为了提高检测性能,我们先前的研究[38]2018应用了一种检测方法[1],该方法利用一系列不重叠的图像块作为CNN的输入。但是,当图像块中的所有像素都来自篡改区域时,将预测该图像块显示为未篡改。在[22]2018中,作者使用较大尺寸的图像块来揭示篡改区域和未篡改区域之间的属性差异。但是,如果输入的伪造图像的尺寸较小,则检测方法可能会失败。 [15]2018中的检测方法利用图像的EXIF元数据作为监督信号来确定图像是否自洽,尽管如果图像中EXIF元数据的信息不足,则检测结果无效。 同时,由于将每个图像块与图像中所有剩余的图像块进行比较,因此[15]中检测方法的时间复杂度非常高。
为了进一步探索基于CNN的拼接伪造检测方法,提出了一种两阶段的层次特征学习方法。特征学习的第一阶段基于粗糙的CNN,它可以粗略地识别出未篡改区域和篡改区域之间的图像属性差异。使用改进的CNN进行特征学习的第二阶段,进一步揭示了未篡改和篡改区域之间图像属性的本质差异。
2 proposed method
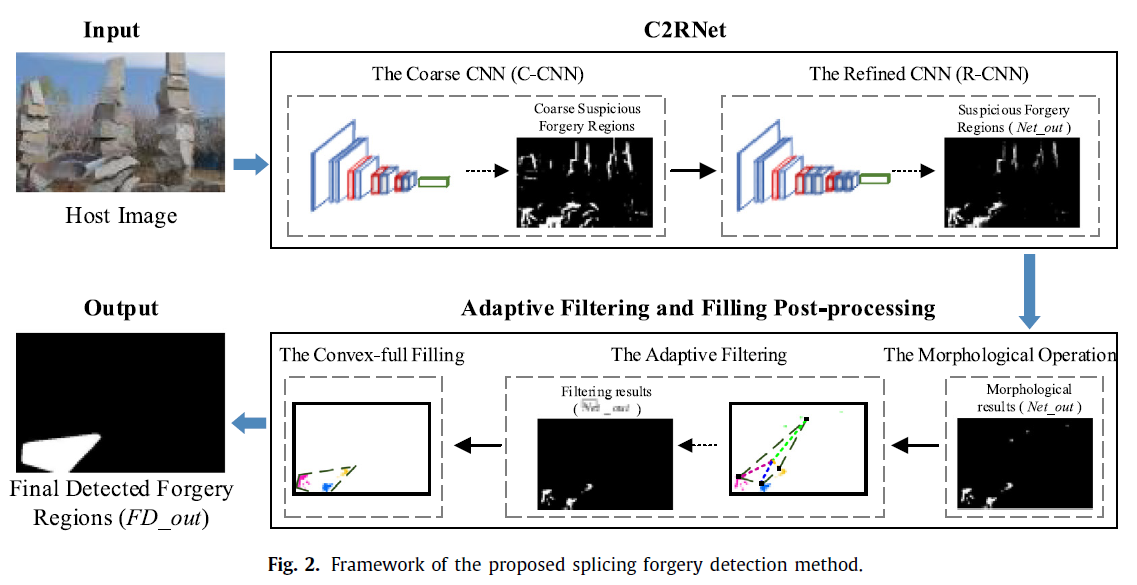

host image --> C2RNet --> Net_out --> adaptive filtering --> FD_out
2.1 Coarse-to-refined network (C2RNet)
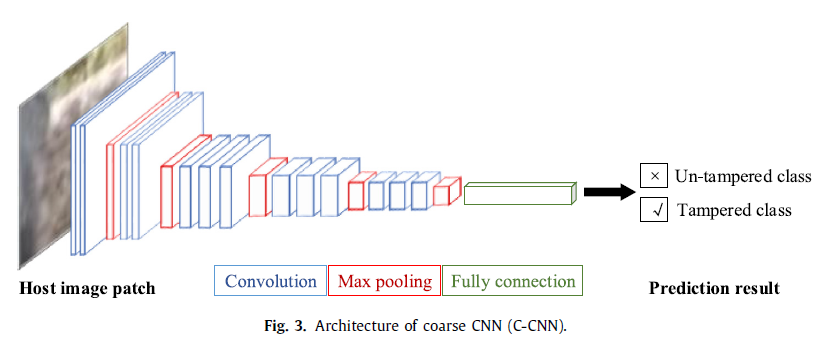
C-CNN 基于VGG-16
