An End-to-End Dense-InceptionNet for Image Copy-Move Forgery Detection阅读
出处 :2019 IEEE transactions on information forensics and security
作者 : Jun-Liu Zhong, Chi-Man Pun, Senior Member, IEEE,the Department of Computer and Information Science, University of Macau
摘要 : dense inception-net 复制粘贴检测 包括3部分:
- Pyramid Feature Extractor (PFE),extract multi-dimensional and multi-scale dense-features,提取器每层的特征都直接和上一层的特征连接起来。
- Feature Correlation Matching (FCM) ,学习深度特征的高相关性,得到三个候选匹配图
- Hierarchical Post-Processing (HPP),利用三个匹配图得到交叉熵的组合,通过反向传播可以得到更好的训练。
数据集 训练集:CMH 、MICC-F200 、MICC-2000 、GPIP 、Coverage 、SUN
测试集:FAU、CMH、GPIP、comofodnew
实验环境 two parallel NVIDIA RTX2070 GPUs. pytorch
classic methods and DNN models are trained on a 3.2 GHz CPU, 64 GB RAM and, two parallel RTX2070 GPUs.
metrics precision 、recall 、f1-score
Ⅰ introduction
基本思路1) feature extraction; 2) feature matching and 3) post-processing operations
基于块的方法 3 把图像分成 overlapped and regular blocks,有许多特征提取方法,离散小波变换(DWT)[4],离散余弦变换(DCT)系数[5],傅立叶-梅林分析(AFMT)[2],模糊矩不变式[6],zernike[7],极坐标复指数变换( PCET)[8],[9],极余弦变换(PCT)[10],径向谐波傅立叶矩(RHFM)[11]被提出以从块中提取特征。 然后,块匹配算法,例如Kd-tree [6],局部敏感哈希(LSH)[7],搜索块特征的相关性以找到相对最佳匹配。 最后,提出了后处理操作[2],以通过考虑一组匹配的特征一致性来进一步提高性能。
基于关键点的方法提出了局部描述符(例如,尺度不变特征变换(SIFT)[12]-[14]并加快了鲁棒特征(SURF)[15],[16]),以搜索高熵区域 找到局部的极端点。 由于仅匹配稀疏极点,所以匹配步骤[3],[14],[15],[17]比基于块的方法更有效。 最后,在后处理步骤[3]中对匹配的关键点进行区域填充。
通常,基于块的方法具有一些致命的弱点,例如昂贵的计算成本,不可检测的大比例失真。 基于关键点的方法无法解决平滑的篡改片段。 融合方法fusion methods [18] – [21]结合了基于关键点的特征提取和基于块的方法的region matting。 不幸的是,具有稀疏关键点功能的融合方法也无法解决平滑的篡改片段。
liu [22]应用DNN作为特征提取器,Ying等 [23]应用图像的小波特征作为深度自动编码器的输入。 Bunk等。 [24]将DNN用作补丁分类器。经典方法[2] [3],[11]-[16],[18]-[20]和辅助DNN模型[22],[23]的缺陷在于,三个主要步骤通常是独立训练的,而不是将它们结合成一个整体。在独立步骤中很难手动粗调/微调各种参数。一些机器学习方法,例如PatchMatch(PM)[25],一致性敏感哈希散列(CSH)[26],[27],以联合训练整个结构中的所有步骤。然而,依赖于块特征提取的机器学习方法具有与基于块的方法相同的缺陷。而且,这些方法仅学习单个检测到的图像的特征以解决伪造问题。对于其他图像,由于没有积累的先验知识,这些方法必须重新初始化模型并重复多次才能解决。这些方法的效率远低于DNN。 Rao和Ni [28]提出寻找粘贴片段边缘的线索,以便进行后续训练。这容易将一般前景对象错误地标识为粘贴的片段,尤其是在复杂的纹理图像中。 Wu等。 [29],[30]为CMFD提出了端到端DNN解决方案(BusterNet)。然而,仅依赖于DNN结构的方法不能识别伪造物体的各种类别,特别是未经训练的物体类别。 BusterNet的一个重大缺陷是该模型仅针对已知或经过训练的案例提供其有效的应用程序,即data-dependent model
