
有监督的图像翻译——Pix2Pix
应用:图像到图像的翻译是GAN的一个重要方向,基于一个输入图像得到输出图像的过程,图像和图像的映射,如标签到图像的生成,图像边缘到图像的生成过程。
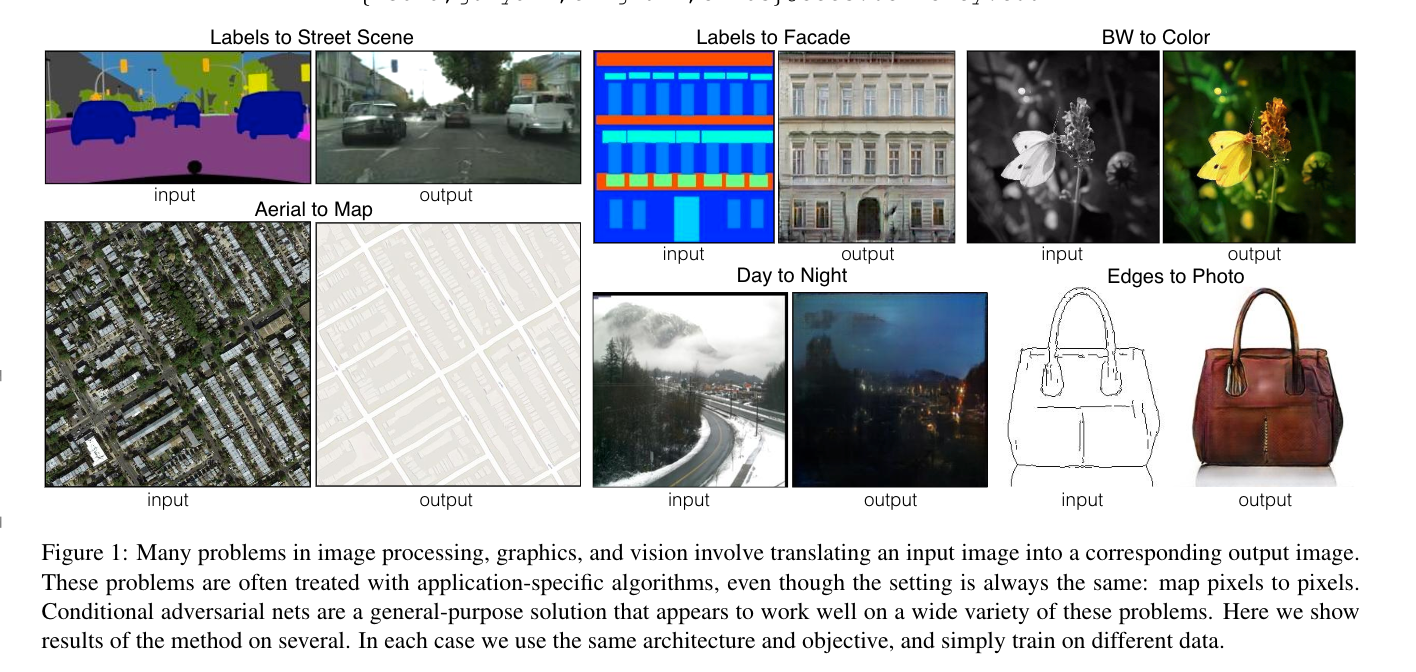
图像处理、图形和视觉中的许多问题涉及到将输入图像转换为相应的输出图像。这些问题通常使用算法来处理,尽管设置总是相同的:将像素映射到像素。条件对抗性网是一种通用的解决方案,它似乎能很好地解决各种各样的此类问题。这里我们展示了几种方法的结果。在每种情况下,我们使用相同的架构和目标,只是针对不同的数据进行训练。
使用条件GAN(CGAN)作为一种图像到图像的解决方案,添加条件信息来指导图像的生成,因此输入条件就是输入图像,其他GAN的生成器基于随机噪声产生图像,CGAN不依赖损失函数实现,无需手动设计损失函数。
图像领域的许多问题归结为图像翻译称为相应的输出,从像素预测像素,设计损失函数,生成模型最小化损失函数,

无条件GAN:生成器随机产生图像;有条件GAN:生成器和鉴别器都考虑了边缘映射,条件GNA损失是学习来的。总结:图像到图像到生成,用特定算法实现,像素到像素的映射,用loss function让算法优化。
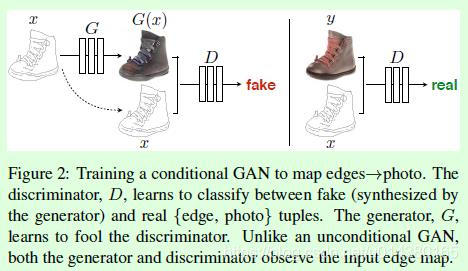
输入图像为y,x是y的边缘,x经过生成器,得到G(x),x和G(x)作为输入经过判别器,该预测值表示输入是否是一对真实图像。概率越大比表示越接近,
y 和x也作为输入,
训练过程图片 x 作为此cGAN的条件,需要输入到G和D中。G的输入是{x,z}(其中,x 是需要转换的图片,z 是随机噪声),输出是生成的图片G(x,z)。D则需要分辨出{x,G(x,z)}和{x,y}