沿着篡改区域的边缘和原图相应位置的边缘提取 \(W_c×W_c\) 的 patch(见3.2),用于训练 C-CNN,通过训练,C-CNN学到篡改区域和非篡改区域的不同。在测试阶段,C-CNN 输出预测分数值
R-CNN
C-CNN输出可疑篡改检测的粗糙结果,这意味着在原图边缘可能有一些不准确的检测区域。所以使用C-CNN对这些区域进行不准确的检测,需要通过进一步的学习来过滤掉。
R-CNN 基于 VGG-19
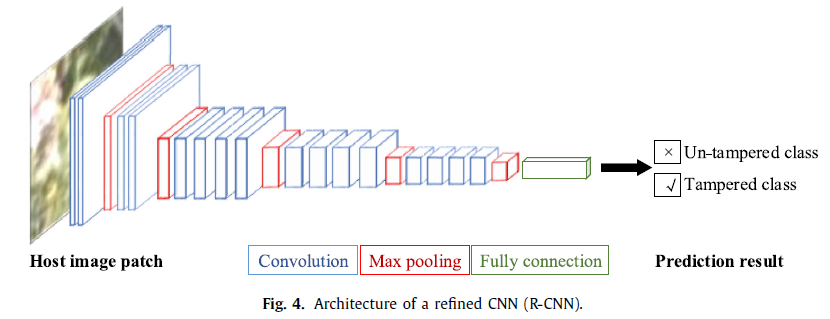
输入尺寸是 \(W_r×W_r\) 且 \(W_c< W_r\) ,这些patch是从原始图像的边缘和被篡改区域的轮廓中提取出来的(见3.2),R-CNN可以学习图像属性的差异,滤除C-CNN检测到的这些不准确区域,得到精细的可疑区域
Image-level CNN for fast computations
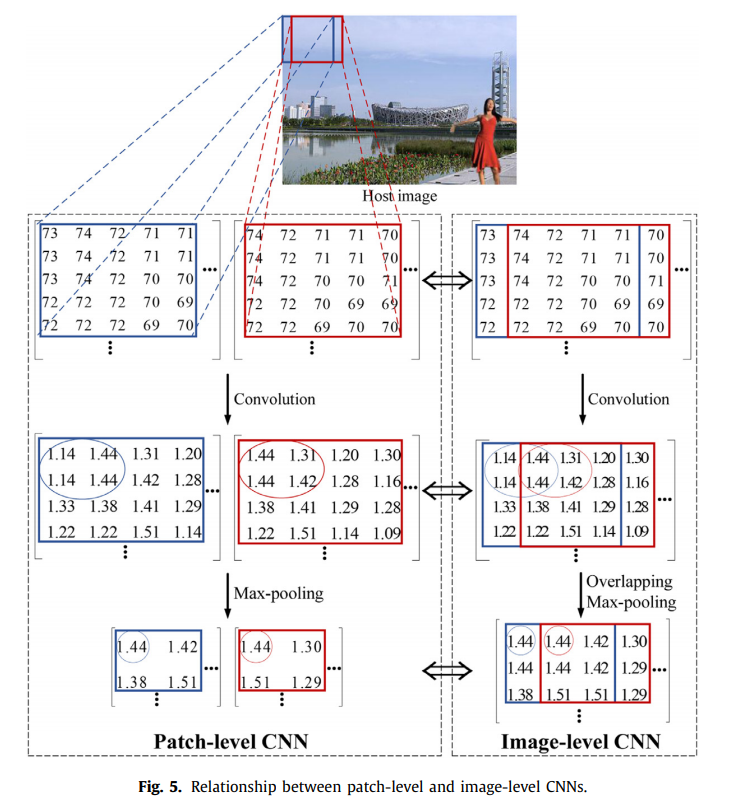
- patch-level CNN 的 max-pooling 层被 image-level CNN 的 overlapping max-pooling 层替换
- image-level CNN 的 overlapping max-pooling 层后加了下采样
[33]提出把 patch-level 转换成 image-level ,从而大大降低了计算复杂度
2.2 Adaptive clustering approach
- adaptive outlier filtering