Ⅱ related work
dense net:每一层都接受来自他之前所有层的输出作为输入,所以一个 N 层的网络,一共存在 n×(n+1)/2 个的连接,可解决梯度退化
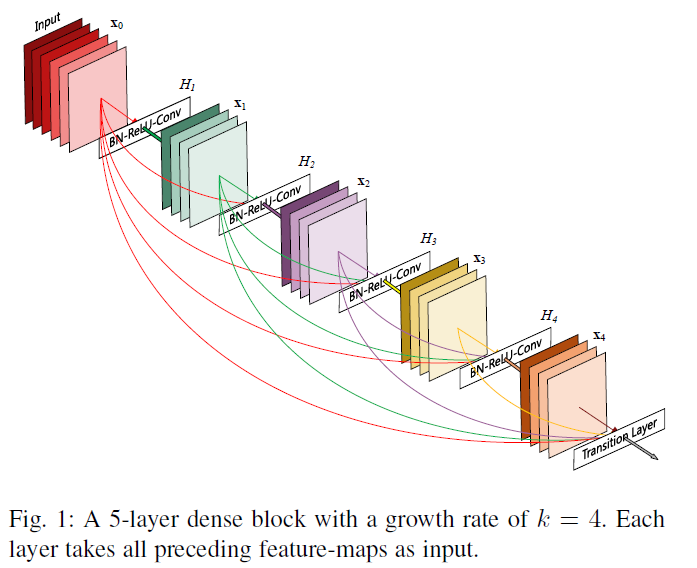
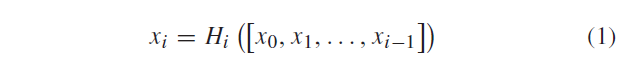
\(x_i\) 表示接收前面所有层的特征图作为输入来生成第i层的特征图,\(H_i\) 是三种连续操作的混合:batch-normalization,relu函数,3×3卷积
sublayer--layer--block-trasition layer

整个网络是 densely 连接的 dense block,为保证特征图大小不变,有 transition layer (包含了一个batch normalization,一个1×1的卷积层以及一个2×2的均值池化层)
[36] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jul. 2017, pp. 2261–2269.
Ⅲ proposed network
Dense-InceptionNet 包括三部分:
-
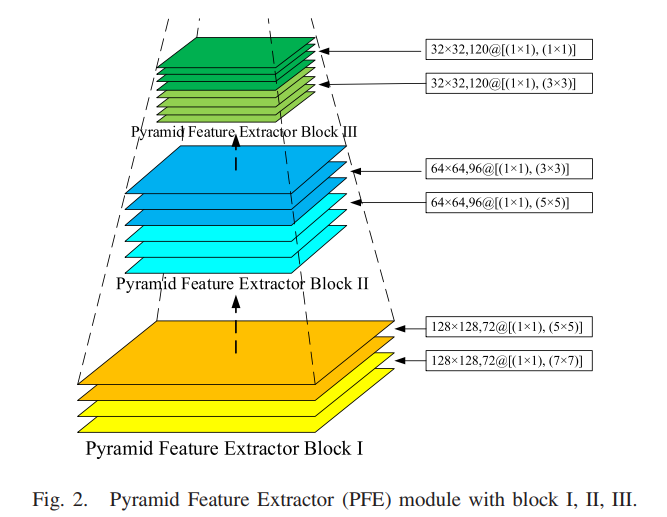
Pyramid Feature Extractor (PFE),米色部分包括 1个 pre-porcessing block,3 个 dense-inception net feature extractor blocks,3 个 transition blocks。每个 PFE block 是为了 extract multi-dimensional and multi-scale dense-features,transition block 为了压缩特征图的深度和调整特征图大小
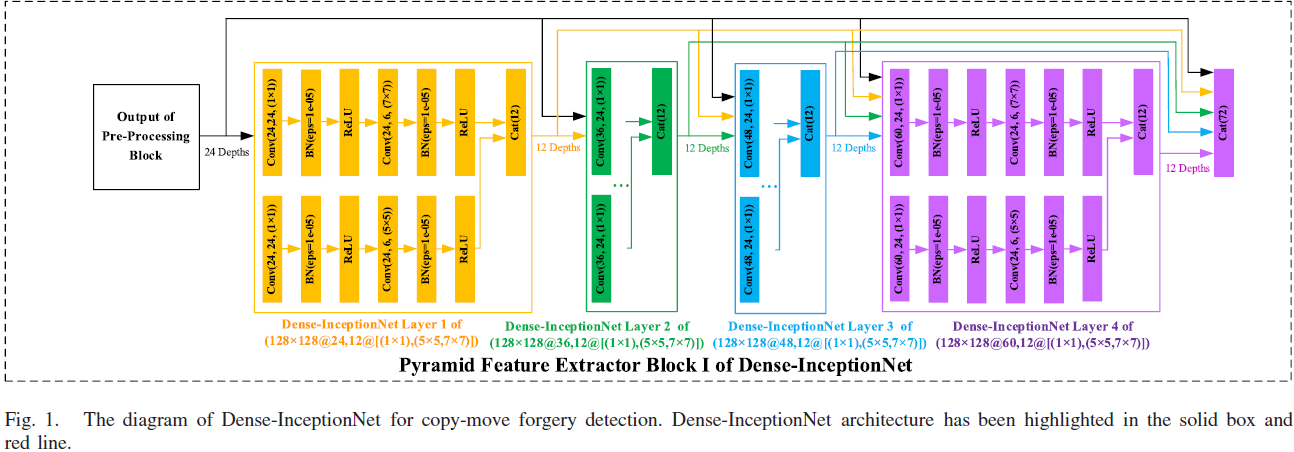
dense-inception net feature extractor blocks 借鉴了 dense net 的思想
-