优化目标:z代表的噪音,判别器D的优化目标(1)越大越好,生成器G的目标使得log(1-D(x,G(x,z))越小越好, ![]()
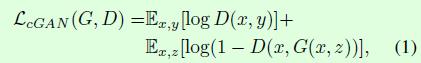
以前的经验告诉我们,将优化目标加上一些正则化,是对模型的性能提升有帮助的,l1和l2在图像生成问题上产生模糊结果,使用L1保证低频信号的正确性

随机噪音z作为输入的到生成器,作用???
网络结构:
生成器:U-Net结构
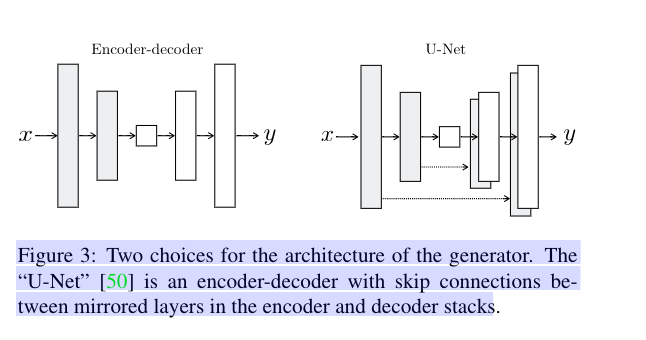
图像到图像的转换问题,高分辨率的输入到高分辨率的输出,但是,输出和输出外观又是不同的,但是都有相同的底层结构的渲染,输入中的结构和输出中的结构对齐,Encoder-Encoder结构的网络,输入经过一系列的网络,进行特征提取,所有的信息流流过所有的层。U-net跳过了某些层与层之间连接。
判别器:采用PathGAN
利用重建解决高频成分,一方面使用L1loss使得生成图片和训练图片相似,另一方面Gan只能用于构建高频信息,
那么就不需要将整张图片输入到判别器中,让判别器对图像的每个大小为N x N的patch做真假判别就可以了。
因为不同的patch之间可以认为是相互独立的。pix2pix对一张图片切割成不同的N x N大小的patch,判别器对每一个patch做真假判别,
将一张图片所有patch的结果取平均作为最终的判别器输
总结:pix2pix使用CGAN框架为图像到图像的翻译提供了一个通用的框架,使用U-Net网络作为生成器,提升细节,利用PatchGAS作为判别器,处理图像的高频部分
缺点:训练需要大量的成对照片,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号