- a convex full filling process
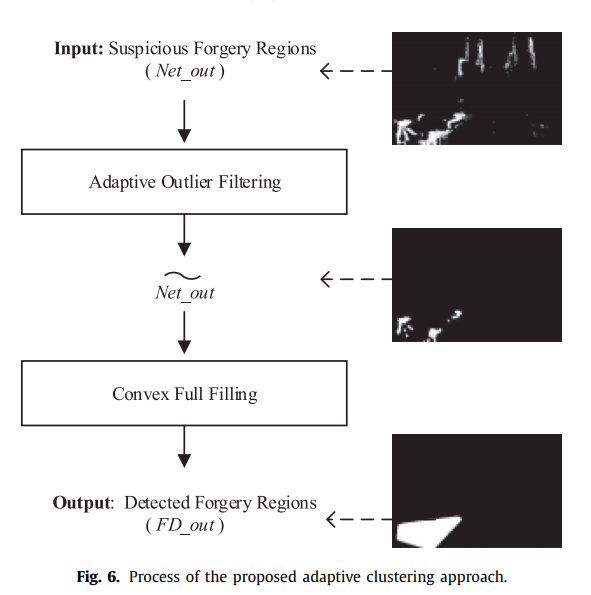

**step-1: **
在 Net-out 做形态学操作 t(x),粗略填充 gaps 和删去明显的错误。
-
应用 k-均值聚类算法 [13] 把 Net-out 划分成 n 个聚类 {\(C_1,C_2,...,C_{n-1},C_n\)}
-
计算聚类的 centroids 矩心 {\(b_1,b_2,...,b_{n-1},b_n\)}
-
计算由 {\(b_1,b_2,...,b_{n-1},b_n\)} 组成的外部多边形的几何中心 gc
-
计算 gc 和 {\(b_1,b_2,...,b_{n-1},b_n\)} 的欧几里得距离 {\(d_{1,gc},d_{2,gc},...,d_{n-1,gc},d_{n,gc}\)}
step-2:
-
计算 {\(d_{1,gc},d_{2,gc},...,d_{n-1,gc},d_{n,gc}\)} 的标准差 sd,如公式1。sd 越小,聚类分布越集中。


-
如果 sd 满足公式3,则认为聚类是集中分布,就把 Net-out 当做 \(\widetilde{Netout}\)

step-3
如果 sd 不满足公式3,使用 adaptive threshold \(t_h\) 删去 distant clusters
-
选择包含像素数量最多的 cluster \(C_k\) 作为 benchmark cluster, \(C_k\) 的 centroid 是 \(b_k\)