Feature Correlation Matching (FCM) ,学习层次特征的相关性,即coarse information (特征相关匹配块 III )和fine details (特征相关匹配块 I、II ),得到得到三个候选匹配图
-
Hierarchical Post-Processing (HPP),利用三个匹配图得到交叉熵的组合,再反向传播
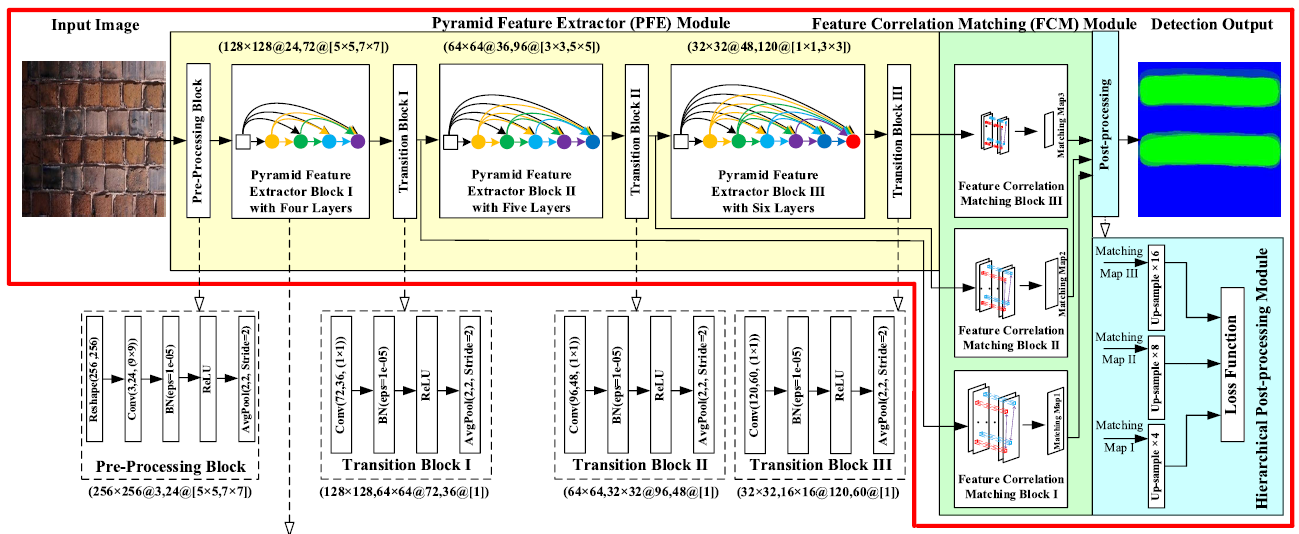
A Pyramid Feature Extractor Module
pre-processing block
ReSh 将输入图像整形为统一大小的256×256×3
Conv size=9×9 ,输出 24 层特征图
BN 保持各层分布不变
ReLU 克服梯度消失,加速训练
AvgPool
输出128×128×24
Pyramid Feature Extractor block
每个 Dense-InceptionNet layer 取之前所有层的特征图作为输入,经过一个 Dense-InceptionNet layer 增加 12层(propagated rate p)特征图(24--36--48--60--72)
layer 内部的 growth rate g=6, layer 内部有 2 个 Conv-BN-ReLU 结构
每个 Conv-BN-ReLU,有两个sub-block,分别增加6 depth,然后拼接,输出a fixed 12 (6×2) concatenated layers
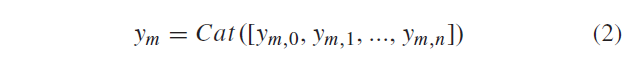
block m ( m=1,2,3 ) 的输出特征图 \(y_m\) 是由block m 内部的 Dense-InceptionNet layer n \(y_{m,n}\) 的特征图拼接而来
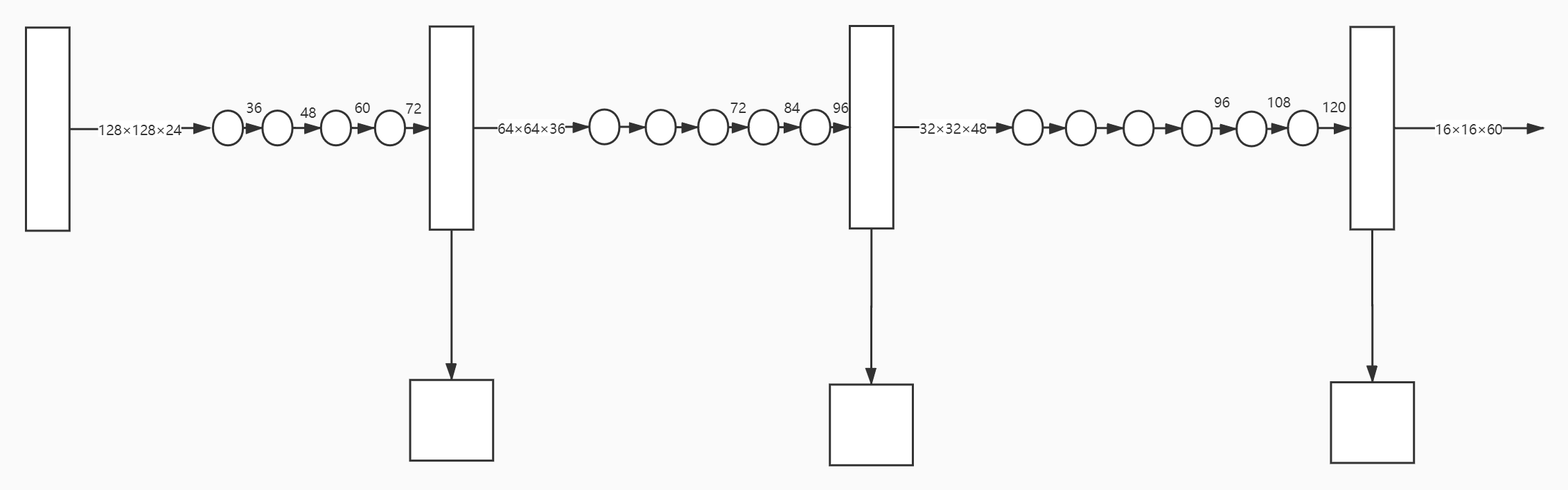
transition block
存在于两个 Pyramid Feature Extractor block 之间

\(y_{m,n}\) 是 block m 的 layer n 的输出 depth
\(l_{m,n}\) 是 block m 的 layer 数目 n
\(y^{t}_m\) 是 pre-processing / transition block 的输出 depth
B Feature Correlation Matching Module