-
计算 \(b_k\) 和 {\(b_1,b_2,...,b_{n-1},b_n\)} 的欧氏距离{\(d_{1,k},d_{2,k},...,d_{n-1,k},d_{n,k}\)}
-
若 \(C_i\) 满足 \(d_{i,k}< t_h,i=1,2,...,n\) ,仍令 \(C_i\) 作为 \(\widetilde{Netout}\) ,其中\(t_h\)如下

step-4
使用 the convex hull algorithm [2] 填充 \(\widetilde{Netout}\) 的 empty parts,得到最终篡改区域 FD_out
由于后处理过程的局限性,本文方法关注于单个篡改区域的检测。
3 experiment
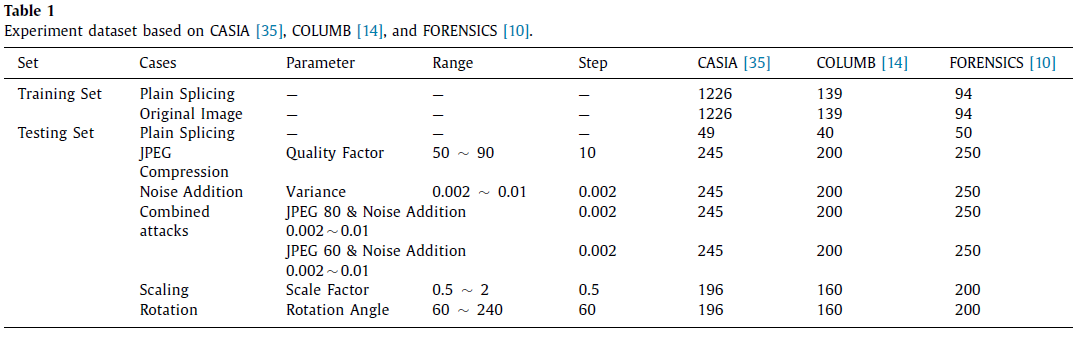
数据集
-
CASIA:广泛用于评价各种拼接篡改检测方法的性能。包含TIFF格式的图像1275对(篡改图像1275个,原始图像1275个),其中大部分像素分辨率约为384×256 。拼接的伪造区域是小而精细的对象
随机选择1226对做训练集,剩下49对做测试集
-
COLUMB:包含179对TIFF格式图像,大小757×568
随机选择139对做训练集,剩下40对做测试集
-
FORENSICS:由高分辨率图像(2018×1536大小)组成,包含144对PNG格式的图像。拼接的伪造区域是小而精细的对象,但是这些区域更真实,更接近背景。拼接伪造区域是简单、大、无意义的区域