如图1 ,从 transition block Ⅰ Ⅱ Ⅲ 输出的 feature map 分别输入给相应的 feature correlation matching block Ⅰ Ⅱ Ⅲ
考虑到匹配模块的输入层数是 36 48 60,KD-tree [3], PatchMatch[25]方法并不合适。
且map的尺寸小,是 64x64 32x32 16x16 的,受到 the nearest neighbor (2NN) test [17] of a keypoint-based method[13]启发,本文提出 a coarser to fine feature matching(在三幅特征图分别做 match )
1. 每个特征图做match
一幅 feature map N×N,有这么多特征点: \(P_0={P_1,...,P_i,...,P_{N×N}}\)
每个特征点有 M 个维度: \({(p_{1,1},p_{1,2},...,p_{1,m}),(p_{2,1},p_{2,2},...,p_{2,m}),...,(p_{i,1},p_{i,2},...,p_{i,m}),...,(p_{N×N,1},p_{N×N,2},...,p_{N×N,m})}\)
用欧氏距离定义负特征相关系数,欧式距离越小,两向量越相关
特征点\(P_i\) 与其他特征点的负特征相关系数定义如公式4
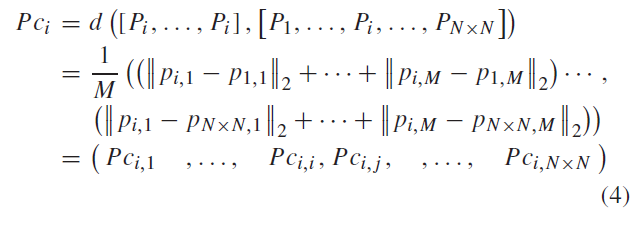
\(P_{c_i}\) 是 对于每个通道计算这个通道 \(P_i\) 和此通道所有其他点的欧氏距离的和,再除以通道数 M
\(P_{c_{i,j}}\) 是\(P_i\),\(P_j\) 的负特征相关系数,越相关则结果越接近 0。(负可能是指负相关的意思)
2. 找到和 i 匹配的 j 点
\(P_{c_i}\) 和其他点的相关系数升序排列,如公式5
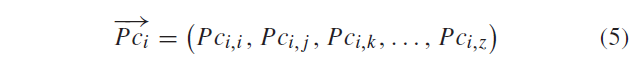
式中,\(P_j\) 和\(P_i\) 满足公式6 的情况下 ,认为\(P_j\) 和\(P_i\) 是一对候选匹配对
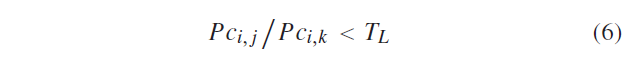
阈值 \(T_l=0.6\) ,\(P_{c_{i,k}}\) 表示第三小的系数
由此,生成大小为N×N的 matching map,标记每个特征点的匹配系数(我觉得这里的深度为 M x (N x N) )
3. 计算特征匹配度
设计公式 7 作为 特征匹配度 来衡量源像素和候选目标像素的相似性,\(P(X)\)是激活函数(类似sigmoid),给出两点的相似性值\(P(X_{i,j})\)\(\in(0,1]\) ,便于二分类
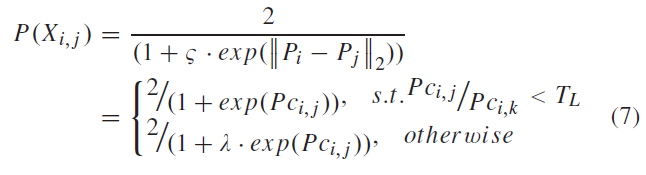
两点相关,负特征相关系数 \(P_{c_{i,j}}\)接近 0, \(exp P_{c_{i,j}}\) 接近于1,特征匹配度 \(P(X_{i,j})\) 接近于 1
两点不相关,\(P_{c_{i,j}}\)接近 1, 令 \(\lambda=2\) 使特征匹配度 \(P(X_{i,j})\) 接近 0
再把相似性值\(P(X_{i,j})\) 填充到 i 点matching map,这时 matching map 里只有范围 0 到 1 的值。
C Hierarchical Post-Processing Module
matching map Ⅰ Ⅱ ,分别是32×32,64×64,提供局部细粒度匹配信息
matching map Ⅲ,是16×16,提供全局粗粒度匹配信息
post-processing module
1. 先计算每个 map 的交叉熵损失
2. 再根据权重计算总的交叉熵损失
先通过双线性插值把三幅 matching maps 上采样到同样大小 256×256
先计算Ⅰ的像素 i,j 的交叉熵损失,\(l_{i,j}\) 表示像素i和j的真正相似性,\(P^c_Ⅰ(X_{i,j})\)表示预测的相似性值
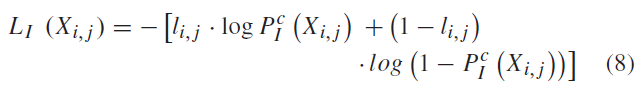
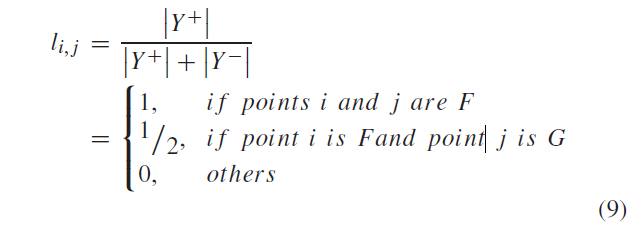
\(P^{c}_Ⅰ(X)\) 是上采样后的matching map \(P_Ⅰ^{c}\) 的激活函数,Y+ ,Y-分别表示正负像素,F=forgery,G=genuine,
| $l_{i,j} $ | j=F | j=G |
|---|---|---|
| i=F | 1 | 1/2 |
| i=G | 0 | 0 |
如果 i 是假像素,匹配的 j 是假像素,认为真正的相似性是 1
如果 i是假像素,匹配的 j 是真像素,认为真正的相似性是 1/2