随机选择94对做训练集,剩下50对做测试集
以上未经改动的图像称为 plain splicing forgery
又对拼接图像加入5种攻击:
- JPEG Compression,用不同的压缩质量把拼接图像存为 JPEG 格式
- Noise Addition,对拼接后的图像加入高斯白噪声,均值为零,方差不同
- Combined Attack,在拼接图像中加入不同方差的高斯白噪声,并对拼接结果存为jpeg
- Scaling:缩放因子 0.5-2 缩放图像
- rotation:旋转角度变化从0◦-240◦
3.1 training
C-CNN 训练: \(W_c=32\) 以篡改区域边缘的像素为中心,提取32×32的 patch ,也在相应的原图位置提取 patch ,得到 11500 个篡改 patches 和 11500 个非篡改patches
R-CNN 训练:\(W_r=96\) ,用Canny edge detector [5]检测原始图像的edge,edge上的像素作为中心提取96×96的patch 记作un-temped。在拼接图像中,以篡改区域边缘的像素为中心,提取96×96的 patch 记作 temped ,得到 11500 个篡改 patches 和 11500 个非篡改patches
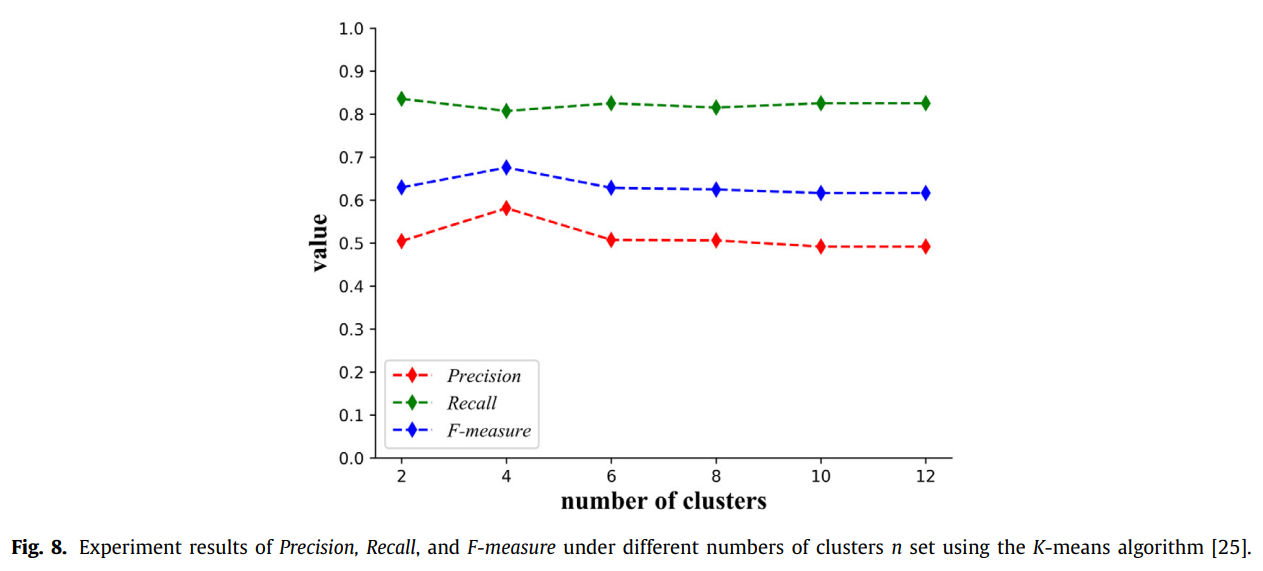
3.2 Analysis of cluster number n