如果 i 是真像素,不论匹配谁,认为真正的相似性是 0
对公式8,如果找到的 i 确实是假像素,loss 就低
如果找到的i误当作假像素,loss 就高
总的反向传播损失函数,如公式10

\(\alpha \beta\gamma\)分别是matching map Ⅰ Ⅱ Ⅲ 的权重

图3 是matching map图

Ⅳ 训练
A 训练数据集
-
CMH:由四个CMH子数据集组成,共有108张复制-移动篡改图像。篡改图像包含了旋转和缩放变换的攻击
-
MICC-F220:有110个基础和110个篡改图像。图像的大小范围从722×480至800×600。然而,该数据集不提供篡改图像的 ground truth
-
MICC-2000:有1300个基础和700张篡改图像,尺寸为2048×1536。然而,该数据集也不提供篡改图像的ground truth
-
GRIP:有80个基本图像和80个相应的篡改图像。数据集提供了相应的ground truth。大部分复制的片段很光滑。
对于提出的网络模型来说 ,学习平滑片段是有好处的
-
Coverage:数据集有100个基本图像和相应的篡改图像,平均尺寸为
400×486
-
SUN:数据集有397个类别和108,754个基本图像。相应的注释图像可以方便地生成篡改图像和GT。为了获得更多的训练数据,我们随机选择每个类别的10张基础图像作为篡改图像的来源。复制的基本图像片段经过旋转或缩放操作,和JPEG压缩、高斯噪声后处理。也对前五个数据集做了变换和后处理
一共得到131778个篡改图像,按8:1:1划分训练:验证:测试集
应用GitHub1,2中可用的图像伪造工具箱来注释相应环境场景、地点和对象的ground truth mask,以区分复制移动的片段(绿色)和真正的片段(蓝色)。

B metics and strategies
precision
recall
F1-score
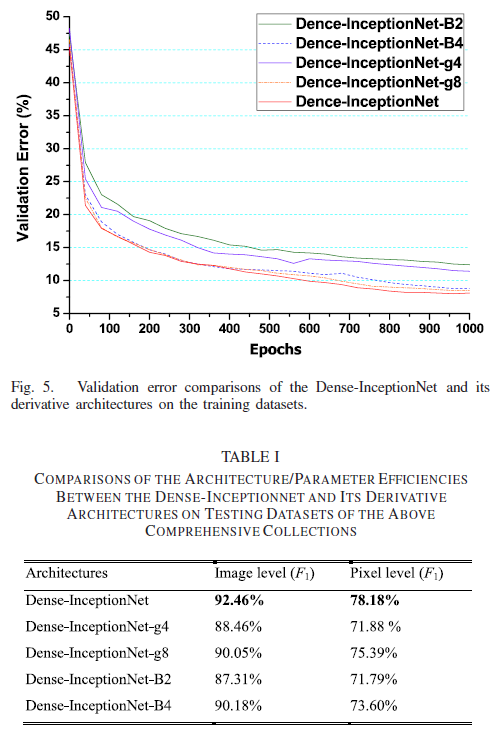
C Performance Comparisons Between the Derivative Architectures
Dense-InceptionNet with different depths, growth rates, propagated rates, and blocks are used to generate its four derivative architectures
- Dense-InceptionNet-g4:growth rate=4,propagated rate=8,output feature depths of the transition block I, II, III are 28, 34, and 41
- Dense-InceptionNet-g8:growth rate=8,propagated rate=16,output feature depths of the transition block I, II, III are 44, 62, and 79
- Dense-InceptionNet-B2:only two extractor blocks I, II, and transition
blocks I, II - Dense-InceptionNet-B4:four extractor blocks and transition blocks,output feature depths of extractor block IV and the transition block Ⅳ are 72,36
Ⅴ 测试
测试数据集
-
FAU:数据集有48张高分辨率的基础图像,平均大小为3000×2300。所有48张图像都分别遭受了旋转、缩放、JPEG压缩和额外的噪声攻击。测试图像的总数为48×37=1776,用于评估。
-
CASIA CMFD:数据集有1309个复制-移动伪造图像,其中包含了旋转、缩放变换的攻击。
-
comofodnew:复制的代码片段会受到旋转、缩放、扭曲或上述组合攻击的影响。然后,整个复制-移动伪造图像遭受JPEG压缩、高斯噪声、模糊、亮度、对比度变化。数据集有200个基本图像和相应的200×24 = 4800张图像,平均大小为512×512。
对比方法
在各个数据集的结果
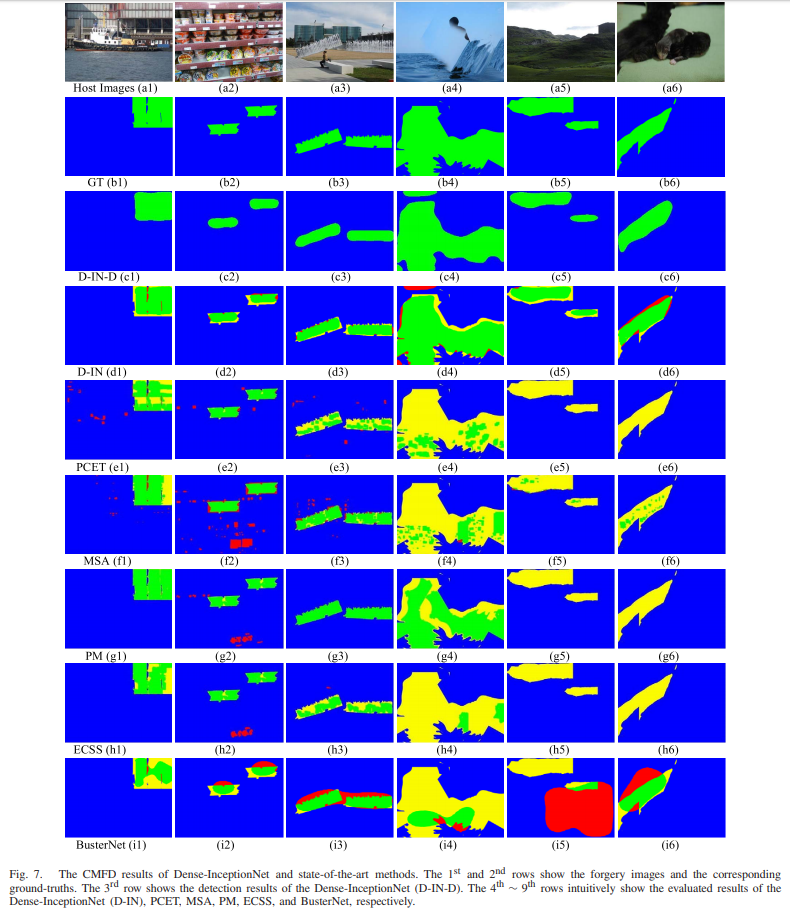

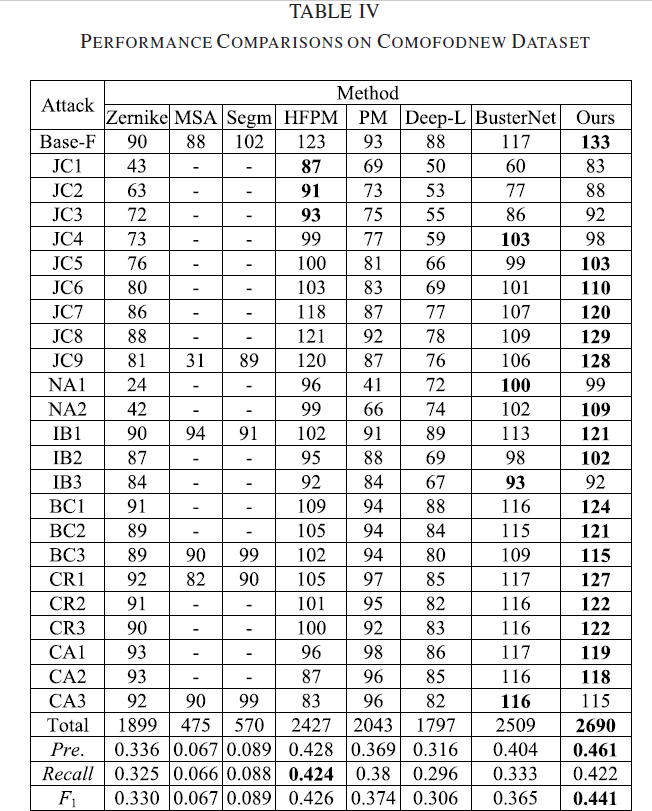
感觉整体表现比较好的是HFPM 、busternet 和 dense-inception


 浙公网安备 33010602011771号
浙公网安备 33010602011771号