为选取合适的 n 值,做了实验,选择 n=4 比较好
3.3 evaluation
对比方法
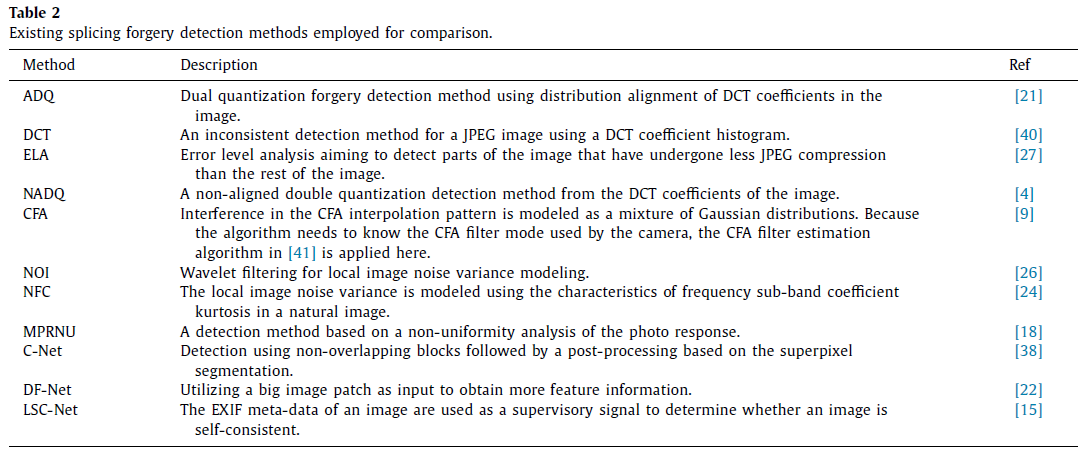
DCT [40]-2007, ADQ [21]-2009 , ELA [27]-2007 , NADQ [4]-2012 , CFA [9]-2012 , NOI [26]-2009 , NFC [24]-2014 , MPRNU [18]-2017 , C-Net [38]-2018(C2r net) , DF-Net [22]-2018 , and LSC-Net [15]-2018
[41]-2016已实现了大多数对比方法
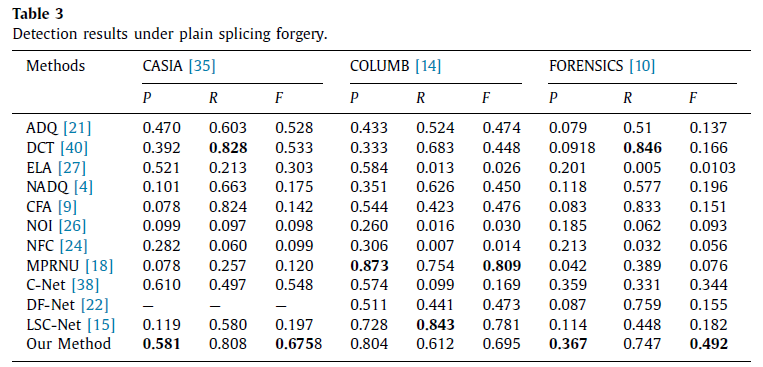
在原始数据集的结果


前 6 列来自三个数据集。最后一列的图含有较多的篡改区域,其形状不规范,对比方法都失败了,而 proposed method 找出了大部分区域 。
当篡改区域的形状较长且极薄时,所提出的方法和比较的方法都无法检测到篡改区域
五种攻击的检测结果
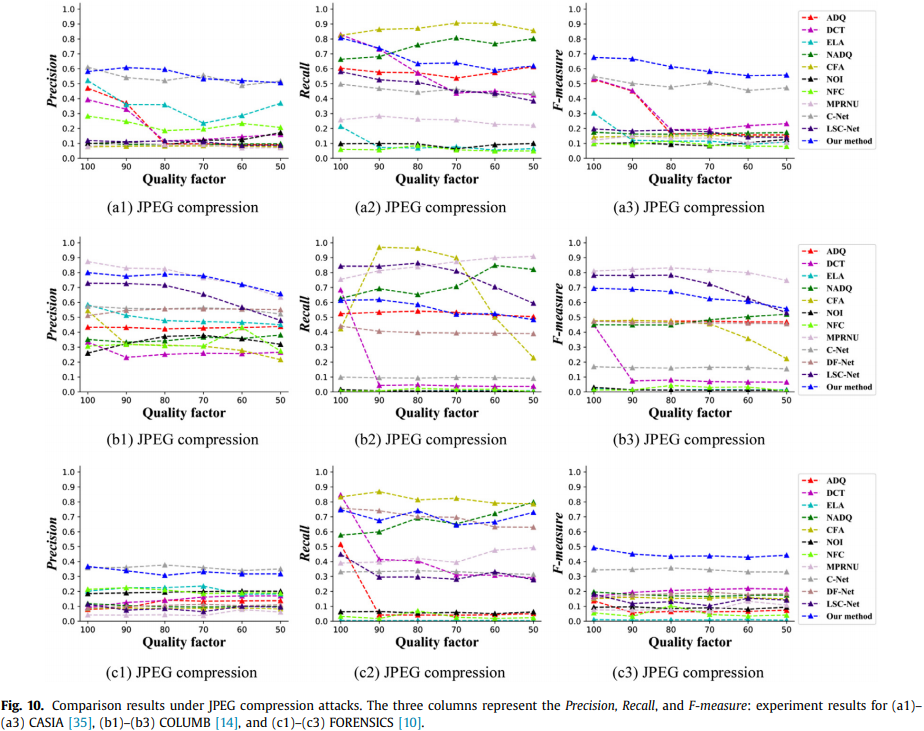
CFA的 recall(把是篡改的当成篡改的比例) 比较高,因为它把几乎整张图当成篡改区域。
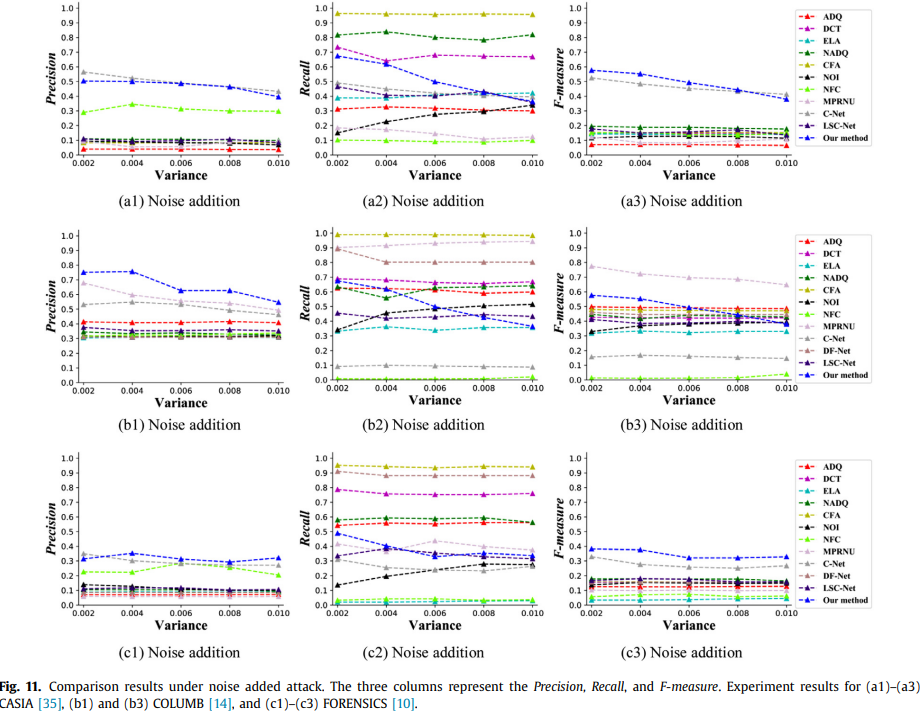
可以看出本文提出的方法表现不错

 浙公网安备 33010602011771号
浙公网安备 33010602011771号